2024-7-3 17:0:30 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Table of Links
- Abstract and Introduction
- Related work
- The WildlifeDatasets toolkit
- MegaDescriptor – Methodology
- Ablation studies
- Performance evaluation
- Conclusion and References
6. Performance evaluation
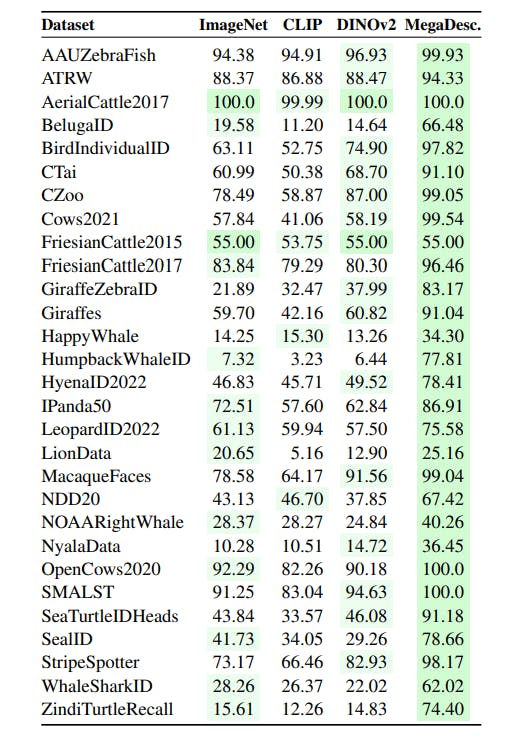
Insights from our ablation studies led to the creation of MegaDescriptors – the Swin-transformer-based models optimized with ArcFace loss and optimal hyperparameters using all publicly available animal re-id datasets.
In order to verify the expected outcomes, we perform a similar comparison as in metric learning vs. Local features ablation, and we compare the MegaDescriptor with CLIP (ViT-L/p14-336), ImageNet-1k (Swin-B/p4-w7-224), and DINOv2 (ViT-L/p14-518) pre-trained models. The proposed MegaDescriptor with Swin-L/p4-w12-384 backbone performs consistently on all datasets and outperforms all methods in on all 29 datasets. Notably, the state-of-the-art foundation model for almost any vision task – DINOv2 – with a much higher input size (518 × 518) and larger backbone performs poorly in animal re-identification.


6.1. Seen and unseen domain performance
This section illustrates how the proposed MegaDescriptor can effectively leverage features learned from different datasets and its ability to generalize beyond the datasets it was initially fine-tuned on. By performing this experiment, we try to mimic how the MegaDescriptor will perform on Seen (known) and Unseen Domains (unknown).
We evaluate the generalization capabilities using the MegaDescriptor-B and all available datasets from one domain (cattle), e.g., AerialCattle2017, FriesianCattle2015, FriesianCattle2017, Cows2021, and OpenCows2020. The first mutation (Same Dataset) was trained on training data from all datasets and evaluated on test data. The second mutation (Seen Domain) used just the part of the domain for training; OpenCows2020 and Cows2021 datasets were excluded. The third mutation (Unseen Domain) excludes all the cattle datasets from training.

The MegaDescriptor-B, compared with a CLIP and DINOv2, yields significantly better or competitive performance (see Figure 7). This can be attributed to the capacity of MegaDescriptor to exploit not just cattle-specific features. Upon excluding two cattle datasets (OpenCows2020 and Cows2021) from the training set, the MegaDescriptor’s performance on those two datasets slightly decreases but still performs significantly better than DINOv2. The MegaDescriptor retains reasonable performance on the cattle datasets even when removing cattle images from training. We attribute this to learning general fine-grained features, which is essential for all the re-identification in any animal datasets, and subsequently transferring this knowledge to the re-identification of the cattle.
如有侵权请联系:admin#unsafe.sh