Analyzing an automotive ECU firmware is sometimes quite challengin 2024-4-30 06:0:0 Author: blog.quarkslab.com(查看原文) 阅读量:22 收藏
Analyzing an automotive ECU firmware is sometimes quite challenging, especially when you cannot emulate some of its most interesting functions to find vulnerabilities, like ECUs based on Renesas RH850 system-on-chips. This article details how we managed to add support for this specific architecture into Unicorn Engine, the various challenges we faced and how we successfully used this work to emulate and analyze a specific function during an assignment.
Introduction
Renesas RH850 architecture is quite common in automotive ECUs and we often need during our assignments to analyze firmwares designed to run on this specific architecture. Reverse-engineering such firmware is one thing, being able to emulate some parts or the entirety of it is another that could be valuable to perform code coverage analysis or more generally fuzzing. And when it comes to fuzzing embedded architectures, one of the best known tools that come into mind is the Unicorn Engine, so why not improve this engine to support the RH850 architecture ?
Renesas RH850 system-on-chips rely on a V850 CPU combined with various hardware peripherals providing Ethernet, RLIN, CAN capabilities to name a few. There are different variants of CPUs in the V850 family, some of them supporting only a specific instruction set and not compatible with more recent variants. Since we owned a RH850 development board, we decided to pick the exact same CPU (V850e3, the latest variant in the RH850 CPU family) that was present in our board in order to be able to check how the emulated CPU behaves compared to a real one.
We found an existing implementation of a RH850 CPU on Github created by Marko Klopčič from iSYSTEM Labs, but this implementation seemed to be incomplete as it did not support exceptions nor FPU instructions. But it was a good starting point, so we used this implementation and improved it, adding missing nuts and bolts to eventually get a working CPU correctly emulated in Unicorn Engine.
Unicorn Engine, QEMU and TCG
Unicorn Engine relies on a modified version of Qemu to provide CPU emulation and bindings, meaning that adding a new CPU in Unicorn Engine is quite similar to adding a new CPU in Qemu. In Qemu, most of the CPU implementations rely on instruction translation rather than direct emulation.
