我一直以来都work在语法类fuzz上,产出了很多高质量的漏洞,但事实上我对其他fuzz所知甚少,这个系列权做对各类fuzz的思考和学习记录。
unicorn学习
主要是unicorn-engine-tutorial这篇文章的学习和一些思考。
task1
hxp CTF 2017 Fibonacci
因为想折腾新玩意,所以顺便安装了一个ghrida,教程在这

这个程序整体来看就是输出打印flag,不过打印的非常非常慢。
sakura@sakuradeMacBook-Pro:~/unicorn$ ./fibonacci
The flag is: hxp{F我们的目的是将这个程序用unicorn engine跑起来,那么就开始吧。
from unicorn import * from unicorn.x86_const import * import struct def read(name): with open(name,'rb') as f: return f.read() def u32(data): return struct.unpack("I", data)[0] def p32(num): return struct.pack("I", num) # 初始化unicorn class # 第一个参数是指定架构,第二个参数代表64位 mu = Uc(UC_ARCH_X86, UC_MODE_64)

首先需要自己手动去初始化虚拟内存。
PS.说到这里我觉得很多对操作系统没什么概念或者学的很差的同学应该就不知道为什么了,这里给出两个资料,把相关部分都看完就理解了。
程序的表示、转换与链接 关于可执行程序的装载和链接
程序的执行和存储访问 关于虚拟内存
异常、中断和输入输出
贴张图,感兴趣的自己去看csapp。



找到程序载入到虚拟内存的基地址,0x00400000,然后我们在0x0地址处分配一个栈。
BASE = 0x400000
STACK_ADDR = 0x0
STACK_SIZE = 1024*1024mu.mem_map(BASE, 1024*1024)
mu.mem_map(STACK_ADDR, STACK_SIZE)将程序load到基地址处,然后设置rsp指向stack。
mu.mem_write(BASE, read("./fibonacci"))
mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 1)现在我们已经像真正加载可执行程序一样,将其加载到了内存中,现在我们就可以开始运行我们的仿真了。
现在确定一下想要仿真执行的起始地址和终止地址。


还是很好找的,0x004004e0-0x00400582
mu.emu_start(0x00000000004004E0, 0x0000000000400582)unicorn在模拟执行程序的时候提供hook功能。
下面这个函数让我们在模拟执行每条指令之前打印出该指令的地址,指令大小。
def hook_code(mu, address, size, user_data):
print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size))
mu.hook_add(UC_HOOK_CODE, hook_code)最终组合就是下面这个脚本。
import struct def read(name): with open(name,'rb') as f: return f.read() def u32(data): return struct.unpack("I", data)[0] def p32(num): return struct.pack("I", num) mu = Uc(UC_ARCH_X86, UC_MODE_64) BASE = 0x400000 STACK_ADDR = 0x0 STACK_SIZE = 1024*1024 mu.mem_map(BASE, 1024*1024) mu.mem_map(STACK_ADDR, STACK_SIZE) mu.mem_write(BASE, read("./fibonacci")) mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 1) def hook_code(mu, address, size, user_data): print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size)) mu.hook_add(UC_HOOK_CODE, hook_code) mu.emu_start(0x00000000004004E0, 0x0000000000400582)
运行遇到如下问题,看一下0x4004ef这条指令为什么会访问到不可访问的地址。
sakura@ubuntu:~/unicorn$ python3 fibonacci.py
>>> Tracing instruction at 0x4004e0, instruction size = 0x1
>>> Tracing instruction at 0x4004e1, instruction size = 0x1
>>> Tracing instruction at 0x4004e2, instruction size = 0x2
>>> Tracing instruction at 0x4004e4, instruction size = 0x5
>>> Tracing instruction at 0x4004e9, instruction size = 0x2
>>> Tracing instruction at 0x4004eb, instruction size = 0x4
>>> Tracing instruction at 0x4004ef, instruction size = 0x7
Traceback (most recent call last):
File "fibonacci.py", line 31, in <module>
mu.emu_start(0x00000000004004E0, 0x0000000000400582)
File "/home/sakura/.local/lib/python3.6/site-packages/unicorn/unicorn.py", line 288, in emu_start
raise UcError(status)
unicorn.unicorn.UcError: Invalid memory read (UC_ERR_READ_UNMAPPED)

BSS段属于静态内存分配。通常是指用来存放程序中未初始化的全局变量和未初始化的局部静态变量。未初始化的全局变量和未初始化的局部静态变量默认值是0,本来这些变量也可以放到data段的,但是因为它们都是0,所以它们在data段分配空间并且存放数据0是没有必要的。
在程序运行时,才会给BSS段里面的变量分配内存空间。
在目标文件(*.o)和可执行文件中,BSS段只是为未初始化的全局变量和未初始化的局部静态变量预留位置而已,它并没有内容,所以它不占据空间。
虽然我并不熟知unicorn的运作原理,这只是我第一次使用它,但我们是通过read的方式直接把可执行文件读进基地址的,想也知道bss段的内存肯定是没有被分配的。
所以这里的解决方案是直接在执行这些有问题的指令前,将其rip指向下一条指令,从而跳过这些地址。
此外因为我们没有把glibc加载到虚拟地址里,所以我们也不能调用glibc函数。
instructions_skip_list = [0x00000000004004EF, 0x00000000004004F6, 0x0000000000400502, 0x000000000040054F] def hook_code(mu, address, size, user_data): print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size)) if address in instructions_skip_list: mu.reg_write(UC_X86_REG_RIP, address+size)
改一下hook函数就可以了。
然后因为我们需要打印出flag,而原本flag是通过如下函数打印的。
_IO_putc((int)(char)uVar3,(_IO_FILE *)stdout)
而此时_IO_putc是没有加载到内存中的,所以我们并不能调用这个函数。
但是可以看到要打印的flag作为第一个参数传递给该函数,而第一个参数是保存在rdi中的,所以只需要在执行这条指令之前读取rdi的值,然后把这个值打印出来即可。
def hook_code(mu, address, size, user_data): ... elif address == 0x400560: c = mu.reg_read(UC_X86_REG_RDI) print(chr(c)) mu.reg_write(UC_X86_REG_RIP, address+size)

