Authors:
(1) Arcangelo Massari, Research Centre for Open Scholarly Metadata, Department of Classical Philology and Italian Studies, University of Bologna, Bologna, Italy {[email protected]};
(2) Fabio Mariani, Institute of Philosophy and Sciences of Art, Leuphana University, Lüneburg, Germany {[email protected]};
(3) Ivan Heibi, Research Centre for Open Scholarly Metadata, Department of Classical Philology and Italian Studies, University of Bologna, Bologna, Italy and Digital Humanities Advanced Research Centre (/DH.arc), Department of Classical Philology and Italian Studies, University of Bologna, Bologna, Italy {[email protected]};
(4) Silvio Peroni, Research Centre for Open Scholarly Metadata, Department of Classical Philology and Italian Studies, University of Bologna, Bologna, Italy and Digital Humanities Advanced Research Centre (/DH.arc), Department of Classical Philology and Italian Studies, University of Bologna, Bologna, Italy {[email protected]};
(5) David Shotton, Oxford e-Research Centre, University of Oxford, Oxford, United Kingdom {[email protected]}.
Table of Links
- Abstract and Intro
- Related Works
- Methodology
- Data and services
- Discussion
- Conclusion, Acknowledgements, and References
3. Methodology
OpenCitations Meta is populated from input data in CSV format (i.e. tabular form). This choice is not accidental. We have found that data exposed by OpenCitations in CSV format (e.g. from COCI (OpenCitations, 2022)) are downloaded more frequently, in comparison to the same data in more structured formats (i.e. JSON Scholix and RDF N-Quads). This is due to the smaller file size (compared to N-Quads and Scholix) and, above all, to the higher readability of the tabular format for a human. The latter is the main reason why the input format adopted by OpenCitations Meta is CSV, to facilitate the future crowdsourcing of bibliographic metadata from human curatorial activities (Heibi et al., 2019a).
The input table of OpenCitations Meta has eleven columns, corresponding to a linearisation of the OCDM (Daquino et al., 2020): id, title, author, editor, publication date, venue, volume, issue, page, type, and publisher. For an in-depth description of how each field is structured, please see (Massari & Heibi, 2022).

Once the CSV tabular data have been acquired, the data are first automatically curated (Curator step) and then converted to RDF based on the OCDM (Creator step). Finally, the curated CSV and RDF are stored as files, while a corresponding triplestore is incrementally populated. Fig. 2 summarises the workflow.

3.1 Curator: deduplication, enrichment and correction
The curation process performs three main actions to improve the quality of the received data: deduplication, enrichment, and correction.
The approach chosen for data deduplication is based strictly on identifiers. In other words, two different entities are considered the same if, and only if, both have the same identifier, e.g. a DOI for articles, an ORCID for people, an ISBN for books, and an ISSN for publication venues (e.g. journals).
Different resources with the same identifier are merged following a precise rule: (1) if the resources are part of the same CSV file, the information of the first occurrence is favoured. However, (2) if the resource is already described in the triplestore, the information in the triplestore will be favoured. In other words, we consider the information stored in the triplestore as trusted, and it can only be incremented with additional data coming from a CSV source.
Once an entity is deduplicated, it is assigned a new, permanent internal identifier called an OpenCitations Meta Identifier (OMID). The OMID has structure [entity_type_abbreviation]/[supplier_prefix][sequential_number]. For example, the first journal article ever processed has OMID br/0601, where br is the abbreviation of “bibliographic resource”, and 060 corresponds to the supplier prefix, which indicates the database to which the bibliographic resource belongs (in this case, OpenCitations Meta). Finally, 1 indicates that this OMID identifies the index’s first bibliographic resource ever recorded for that prefix.
More precisely, the supplier prefix used for OpenCitations Meta is “06[1-9]*0”, i.e. “06” optionally followed by any number excluding zero and a “0” at the end. For example, “060”, “0610”, and “06230” are valid supplier prefixes in OpenCitations Meta.
The entities that are subject to deduplication and subsequently identified with an OMID are external identifiers (abbr. id), agent roles (i.e. authors, editors, publishers, abbr. ar), responsible agents (i.e. people and organisations, abbr. ra), resource embodiments (i.e. pages, abbr. re), and venues, volumes and issues (which are all bibliographic resources, abbr. br). Volumes and issues have OMIDs because they are treated as first-class citizens, not attributes of articles. This has the advantage of permitting one, for instance, to search for the papers within a specific issue, the volumes of a named journal, or journal issues published within a certain time period. In contrast, titles and dates are treated as literal values, not as entities.
