
阅读: 1
GoAhead是开源的web框架,由于其高性能,高可用性,在嵌入式系统中广泛使用。传统基于GoAhead框架开发的服务端会大量使用ASP脚本语言编写动态页面,并使用C/C++语言编写功能函数注册到脚本层中供ASP脚本调用。为了更全面的进行安全审计,我们不仅要关注功能函数的实现,同时也要分析ASP脚本的处理过程。本篇文章以某个交换机固件来作为例子,讲解如何提取ASP文件。
GoAhead版本
在分析带有GoAhead的固件之前,需要先知道该框架的版本,这样除了能知道历史漏洞(CVE编号)外,还能对着该版本的源码进行分析,快速定位到关键点。
获取版本
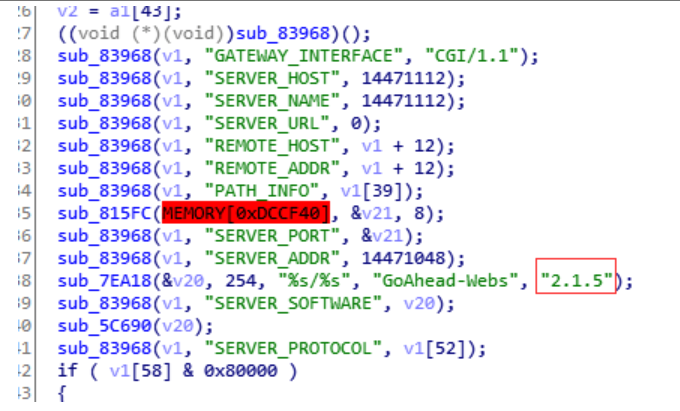
简单搜索字符串“GoAhead”可以非常快地定位到版本号,可以看到下面的版本号为2.1.5。
下载源码
由于GoAhead源码已经不在GitHub上维护了,官网的历史版本又只对企业用户开放,所以没法从官方渠道获取源码。
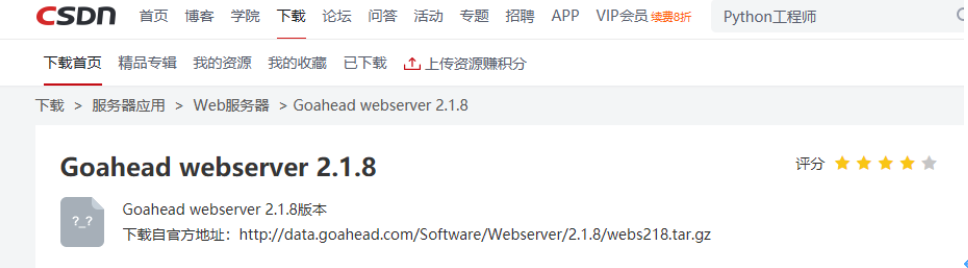
不过可以从之前网友共享的资源入手,来获取到这部分源码,最后在CSDN上下载了一个相近的版本2.1.8。
ASP文件
GoAhead Webserver支持类ASP的服务器端脚本语言,该脚本的语法和微软的ASP Active Server Page)语法基本相同,通过使用ASP脚本可以非常高效得开发动态页面。如下就是一个非常典型的ASP代码,可以看到ASP代码是嵌入” “<%…%>”之间的部分,其中的testasp函数的实现是在C/C++层中。
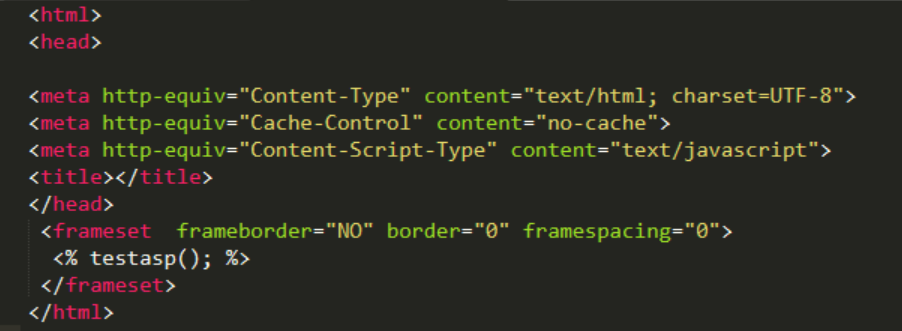