其实对我来说能把程序用unicorn跑起来就算是完成任务了。
算法优化我并不感兴趣,所以看一下下一个task。
task2
分析如下shellcode
shellcode = "\xe8\xff\xff\xff\xff\xc0\x5d\x6a\x05\x5b\x29\xdd\x83\xc5\x4e\x89\xe9\x6a\x02\x03\x0c\x24\x5b\x31\xd2\x66\xba\x12\x00\x8b\x39\xc1\xe7\x10\xc1\xef\x10\x81\xe9\xfe\xff\xff\xff\x8b\x45\x00\xc1\xe0\x10\xc1\xe8\x10\x89\xc3\x09\xfb\x21\xf8\xf7\xd0\x21\xd8\x66\x89\x45\x00\x83\xc5\x02\x4a\x85\xd2\x0f\x85\xcf\xff\xff\xff\xec\x37\x75\x5d\x7a\x05\x28\xed\x24\xed\x24\xed\x0b\x88\x7f\xeb\x50\x98\x38\xf9\x5c\x96\x2b\x96\x70\xfe\xc6\xff\xc6\xff\x9f\x32\x1f\x58\x1e\x00\xd3\x80"先直接反汇编看一眼,嗯,看不懂。

作者提示了这个shellcode所用的架构是x86-32,且明确说明了是使用了系统调用。
那基本思路就是hook一下int 80,然后把使用的系统调用号从eax里取出来,然后参数依序从ebx,ecx,edx里取出来。

from unicorn import * from unicorn.x86_const import * mu = Uc(UC_ARCH_X86, UC_MODE_32) BASE = 0x400000 STACK_ADDR = 0x0 STACK_SIZE = 1024*1024 mu.mem_map(BASE, 1024*1024) mu.mem_map(STACK_ADDR, STACK_SIZE) shellcode = b"\xe8\xff\xff\xff\xff\xc0\x5d\x6a\x05\x5b\x29\xdd\x83\xc5\x4e\x89\xe9\x6a\x02\x03\x0c\x24\x5b\x31\xd2\x66\xba\x12\x00\x8b\x39\xc1\xe7\x10\xc1\xef\x10\x81\xe9\xfe\xff\xff\xff\x8b\x45\x00\xc1\xe0\x10\xc1\xe8\x10\x89\xc3\x09\xfb\x21\xf8\xf7\xd0\x21\xd8\x66\x89\x45\x00\x83\xc5\x02\x4a\x85\xd2\x0f\x85\xcf\xff\xff\xff\xec\x37\x75\x5d\x7a\x05\x28\xed\x24\xed\x24\xed\x0b\x88\x7f\xeb\x50\x98\x38\xf9\x5c\x96\x2b\x96\x70\xfe\xc6\xff\xc6\xff\x9f\x32\x1f\x58\x1e\x00\xd3\x80" mu.mem_write(BASE, shellcode) mu.reg_write(UC_X86_REG_ESP, STACK_ADDR + STACK_SIZE-1) def hook_code(mu, address, size, user_data): # print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size)) code = mu.mem_read(address,size) # print(code) if code == b"\xcd\x80": print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size)) eax = mu.reg_read(UC_X86_REG_EAX) ebx = mu.reg_read(UC_X86_REG_EBX) ecx = mu.reg_read(UC_X86_REG_ECX) edx = mu.reg_read(UC_X86_REG_EDX) print("{}: {} {} {}".format(eax,ebx,ecx,edx)) if(eax == 15): file_name = bytes(mu.mem_read(ebx,32)).split(b'\x00')[0] print("file_name is {}".format(file_name)) mu.reg_write(UC_X86_REG_EIP, address+size) mu.hook_add(UC_HOOK_CODE, hook_code) mu.emu_start(BASE,BASE+len(shellcode))
sakura@ubuntu:~/unicorn$ python3 sc.py
>>> Tracing instruction at 0x40006b, instruction size = 0x2
15: 4194392 438 0
>>> Tracing instruction at 0x400070, instruction size = 0x2
1: 4194392 438 0打开系统调用的解释网站对照看一下。
https://syscalls.kernelgrok.com/

查了一下chmod命令可以使用八进制数来指定权限。所以438就是666,代表读写权限。
hex(4194392)->'0x400058',是一个指针,指向的是文件名的字符串,把这个字符串取出来就知道到底读的是什么文件了。
这里吐个槽python3的mu.mem_read(ebx,32)返回一个bytearray,需要先bytes(xx)转成bytes,浪费了我半小时,另外bytes split要用b'xxx'
>>> Tracing instruction at 0x40006b, instruction size = 0x2
15: 4194392 438 0
file_name is b'/etc/shadow'
>>> Tracing instruction at 0x400070, instruction size = 0x2
1: 4194392 438 0这样我们就知道这个shellcode其实是将/etc/shadow设置成可读可写。
task3
gcc function.c -m32 -o function.
调用super_function,返回的方式1。
int strcmp(char *a, char *b) { //get length int len = 0; char *ptr = a; while(*ptr) { ptr++; len++; } //comparestrings for(int i=0; i<=len; i++) { if (a[i]!=b[i]) return 1; } return 0; } __attribute__((stdcall)) int super_function(int a, char *b) { if (a==5 && !strcmp(b, "batman")) { return 1; } return 0; } int main() { super_function(1, "spiderman"); }
从前面的学习,我们已经学会了如何把程序加载进内存用unicorn仿真跑起来,和怎么用hook的方式去改变代码的执行流。
感觉解法很多...
分析一下题意,应该是指只调用super_function函数,而不执行代码的其他部分。