In direct emulation, each instruction is decoded, then emulated and any effect the instruction can have on registers, memory and flags is mimicked as it is supposed to happen in the original CPU. This approach is not efficient as each instruction has to be decoded and emulated every time it is executed, introducing some latency at instruction processing level that adds up and generally leads to a noticeable overall latency that slows down the emulation of a program or firmware.
To avoid this, Qemu provides a very important component called Tiny Code Generator or TCG added in 2008 by Fabrice Bellard, that uses instruction translation to turn any emulated instruction into a set of native instructions that can be run on the host architecture CPU, as well as caching and optimizations to speed up the emulation of the original instruction. Let's dive into Qemu's TCG to understand how it works and how we can use it for CPU emulation.
Tiny Code Generator
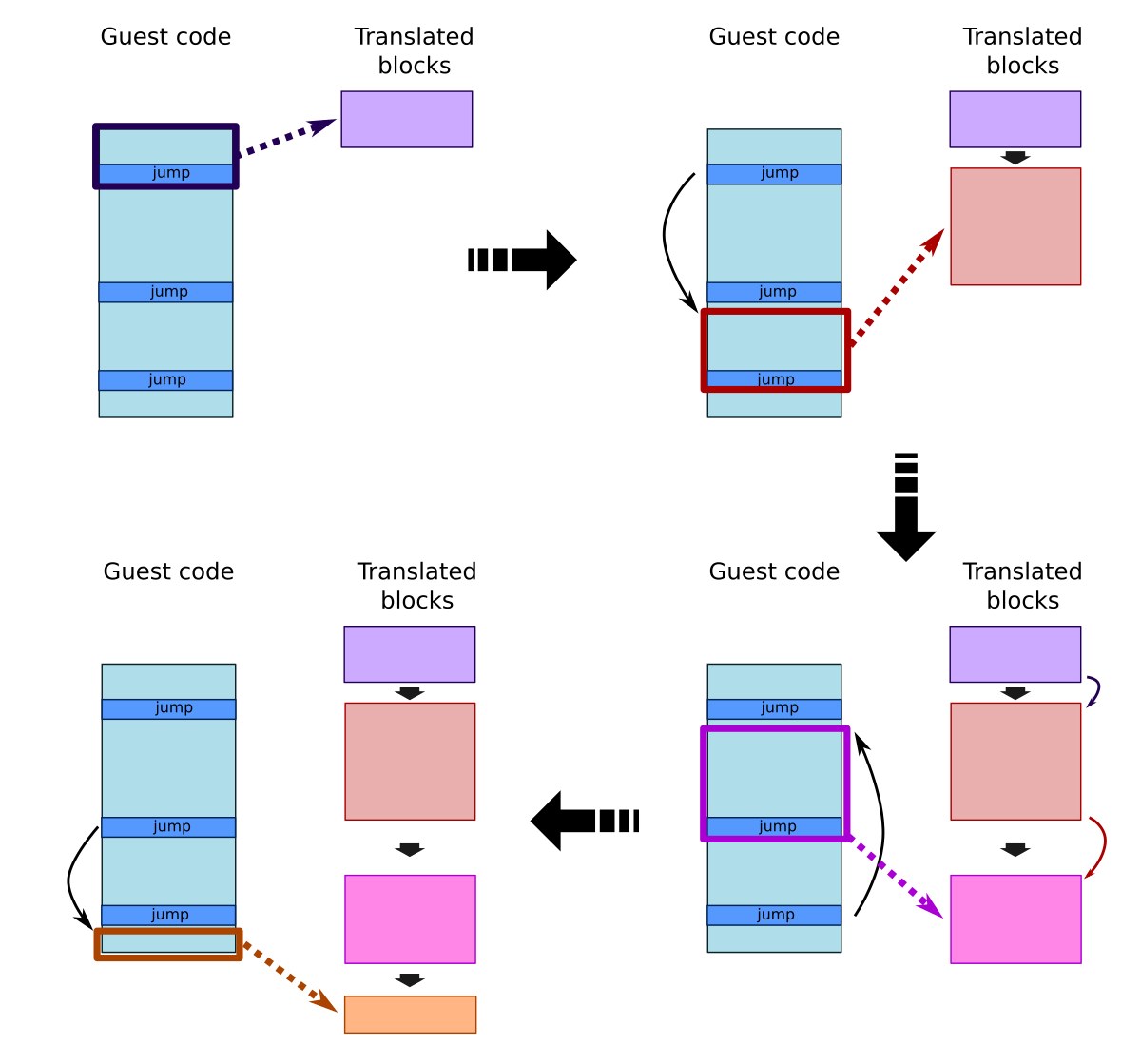
Qemu's TCG generates Intermediate Representation (IR) code for each emulated instruction that will then be translated into native code, taking advantage of the execution speed of the host. This Intermediate Representation is generated by our target CPU implementation, translating target instructions into their IR equivalent. Moreover, the TCG also breaks the emulated code into execution blocks that will be optimized, cached and linked.
![]()
QEMU TCG guest code translation
When the TCG first meets an instruction, it uses the target CPU implementation to generate the IR equivalent of this instruction and the following ones until it meets an instruction causing the CPU to jump to another location in memory (basically a jump, conditional jump or procedure call), grouping them in a translated block. Once a translated block is generated, it can be cached and executed, so if it is called again later, then the TCG will execute the same block without having to translate it again (except if the CPU state is not exactly the same, but we will cover this later). Latency is then reduced and the overall performance is improved. As shown in the above schema, translated blocks are dynamically generated by following the execution flow and kept in cache.
Qemu's TCG provides a set of basic functions (API) allowing the CPU implementation to generate a specific IR code for each supported instruction.