GoAhead为了更加方便的移植到不同嵌入系统上,其对文件的存储提供了非常灵活的方式,对于Linux这类系统,可以选择将文件存放在文件系统中,或者对于eCOS这类系统可以将文件直接以数组的形式直接固化到固件中,从而不必增加文件系统这部分模块。源码中的“WEBS_PAGE_ROM”宏就是控制不同的ASP文件存放方式。当定义了WEBS_PAGE_ROM意味着将文件以数组的形式存放在固件中。
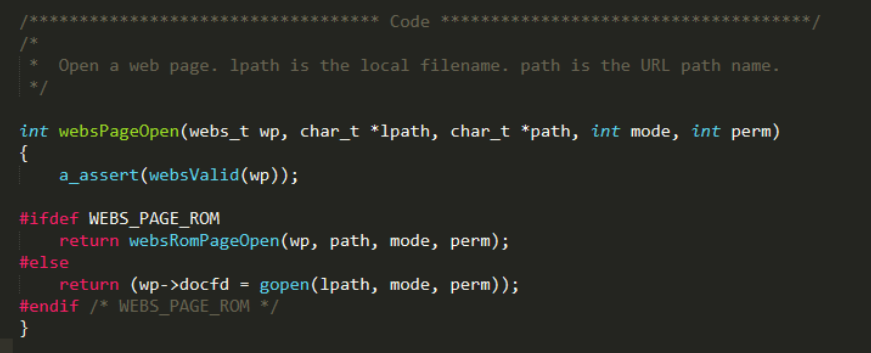
- 对于存放到文件系统的ASP脚本文件,可以直接用binwalk提取,然后分析其代码逻辑。
- 对于固化到固件中的ASP脚本文件,binwalk往往提取不了,或者说提取不完全,这就需要自己手动提取这类文件。
存放格式
为了了解ASP文件的存放格式,首先得知道如何将文件传成数组:
- 建立清单文件files.txt,在里面编写需要转换文件路径:
D:/web/css/style.css D:/web/home.asp D:/web/images/button.jpg //略 |
- 运行如下命令,将文件转换为数组:
webcomp D:/web files.txt >romfiles.c
- 打开romfiles.c可以看到全局变量文件索引表websRomPageIndex:

Page就是转换后的数组:
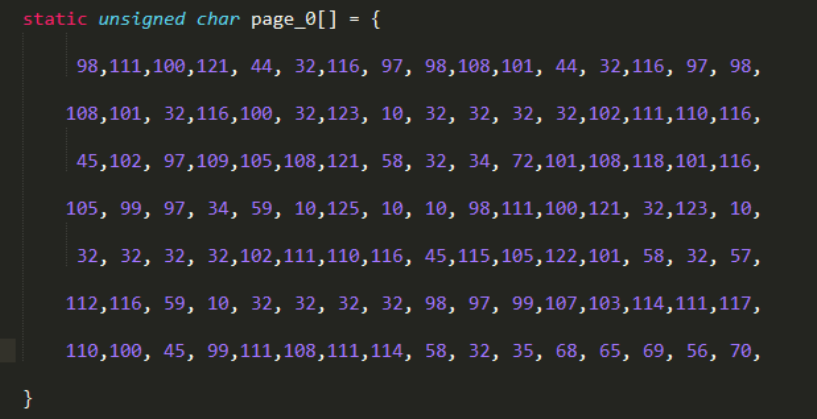
同时可以查看websRomPageIndexType结构,定义如下,为了提取所有表中的文件,需要定位到固件中websRomPageIndex的地址,然后编写脚本根据格式进行提取。
定位索引表
特征定位
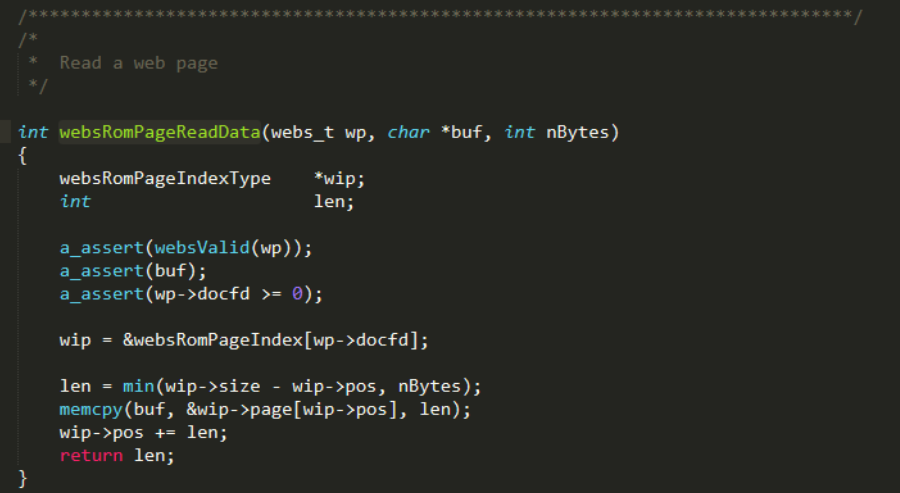