假设基地址是0x08048000,那么要执行的就是0x08048000+0x57b-0x08048000+0x5b1
然后考虑32位传参,先看一下栈帧结构。
图来自CSAPP第二版。

if (a==5 && !strcmp(b, "batman")) { return 1; }
从代码可以看出,传入的参数a和b的值应为5和"batman"
从汇编代码最后的Ret 8可以看出来被调用者平衡堆栈,显然是stdcall调用约定。
stdcall的调用约定意味着参数从右向左压入堆栈。
当我们开始执行super_function的时候,esp是指向返回地址的。
所以a的值在esp+4,b的值在esp+8。(不理解的看图)
然后返回值会保存在eax里。
import struct def read(name): with open(name,'rb') as f: return f.read() def u32(data): return struct.unpack("I", data)[0] def p32(num): return struct.pack("I", num) from unicorn import * from unicorn.x86_const import * mu = Uc(UC_ARCH_X86, UC_MODE_32) BASE = 0x8048000 STACK_ADDR = 0x0 STACK_SIZE = 1024*1024 mu.mem_map(BASE, 1024*1024) mu.mem_map(STACK_ADDR, STACK_SIZE) string_addr = 0x0 mu.mem_write(string_addr, b"batman\x00") str = mu.mem_read(string_addr,6) print(str) mu.mem_write(BASE, read("./function")) mu.reg_write(UC_X86_REG_ESP, STACK_ADDR + 1024) mu.mem_write(STACK_ADDR + 1024 + 4, p32(5)) mu.mem_write(STACK_ADDR + 1024 + 8, p32(string_addr)) def hook_code(mu, address, size, user_data): print ('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size)) print(mu.mem_read(address,size)) mu.hook_add(UC_HOOK_CODE, hook_code) mu.emu_start(BASE+0x57b,BASE+0x5b1) reg = mu.reg_read(UC_X86_REG_EAX) print(reg)

到这里我的unicorn学习就结束了,感觉大概熟悉了一下API和使用。
另外ghrida真的不好用。。我准备换回IDA了。
AFL-unicorn学习
先在sec.today上找一下资料

https://medium.com/hackernoon/afl-unicorn-fuzzing-arbitrary-binary-code-563ca28936bf
第一篇我就不赘述了,

稍微值得一提的就是这个图了,它使用AFL来mutate样本去生成数据,然后将数据读到一个固定的地址里,然后harness会从这个地址读取数据并运行要仿真的指令,如果出现crash,则模拟这个行为让harness崩溃,从而告知AFL crash发生,从而记录下crash样本。
harness基本上就是用了上面这些task里类似的方法去用unicorn把指令仿真执行起来,如下。
""" Simple test harness for AFL's Unicorn Mode. This loads the simple_target.bin binary (precompiled as MIPS code) into Unicorn's memory map for emulation, places the specified input into simple_target's buffer (hardcoded to be at 0x300000), and executes 'main()'. If any crashes occur during emulation, this script throws a matching signal to tell AFL that a crash occurred. Run under AFL as follows: $ cd <afl_path>/unicorn_mode/samples/simple/ $ ../../../afl-fuzz -U -m none -i ./sample_inputs -o ./output -- python simple_test_harness.py @@ """ import argparse import os import signal from unicorn import * from unicorn.mips_const import * # Path to the file containing the binary to emulate BINARY_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'simple_target.bin') # Memory map for the code to be tested CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded CODE_SIZE_MAX = 0x00010000 # Max size for the code (64kb) STACK_ADDRESS = 0x00200000 # Address of the stack (arbitrarily chosen) STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen) DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed DATA_SIZE_MAX = 0x00010000 # Maximum allowable size of mutated data try: # If Capstone is installed then we'll dump disassembly, otherwise just dump the binary. from capstone import * cs = Cs(CS_ARCH_MIPS, CS_MODE_MIPS32 + CS_MODE_BIG_ENDIAN) def unicorn_debug_instruction(uc, address, size, user_data): mem = uc.mem_read(address, size) for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size): print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr)) except ImportError: def unicorn_debug_instruction(uc, address, size, user_data): print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) def unicorn_debug_block(uc, address, size, user_data): print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size)) def unicorn_debug_mem_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE: print(" >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) else: print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size)) def unicorn_debug_mem_invalid_access(uc, access, address, size, value, user_data): if access == UC_MEM_WRITE_UNMAPPED: print(" >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value)) else: print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size)) def force_crash(uc_error): # This function should be called to indicate to AFL that a crash occurred during emulation. # Pass in the exception received from Uc.emu_start() mem_errors = [ UC_ERR_READ_UNMAPPED, UC_ERR_READ_PROT, UC_ERR_READ_UNALIGNED, UC_ERR_WRITE_UNMAPPED, UC_ERR_WRITE_PROT, UC_ERR_WRITE_UNALIGNED, UC_ERR_FETCH_UNMAPPED, UC_ERR_FETCH_PROT, UC_ERR_FETCH_UNALIGNED, ] if uc_error.errno in mem_errors: # Memory error - throw SIGSEGV os.kill(os.getpid(), signal.SIGSEGV) elif uc_error.errno == UC_ERR_INSN_INVALID: # Invalid instruction - throw SIGILL os.kill(os.getpid(), signal.SIGILL) else: # Not sure what happened - throw SIGABRT os.kill(os.getpid(), signal.SIGABRT) def main(): parser = argparse.ArgumentParser(description="Test harness for simple_target.bin") parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input to load") parser.add_argument('-d', '--debug', default=False, action="store_true", help="Enables debug tracing") args = parser.parse_args() # Instantiate a MIPS32 big endian Unicorn Engine instance uc = Uc(UC_ARCH_MIPS, UC_MODE_MIPS32 + UC_MODE_BIG_ENDIAN) if args.debug: uc.hook_add(UC_HOOK_BLOCK, unicorn_debug_block) uc.hook_add(UC_HOOK_CODE, unicorn_debug_instruction) uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, unicorn_debug_mem_access) uc.hook_add(UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, unicorn_debug_mem_invalid_access) #--------------------------------------------------- # Load the binary to emulate and map it into memory print("Loading data input from {}".format(args.input_file)) binary_file = open(BINARY_FILE, 'rb') binary_code = binary_file.read() binary_file.close() # Apply constraints to the mutated input if len(binary_code) > CODE_SIZE_MAX: print("Binary code is too large (> {} bytes)".format(CODE_SIZE_MAX)) return # Write the mutated command into the data buffer uc.mem_map(CODE_ADDRESS, CODE_SIZE_MAX) uc.mem_write(CODE_ADDRESS, binary_code) # Set the program counter to the start of the code start_address = CODE_ADDRESS # Address of entry point of main() end_address = CODE_ADDRESS + 0xf4 # Address of last instruction in main() uc.reg_write(UC_MIPS_REG_PC, start_address) #----------------- # Setup the stack uc.mem_map(STACK_ADDRESS, STACK_SIZE) uc.reg_write(UC_MIPS_REG_SP, STACK_ADDRESS + STACK_SIZE) #----------------------------------------------------- # Emulate 1 instruction to kick off AFL's fork server # THIS MUST BE DONE BEFORE LOADING USER DATA! # If this isn't done every single run, the AFL fork server # will not be started appropriately and you'll get erratic results! # It doesn't matter what this returns with, it just has to execute at # least one instruction in order to get the fork server started. # Execute 1 instruction just to startup the forkserver print("Starting the AFL forkserver by executing 1 instruction") try: uc.emu_start(uc.reg_read(UC_MIPS_REG_PC), 0, 0, count=1) except UcError as e: print("ERROR: Failed to execute a single instruction (error: {})!".format(e)) return #----------------------------------------------- # Load the mutated input and map it into memory # Load the mutated input from disk print("Loading data input from {}".format(args.input_file)) input_file = open(args.input_file, 'rb') input = input_file.read() input_file.close() # Apply constraints to the mutated input if len(input) > DATA_SIZE_MAX: print("Test input is too long (> {} bytes)".format(DATA_SIZE_MAX)) return # Write the mutated command into the data buffer uc.mem_map(DATA_ADDRESS, DATA_SIZE_MAX) uc.mem_write(DATA_ADDRESS, input) #------------------------------------------------------------ # Emulate the code, allowing it to process the mutated input print("Executing until a crash or execution reaches 0x{0:016x}".format(end_address)) try: result = uc.emu_start(uc.reg_read(UC_MIPS_REG_PC), end_address, timeout=0, count=0) except UcError as e: print("Execution failed with error: {}".format(e)) force_crash(e) print("Done.") if __name__ == "__main__": main()
看一下第二篇
https://hackernoon.com/afl-unicorn-part-2-fuzzing-the-unfuzzable-bea8de3540a5
task1 FSK_Messaging_Service
第二篇以一个相对具体的例子,将afl-unicorn的使用场景从不到30行的case扩展到了一个CGC CTF题
FSK_Messaging_Service
题目描述是这样的:这是一项服务,该服务实现了具有分组FSK解调前端,分组解码,处理以及最终将其解析为简单Messenger服务的分组无线接收器。
step0
安装afl-unicorn
cd /path/to/afl-unicorn
make
sudo make install
cd unicorn_mode
sudo ./build_unicorn_support.sh另外这里还有个坑,如果你在18.04系统上不能运行起来它,可以试试16.04,这卡了我几个小时。
step1
首要的工作是对要fuzz的代码进行理解,也就是说理清楚要fuzz的起点和终点,需要构造的输入是什么?输入是如何传递进去的,输入上有哪些约束,比如最大最短长度,是否需要满足某个具体的算式,这个约束是不变的还是动态的。