Writing an IR generator for an instruction
As an example, we are going to write the code to generate the Intermediate Representation for RH850's ADD instruction in its first format (ADD reg1, reg2), as defined in the documentation:

RH850 ADD instruction definition
First, we need a special function to generate some IR code to retrieve the current CPU registers value into a TCG variable:
/* Wrapper for getting reg values - need to check of reg is zero since
* cpu_gpr[0] is not actually allocated
*/
void gen_get_gpr(TCGContext *tcg_ctx, TCGv t, int reg_num)
{
if (reg_num == 0) {
tcg_gen_movi_tl(tcg_ctx, t, 0);
} else {
tcg_gen_mov_tl(tcg_ctx, t, cpu_gpr[reg_num]);
}
}
This function generates a TCG mov instruction to either set the provided register to zero (if R0 is requested because in this CPU the R0 register is always zero) or to the current value of the provided general-purpose register based on its index. Once this function is written, we also need one to write some value in our CPU general-purpose registers:
/* Wrapper for setting reg values - need to check if reg is zero since
* cpu_gpr[0] is not actually allocated. this is more for safety purposes,
* since we usually avoid calling the OP_TYPE_gen function if we see a write to
* $zero
*/
void gen_set_gpr(TCGContext *tcg_ctx, int reg_num_dst, TCGv t)
{
if (reg_num_dst != 0) {
tcg_gen_mov_tl(tcg_ctx, cpu_gpr[reg_num_dst], t);
}
}
Again, we use a mov instruction to write into our general-purpose register. Since TCG can only work with its own registers, all our general-purpose registers are declared as TCG global variables:
/* global register indices */
static TCGv cpu_gpr[NUM_GP_REGS];
Everything is set to implement the IR code generation function. We start by getting the general-purpose registers values from the register indexes passed in arguments and store them into two new TCG temporary variables named r1 and r2:
static void gen_intermediate_add_reg_reg(DisasContext *ctx, int rs1, int rs2)
{
TCGContext *tcg_ctx = ctx->uc->tcg_ctx;
TCGv r1 = tcg_temp_new(tcg_ctx);
TCGv r2 = tcg_temp_new(tcg_ctx);
TCGv tcg_result = tcg_temp_new(tcg_ctx);
gen_get_gpr(tcg_ctx, r1, rs1);
gen_get_gpr(tcg_ctx, r2, rs2);
Then, we implement the arithmetic addition using TCG's
tcg_gen_add_tl function:
tcg_gen_add_tl(tcg_ctx, tcg_result, r2, r1);
gen_set_gpr(tcg_ctx, rs2, tcg_result);
We also compute the flags based on the current registers status:
gen_flags_on_add(tcg_ctx, r1, r2);
And last but not least, we free the two temporary TCG variables:
tcg_temp_free(tcg_ctx, r1);
tcg_temp_free(tcg_ctx, r2);
}
This gives the following final function for the RH850 ADD instruction (format I):
static void gen_intermediate_add_reg_reg(DisasContext *ctx, int rs1, int rs2)
{
/* Retrieve the TCG context from Unicorn's disassembly context. */
TCGContext *tcg_ctx = ctx->uc->tcg_ctx;
/* Create two temporary TCG variables. */
TCGv r1 = tcg_temp_new(tcg_ctx);
TCGv r2 = tcg_temp_new(tcg_ctx);
gen_get_gpr(tcg_ctx, r1, rs1);
gen_get_gpr(tcg_ctx, r2, rs2);
/* Add r1 and r2 and write the result into tcg_result */
tcg_gen_add_tl(tcg_ctx, c, r2, r1);
/* Write the result into general-purpose register designed by index rs2 */
gen_set_gpr(tcg_ctx, rs2, tcg_result);
/* Update flags */
gen_flags_on_add(tcg_ctx, r1, r2);
/* Free all temporary variables. */
tcg_temp_free(tcg_ctx, r1);
tcg_temp_free(tcg_ctx, r2);
tcg_temp_free(tcg_ctx, tcg_result);
}
This function has to be called with the correct parameters extracted from the decoded instruction and will generate the equivalent IR code that will modify our CPU general-purpose registers and flags accordingly.
In our RH850 implementation, we grouped similar arithmetic functions into a single Intermediate Representation generator in order to factorize as much code as possible.
Labels, tests and jumps in IR
Sometimes it is required to implement a conditional jump inside a single
block to return two different values based on a specific condition, for
instance. This kind of behavior is implemented in the aforementioned
gen_flags_on_add() IR generator, as shown below:
static void gen_flags_on_add(TCGContext *tcg_ctx, TCGv_i32 t0, TCGv_i32 t1)
{
TCGLabel *cont;
TCGLabel *end;
TCGv_i32 tmp = tcg_temp_new_i32(tcg_ctx);
tcg_gen_movi_i32(tcg_ctx, tmp, 0);
// 'add2(rl, rh, al, ah, bl, bh) creates 64-bit values and adds them:
// [CYF : SF] = [tmp : t0] + [tmp : t1]
// While CYF is 0 or 1, SF bit 15 contains sign, so it
// must be shifted 31 bits to the right later.
