2024-6-1 21:30:24 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Authors:
(1) Praveen Tirupattur, University of Central Florida.
Table of Links
- Abstract
- Acknowledgements
- Chapter 1: Introduction
- Chapter 2: Related Work
- Chapter 3: Proposed Approach
- Chapter 4: Experiments and Results
- Chapter 5: Conclusions and Future Work
- Bibliography
4. Experiments and Results
In this chapter, details of the experiments conducted to evaluate the performance of the system in detecting violent content in videos are presented. The first section deals with the datasets used for this work, the next section describes the experimental setup and finally in the last section, results of the experiments performed are presented.
4.1. Datasets
In this work, data from more than one source has been used to extract audio and visual features, train the classifiers and to test the performance of the system. The two main datasets used here are the Violent Scene Dataset (VSD) and the Hockey Fights dataset. Apart from these two datasets, images from websites such as Google Images[1] are also used. Each of these datasets and their use in this work is described in detail in the following sections.
4.1.1. Violent Scene Dataset
Violent Scene Dataset (VSD) is an annotated dataset for violent scene detection in Hollywood movies and videos from the web. It is a publicly available dataset specifically designed for the development of content-based detection techniques targeting physical violence in movies and videos from the websites such as YouTube[2]. The VSD dataset was initially introduced by Demarty et al. [15] in the framework of the MediaEval benchmark initiative, which serves as a validation framework for the dataset and establishes a state of the art baseline for the violence detection task. The latest version of the dataset VSD2014 is a considerable extension of its previous versions (Demarty et al. [19] , Demarty et al. [18] and Demarty et al. [17]) in several regards. First, to annotate the movies and user-generated videos, violence definition which is closer to the targeted real-world scenario is used by focusing on physical violence one would not let a 8-year-old child watch. Second, the dataset has a substantial set of 31 Hollywood movies. Third, VSD2014 includes 86 web video clips and their meta-data retrieved from YouTube to serve for testing the generalization capabilities of the system developed to detect violence. Fourth, it includes state-of-the-art audio-visual content descriptors. The dataset provides annotations of violent scenes and of violence-related concepts for a collection of (i) Hollywood movies and (ii) user-generated videos shared on the web. In addition to the annotations, pre-computed audio and visual features and various meta-data are provided.
The VSD2014 dataset is split into three different sub-sets, called Hollywood: Development, Hollywood: Test, and YouTube: Generalization. Please refer to Table 4.1 for an overview of the three subsets and basic statistics, including duration, the fraction of violent scenes (as percentage on a per-frame-basis), and the average length of a violent scene. The content of the VSD2014 dataset is categorized into three types: movies/videos, features, and annotations.
The Hollywood movies included in the dataset are chosen such that they are from different genres and have diversity in the types of violence they contain. Movies ranging from extremely violent to virtually no violent content are selected to create this dataset. The selected movies also contain a wide range of violence types. For example, war movies, such as Saving Private Ryan, contain specific gunfights and battle scenes involving lots of people, with a loud and dense audio stream containing numerous special effects. Action movies, such as the Bourne Identity, contain scenes of fights involving only a few participants, possibly hand to hand. Disaster movies, such as Armageddon, show the destruction of entire cities and contain huge explosions. Along with these, a few completely nonviolent movies are also added to the dataset to study the behavior of algorithms on such content. As the actual movies can not be provided in the dataset due to copyright issues, annotations for 31 movies, 24 in the Hollywood: Development and 7 in the Hollywood: Test set are provided. The YouTube: Generalization set contains video clips shared on YouTube under Creative Commons license. A total of 86 clips in MP4 format is included in the dataset. Along with the video meta-data such as video identifier, publishing date, category, title, author, aspect ratio, duration etc., are provided as XML files.
