
2024-4-30 23:56:42 Author: securityboulevard.com(查看原文) 阅读量:4 收藏

In a world of increasingly powerful data analytics, security researchers continue to develop new uses for artificial intelligence (AI) and machine learning (ML). In security, predictive analytics offer insight into how a company should prioritize its activities. With more vulnerabilities detected daily, vulnerability management teams become overwhelmed, unable to patch or remediate everything all at once.
By predicting which vulnerabilities threat actors are most likely to exploit, security teams can prioritize their remediation activities, focusing on vulnerabilities that potentially have the most impact. As researchers refine their use of predictive analytics, they fill in gaps created by those who came before them.
In “Threat Class Predictor: An explainable framework for predicting vulnerability threat using topic and trend modeling,” François Labrèche and Serge-Olivier Paquette train a natural language processing (NLP) model on a robust dataset, then leverage clear & dark web social media to predict exploitability.
The researchers accessed Flare’s API to observe cybercriminal activities on the clear & dark web for their research.
Keep reading for the highlights and make sure to read Threat Class Predictor: An explainable framework for predicting vulnerability Threat using topic and trend modeling to learn more about the research.


Limitations of the Previous Research: Class Imbalance and Lack of Interpretability
Researchers have attempted to predict the vulnerabilities threat actors will most likely exploit over the years. Some examples of this research include:
- Using neural networks trained on the National Vulnerability Database (NVD) and exploit database data
- Combining NLP models with Twitter posts
- Analyzing spam lists and patching activities to determine whether these adequately responded to real-world vulnerability exploits.
While useful, much of the previous research had issues with their datasets that led to class imbalance (defined as an unequal distribution of classes, which can lead to bias in the model), ultimately undermining the analytics models’ validity and practicality.
To understand class imbalance, you can think of the datasets used as a table. In the chart below, the hypothetical researchers built a model around response to color saturation:
| Colors | Saturation | Scores |
| Blue | Light | Good |
| Pink | Medium | Poor |
| Green | Dark | Excellent |
| Purple | Medium | Poor |
| Yellow | Medium | Poor |
In the Scores column, the Poor responses far outweigh the Good or Excellent. In data analytics, this is called a “class-imbalanced dataset” because one type of outcome far outweighs the others.
When this happens, the dataset size needs to be adjusted. In the above chart, the dataset lacks too few Good and Excellent classes. Simultaneously, it only contains one Light Saturation and one Dark Saturation data point. Researchers might want to adjust their dataset by adding more variety of data points, like Light Green or Dark Blue.
In response to the previous research’s class imbalance, Labrèche and Paquette’s research combined an NLP analytics model with an expanded dataset that does not only include publicly disclosed exploit databases, but also other sources such as Github, ClamAV, PacketStorm and threat intelligence feeds.
Building a New Predictive Model
Labrèche and Paquette’s predictive analytics model is more reliable and interpretable than previous models for several reasons.
Expanded Threat Data
Similar to the previous research, Labrèche and Paquette began training their NLP with NVD data using descriptions of 152,585 vulnerabilities published between January 1, 2008, and August 1, 2022. The researchers funneled all those descriptions into a topic model that acts as a sort of word cloud builder. This model uncovered salient groups of words used to describe vulnerabilities, ultimately generating 30 basic types of vulnerability, six of which we present below.

