2024-5-30 05:30:55 Author: hackernoon.com(查看原文) 阅读量:3 收藏
A lot of questions are swirling about the state of generative AI right now. How far along are companies with their bespoke GenAI efforts? Are organizations actually building AI applications using their own proprietary data in ways that move the needle? What kind of architecture is required?
These questions aren’t surprising — there’s a huge range of opinions about AI out there, from unabashed optimism to jaded cynicism, mixed with a lot of hype.
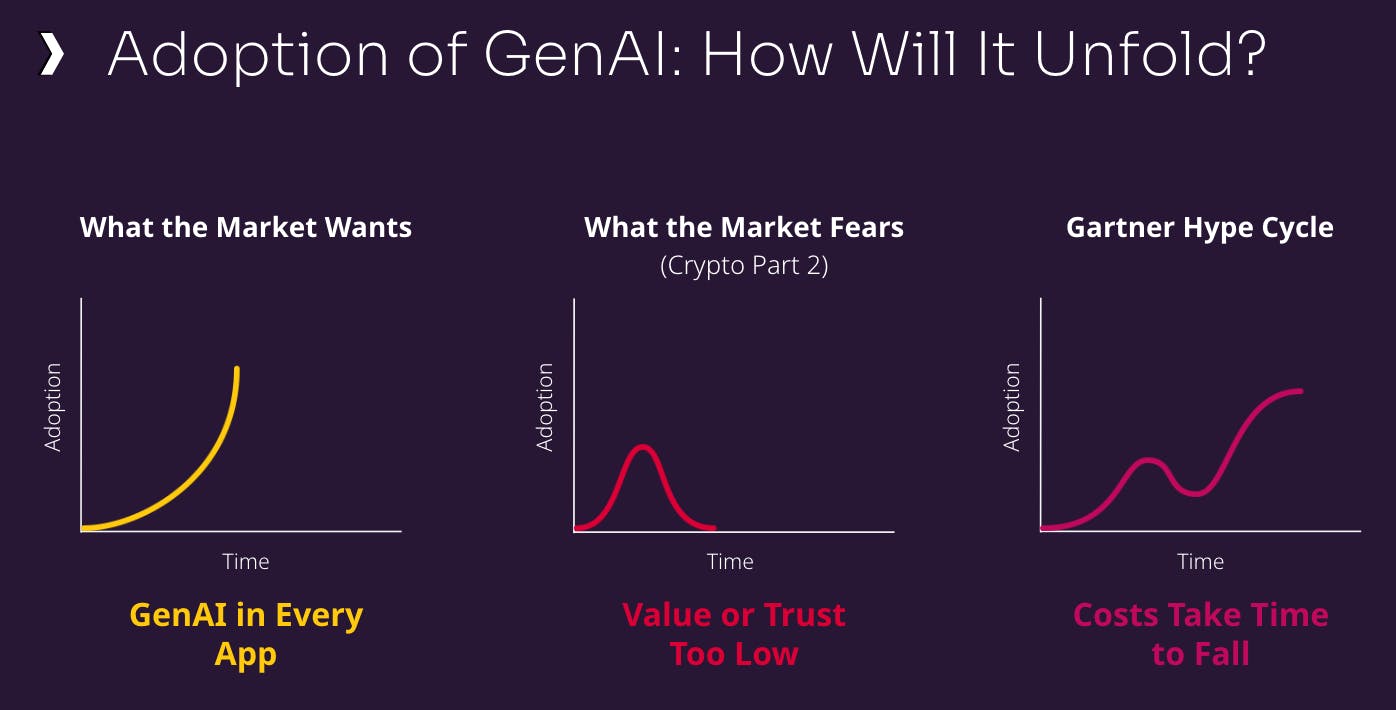
I’ve found that it helps to clarify the state of affairs in the GenAI marketplace across three areas: what the market wants to see, fears about what might happen, and what will happen (and how) in 2024.

What Does Everyone Want — and What Are They Afraid of?
GenAI exploded on the scene in late 2022 when OpenAI released ChatGPT and showed how powerful and accessible this kind of technology could be. The excitement about the potential upside of AI was everywhere. In short order, GenAI was going to be infused into every application at every enterprise. Investors envisioned a hockey-stick-like growth curve for companies that provide the infrastructure to support GenAI.
The naysayers, on the other hand, envisioned a dystopian AI future that’s a cross between “Westworld” and “Black Mirror.” Others warn of an AI bubble. From an investment perspective, some say it’s like crypto all over again — lots of excitement and hype, and then a smoking crater.
I think both of these fears are unfounded. Sure, with every new technology wave, there’ll be bad actors using GenAI for the wrong reasons. And the excitement about the possibilities of GenAI is everywhere; it does have a “bubbly” feel to it, and might even be more strident than the crypto buzz.
But the big difference between GenAI and crypto is the fact that there are many, many real use cases for the former, across organizations and across industries. In crypto, there was one strong use case: financial transactions between untrusted parties (aka money laundering). That’s something that the mainstream isn’t quite as interested in.
Right now, the state of affairs for GenAI applications reminds me of e-commerce in the late 1990s, when companies were trying to figure out how to make it safe to use credit cards over the Internet. It took a little while for organizations to figure out how to do it securely, but once they did, suddenly everyone had an e-commerce site.
