
A reader contacted me with an eml file (which turned out to be benign) that emldump.py could not parse correctly.
I've written several diary entries explaining how to analyse MIME/eml files with my emldump.py tool, back in the days when threat actors were discovering all kinds of obfuscation tricks that I tried to defeat in my emldump.py tool.
The output of emldump.py for a sample MIME/eml file looks like this:

You can see the multipart structure with different parts (4 in this sample).
When emldump.py can not parse a file properly, there is no multipart structure, just text:

I try options -f to filter out obfuscated lines and -F to fix obfuscated lines, but that does not help:

So I need to take a look at the file content to see what is going on. I do a hex/ascii dump of the start of the file with my cut-bytes.py tool:
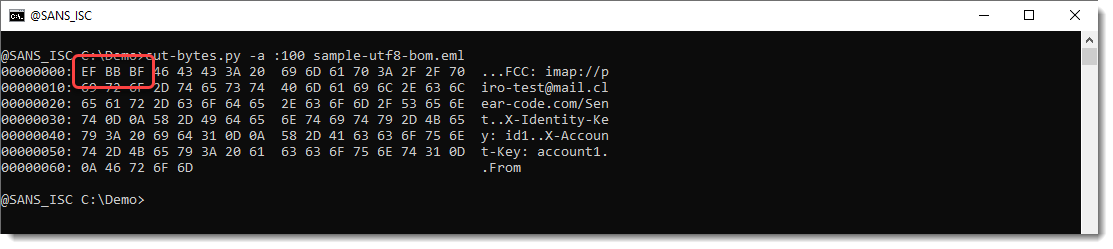
I see that the file starts with EF BB BF. If I remember correctly, this is a Unicode Byte Order Mark (BOM, Unicode character U+FEFF ZERO WIDTH NO-BREAK SPACE) represented in UTF-8.
I confirm this with my tool file-magic.py:

So it looks like the cullprit is the BOM (which is not necessary neither recommended for UTF-8 files). Let's check by removing the first 3 bytes of the file:

And now emldump.py can parse the file correctly.
So I released a new version of emldump.py that uses the Python codec utf-8-sig in stead of the utf-8 codec. utf-8-sig behaves just like utf-8, except that it drops the BOM when present. Now emldump.py can handle files like these too:

Didier Stevens
Senior handler
blog.DidierStevens.com
如有侵权请联系:admin#unsafe.sh