虽然我其实不太看得懂这些东西,但是粗略的理解来说就是如果直接构造输入喂进去,那么会卡在Demodulation Logic部分,永远无法正确的突破。
可以粗略的理解成,如果你用AFL去fuzz js引擎,那它几乎不太可能去生成有效的js语法,会卡在语法parser那里,举个例子,for进行一轮字节变异成aor,能通过才见鬼了。
而通过AFL-unicorn我们可以直接过掉前面这部分代码,直接将Message Packet Parsing Logic作为Harness,把Packets作为原始输入去fuzz。
但其实看到这里,Packet的构造还是存在一定问题的,首先即使这个Packet喂进去了造成Crash,如何从更上层输入去构造出这个Packet,会不会有更上层的过滤导致永远不可能构造出来这个Packet,这都是很容易考虑到的问题,不过这里暂时略过这个问题往下看吧。
从Packets做输入,那么关键代码就在packet.c里,
https://github.com/trailofbits/cb-multios/blob/master/challenges/FSK_Messaging_Service/src/packet.c
选择要fuzz的函数是cgc_receive_packet

函数的基本功能如下:
- 校验packet buffer不为空且长度大于0
- 计算16位CRC校验和以验证数据包的内容
- 循环检查packet type,如果匹配,则调用cgc_add_new_packet实例化tSinglePacketData对象pNewPacket,并向其中memcpy来自原始数据包的信息。
现在我们开始考虑参数和约束
void cgc_receive_packet( uint8_t *pData, uint8_t dataLen, uint16_t packetCRC )
pData是指向数据包的指针,dataLen是其长度,packetCRC是16位CRC校验和。
显而易见的约束是CRC要正确。
// Perform Checksum check uint16_t check_checksum = cgc_simple_checksum16( pData, dataLen ); // Validate Checksum if ( packetCRC != check_checksum ) return;
step2
其实看到这里就感觉没必要继续看下去了,价值很有限了。
简单地说接下来的工作是要dump出有效的进程上下文,这个原因十分简单,在之前我们学习Unicorn的时候就遇到了很多问题,有很多运行时才会分配的内存区域,比如堆分配、栈指针、全局变量这些东西。
但是说到底……我要是能把固件跑起来,我还要你这个仿真干嘛
问题就在这里了,所以我感觉除了极小量级的代码可能还能用一下,越是复杂,接口不规范的东西,越是不可能用这个东西跑起来了。
但权做学习吧。
afl-unicorn的helper tools
https://github.com/Battelle/afl-unicorn/blob/master/unicorn_mode/helper_scripts/unicorn_dumper_ida.py
IDA的版本要求<7,我试一下gdb版的能不能用。
https://github.com/Battelle/afl-unicorn/blob/master/unicorn_mode/helper_scripts/unicorn_dumper_gdb.py
选择在此处断下,此时eax中存放pData,edx(dl)里存放dataLen