The parallel I see in GenAI right now: how to ensure that language models don’t return inaccurate responses by hallucinating. The good news? That’s been figured out (thanks to retrieval-augmented generation, or RAG; more on that below).
Where Are We Now, and Where Are We Going?
A lot of what we saw last year were proof-of-concept GenAI projects: apps to demonstrate to a company’s leadership what’s possible. But very few companies have moved beyond that to build applications that are in full production. By “production,” I mean that an organization has an AI application that is being used by customers or employees in a non-prototype way.
In other words, it’s available as a routine part of activities within some segments of business operations. It might be the front office, it might be what’s behind a call to customer service, but it’s somewhere near the mainstream part of business.
Walmart is a good early example of this. The retailer announced in January that it has added GenAI-powered search to its shopping app. Apple is reportedly testing a GenAI tool to help its employees provide speedier technical support. Until we start seeing more examples like this, GenAI is going to linger a little longer in the early stage of what Gartner calls the “hype cycle.”
Volkswagen just announced an in-house lab to develop GenAI apps for navigation and infotainment applications for its automobiles.

That said, we’re not as far from reaching the “plateau of productivity” as some might think. As I mentioned earlier, trusting models’ output has been a hurdle for organizations that are still grappling with how to produce relevant and accurate large language model (LLM) responses by reducing hallucinations.
RAG, which provides models with additional data or context in real-time from other sources — most often, a database that can store vectors — is being employed now to help solve this problem. This technology advancement is a key to developing domain-specific, bespoke GenAI applications built on organizations’ most valuable asset: their own data.
While RAG has emerged as the de facto method for getting enterprise context into GenAI applications, fine-tuning — when a pre-trained model is trained further on a subset of data — is often mentioned as well. There are times when this method can be useful, but RAG is the right choice if there’s any concern for privacy, security, or speed.
Regardless of how context is added to the application, the big question I get often from investors I’ve been speaking with is when will companies start to make money from GenAI apps?
My response: Most of the enterprises you track are consumption-based businesses. Many are now supporting the experiments, proofs of concept (POCs), and niche apps that their customers have built; those don’t do much in the way of consumption.
But this is starting to change as major AI applications start to go from POC into true production. I predict this is going to happen in a significant way by the end of 2024. It will come to fruition in the second half of 2024 starting in two places.
First, it’s taking hold in retail (see the Walmart example mentioned earlier). You’ll also see widespread adoption in what I call the “AI intranet” area: Chat with PDF, knowledge bases, and internal call centers.
With the consumption that these kinds of apps drive, companies like Microsoft, Google, and even Oracle are starting to report results from AI. Outside of the realm of hyperscalers, other AI infrastructure companies will likely start to highlight lifts in the earnings reports they release in January, February, and March of next year.
The Path to Production for GenAI Applications
The groundwork has already been laid for consumption-based AI infrastructure companies. We’ve already seen strong, commercial proof points that show what’s possible for a large base of domain-specific, bespoke applications. From the creative AI apps — Midjourney, Adobe Firefly, and other image generators, for example — to knowledge apps like GitHub Copilot (over 1 million developers use it), Glean, and others, these applications have enjoyed great adoption and have driven significant productivity gains.
Progress on bespoke apps is most advanced in industries and use cases that need to facilitate delivering knowledge to the point of interaction. The knowledge will come from their own data, using off-the-shelf models (either open source or proprietary), RAG, and the cloud provider of their choice.
Three elements are required for enterprises to build bespoke GenAI apps that are ready for the rigors of functioning at the production scale: smart context, relevance, and scalability.
Smart Context
Let’s take a quick look at how proprietary data is used to generate useful, relevant, and accurate responses in GenAI applications.
Applications take user input in the shape of all kinds of data and feed it all into an embedding engine, which essentially derives meaning from the data, retrieves information from a vector database using RAG, and builds the “smart context” that the LLM can use to generate a contextualized, hallucination-free response that’s presented to the user in real-time.
Relevance
This isn’t a topic you hear much about at operational database companies. But in the field of AI and vector databases, relevance is a mix of recall and precision that’s critical to producing useful, accurate, non-hallucinatory responses.
Unlike traditional database operations, vector databases enable semantic or similarity search, which is non-deterministic in nature. Because of this, the results returned for the same query can be different depending on the context and how the search process is executed. This is where accuracy and relevance play a key role in how the vector database operates in real-world applications. Natural interaction requires that the results returned on a similarity search are accurate AND relevant to the requested query.
Scalability
GenAI apps that go beyond POCs and into production require high throughput. Throughput essentially is the amount of data that can be stored, accessed, or retrieved in a given amount of time. High throughput is critical to delivering real-time, interactive, data-intensive features at scale; writes often involve billions of vectors from multiple sources, and GenAI applications can generate massive amounts of requests per second.
Wrapping Up
As with earlier waves of technology innovation, GenAI is following an established pattern, and all signs point to it moving even faster than previous tech revolutions. If you cut through all the negative and positive hype about it, it’s clear that promising progress is being made by companies working to move their POC GenAI apps to production.
And companies like my employer DataStax that provide the scalable, easy-to-build-on foundations for these apps will start seeing the benefits of their customers’ consumption sooner than some might think.
By Ed Anuff, DataStax
Learn more about how DataStax enables customers to get their GenAI apps to production.
如有侵权请联系:admin#unsafe.sh