In this dataset, a common set of audio and visual descriptors are provided. Audio features such as amplitude envelop (AE), root-mean-square energy (RMS), zero-crossing rate (ZCR), band energy ratio (BER), spectral centroid (SC), frequency bandwidth (BW), spectral flux (SF), and Mel-frequency cepstral coefficients (MFCC) are provided on a per-video-frame-basis. As audio has a sampling rate of 44,100 Hz and the videos are encoded with 25 fps, a window of size 1,764 audio samples in length is considered to compute these features and 22 MFCCs are computed for each window while all other features are 1-dimensional. Video features provided in the dataset include color naming histograms (CNH), color moments (CM), local binary patterns (LBP), and histograms of oriented gradients (HOG). Audio and visual features are provided in Matlab version 7.3 MAT files, which correspond to HDF5 format.

The VSD2014 dataset contains binary annotations of all violent scenes, where a scene is identified by its start and end frames. These annotations for Hollywood movies and YouTube videos are created by several human assessors and are subsequently reviewed and merged to ensure a certain level of consistency. Each annotated violent segment contains only one action, whenever this is possible. In cases where different actions are overlapping, the segments are merged. This is indicated in the annotation files by adding the tag “multiple action scene”. In addition to binary annotations of segments containing physical violence, annotations also include high-level concepts for 17 movies in the Hollywood: Development set. In particular, 7 visual concepts and 3 audio concepts are annotated, employing a similar annotation protocol as used for violent/non-violent annotations. The concepts are the presence of blood, fights, presence of fire, presence of guns, presence of cold arms, car chases, and gory scenes, for the visual modality; the presence of gunshots, explosions, and screams for the audio modality.
A more detailed description of this dataset is provided by Schedl et al. [51] and for the details about each of the violence classes, please refer to Demarty et al. [19].
4.1.2. Fights Dataset
This dataset is introduced by Nievas et al. [42] and it is created specifically for evaluating fight detection systems. This dataset consists of two parts, the first part (“Hockey”) consists of 1,000 clips at a resolution of 720 × 576 pixels, divided into two groups, 500 fights, and 500 non-fights, extracted from hockey games of the National Hockey League (NHL). Each clip is limited to 50 frames and resolution lowered to 320 × 240. The second part (“Movies”) consists of 200 video clips, 100 fights, and 100 non-fights, in which fights are extracted from action movies and the non-fight videos are extracted from public action recognition datasets. Unlike the hockey dataset, which was relatively uniform both in format and content, these videos depict a wider variety of scenes and were captured at different resolutions. Refer to Figure 4.1 for some of the frames showing fights from the videos in the two datasets. This dataset is available on-line for download[3].

4.1.3. Data from Web
Images from Google are used in developing the color models (Section 3.1.1.2) for the classes blood and non-blood, which are used in extracting blood feature descriptor for each frame in a video. The images containing blood are downloaded from Google Images 1 using query words such as “bloody images”, “bloody scenes”, “bleeding”, “real blood splatter” etc. Similarly, images containing no blood are downloaded using search words such as “nature”,“spring”,“skin”,“cars” etc.
The utility to download images from Google, given a search word, was developed in Python using the library Beautiful Soup (Richardson [48]). For each query, the response contained about 100 images of which only the first 50 were selected for download and saved in a local file directory. Around 1,000 images were downloaded in total, combining both blood and non-blood classes. The average dimensions of the images downloaded are 260 × 193 pixels with a file size of around 10 Kilobytes. Refer to Figure 3.3 for some of the sample images used in this work.
4.2. Setup
In this section, details of the experimental setup and the approaches used to evaluate the performance of the system are presented. In the following paragraph, partitioning of the dataset is discussed and the later paragraphs explain the evaluation techniques.