tcg_gen_add2_i32(tcg_ctx, cpu_SF, cpu_CYF, t0, tmp, t1, tmp);
tcg_gen_mov_i32(tcg_ctx, cpu_ZF, cpu_SF);
tcg_gen_xor_i32(tcg_ctx, cpu_OVF, cpu_SF, t0);
tcg_gen_xor_i32(tcg_ctx, tmp, t0, t1);
tcg_gen_andc_i32(tcg_ctx, cpu_OVF, cpu_OVF, tmp);
tcg_gen_shri_i32(tcg_ctx, cpu_SF, cpu_SF, 0x1f);
tcg_gen_shri_i32(tcg_ctx, cpu_OVF, cpu_OVF, 0x1f);
tcg_temp_free_i32(tcg_ctx, tmp);
cont = gen_new_label(tcg_ctx);
end = gen_new_label(tcg_ctx);
tcg_gen_brcondi_i32(tcg_ctx, TCG_COND_NE, cpu_ZF, 0x0, cont);
tcg_gen_movi_i32(tcg_ctx, cpu_ZF, 0x1);
tcg_gen_br(tcg_ctx, end);
gen_set_label(tcg_ctx, cont);
tcg_gen_movi_i32(tcg_ctx, cpu_ZF, 0x0);
gen_set_label(tcg_ctx, end);
}
Conditional jumps as the one on line 27 of the code above require two labels to be defined, one indicating the code to be executed if the condition is satisfied and the other the code to be executed if it is not.
Labels are defined as shown on lines 3 and 4, and set with a call to gen_set_label() as shown on lines 31 and 34. They mark specific locations in the code that can be reached through jumps.
Conditional jumps are generated through specific TCG primitives such as
tcg_gen_brcondi_i32() as shown on line 27. In this
example, the execution will continue to label cont if the
zero flag is set (and the zero flag will be unset) or right after the
conditional jump if the condition is not satisfied.
Chaining translated blocks
Translating instructions manipulating the execution flow such as procedure calls, direct or conditional jumps, requires the possibility to tell QEMU which translated block must be executed next. And this is particularly true for conditional jumps that can lead to two different blocks. Each translated block has two available jump slots that can be used by the IR code to manipulate the execution flow.
In case of a simple jump for instance, the following code is used:
tcg_gen_goto_tb(tcg_context, 0);
tcg_gen_movi_tl(tcg_context, cpu_pc, dest_address);
tcg_gen_exit_tb(tcg_context, ctx->base.tb, 0);
When this IR code is first executed, the goto instruction generated
when calling tcg_gen_goto_tb() does not do anything but
allocate the first jump slot. The next line modifies the CPU state and
specifically its program counter, and the call to
tcg_gen_exit_tb() tells the TCG that it shall generate an
IR code handling the exit of the current translated block and the
first jump slot.
The translated block exit code will then evaluate the CPU state and
patch the IR goto instruction emitted by the first call to
tcg_gen_goto_tb() with the corresponding destination
translated block address. The next time this translated block is
executed, the execution will directly jump to the next translated
block address associated with this jump slot while modifying the
current CPU state accordingly. Conditional jumps are handled the same
way except it generates two goto IR instructions, one for each jump
slot, and these IR instructions will be patched on-the-fly when the
execution follows one path or the other.
Airbus SecLab wrote a blogpost series on QEMU's TCG that covers other aspects of the TCG if you want to get a better understanding on TCG and the way it translates its IR code into native code and handles memory accesses. QEMU's TCG internals are also documented in the QEMU official documentation.
Adding a new CPU into Unicorn Engine
Translating guest instructions into their IR equivalent is one thing, adding a new CPU into Unicorn Engine is another. A CPU in Unicorn Engine behaves quite the same as in QEMU: we must define a set of callbacks handling different operations on our emulated CPU, such as managing its registers and state or translate an instruction located at a specific address.
