2024-5-28 22:0:20 Author: hackernoon.com(查看原文) 阅读量:0 收藏
Authors:
(1) Dinesh Kumar Vishwakarma, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India;
(2) Mayank Jindal, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India
(3) Ayush Mittal, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India
(4) Aditya Sharma, Biometric Research Laboratory, Department of Information Technology, Delhi Technological University, Delhi, India.
Table of Links
- Abstract and Intro
- Background and Related Work
- EMTD Dataset
- Proposed Methodology
- Experiments
- Conclusion and References
5. Experiments
In this part, we will examine various model architectures on different modalities and prefeature fused models. Later, we verify our work by validating it on the standard LMTD-9 dataset as well as on our proposed dataset. Finally, a comparative study is discussed to explore our model robustness. All the experiments are performed on GPU workstations with 128 GB DDR4 RAM and Nvidia Titan RTX (24 GB) GPU configuration.
5.1. Datasets
To verify our framework, we utilize our proposed dataset and standard LMTD-9 [2] dataset. Comprehensive details are mentioned as follows:
5.1.1. English movie trailer dataset (EMTD)
EMTD: Our proposed dataset contains a separate training set of 1700 unique trailers and a validation set of 300 unique trailers, all taken from IMDB, as mentioned in Section 3.
5.1.2. Labeled movie trailer dataset (LMTD-9)
LMTD [16], [20] is a multi-label large-scale movie trailer dataset including trailer link, trailer metadata, plot/summary, unique trailer id consisting of around 9k movie trailers belonging to 22 distinct labels/genres. For verification purposes, a validation set (subpart) of LMTD-9 [2] is used that only includes the Hollywood trailers released after 1980 and trailers specific to our genre list. The dataset contains varying length trailers with different video quality and aspect ratios.
5.2. Classification results on different models
In this section, we will discuss our experiments with different framework variations. We experimented with 3 different frameworks based on separate modalities and pre-fused features.
-
MS (Video frames analysis): Model considering the only Situation based features from video frames.
-
MD (Dialogues-metadata analysis): Model considering dialogues from audio and descriptions from metadata as features.
-
MSD (Multi-modality analysis): Model considering situation-based features from video frames, dialogues from audio and descriptions from metadata as features.



The architecture proposed in Section 4.2.3 with pre-fused features is used for MSD. However, the input corpus is slightly modified. The corpus defined in Section 4.4 is used for MSD. Precision, Recall, and F1-score for MSD on LMTD-9 and EMTD is depicted in Table 5. However, the AU (PRC) comparison of MSD with MS and MD is discussed in the upcoming section.
Some variation can be seen among the performance of different genres. Most of the trailers belonging to major genres are being classified precisely (with an F1 score of 0.84 and above), which shows that the proposed model is performing well. The action genre was the best performing genre among five with an F1-score of 0.88 and 0.89 on EMTD and LMTD-9 respectively. The romance genre was seen to be the least performing genre among all genres in terms of the F1-score. It is observed that many romance genre trailers are being misclassified into comedy as both these genres are dominated by similar words like happy, smile, laugh, etc.



5.3. AU (PRC) Comparison
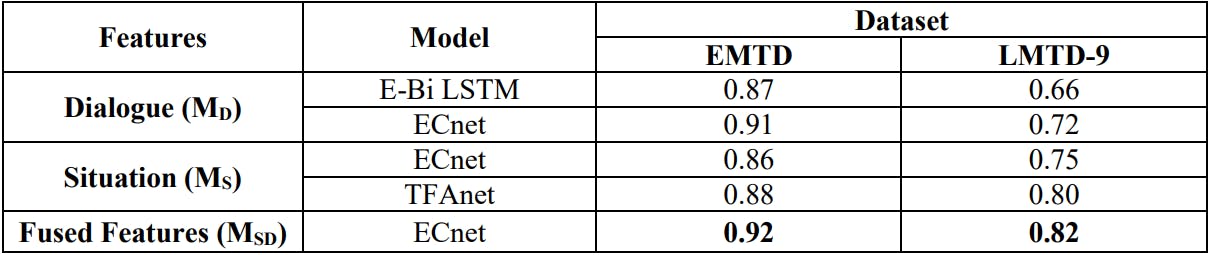
The AU (PRC) i.e., area under the precision-recall curve, is calculated to compare our classification results, as we are dealing with the multi-label classification problem. AU (PRC) measure helps to compare the actual performance of our model, compensating for the noise effect due to class imbalance in the multi-label dataset. The AU (PRC) curves are created for all 3 models on both datasets as depicted in Fig. 5, Fig. 6, and Fig. 7. On the validation set of EMTD, we found almost similar AU (PRC) values 92%, 91%, 88% on MSD, MD, and MS, respectively. However, we found that our MSD gives the 82% AU (PRC) values on the LMTD9 dataset, which is greater than the other two models i.e., 72% and 80% AU (PRC) of MD and MS respectively as in Table 6.

However, for overall comparison with some other models that we experimented with within our study, we mention their results in Table 6. For choosing the best architecture, the models are compared in terms of AU (PRC) on both of the validation datasets. The implementation of Features Model Dataset EMTD LMTD-9 Dialogue (MD) E-Bi LSTM 0.87 0.66 ECnet 0.91 0.72 Situation (MS) ECnet 0.86 0.75 TFAnet 0.88 0.80 Fused Features (MSD) ECnet 0.92 0.82 all the mentioned models helps us in deciding the best model for the fused features. Although MD has comparable AU (PRC) values with MSD on EMTD but on LMTD-9, MSD outperformed MD. Similar is the case with MS on LMTD-9. While MSD performed simultaneously well on both datasets, which is not true in the case of MS and MD individually. So, by cross dataset validation MSD proves to be a more robust one. We conclude that the proposed MSD is the best performing model.
5.4. Baseline comparison
In this section, we validate the performance of our proposed model by performing the state of art comparison with the previous approaches for movie genre classification using the AU (PRC) metric for each genre separately as depicted in Table 7. All the results mentioned in Table 7 are shown up to two decimal places and are based on the standard LMTD-9 dataset except for Fish et. al. [22], whose results are based on MMX trailer-20 dataset. It does not consider the romance genre in its study. However, for the other genres, the difference in the AU (PRC) values of Fish et. al [22] and MSD is worth noting. MSD outperforms it by 20% on average. Low-level visual features based classification [23] is based on 24 low-level visual features, SAS-MC-v2 [24] uses only the synopsis for trailer classification, Fish et. al. [22] and CTT-MMC-TN [25] are based on high-level features. Comparing to low-level feature approaches [23], [24], MSD on an average outperforms by 10%, and by comparing from approaches using high-level features [22], [25], it outperforms by 8% on an average for each genre. It is also observed comedy genre performed well in most works as compared to the other four genres while science-fiction has relatively lower AU (PRC) values. This could be due to the unavailability of proper distinction in the science-fiction genre, as its features overlap with some other similar genres (like action).

The comparative study demonstrates that the proposed model is robust as it outperforms existing approaches and gives excellent results. The better performance is due to the reason that the architecture proposed includes both cognitive and affective features, helping the model to learn substantial characteristics of each genre, hence predicting genres more precisely.
如有侵权请联系:admin#unsafe.sh