After establishing these thirty vulnerability types, they moved on to identifying associated auxiliary features by analyzing:
- The length of the description
- The number of references available for the vulnerability at the time of publication,
- The number of software configurations affected by this vulnerability
- The CVSSv2 score
- The CVSSv2 metrics
This expanded vulnerability dataset enabled them to build a robust threat class prediction model.
Expanded Open-Source Intelligence (OSINT): Dark Web Data
Past research focused on two ways to identify threat actor exploits. Researchers used exploit databases to identify vulnerabilities used by existing threat actors and Twitter API to collect real-world conversations about exploits in-the-wild easily. However, exploit databases only provided visibility into already-available malware, meaning they lacked the real-time data element. While tweets offered the real-time element, they focused primarily on security researchers rather than threat actors.
To expand their real-time online discussion dataset, Labrèche and Paquette added an important OSINT source: the Flare API. The Flare API enabled the researchers to crawl 90 clear & dark web forums, amongst them:
- Exploit.in
- xss.is
- pediy
- nulled.to
- RaidForums
Across both the clear & dark web, Labrèche and Paquette searched for common vulnerability and exposure (CVE) mentions across a range beginning with CVE-2013 and ending with CVE-2022. For Twitter, the team tracked the following hashtags, alone and in pairs:
- #infosec
- #vulnerability
- #infosec
- #exploit
From this research, they identified the following:
- 13,114 dark web forum posts
- 36,598 Reddit posts
- 512,347 tweets
Labrèche and Paquette applied their NLP model to the collected OSINT data, enabling them to identify the vulnerabilities that the information security community and threat actors were discussing, ultimately creating a model that predicts the communication patterns associated with vulnerability disclosure.
Combining Technical and Human for Better Predictive Analytics
By analyzing online discussions combined with vulnerability data, Labrèche and Paquette’s model could predict the vulnerabilities that attackers were more likely to exploit and vulnerabilities that analysts are most likely to overlook.
The researchers analyzed two threat classes: exploit publication and malware inclusion. Although some vulnerability characteristics overlaps exist between these, the researchers were able to isolate ones unique to each.
Exploit Publication
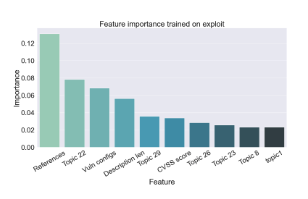
When predicting whether threat actors would leverage an exploit around a vulnerability, the analytics model found that the combination of discussions and technical characteristics included:
- Parameter, Plugins and SQL injections
- Google and OAuth Vulnerabilities
- Cross-Site Scripting (XSS) vulnerabilities
- Denial of Service (DOS) vulnerabilities
- Web vulnerabilities
- Vulnerabilities centered around network attacks
Since these exploits focus on gaining unauthorized access to web-based applications, code- and web-based weaknesses, like command injection vulnerabilities, make sense.
Malware Inclusion
Meanwhile, when predicting attackers would use a vulnerability in their malware, the top characteristics were:
- Vulnerabilities including the use of Windows handles
- PDF vulnerabilities
- Heap and buffer overflow vulnerabilities
Since malware typically installs on devices, device- and software-based vulnerabilities make sense here.
Predictive Threat Score Models Enable Remediation Prioritization
At the time of publication, Labrèche and Paquettte’s predictive models correctly identified that attackers would publish exploits using them:
- CVE-2022-34265
- CVE-2022-34918
- CVE-2022-31795
Further their models correctly identified that the following vulnerabilities would be used in malware:
- CVE-2022-22047
By incorporating dark web forum data into the threat score, predictive models become more accurate and more context-aware. With data about the vulnerabilities that threat actors find interesting, these models can combine the attacker’s human side with the attack’s technical side. By enhancing these predictive data models with dark web monitoring, security researchers can explore a vulnerability or set of vulnerabilities likely to be included in real-world attacks that are otherwise overlooked by the information security community.
CTI and Flare
The Flare Threat Exposure Management (TEM) solution empowers organizations to proactively detect, prioritize, and mitigate the types of exposures commonly exploited by threat actors. Our platform automatically scans the clear & dark web and illicit Telegram channels 24/7 to discover unknown events, prioritize risks, and deliver actionable intelligence you can use instantly to improve security.
Flare integrates into your security program in 30 minutes and often replaces several SaaS and open source tools. Learn more by signing up for our free trial.
The post Using CTI to Help Predict Vulnerability Exploitability appeared first on Flare | Cyber Threat Intel | Digital Risk Protection.
*** This is a Security Bloggers Network syndicated blog from Flare | Cyber Threat Intel | Digital Risk Protection authored by Flare. Read the original post at: https://flare.io/learn/resources/blog/using-cti-to-help-predict-vulnerability-exploitability/
如有侵权请联系:admin#unsafe.sh