回到GoAhead源码,为了定位websRomPageIndex全局表,需要找到调用它的地方,websRomPageReadData函数使用了这个表,该函数负责将文件数据拷贝到指定的缓冲区。
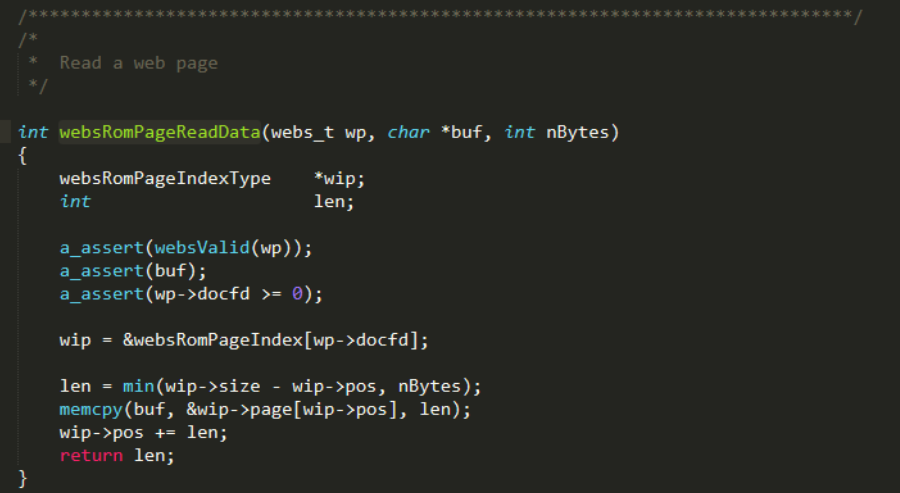
继续查看调用websRomPageReadData函数的地方,直到找到特征字符串(用于定位函数),最后找到了一个函数websAspRequest,非常适合定位。通过”Can’t read %s”字符串可以快速在固件中找到这个函数。
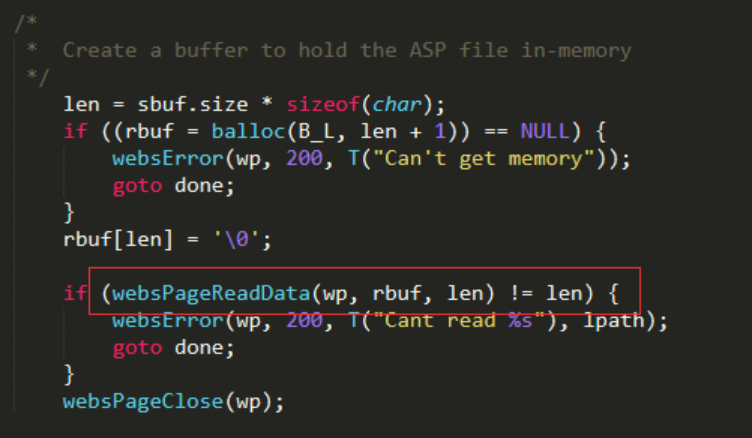
定位流程
最后简单总结了下定位流程:
动手实践
固件中定位表
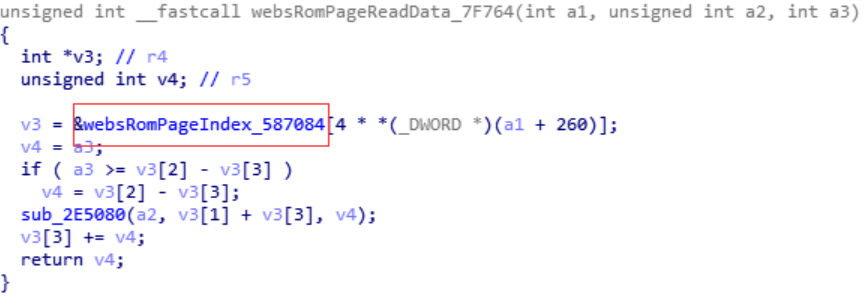
通过字符串定位到websPageReadData函数,如下框起来的就是该函数:

继续进入函数分析,找到websRomPageIndex全局表:
编写脚本
已经在固件中定位到websRomPageIndex全局表的位置,编写如下脚本提取文件数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
#extract files from GoAhead ROM from struct import * import os def get_str(data,index): ret='' i=index while data[i]!