As mentioned in the earlier Section 4.1, data from multiple sources is used in this system. The most important source is the VSD2014 dataset. It is the only publicly available dataset which provides annotated video data with various categories of violence and it is the main reason for using this dataset in developing this system. As explained in the previous Section 4.1.1, this dataset contains three subsets, Hollywood: Development, Hollywood: Test and YouTube: Generalization. In this work all the three subsets are used. The Hollywood: Development subset is the only dataset which is annotated with different violence classes. This subset consisting of 24 Hollywood movies is partitioned into 3 parts. The first part consisting of 12 movies (Eragon, Fantastic Four 1, Fargo, Fight Club, Harry Potter 5, I Am Legend, Independence Day, Legally Blond, Leon, Midnight Express, Pirates Of The Caribbean, Reservoir Dogs) is used for training the classifiers. The second part consisting of 7 movies (Saving Private Ryan, The Bourne Identity, The God Father, The Pianist, The Sixth Sense, The Wicker Man, The Wizard of Oz) is used for testing the trained classifiers and to calculate weights for each violence type. The final part consisting of 3 movies (Armageddon, Billy Elliot, and Dead Poets Society) is used for evaluation. The Hollywood: Test and the YouTube: Generalization subsets are also used for evaluation, but for a different task. The following paragraphs provide details of the evaluation approaches used.
To evaluate the performance of the system, two different classification tasks are defined. In the first task, the system has to detect specific category of violence present in a video segment. The second task is more generic where the system has to only detect the presence of violence. For both these tasks, different datasets are used for evaluation. In the first task which is a multi-class classification task, the validation set consisting of 3 Hollywood movies (Armageddon, Billy Elliot, and Dead Poets Society) is used. In this subset, each frame interval containing violence is annotated with the class of violence that is present. Hence, this dataset is used for this task. These 3 movies were neither used for training, testing of classifiers nor for weight calculation so that the system can be evaluated on a purely new data. The procedure illustrated in Figure 3.1 is used for calculating the probability of a video segment to belong to a specific class of violence. The output probabilities from the system and the ground truth information are used to generate ROC (Receiver Operating Characteristic) curves and to assess the performance of the system.
In the second task, which is a binary classification task, Hollywood: Test and the YouTube: Generalization subsets of the VSD2104 dataset are used. The Hollywood: Test subset consists of 8 Hollywood movies and the YouTube: Generalization subset consists for 86 videos from YouTube. In both these subsets the frame intervals containing violence are provided as annotations and no information about the class of violence is provided. Hence, these subsets are used for this task. In this task, similar to the previous one, the procedure illustrated in Figure 3.1 is used for calculating the probability of a video segment to belong to a specific class of violence. For each video segment, the maximum probability obtained for any of the violence class is considered to be the probability of it being violent. Similar to above task, ROC curves are generated from these probability values and the ground truth from the dataset.
In both these tasks, first all the features are extracted from the training and testing datasets. Next, the training and testing datasets are randomly sampled to get an equal amount of positive and negative samples. 2,000 feature samples are selected for training and 3,000 are selected for testing. As mentioned above, disjoint training and testing sets are used to avoid testing on training data. In both the tasks, SVM classifiers with Linear, Radial Basis Function and Chi-Square kernels are trained for each feature type and the classifiers with good classification scores on the test set are selected for the fusion step. In the fusion step, the weights for each violence type are calculated by grid-searching the possible combinations which maximize the performance of the classifier. The EER (Equal Error Rate) measure is used as the performance measure.
4.3. Experiments and Results
In this section, the experiments and their results are presented. First, the results of the multi-class classification task are presented, followed by the results of the binary classification task.
4.3.1. Multi-Class Classification
In this task, the system has to detect the category of violence present in a video. The violence categories targeted in this system are Blood, Cold arms, Explosions, Fights, Fire, Firearms, Gunshots, Screams. As mentioned in the Chapter 1, these are the subset of categories of violence that are defined in the VSD2014. Apart from these eight categories, Car Chase, and Subjective Violence are also defined in VSD2014, which are not used in this work as there were not enough video segments tagged with these categories in the dataset. This task is very difficult as detection of sub-categories of violence adds more complexity to the complicated problem of violence detection. The attempt to detect fine-grained concepts of violence by this system is novel and there is no existing system which does this task.
As mentioned in Chapter 3, this system uses weighted decision fusion approach to detect multiple classes of violence where weights for each violence category are learned using a grid-search technique. Please refer to Section 3.1.3 for more details about this approach. In Table 4.2, the weights for each violence class which is found using this grid-search technique are presented.
