2024-6-8 20:30:25 Author: hackernoon.com(查看原文) 阅读量:5 收藏
Authors:
(1) Kedan Li, University of Illinois at Urbana-Champaign;
(2) Min Jin Chong, University of Illinois at Urbana-Champaign;
(3) Jingen Liu, JD AI Research;
(4) David Forsyth, University of Illinois at Urbana-Champaign.
Table of Links
Image synthesis: Spatial transformer networks estimate geometric transformations using neural networks [23]. Subsequent work [28,39] shows how to warp one object to another. Warping can be used to produce images of rigid objects [26,30] and non-rigid objects (e.g., clothing) [17,12,45]. In contrast to prior work, we use multiple spatial warpers.
Our warps must be combined into a single image, and our U-Net for producing this image follows trends in inpainting (methods that fill in missing portions of an image, see [48,31,50,49]). Han et al. [16,52] show inpainting methods can complete missing clothing items on people.
In our work, we use FID∞ to quantitatively evaluate our method. This is based on the Frchet Inception Distance (FID) [18], a common metric in generative image modelling [5,54,29]. Chong et al. [9] recently showed that FID is biased; extrapolation removes the bias, to an unbiased score (FID∞).
Generating clothed people: Zhu et al. [57] used a conditional GAN to generate images based on pose skeleton and text descriptions of garment. SwapNet [38] learns to transfer clothes from person A to person B by disentangling clothing and pose features. Hsiao et al. [20] learned a fashion model synthesis network using per-garment encodings to enable convenient minimal edit to specific items. In contrast, we warp products onto real model images.
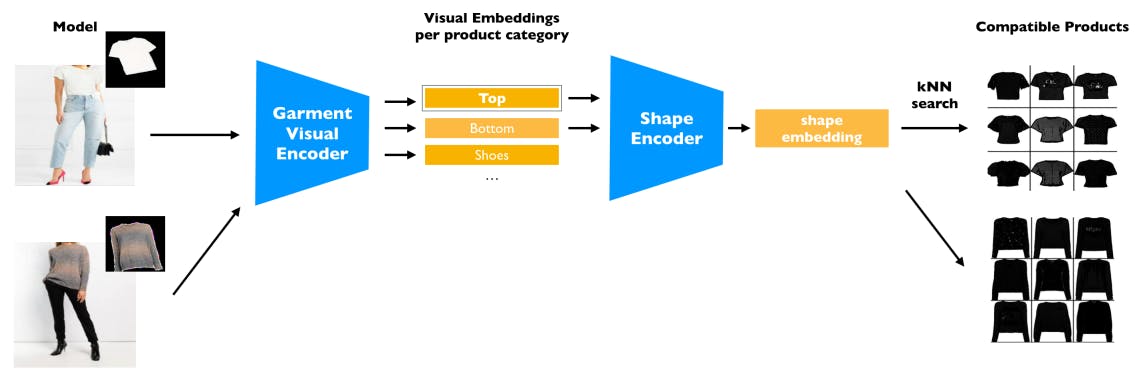
Shape matching underlies our method to match product to model. Tsiao et al. [19] built a shape embedding to enable matching between human body and well-fitting clothing items. Prior work estimated the shape of human body [4,27], clothing items [10,25] and both [35,40], through 2D images. The DensePose [1] descriptor helps modeling the deformation and shading of cloth and, therefore, has been adopted by recent work [36,13,47,51,7,52].
Virtual try-on (VTO) maps a product to a model image. VITON [17] uses a U-Net to generate a coarse synthesis and a mask on the model where the product is presented. A mapping from the product mask to the on-model mask is learned through Thin plate spline (TPS) transformation [3]. The learned mapping is applied on the product image to create a warp. Following their work, Wang et al. [45] improved the architecture using a Geometric Matching Module [39] to estimate the TPS transformations parameters directly from pairs of product image and target person. They train a separate refinement network to combine the warp and the target image. VTNFP [53] extends the work by incorporatiing body segments prediction and later works follow similar procedure [37,24,42,22,2]. However, TPS transformation fails to produce reasonable warps, due to the noisiness of generated masks in our dataset, as shown in Figure 6 right. Instead, we adopt affine transformations which we have found to be more robust to imperfections instead of TPS transformation. A group of following work extended the task to multi-pose. Warping-GAN [11] combined adversarial training with GMM, and generate post and texture separately using a two stage network. MG-VTON [12] further refine the generation method using a three-stage generation network. Other work [21,55,51,7,46] followed similar procedure. Han et al. [15] argued that TPS transformation has low degree of freedom and proposed a flow-based method to create the warp.
Much existing virtual try-on work [17,12,21,47,55,53,24,37] is evaluated on datasets that only have tops (t-shirt, shirt, etc.). Having only tops largely reduces the likelihood of shape mismatch as tops have simple and similar shapes. In our work, we extend the problem to include clothing items of all categories(tshirt, shirt, pants, shorts, dress, skirt, robe, jacket, coat, etc.), and propose a method for matching the shape between the source product and the target model. Evaluation shows that using pairs that match in shape significantly increases the generation quality for both our and prior work (table 4.3).
In addition, real studio outfits are often covered by an unzipped/unbuttoned outerwear, which is also not presented in prior work [17,12,21,47,55,53,37]. This can cause partition or severe occlusion to the garment, and is not addressed by prior work as shown in Figure 6. We show that our multi-warp generation module ameliorates these difficulties.

如有侵权请联系:admin#unsafe.sh