2024-10-10 04:0:31 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Authors:
(1) Liang Wang, Microsoft Corporation, and Correspondence to ([email protected]);
(2) Nan Yang, Microsoft Corporation, and correspondence to ([email protected]);
(3) Xiaolong Huang, Microsoft Corporation;
(4) Linjun Yang, Microsoft Corporation;
(5) Rangan Majumder, Microsoft Corporation;
(6) Furu Wei, Microsoft Corporation and Correspondence to ([email protected]).
Table of Links
3 Method
4 Experiments
4.1 Statistics of the Synthetic Data
4.2 Model Fine-tuning and Evaluation
5 Analysis
5.1 Is Contrastive Pre-training Necessary?
5.2 Extending to Long Text Embeddings and 5.3 Analysis of Training Hyperparameters
B Test Set Contamination Analysis
C Prompts for Synthetic Data Generation
D Instructions for Training and Evaluation
5.2 Extending to Long Text Embeddings
![Figure 4: Illustration of the personalized passkey retrieval task adapted from Mohtashami and Jaggi [26]. The “” and “” are repeats of “The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again.” In addition, each document has a unique person name and a random passkey inserted at a random position. The task is to retrieve the document that contains the given person’s passkey from 100 candidates.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-1e830do.png?auto=format&fit=max&w=2048)



5.3 Analysis of Training Hyperparameters
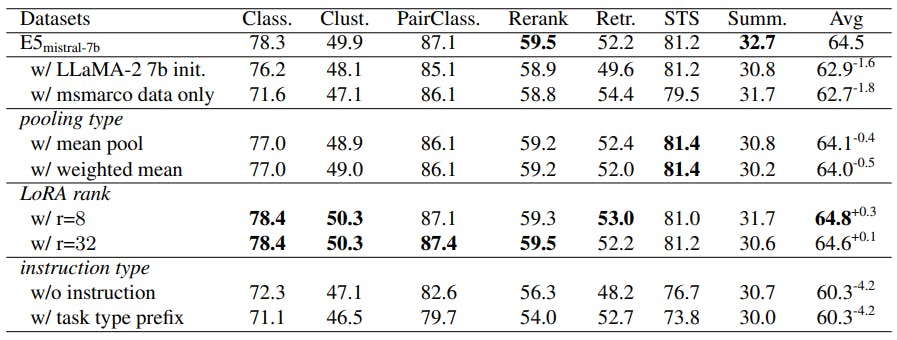
Table 4 presents the results under different configurations. We notice that the Mistral-7B initialization holds an advantage over LLaMA-2 7B, in line with the findings from Mistral-7B technical report [19]. The choice of pooling types and LoRA ranks does not affect the overall performance substantially, hence we adhere to the default setting despite the marginal superiority of LoRA rank 8. On the other hand, the way of adding instructions has a considerable impact on the performance. We conjecture that natural language instructions better inform the model regarding the embedding task at hand, and thus enable the model to generate more discriminative embeddings. Our framework also provides a way to customize the behavior of text embeddings through instructions without the need to fine-tune the model or re-built document index.
如有侵权请联系:admin#unsafe.sh