These weights are used to get the weighted sum of output values of binary feature classifiers for each violence category. The category with the highest sum is then the category of violence present in that video segment. If the output sum is less than 0.5 then the video segement is categorised as Non-Violent. The video segments in the validation set are classified using this approach and the results are presented in the Figure 4.2. In the figure, each curve represents the ROC curve for each of the violence categories.
Table 4.2: Classifier weights obtained for each of the violence class using Grid-Search technique. Here the criteria for selecting the weights for a violence class was to find the weights which minimize the EER for that violence class.


Figure 4.2: Performance of the system in the Multi-Class Classification task.
4.3.2. Binary Classification
In this binary classification task, the system is expected to detect the presence of violence without having to find the category. Similar to the previous task, the output probabilities of binary feature classifiers are combined using a weighted sum approach and the output probabilities of the video segment to belong to each of the violence classes are calculated. If the maximum probability for any of the class exceeds 0.5 then the video segment is categorized as violence or else it is categorized as non-violence. As mentioned in Section 4.2, this task is performed on YouTube-Generalization and Hollywood-Test datasets. The Figure 4.3 provides the results of this task on both the datasets. Two ROC curves one for each of the datasets are used to represent the performance of the system. Using 0.5 as the threshold to make the decision of whether the video segment contains violence or not, the precision, recall and accuracy values are calculated. Please refer to Table 4.3 for the obtained results.

![Table 4.4: Classification results obtained by the best performing teams from MediaEval-2014 (Schedl et al. [51]).](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-mid3v31.png?auto=format&fit=max&w=2048)
4.4. Discussion
In this section, the results presented in Section 4.3 are discussed. Before discussing the results of the Multi-Class and Binary classification tasks, the performance of the individual classifiers is discussed.
4.4.1. Individual Classifiers
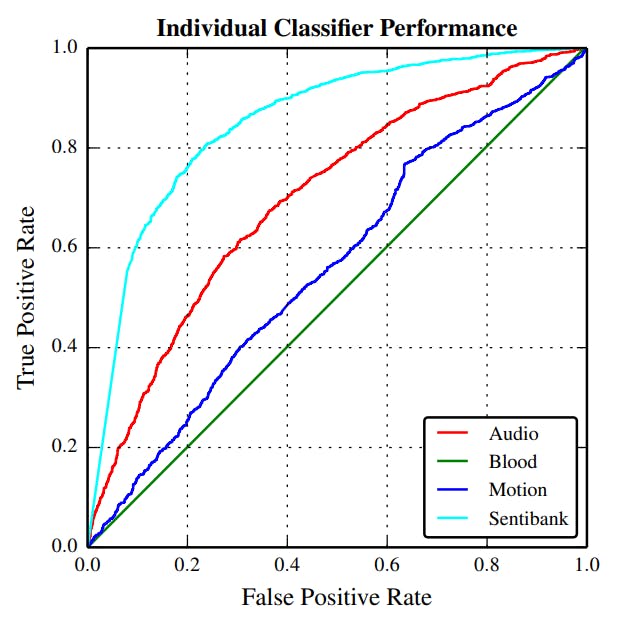
In both the classification tasks discussed in Section 4.3, a fusion of classifier scores is performed to get the final results. Hence, the performance of the system mainly depends on the individual performance of each of the classifiers and partially on the weights assigned to each of the classifiers. For the final classification results to be good, it is important that each of the classifiers have good individual performance. To get best performing classifiers, SVMs are trained using three different kernel functions (Linear, RBF, and Chi-Square) and the classifier with optimal performance on the test set are selected. Following this approach, best performing classifiers for each feature type are selected. The performance of these selected classifiers on the test dataset in presented in Figure 4.4. It can be observed that SentiBank and Audio are the two feature classifiers that show reasonable performance on the test set. Motion feature classifier has a performance which is a little better than chance and Blood has performance equivalent to chance. A detailed discussion on the performance of each of these classifiers in the increasing order of their performance are presented next.