在此处dump进程上下文。
我在这卡住了,因为我想了想我好像并不知道该怎么hit到cgc_receive_packet的代码,在进行了"繁琐"的逆向工程之后。
我找到了作者的issue。
https://github.com/Battelle/afl-unicorn/issues/9
它给了一个patch用来生成有效输入。
./pov > case
sakura@ubuntu:~/unicorn/cb-multios/build/challenges/FSK_Messaging_Service$ ./FSK_Messaging_Service < case
[[RECEIVER STARTED -- TIMESTAMP: 1453110580]]
Total 12 bytes received and 0 invalid packets.
Displaying 2 received packets:
Displaying packet 0 type 3:
[CONNECT MESSAGE]ASDF connected
Displaying packet 1 type 3:
[CONNECT MESSAGE]ASDF connected差不多效果这样。
然后开始dump上下文了。
sakura@ubuntu:~/unicorn$ gdb ./FSK_Messaging_Service
Reading symbols from ./FSK_Messaging_Service...done.
gef➤ b *0x804D106
Breakpoint 1 at 0x804d106: file /home/sakura/unicorn/cb-multios/challenges/FSK_Messaging_Service/src/baseband.c, line 330.
gef➤ x/5i 0x804D106
0x804d106 <cgc_do_sample+854>: mov DWORD PTR [esp],eax
0x804d109 <cgc_do_sample+857>: movzx eax,dl
0x804d10c <cgc_do_sample+860>: mov DWORD PTR [esp+0x4],eax
0x804d110 <cgc_do_sample+864>: movzx eax,WORD PTR [ecx+0x126]
0x804d117 <cgc_do_sample+871>: mov DWORD PTR [esp+0x8],eax
gef➤ r < case
Starting program: /home/sakura/unicorn/FSK_Messaging_Service < case
[[RECEIVER STARTED -- TIMESTAMP: 1453110580]]
[ Legend: Modified register | Code | Heap | Stack | String ]
───────────────────────────────────────────────────────────── registers ────
$eax : 0xffffd3c6 → 0x53410403
$ebx : 0x0
$ecx : 0xffffd3a0 → 0xf7fd0002 → 0x306cf7fd
$edx : 0xffffd306 → 0x00000000
$esp : 0xffffd1e0 → 0xcccccccd
$ebp : 0xffffd208 → 0xffffd238 → 0xffffd258 → 0xffffd4d8 → 0x00000000
$esi : 0xc0d2
$edi : 0x0
$eip : 0x0804d106 → <cgc_do_sample+854> mov DWORD PTR [esp], eax
$eflags: [zero carry PARITY adjust SIGN trap INTERRUPT direction overflow resume virtualx86 identification]
$cs: 0x0023 $ss: 0x002b $ds: 0x002b $es: 0x002b $fs: 0x0000 $gs: 0x0063
───────────────────────────────────────────────────────────────── stack ────
0xffffd1e0│+0x0000: 0xcccccccd ← $esp
0xffffd1e4│+0x0004: 0x40308ccc
0xffffd1e8│+0x0008: 0x00000000
0xffffd1ec│+0x000c: 0x40310000
0xffffd1f0│+0x0010: 0x00000000
0xffffd1f4│+0x0014: 0x40080000
0xffffd1f8│+0x0018: 0x04000000
0xffffd1fc│+0x001c: 0x00000000
─────────────────────────────────────────────────────────── code:x86:32 ────
0x804d0fd <cgc_do_sample+845> mov ecx, DWORD PTR [ebp+0x8]
0x804d100 <cgc_do_sample+848> mov dl, BYTE PTR [ecx+0x23]
0x804d103 <cgc_do_sample+851> mov ecx, DWORD PTR [ebp+0x8]
→ 0x804d106 <cgc_do_sample+854> mov DWORD PTR [esp], eax
0x804d109 <cgc_do_sample+857> movzx eax, dl
0x804d10c <cgc_do_sample+860> mov DWORD PTR [esp+0x4], eax
0x804d110 <cgc_do_sample+864> movzx eax, WORD PTR [ecx+0x126]
0x804d117 <cgc_do_sample+871> mov DWORD PTR [esp+0x8], eax
0x804d11b <cgc_do_sample+875> call 0x804d9f0 <cgc_receive_packet>
───────────────────────────────────── source:/home/sakura/un[...].c+330 ────
325 #if DEBUG_BASEBAND
326 cgc_printf( "Packet RX[$d][$X]\n", pState->packetState.packetDataLen, pState->packetState.packetCRC );
327 #endif
328
329 // Packet received! -- send to packet processing
// pState=0xffffd210 → [...] → 0x306cf7fd
→ 330 cgc_receive_packet( pState->packetState.packetData, pState->packetState.packetDataLen, pState->packetState.packetCRC );
331
332 // Reset
333 cgc_reset_baseband_state( pState );
334 }
335 }
─────────────────────────────────────────────────────────────── threads ────
[#0] Id 1, Name: "FSK_Messaging_S", stopped 0x804d106 in cgc_do_sample (), reason: BREAKPOINT
───────────────────────────────────────────────────────────────── trace ────
[#0] 0x804d106 → cgc_do_sample(pState=0xffffd3a0, sample_in=0x0)
[#1] 0x804ccbb → cgc_run_cdr(pState=0xffffd3a0, in_sample=0x0)
[#2] 0x804ca25 → cgc_process_sample(pState=0xffffd3a0, in_sample=0x0)
[#3] 0x804e6cd → main(secret_page_i=0x4347c000, unused=0xffffd574)
────────────────────────────────────────────────────────────────────────────
Breakpoint 1, 0x0804d106 in cgc_do_sample (pState=0xffffd3a0, sample_in=0x0) at /home/sakura/unicorn/cb-multios/challenges/FSK_Messaging_Service/src/baseband.c:330
330 cgc_receive_packet( pState->packetState.packetData, pState->packetState.packetDataLen, pState->packetState.packetCRC );
gef➤
gef➤ source unicorn_dumper_gdb.py
----- Unicorn Context Dumper -----
You must be actively debugging before running this!
If it fails, double check that you are actively debugging before running.
Process context will be output to UnicornContext_20200405_045024
Dumping segment @0x0000000008048000 (size:0x7000): /home/sakura/unicorn/FSK_Messaging_Service [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x000000000804f000 (size:0x1000): /home/sakura/unicorn/FSK_Messaging_Service [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x0000000008050000 (size:0x22000): [heap] [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x000000004347c000 (size:0x1000): [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x00000000f7dbd000 (size:0x1d5000): /lib/i386-linux-gnu/libc-2.27.so [{'r': True, 'w': False, 'x': True}]
Skipping segment /lib/i386-linux-gnu/libc-2.27.so@0x00000000f7f92000