Declaring a new CPU and its callbacks
Declaring a new CPU is quite straightforward, as the code below demonstrates:
DEFAULT_VISIBILITY
void rh850_uc_init(struct uc_struct *uc)
{
uc->release = rh850_release;
uc->reg_read = rh850_reg_read;
uc->reg_write = rh850_reg_write;
uc->reg_reset = rh850_reg_reset;
uc->set_pc = rh850_set_pc;
uc->get_pc = rh850_get_pc;
uc->cpus_init = rh850_cpus_init;
uc->cpu_context_size = offsetof(CPURH850State, uc);
uc_common_init(uc);
}
This code tells Unicorn Engine the different callback functions to use
for all the required operations, including CPU initialization here
performed through the rh850_cpus_init() function. This
function basically initializes a single CPU, as shown below:
static int rh850_cpus_init(struct uc_struct *uc, const char *cpu_model)
{
RH850CPU *cpu;
cpu = cpu_rh850_init(uc, cpu_model);
if (cpu == NULL) {
return -1;
}
return 0;
}
The cpu_rh850_init() function is in charge of initializing
the CPU state the same way QEMU does, by calling a set of subfunctions
that will set some additional callbacks and the default IR generation
routine:
void gen_intermediate_code(CPUState *cpu, TranslationBlock *tb, int max_insns)
{
DisasContext dc;
translator_loop(&rh850_tr_ops, &dc.base, cpu, tb, max_insns);
}
The above function configures the translator that will analyze the guest code and generate the translated blocks. The supported translation operations are defined as follows:
static const TranslatorOps rh850_tr_ops = {
.init_disas_context = rh850_tr_init_disas_context,
.tb_start = rh850_tr_tb_start,
.insn_start = rh850_tr_insn_start,
.breakpoint_check = rh850_tr_breakpoint_check,
.translate_insn = rh850_tr_translate_insn,
.tb_stop = rh850_tr_tb_stop,
};
The translator is then able to translate any guest CPU instruction thanks to the translate_insn callback function. This function basically parses the instruction located at the program counter address and generates the corresponding IR code. We will not cover in this blogpost how instruction decoding is performed in our RH850 CPU implementation.
Unicorn Engine bindings
One of the strengths of Unicorn Engine is that it provides bindings for numerous languages such as Python, Java or Rust to name a few. These bindings are automatically generated based on a C include file for each supported architecture. The only thing we need to do is to add a new header file for our RH850 architecture telling Unicorn Engine the registers indexes to use to access the CPU state:
//> RH850 global purpose registers
typedef enum uc_rh850_reg {
UC_RH850_REG_R0 = 0,
UC_RH850_REG_R1,
UC_RH850_REG_R2,
UC_RH850_REG_R3,
UC_RH850_REG_R4,
/** ... **/
//> RH850 system registers, selection ID 2
UC_RH850_REG_HTCFG0 = UC_RH850_SYSREG_SELID2,
UC_RH850_REG_MEA = UC_RH850_SYSREG_SELID2 + 6,
UC_RH850_REG_ASID,
UC_RH850_REG_MEI,
UC_RH850_REG_PC = UC_RH850_SYSREG_SELID7 + 32,
UC_RH850_REG_ENDING
} uc_cpu_rh850;
//> RH8509 Registers aliases.
#define UC_RH850_REG_ZERO UC_RH850_REG_R0
#define UC_RH850_REG_SP UC_RH850_REG_R3
#define UC_RH850_REG_EP UC_RH850_REG_R30
#define UC_RH850_REG_LP UC_RH850_REG_R31
And that's all! Unicorn Engine will handle all the bindings generation based on this include file, for every supported languages.
Testing our implementation
We created a small python program to test the execution of a RH850 function extracted from one of the various RH850 firmware we have, namely strlen:
#!/usr/bin/env python
# Sample code for RH850 of Unicorn. Damien Cauquil <[email protected]>
#
from __future__ import print_function
from unicorn import *
from unicorn.rh850_const import *
'''
; Assembly code taken from our firmware (strlen implementation)
;
; r6 -> points to the target text string
; r10 -> computed string length
; r11 -> evaluated byte
0002876e 1f 52 mov -0x1,r10
00028770 41 52 add 0x1,r10
00028772 06 5f 00 00 ld.b 0x0[r6],r11
00028776 41 32 add 0x1,r6
00028778 60 5a cmp 0x0,r11
0002877a ba fd bne LAB_00028770
'''
# Inline bytecode for this function
RH850_CODE = b"\x1f\x52\x41\x52\x06\x5f\x00\x00\x41\x32\x60\x5a\xba\xfd"
# memory address where emulation starts
CODE_ADDRESS = 0x0
RAM_ADDRESS = 0x100
try:
# Initialize emulator in normal mode
mu = Uc(UC_ARCH_RH850, 0)
# map 2MB memory for this emulation and store our string
mu.mem_map(CODE_ADDRESS, 2*1024*1024)
mu.mem_write(RAM_ADDRESS, b'This is a test\0')
# write machine code to be emulated to memory
mu.mem_write(CODE_ADDRESS, RH850_CODE)
# initialize machine registers
mu.reg_write(UC_RH850_REG_R6, RAM_ADDRESS)
# emulate machine code in infinite time
mu.emu_start(CODE_ADDRESS, CODE_ADDRESS + len(RH850_CODE))
# Read string length (stored in R10)
print('Computed string length: %d' % mu.reg_read(UC_RH850_REG_R10))
except UcError as e:
print(e)
print("ERROR: %s" % e)
And when run, this example provides the correct number of characters for the text string "This is a test":
$ python3 rh850-strlen-example.py
Computed string length: 14
Use case: code coverage
As we often assess automotive ECUs on a gray/black box approach, we're frequently dealing with Renesas RH850 microcontroller. Being able to emulate such architecture is quite valuable when reverse-engineering the firmware of the ECU, to find or confirm vulnerabilities.