4.4.1.1. Motion
As it is evident from Figure 4.4, the performance of the motion feature classifier on the test set is only a little better than chance. To understand the reason behind this, the performance of all the motion feature classifiers, trained with different SVM kernels on available datasets are compared. Refer to Figure 4.5 for the comparison. In the figure, the left plot shows the performance of the classifiers on the test set from Hockey dataset and the plot on the right shows the comparison on Hollywood-Test dataset. In both the graphs, the red curve corresponds to the classifier trained on the Hockey dataset and the remaining three curves correspond to classifiers trained on the Hollywood-Dev dataset.
From both these plots, it can be observed that the performance of the classifiers trained and tested on the same dataset is reasonably good when compared to the classifiers which are trained on one dataset and tested on another. In the plot on the left (TestSet: Hockey Dataset), the classifier trained on Hockey Dataset has better performance. Similarly, in the plot on the right (TestSet: Hollywood-Test), the performance of classifiers trained on Hollywood-Dev dataset have better performance. From there observations, it can be inferred that the motion feature representation learned from one dataset can not be transferred to another dataset. The reason for this could be to the disparity in video resolution and video format between the datasets. The videos from the Hockey dataset and the Hollywood-Test dataset have different formats, and also, not all videos from Hollywood-Development and Hollywood-Test have the same format. The video format plays an important role as the procedure used to extract motion features (explained in Section 3.1.1.3.1) use motion information from video codecs. Length and resolution of a video will also have some effect, even though the procedure used here tries to reduce this by normalizing the extracted features with the length of the video segment and by aggregating the pixel motions over a pre-defined number of sub-regions of the frame. Videos from Hockey dataset are very short segments of one second each and have small frame size and low quality. Whereas, the video segments from the Hollywood dataset are longer and have larger frame size with better quality. One solution for this problem could be to convert all the videos to the same format, but even then there could be a problem due to improper video encoding. The other solution could be to use an Optical flow based approach to extract motion features (explained in Section 3.1.1.3.2). But as explained earlier, this approach is tedious and may not work when there is blur due to motion in a video.
4.4.1.2. Blood
The performance of blood feature classifier on the test set is just as good as a chance. Refer to Figure 4.4 for the results. Here the problem is not with the feature extraction as the blood detector used for blood feature extraction has shown very good results in detecting regions containing blood in an image. Please refer to Figure 3.4 for the performance of blood detector on images from the web and to Figure 4.6 for the performance of it on sample frames from the Hollywood dataset. From this, it is clear that the blood feature extractor is doing a pretty good job and it is not the problem with the feature extraction. Hence, it can be concluded that the problem is with the classifier training and it is due to the limited availability of training data.
In the VSD2014 dataset which is used for training, the video segments containing blood are annotated with labels (“Unnoticeable”, “Low”, “Medium”, and “High”) representing the amount of blood contained in these segments. There are very few segments in this dataset which are annotated with the label “High”, as a result of which, the SVM classifiers are unable to learn the feature representation of the frames containing blood effectively. The performance of this feature classifier can be improved by training it with a larger dataset with many instances of frames containing a high amount of blood. Alternatively images from Google can also be used to train this classifier.
4.4.1.3. Audio
Audio feature classifier is the second best-performing classifier (refer to Figure 4.4) on the test set and this shows the importance of audio in violence detection. Although visual features are good indicators of violent content, there are some scenes in which audio plays more important role. For example, scenes containing fights, gunshots, and explosions. These scenes have characteristic sounds and audio features such as MFCCs and Energy-entropy, can be used to detect sound patterns associated with these violent scenes. In this work, MFCC features are used to describe audio content (refer to Section 3.1.1.1) as many previous works on violence detection (Acar et al. [1], Jiang et al. [33], Lam et al. [36], etc.) have shown the effectiveness of MFCC features in detecting audio signatures associated with violent scenes. Other audio features such as energy entropy, pitch and power spectrum can also be used along with MFCC features to further improve the performance of the feature classifier. But it is important to note that, audio alone is not sufficient to detect violence and it only plays an important role in detecting few violence classes such as Gunshots and Explosions which have unique audio signatures.