Dumping segment @0x00000000f7f93000 (size:0x2000): /lib/i386-linux-gnu/libc-2.27.so [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7f95000 (size:0x1000): /lib/i386-linux-gnu/libc-2.27.so [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x00000000f7f96000 (size:0x3000): [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x00000000f7fc5000 (size:0x1000): [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x00000000f7fc6000 (size:0x3000): /home/sakura/unicorn/cb-multios/build/include/tiny-AES128-C/libtiny-AES128-C.so [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7fc9000 (size:0x1000): /home/sakura/unicorn/cb-multios/build/include/tiny-AES128-C/libtiny-AES128-C.so [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7fca000 (size:0x1000): /home/sakura/unicorn/cb-multios/build/include/tiny-AES128-C/libtiny-AES128-C.so [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x00000000f7fcb000 (size:0x3000): /home/sakura/unicorn/cb-multios/build/include/libcgc.so [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7fce000 (size:0x1000): /home/sakura/unicorn/cb-multios/build/include/libcgc.so [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7fcf000 (size:0x1000): /home/sakura/unicorn/cb-multios/build/include/libcgc.so [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x00000000f7fd0000 (size:0x2000): [{'r': True, 'w': True, 'x': True}]
Exception reading segment ([vvar]): <class 'gdb.MemoryError'>
Dumping segment @0x00000000f7fd5000 (size:0x1000): [vdso] [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7fd6000 (size:0x26000): /lib/i386-linux-gnu/ld-2.27.so [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7ffc000 (size:0x1000): /lib/i386-linux-gnu/ld-2.27.so [{'r': True, 'w': False, 'x': True}]
Dumping segment @0x00000000f7ffd000 (size:0x1000): /lib/i386-linux-gnu/ld-2.27.so [{'r': True, 'w': True, 'x': True}]
Dumping segment @0x00000000fffdd000 (size:0x21000): [stack] [{'r': True, 'w': True, 'x': True}]
Done.大概这样。
粗略看了一下dump程序,基本上就是调用了gef的get_process_maps接口,然后依次把每个segment的内存保存下来和调用get_register接口保存寄存器信息。
step3
接下来就开始编写harness了。
其实用c来写比python效率要快很多,但是为了快速学习,这里就用python搞一下。
整体的Harness的流程就是:
- 创建和分配memory map
- 加载target程序到memory map
- 仿真执行至少一条指令(hack trick)
- 从afl获取data和size用以fuzz
- 设置初始状态,即进程上下文
- 仿真代码,并正确处理crash
基本上每个harness都是这样,对着往里面填模板就好了。
这里的unicorn_loader在这。
用处就是把我们之前dump出来的context加载进去。
import argparse from unicorn import * from unicorn.x86_const import * # TODO: Set correct architecture here as necessary import unicorn_loader # Simple stand-in heap to prevent OS/kernel issues unicorn_heap = None # Start and end address of emulation START_ADDRESS = # TODO: Set start address here END_ADDRESS = # TODO: Set end address here """ Implement target-specific hooks in here. Stub out, skip past, and re-implement necessary functionality as appropriate """ def unicorn_hook_instruction(uc, address, size, user_data): # TODO: Setup hooks and handle anything you need to here # - For example, hook malloc/free/etc. and handle it internally pass #------------------------ #---- Main test function def main(): parser = argparse.ArgumentParser() parser.add_argument('context_dir', type=str, help="Directory containing process context") parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input content") parser.add_argument('-d', '--debug', default=False, action="store_true", help="Dump trace info") args = parser.parse_args() print("Loading context from {}".format(args.context_dir)) uc = unicorn_loader.AflUnicornEngine(args.context_dir, enable_trace=args.debug, debug_print=False) # Instantiate the hook function to avoid emulation errors global unicorn_heap unicorn_heap = unicorn_loader.UnicornSimpleHeap(uc, debug_print=True) uc.hook_add(UC_HOOK_CODE, unicorn_hook_instruction) # Execute 1 instruction just to startup the forkserver # NOTE: This instruction will be executed again later, so be sure that # there are no negative consequences to the overall execution state. # If there are, change the later call to emu_start to no re-execute # the first instruction. print("Starting the forkserver by executing 1 instruction") try: uc.emu_start(START_ADDRESS, 0, 0, count=1) except UcError as e: print("ERROR: Failed to execute a single instruction (error: {})!".format(e)) return # Allocate a buffer and load a mutated input and put it into the right spot if args.input_file: print("Loading input content from {}".format(args.input_file)) input_file = open(args.input_file, 'rb') input_content = input_file.read() input_file.close() # TODO: Apply constraints to mutated input here raise exceptions.NotImplementedError('No constraints on the mutated inputs have been set!') # Allocate a new buffer and put the input into it buf_addr = unicorn_heap.malloc(len(input_content)) uc.mem_write(buf_addr, input_content) print("Allocated mutated input buffer @ 0x{0:016x}".format(buf_addr)) # TODO: Set the input into the state so it will be handled raise exceptions.NotImplementedError('The mutated input was not loaded into the Unicorn state!') # Run the test print("Executing from 0x{0:016x} to 0x{1:016x}".format(START_ADDRESS, END_ADDRESS)) try: result = uc.emu_start(START_ADDRESS, END_ADDRESS, timeout=0, count=0) except UcError as e: # If something went wrong during emulation a signal is raised to force this # script to crash in a way that AFL can detect ('uc.force_crash()' should be # called for any condition that you want AFL to treat as a crash). print("Execution failed with error: {}".format(e)) uc.dump_regs() uc.force_crash(e) print("Final register state:") uc.dump_regs() print("Done.") if __name__ == "__main__": main()
整体浏览一下,TODO的地方不多,加载context之类的工作,比如之前我们学习unicorn时候要做的很多分配栈地址之类的,都已经在unicorn_loader里给通过load我们之前dump出的context来自动完成了,简单快捷。
那么把每处TODO大概看看
- TODO: Apply constraints to mutated input here
我感觉没必要额外加什么约束,直接注释掉raise。 - TODO: Set the input into the state so it will be handled
我们要fuzz的函数的参数此时都存在寄存器里,所以直接改掉寄存器的值就好。 - TODO: Set start/end address here
这个就是我们刚刚断下来的地址就是起始地址,要fuzz的函数结束的地方就是终止地址。