Fig. 3 illustrates the deduplication decisional tree. Given an input entity and its identifiers, there are six possible outcomes:
-
If the entity has no identifiers, or they do not exist in the triplestore, then a new OMID is created for the entity;
-
If the entity does not have an OMID, and if one of its external identifiers has already been associated with one and only one other entity, then the two entities are merged and treated as the same;
-
If the entity’s external identifiers in the CSV connect two or more entities within the triplestore that had hitherto been distinct, and no OMID is specified in the CSV, then a conflict arises that cannot be resolved automatically and will require manual intervention. A new OMID is minted for this conflictual entity. For example, in the CSV, the same journal name is associated with two identifiers, issn:1588-2861 and issn:0138-9130; however, in the triplestore, there are entries for two separate entities, one with identifier issn:1588-2861 and the other with identifier issn:0138-9130, which in reality refer to the same entity;
-
If an entity in the CSV has an OMID that exists in the triplestore and no other IDs are present, then the information in the triplestore overwrites that in the CSV. The triplestore is then updated only by the addition of missing details. In other words, specifying its OMID for an entity in the CSV is a way to update an existing entity within OpenCitations Meta;
-
If an entity has an existing OMID and additional identifiers are associated with other entities without an OMID (in the CSV) or with the same OMID (in the CSV or triplestore), then the entities are merged. Moreover, the information in the CSV is overwritten with that already available in the triplestore, and missing details present in the CSV are then added to the triplestore;
-
Finally, if external identifiers connect several entities in the triplestore with different OMIDs, then a conflict arises. In this case, the OMID specified in the CSV takes precedence, and only entities with that OMID are merged.
Given these general rules, three particular cases deserve special concern. The first notable issue concerns the order of authors and editors, which must be maintained according to the OCDM. In the event of a merge, the order recorded when the entity was first created overwrites subsequent ones, and any new authors or editors are added to the end of the existing list, as shown in Fig. 4.


Secondly, in the context of two bibliographic resources being merged, the people involved as authors or editors without an identifier are disambiguated based on their given and family names.
The last significant case involves the containment relationship between articles, issues, volumes and venues. This structure is preserved in the case of a merge, where two volumes or issues are considered the same only if they have the same value, which may be a sequential number (e.g. “Volume 1”) or an arbitrary name (e.g. “Clin_Sect”).
3.2 Curator: error proofing
Once all entities have obtained an OMID, data are normalised, and the errors that can be handled automatically are corrected. All identifiers are checked based on their identifier scheme – for instance, the syntactic correctness of ISBNs, ISSNs and ORCIDs is computed using specific formulas provided by the documentation of the identifier scheme. However, the semantic correctness of identifiers is verified only for ORCIDs and DOIs, which is done using open APIs to verify their actual existence – since, for instance, it is possible to produce an ORCID that is valid syntactically, but that is not in fact assigned to a person.
All ambiguous and alternative characters used for spaces (e.g. tab, no-break space, em space) are transformed into space (Unicode character U+0020). Similarly, ambiguous characters for hyphens within ids, pages, volumes, issues, authors and editors (e.g. non-breaking hyphens, en dash, minus sign) are changed to hyphen-minus (Unicode character U+002D).
Regarding titles of bibliographic resources (“venue” and “title” columns), every word in the title is capitalised except for those with capitals within them (that are probably acronyms, e.g. “FaBiO” and “CiTO”). This exception, however, does not cover the case of entirely capitalised titles. The same rule is also followed for authors and editors, whether individuals or organisations.
Dates are parsed considering both the format validity, based on ISO 8601 (YYYYMM-DD) (Wolf & Wicksteed, 1997), and the value (e.g. 30 February is not a valid date). Where necessary, the date is truncated. For example, the date 2020-02-30 is transformed into 2020-02 because the day of the given date is invalid. similarly, 2020- 27-12 will be truncated to 2020 since the month (and hence the day) is invalid. The date is discarded if the year is invalid (e.g. a year greater than 9999).
The correction of volume and issue numbers is based on numerous rules which deserve special mention. In general, we have identified six classes of errors that may occur, and each different class is addressed accordingly:
- Volume number and issue number in the same field (e.g. “Vol. 35 N° spécial 1”). The two values are separated and assigned to the corresponding field.
-
Prefix errors (e.g. “.38”). The prefix is deleted.
-
Suffix errors (e.g. “19/”). The suffix is deleted.