4.4.1.4. SentiBank
The SentiBank feature classifier has shown the best performance of all the feature classifiers (Refer to Figure 4.4) and has contributed strongly to the overall performance of the system. This demonstrates the power of SentiBank, in detecting complex visual sentiments such as violence. Figure 4.7 shows the average scores for top 50 ANPs for frames containing violence and no violence. As it can be observed the list of ANPs with highest average scores for violence and no-violence class are very different and this is the reason behind the very good performance of SentiBank in separating violence class from no-violence class. Note that, not all the adjectives in the ANP list for violence class describe violence. This could be due to many different reasons, one of which could be the fact that, of the 1,200 ANPs used in SentiBank only a few describe the emotions related to violence (like fear, terror, rage, anger etc.,). Please refer to Figure 4.8 which shows the Plutchik’s Wheel of Emotions and the distribution of ANPs for each category of emotion in VSO.

4.4.2. Fusion Weights
As mentioned earlier (Section 3.1.3), the final classification scores are calculated by late fusion of individual classifier scores using weighted sum approach. The weights used here are calculated using a grid-search approach with the goal to minimize the Equal Error Rate (EER). So, weights play an important role in determining the overall classification performance of the system. Note that all these weights are calculated on the test set. In Table 4.2, the weights of the classifiers for each of the eight violence class, obtained using the grid-search technique, are presented. From the weights obtained, the following observations about weight distribution can be made, (i) For most of the violence classes, the highest weight is assigned to SentiBank as it is the most discriminative feature. (ii) Audio has received the highest weight for violence classes such as Gunshots, Explosions, and Fights where audio plays a very important role. (iii) Blood has received high weights for violence classes such as Screams, Gunshots, and Firearms. This is interesting as a video segment belonging to any of these violence classes can also have blood in it. (iv) Motion has received the least weight in most of the violence classes as it the least performing feature. But, it can also be observed that it has a higher weight for the class Fights where a lot of motion can be expected.
If the weights assigned to each of the violence classes are analyzed the following observations can be made, (i) For the class Gunshots, the highest distribution weights is between Audio (0.5) and Blood (0.45). This is expected as audio features play an important role in detecting gunshots and the scenes containing gunshots are also expected to have a lot of blood. (ii) Audio (0.4), and visual features (Motion - 0.25 and SentiBank - 0.30) have received an almost equal amount of weight for the class Fights. This is expected as both audio and visual features are important in detecting scenes containing fights. (iii) For the class Explosions, highest weights are assigned to Audio (0.9) which is expected, as audio features are crucial in detecting explosions. (iv) Fire is a violence class where visual features are expected to have high weights and as expected the best performing visual feature, SentiBank (0.85), is assigned the highest weight. (v) Violence class Cold


arms contain scenes which have the presence of any cold weapon (e.g., knives, swords, arrows, halberds, etc.). For this class, visual features are expected to have high weights. And as expected, SentiBank (0.95) has the highest weight for this class. (vi) “Firearms” is the violence class in which the scenes contain guns and firearms. Similar to the above class, visual features are expected to have high weights. For this class, SentiBank (0.6) and Blood (0.3) have received the highest distribution of weights. The reason for Blood being assigned a higher weight might be due to the fact that most of the scenes containing guns will also contain bloodshed. (vii) For the class Blood, the feature Blood is expected to have the highest weight. But feature Blood (0.05) received only a small weight and SentiBank (0.95) gained the highest weight. This is not an expected result and this could be due to the poor performance of the Blood feature classifier on the test set. (viii) It is intuitive to expect Audio to have higher weights for class “Screams” as audio features play an important role in detecting screams. But, the weights obtained here are against this intuition. Audio has received very less weight whereas SentiBank has received highest weight. Overall, the weights obtained from the grid-search are more or less as expected for most of the classes. Better weight distribution could be obtained if the performance of individual classifiers on the test is improved.