- TODO: Setup hooks and handle anything you need to here
最麻烦的地方,和之前学习unicorn一样,有些指令还是要单独hook的。
另外就是之前说的,这个函数要先检查crc校验和,这个参数我们没做控制,直接把那个检查hook了然后跳过。
hook crc校验和

hook malloc,好处是我们可以自己实现自己的Guard Page,从而在越界读写的时候立刻crash。


hook free

hook printf

hook cgc_transmit

import struct def read(name): with open(name,'rb') as f: return f.read() def u32(data): return struct.unpack("I", data)[0] def p32(num): return struct.pack("I", num) import argparse from unicorn import * from unicorn.x86_const import * # TODO: Set correct architecture here as necessary import unicorn_loader # Simple stand-in heap to prevent OS/kernel issues unicorn_heap = None # Start and end address of emulation START_ADDRESS = 0x0804D106 # TODO: Set start address here END_ADDRESS = 0x0804D120 # TODO: Set end address here # Address where checksum is checked and where it goes if it is valid CHKSUM_CMP_ADDR = 0x0804DA45 CHKSUM_PASSED_ADDR = 0x0804DA52 # Entry points of addresses of functions to hook MALLOC_ENTRY = 0x08049C40 FREE_ENTRY = 0x08049980 PRINTF_ENTRY = 0x0804AA60 CGC_TRANSMIT_ENTRY = 0x0804A4C2 CGC_TRANSMIT_PASSED = 0x0804A4DC """ Implement target-specific hooks in here. Stub out, skip past, and re-implement necessary functionality as appropriate """ def unicorn_hook_instruction(uc, address, size, user_data): if address == MALLOC_ENTRY: print("--- Rerouting call to malloc() @ 0x{0:08x} ---".format(address)) size = struct.unpack("<I", uc.mem_read(uc.reg_read(UC_X86_REG_ESP) + 4, 4))[0] retval = unicorn_heap.malloc(size) uc.reg_write(UC_X86_REG_EAX, retval) uc.reg_write(UC_X86_REG_EIP, struct.unpack("<I", uc.mem_read(uc.reg_read(UC_X86_REG_ESP), 4))[0]) uc.reg_write(UC_X86_REG_ESP, uc.reg_read(UC_X86_REG_ESP) + 4) # Bypass these functions by jumping straight out of them - We can't (or don't want to) emulate them elif address == FREE_ENTRY or address == PRINTF_ENTRY: print("--- Bypassing a function call that we don't want to emulate @ 0x{0:08x} ---".format(address)) uc.reg_write(UC_X86_REG_EIP, struct.unpack("<I", uc.mem_read(uc.reg_read(UC_X86_REG_ESP), 4))[0]) uc.reg_write(UC_X86_REG_ESP, uc.reg_read(UC_X86_REG_ESP) + 4) # Bypass the checksum check elif address == CHKSUM_CMP_ADDR: print("--- Bypassing checksum validation @ 0x{0:08x} ---".format(address)) uc.reg_write(UC_X86_REG_EIP, CHKSUM_PASSED_ADDR) # Bypass the CGC_TRANSMIT_ENTRY check elif address == CGC_TRANSMIT_ENTRY: print("--- Bypassing CGC_TRANSMIT_ENTRY validation @ 0x{0:08x} ---".format(address)) uc.reg_write(UC_X86_REG_EIP, CGC_TRANSMIT_PASSED) elif address == START_ADDRESS: print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' %(address, size)) print(mu.mem_read(address,size)) # TODO: Setup hooks and handle anything you need to here # - For example, hook malloc/free/etc. and handle it internally pass #------------------------ #---- Main test function def main(): parser = argparse.ArgumentParser() parser.add_argument('context_dir', type=str, help="Directory containing process context") parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input content") parser.add_argument('-d', '--debug', default=False, action="store_true", help="Dump trace info") args = parser.parse_args() print("Loading context from {}".format(args.context_dir)) uc = unicorn_loader.AflUnicornEngine(args.context_dir, enable_trace=args.debug, debug_print=False) # Instantiate the hook function to avoid emulation errors global unicorn_heap unicorn_heap = unicorn_loader.UnicornSimpleHeap(uc, debug_print=True) uc.hook_add(UC_HOOK_CODE, unicorn_hook_instruction) # Execute 1 instruction just to startup the forkserver # NOTE: This instruction will be executed again later, so be sure that # there are no negative consequences to the overall execution state. # If there are, change the later call to emu_start to no re-execute # the first instruction. print("Starting the forkserver by executing 1 instruction") try: uc.emu_start(START_ADDRESS, 0, 0, count=1) except UcError as e: print("ERROR: Failed to execute a single instruction (error: {})!".format(e)) return # Allocate a buffer and load a mutated input and put it into the right spot if args.input_file: print("Loading input content from {}".format(args.input_file)) input_file = open(args.input_file, 'rb') input_content = input_file.read() input_file.close() # TODO: Apply constraints to mutated input here if len(input_content) > 0xFF: return # raise exceptions.NotImplementedError('No constraints on the mutated inputs have been set!') # Allocate a new buffer and put the input into it buf_addr = unicorn_heap.malloc(len(input_content)) uc.mem_write(buf_addr, input_content) print("Allocated mutated input buffer @ 0x{0:016x}".format(buf_addr)) # TODO: Set the input into the state so it will be handled #raise exceptions.NotImplementedError('The mutated input was not loaded into the Unicorn state!') uc.reg_write(UC_X86_REG_EAX, buf_addr) uc.reg_write(UC_X86_REG_DL, len(input_content)) # Run the test print("Executing from 0x{0:016x} to 0x{1:016x}".format(START_ADDRESS, END_ADDRESS)) try: result = uc.emu_start(START_ADDRESS, END_ADDRESS, timeout=0, count=0) except UcError as e: # If something went wrong during emulation a signal is raised to force this # script to crash in a way that AFL can detect ('uc.force_crash()' should be # called for any condition that you want AFL to treat as a crash). print("Execution failed with error: {}".format(e)) uc.dump_regs() uc.force_crash(e) print("Final register state:") uc.dump_regs() print("Done.") if __name__ == "__main__": main()
step4
运行fuzz
需要唯一些输入进去。
那就random一些就好了。
# -*- coding: utf-8 -*- import os, random def main(): for i in range(50): size = random.randint(20, 50) os.system(f'dd if=/dev/urandom of=testcase/testcase_{i} count=2 bs={size}') if __name__ == '__main__': main()
/home/sakura/unicorn/afl-unicorn/afl-fuzz -U -m none -i /home/sakura/unicorn/testcase/ -o /home/sakura/unicorn/fuzz_out/ -- python harness.py /home/sakura/unicorn/UnicornContext_20200405_045024/ @@
crash很多,跑了大概几秒钟,大概打开看看,定位一下漏洞点。