='\x00': ret+=data[i] i+=1 return ret websRomPageIndex_addr=0x547084 load_base=0x40000 with open('test.bin','rb') as fd: data=fd.read() s_pos=websRomPageIndex_addr while True: path_addr=unpack('I',data[s_pos:s_pos+4])[0] if path_addr==0x0: break path=get_str(data,path_addr-load_base) print path page_addr=unpack('I',data[s_pos+4:s_pos+4+4])[0] page_size=unpack('I',data[s_pos+8:s_pos+8+4])[0] page_data=data[page_addr-load_base:page_addr-load_base+page_size] path='./aspfile/'+path outpath,outfilename = os.path.split(path) if not os.path.exists(outpath): os.makedirs(outpath) with open(path,'wb+') as fd: fd.write(page_data) s_pos+=16 |
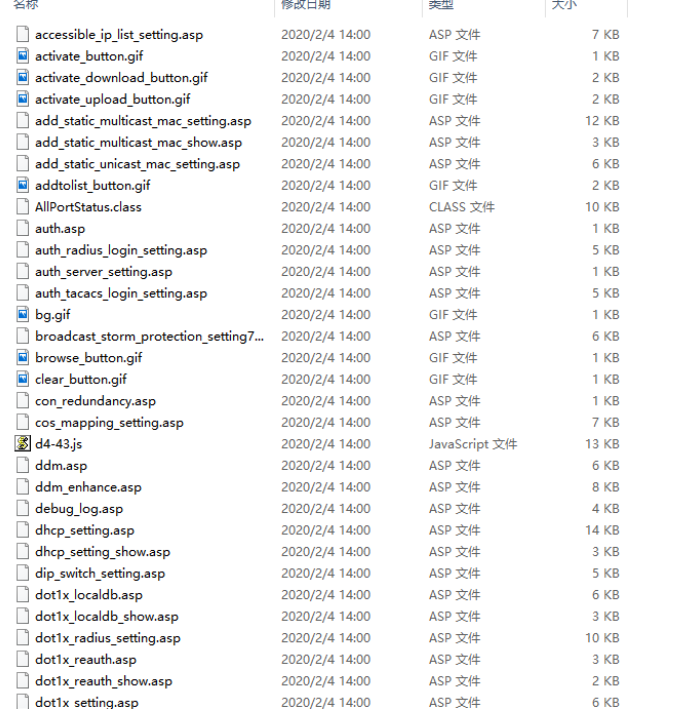
提取的文件如下所示:
总结
本篇主要介绍了提取ASP文件的一些思路,可以看到,提取方法虽然不难,但是分析过程还是需要一定的耐心。在提取ASP文件后,通过查看其源码,就能定位到一些存在于ASP脚本中的安全问题,审计方法和传统web审计方法类似,这里就不再赘述了。
作者:工业物联网安全实验室 陈杰