4.4.3. Multi-Class Classification
In this section, the results obtained in the multi-class classification task are discussed. Please refer to Figure 4.2 for the results obtained in this task. From the figure, the following observations can be drawn (i) The system shows good performance (EER of around 30%) in detecting Gunshots. (ii) For the violence classes, Cold arms, Blood and Explosions, the system shows moderate performance (EER of around 40%). (iii) For the remaining violence classes (Fights, Screams, Fire, Firearms) the performance is as good as a chance (EER of more than 45%). These results suggest that there is huge scope for improvement, but, it is important to remember that violence detection is not a trivial task and distinguishing between different classes of violence is, even more, difficult. All the approaches proposed so far have only concentrated on detecting the presence or absence of violence, but not on detecting the category of violence. The novel approach proposed in this work is one of the first in this direction and there are no baseline systems to compare the performance with. The results obtained from this work will serve as a baseline for future works in this area.
In this system, the late fusion approach is followed which has shown good results in a similar multimedia concept detection task of adult content detection (Schulze et al. [52]). Hence, the poor performance of the system can not be attributed to the approach followed. The performance of the system depends on the performance of individual classifiers and the fusion weight assigned to them for each of the violence classes. As the fusion weights are adjusted to minimize the EER using the Grid-Search technique, the overall performance of the system solely depends on the performance of the individual classifiers. So, to improve the performance of the system in this task, it is necessary to improve the performance of individual classifiers in detecting violence.
4.4.4. Binary Classification
The results for the binary classification task are presented in Figure 4.3. This task is an extension to the multi-class classification task. As explained earlier, in this task, a video segment is categorized as “Violence” if the output probability for any one of the violence classes is more than the threshold of 0.5. The performance of the system in this task is evaluated on two datasets, Hollywood-Test, and YouTube-Generalization. It can be observed that the performance of the system on these datasets is a little better than chance. It can also be observed that the performance is better on Hollywood-Test dataset than YouTube-Generalization dataset. This is expected as all the classifiers are trained on data from Hollywood-Development dataset which have similar video content to that of Hollywood-Test dataset. The precision, recall and accuracy values obtained by the system for this task are presented in Table 4.3. The results obtained by the best performing team in this task from MediaEval-2014 are given in Table 4.4.
These results can not be directly compared, even though the same dataset is used, as the process used for evaluation is not the same. In MediaEval-2014, a system is expected to output the start and end frame for the video segments which contain violence and, if the overlap between the ground truth and the output frame intervals is more than 50% then it is considered as a hit. Please refer to Schedl et al. [51] for more information on the process followed in MediaEval-2014. In the proposed approach, the system categorizes each 1-second segment of the input video to be of class “Violence” or “No Violence” and the system performance is calculated by comparing this with the ground truth. This evaluation criteria used here is much more stringent and more granular when compared to the one used in MediaEval-2014. Here, as the classification is done for each 1-second segment, there is no need for a strategy to penalize detection of shorter segments. MAP metric is used for selecting the best performing system in MediaEval whereas, in the proposed system, the EER of the system is optimized.
Even though the results obtained from this system can not be directly compared to the MediaEval results, it can be observed that the performance of this system is comparable to, if not better than, the best performing system from MediaEval-2014 even though strict evaluation criteria are used. These results suggest that the system developed using the proposed novel approach is better than the existing state-of-art systems in this area of violence detection.
4.5. Summary
In this chapter, a detailed discussion on the evaluation of the developed system is presented. In the Section 4.1, details of the datasets used in this work are explained and in the next section Section 4.2, the experimental setup is discussed. In Section 4.3 the experiments and their results are presented, followed by a detailed discussion on the obtained results in Section 4.4.
[1] http://www.images.google.com
[2] http://www.youtube.com
[3] http://visilab.etsii.uclm.es/personas/oscar/FightDetection/index.html
如有侵权请联系:admin#unsafe.sh