但问题来了,没有栈回溯,我怎么定位到漏洞点。

我简单的排查了一下,因为这道题的代码量并不大,尤其是我hook的代码并不多,所以我可以trace每条指令,和执行时它的一些关键信息。
而这里比较简单的就是我review了一下memcpy的交叉引用,然后在new_packet里面找到了我要的。
因为我是打印了执行流的,我看了一下地址


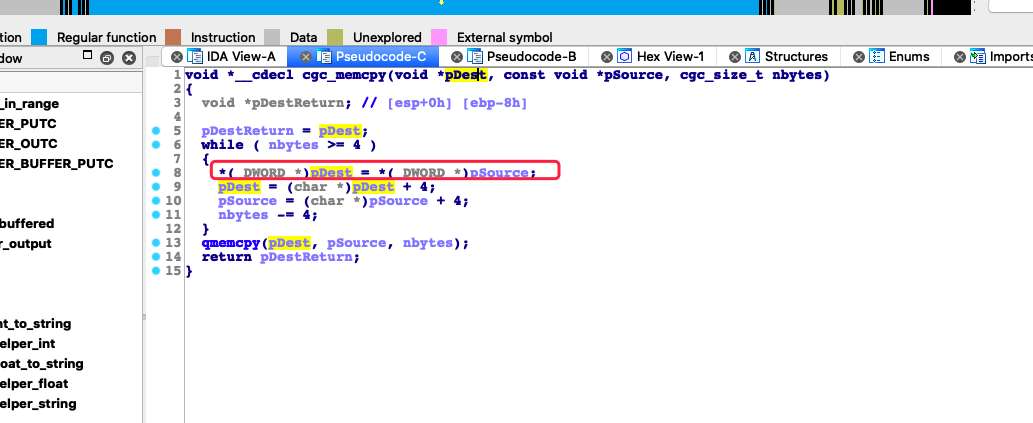
在我检索之后发现log里有call cgc_memcpy,并且里没有trace到它的下一条指令0x000000000804db8e

到这里基本上就可以知道漏洞点了。

简单的思考一下,pNewPacket的buf大小是0x40,也就是64字节。

但是很显然,在cgc_receive_packet里是根本没有对其进行dataLen的校验的。换而言之,

这里cgc_g_packetHandlers是一个全局变量,用处大概是填充诸多类型的packetType用来进行check。
而只需要在pData第一个字节构造好type类型,就可以进入add_new_packet函数里,并造成一个oob write了。
总结
afl-unicorn的局限性在于,它和unicorn一样,在你模拟执行的时候,必须hook一些函数来让它正常运行,为了尽可能简单的来模拟环境,你可能还需要去运行固件并dump内存上下文,这有时是困难的,起码我在刚开始研究afl-unicorn时候的初衷是因为我有一些东西不能直接跑起来。
此外在trace crash路径的时候,虽然我是逐指令hook的,但是事实上这样在遇到一些循环之类的时候会造成log爆炸的增长,我相信你不会想看到这种东西的。
所以还需要根据实际情况去hook需要hook的代码。
我已经很久没做任何逆向了,不过我有很多感兴趣的目标,我需要掌握的更多。
后续我可能还会再更新一篇关于afl-unicorn源码的笔记,不过可能会比较简单,因为我不是那种非常注意细节的人,我只关心我应该怎么改才能让我的工作跑起来。
这个系列不出意外我会长期更新,并会在适当的时候写一些我曾经使用过的,挖掘到了高质量浏览器漏洞的fuzz的内容,事实上都非常简单和有趣。
先知的代码缩进好像有点问题,不过所有使用到的代码都在这里可以找到
Reference
http://eternal.red/2018/unicorn-engine-tutorial/
https://hackernoon.com/afl-unicorn-part-2-fuzzing-the-unfuzzable-bea8de3540a5
如有侵权请联系:admin#unsafe.sh