-
Encoding errors (e.g. “5â\x80\x926”, “38â39”, “3???4”). Only numbers at the extremes are retained, separated by a single hyphen. Therefore, the examples are corrected to “5-6”, “38-39”, and “3-4”, respectively, since “â\x80\x92”, “â” and “???” are incorrectly encoded hyphens.
-
Volume classified as issue (e.g. “Volume 1” in the “issue” field). If the volume pattern is found in the “issue” field and the “volume” field is empty, the content is moved to the “volume” field, and the “issue” field is set to null. However, if the “issue” field contains a volume pattern and the “volume” field contains an issue pattern, the two values are swapped.
-
Issue classified as volume (e.g. “Special Issue 2” in the “volume” field). It is handled in the same way as case 5, but in reversed roles.
We considered as volumes those patterns containing the words “original series”, “volume”, “vol”, and volume in various other languages, e.g. “tome” in French and “cilt” in Turkish. For example, “Original Series”, “Volume 1”, “Vol 71”, “Tome 1”, and “Cilt: 1” are classified as volumes. Instead, we considered as issues those patterns containing the words “issue”, “special issue” and issue in various languages, e.g. “horssérie” (special issue in French) and “özel sayı” (special issue in Turkish). For example, “issue 2”, “special issue 2”, “Special issue ’Urban Morphology”’, “Özel Sayı 5”, and “Hors-série 5” are classified as issues.
Finally, in case a value is both invalid in its format and invalid because it is in the wrong field, then such a value is first corrected and then moved to the right field, if appropriate.
Once the input data has been disambiguated, enriched and corrected, a new CSV file is produced and stored. This file represents the first output of the process (3a in Fig. 2).
3.3 Creator: semantic mapping
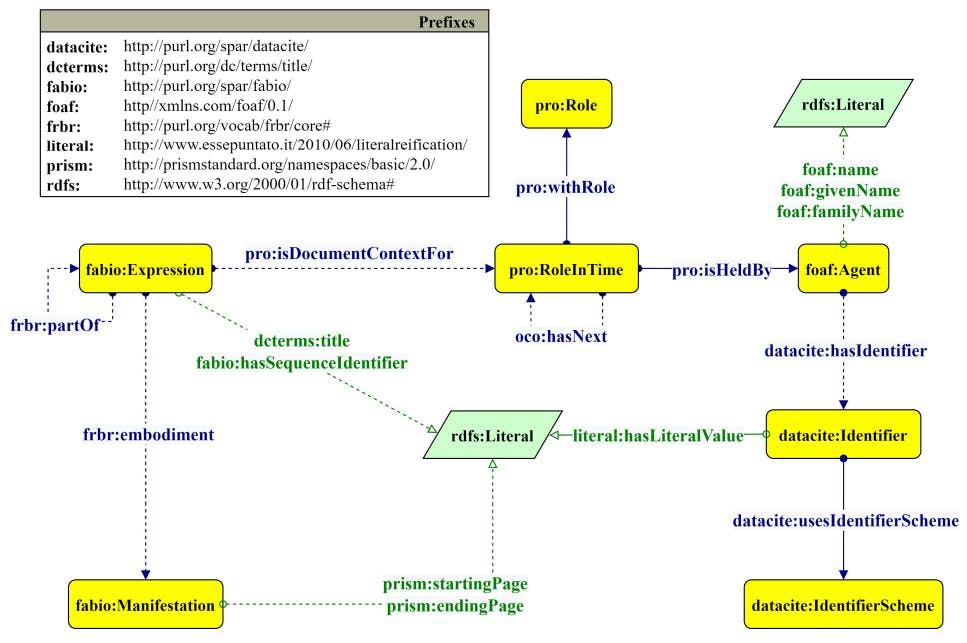
In this phase, data are modelled in RDF following the OCDM (Daquino et al., 2020). This ontology reuses entities defined in the SPAR Ontologies to represent bibliographic entities (fabio:Expression), identifiers (datacite:Identifier), agent roles (pro:RoleInTime), responsible agents (foaf:Agent) and publication format details (fabio:Manifestation). The agent role (i.e. author, editor or publisher) is used as a proxy between the bibliographic resource and the responsible agent, i.e. the person or organisation. This approach helps us define time-dependent and context-dependent roles and statuses, such as the order of the authors (Peroni et al., 2012). Fig. 5 depicts the relationships between the various entities through the Graffoo graphical framework (Falco et al., 2014).

For example, in OpenCitations Meta the entity with OMID omid:br/062601067530 has title Open Access And Online Publishing: A New Frontier In Nursing? (dcterms:title), and was published on 2012-07-25 (prism:publicationDate). Using FRBR (Tillett, 2005), the article is the final published version, or an expression of the original work (fabio:Expression), which has as a sample the entity omid:re/06260837633 (frbr:embodiment), that is the printed publication corresponding to pages 1905-1908 of the journal volume (prism:startingPage, prism:endingPage). More precisely, the article is part of (frbr:partOf) the issue (fabio:JournalIssue) number 9 (fabio:hasSequenceIdentifier), contained in the volume (fabio:JournalVolume) number 68 of the venue Journal Of Advanced Nursing (fabio:Journal).
Furthermore, the person (foaf:Agent) Glenn Hunt (foaf:givenName, foaf:familyName) is the first author (pro:RoleInTime) in the context of this article (pro:isDocumentContextFor). Similarly, the second author is Michelle Cleary (pro:hasNext).
Finally, this publication has the OpenCitations Meta Identifier (OMID) omid:id/062601093630 (datacite:hasIdentifier), an entity of type datacite:Identifier. It also has an external identifier, that uses as its identifier scheme a Digital Object Identifier (DOI) (datacite:usesIdentifierScheme) and that has the literal value “10.1111/j.1365- 2648.2012.06023.x” (literal:hasLiteralValue).
Once the mapping is complete, the RDF data produced can be stored (4a in Fig. 2) and uploaded to a triplestore (4b in Fig. 2).
3.4 Creator: provenance and change tracking
In addition to handling their metadata, great importance is given to provenance and change tracking for entities in OpenCitations Meta. Provenance is a record of who processed a specific entity by creating, deleting, modifying or merging it, when this action was performed, and what the primary source was (Gil et al., 2010). Keeping track of this information is crucial to ensure the reliability of the metadata within OpenCitations Meta. Indeed, the truth of a statement on the Web and the Semantic Web is never absolute, and integrity must be assessed by every application that processes information by evaluating its context (Koivunen & Miller, 2001).
However, besides storing provenance information, mechanisms to understand the evolution of entities are critical when dealing with activities such as research assessment exercises, where modifications, due to either corrections or misspecification, may affect the overall evaluation of a scholar, a research group, or an entire institution. For instance, the name of an institution might change over time, and the reflection of these changes in a database “make it difficult to identify all institution’s names and units without any knowledge of institution’s history” (Pranckut˙e, 2021). This scenario can be prevented by keeping track of how data evolved in the database, thus enabling users to understand such dynamics without accessing external background knowledge. To our knowledge, no other semantic database of scholarly metadata keeps track of changes and provenance in standard RDF 1.1.
The provenance mechanism employed by OpenCitations describes an initial creation snapshot for each stored entity, potentially followed by other snapshots detailing modification, merge or deletion of data, each marked with its snapshot number, as summarised in Fig. 6

Regarding the semantic representation, the problem of provenance modelling (Sikos & Philp, 2020) and change-tracking in RDF (Pelgrin et al., 2021) has been discussed in the scholarly literature. To date, no shared standard achieves both purposes. For this reason, OpenCitations employs the most widely shared approaches, i.e. named graphs (Carroll et al., 2005), the Provenance Ontology (Lebo et al., 2013), and Dublin Core (Board, 2020).
In particular, each snapshot is connected to the previous one via the prov:wasDerivedFrom predicate and is linked to the entity it describes via prov:specializationOf. In addition, each snapshot corresponds to a named graph in which the provenance metadata are described, namely the responsible agent (prov:wasAttributedTo), the primary source (prov:hadPrimarySource), the generation time (prov:generatedAtTime), and, after the generation of an additional snapshot, the invalidation time (prov:invalidatedAtTime). Each snapshot may also optionally be represented by a natural language description of what happened (dcterms:description).
In addition, the OCDM provenance model adds a new predicate, oco:hasUpdateQuery, described within the OpenCitations Ontology (Daquino & Peroni, 2019), which expresses the delta between two versions of an entity via a SPARQL UPDATE query. Fig. 7 displays the model via a Graffoo diagram.

The deduplication process described in Section 3.1 takes place not only on the current state of the dataset but on its entire history by enforcing the change-tracking mechanism. In other words, if an identifier can be traced back to an entity deleted from the triplestore, that identifier will be associated with the OMID of the deleted entity. If the deletion is due to a merge chain, the OMID of the resulting entity takes precedence. For more on the time-traversal queries methodology, see (Massari & Peroni, 2022). For more details on the programming interface for creating data and tracking changes according to the SPAR Ontologies, consult (Persiani et al., 2022).
如有侵权请联系:admin#unsafe.sh