The first use-case of the RH850 emulator was an ECU acting as a gateway between the in-vehicle CAN network and third-party ones for specific adaptations. Part of the assessment was to ensure the integrity of the firmware and the calibration of the device.
A bit of context - the UDS protocol
Update of an ECU is generally done using the UDS protocol over a
CAN/Automotive-Ethernet network. Privileged access to the update
procedure is secured by a Security Access service, which
consists of a challenge-response algorithm. When requesting a
Security Access, the diagnostic tool asks for a Seed, the
challenge sent by the ECU, and sends back a Key, the response to this
challenge.
In our case, the manufacturer relies on a secure proven asymmetric
encryption scheme for such challenge, unless the device is still in Virgin mode
, where it uses a static Seed/Key.
Part of our assessment was to ensure that an attacker could not be able
to revert the ECU to a Virgin state, and to check the
entropy of the generated Seed to avoid any replay attacks, by
reverse-engineering the provided firmware.
When it comes to UDS, our first approach is to locate the main function
handling UDS request, by finding the UDS database, using a tool like
binbloom. Once
we have identified the function, we can start to understand how data are
handled/stored, like our Virgin status.
Building harness
To help us in our reverse-engineering work, being able to perform some dynamic analysis is useful. As the debug ports of the ECU are locked in production mode, we couldn't use a debugger plugged onto it. However, using the work done on the RH850 emulator, we can emulate some targeted functions to have a better understanding on their behavior or to confirm some assumptions by manipulating specific values in memory.
The first task to run our emulator is to build the harness. To do so, we
will need to map some addresses of the microcontroller, mostly the
Program Flash and parts of the RAM including
the stack. That information is provided in the
microcontroller user manual, usually under the section Memory Map.

RH850 memory map
In our case, the firmware was provided in a PDX package,
according to Open Diagnostic Data Exchange standard,
defined by ISO 22901-1. Two binary files were included in the
PDX package, one for the application, the other one for
the calibration, with an ODX file specifying the location
in memory of each part :
- Application:
0x0000C000- Calibration:
0x0000A000
Based on the microcontroller datasheet we also mapped the
RAM and the stack, so our emulator will be
able to read and write at those addresses. Note that Unicorn-engine only
supports blocks of 4KB for the various memory areas.
We also need to add the memory area for the bootloader, stored at
0x00008000, which was not provided during our assessment,
to cover various calls to those addresses.
Finally, we will need to set some value in RAM and at
least in the PC register depending on the state we want to
test and specify the start/end addresses, for example the
Virgin status using service Read Data By Identifier.
We directly target the function handling this
service, we found at 0x00018DAE.
Our basic harness will look like the following:
#!/usr/bin/python3
import math
import logging
from pwn import *
from unicorn import *
from unicorn.rh850_const import *
# Memory map
BOOT_ADDRESS = 0x00008000
BOOT_LEN = 0x00001000
CODE_ADDRESS = 0x0000C000
CALIB_ADDRESS = 0x0000A000
RAM_ADDRESS = 0xFE000000
RAM_LEN = 0x02000000
STACK_ADDRESS = 0x60000000
STACK_LEN = 0x00010000
START_ADDRESS = 0x00018DAE
END_ADDRESS = 0x00018EAE
UDS_PAYLOAD = b'\x22\xF2\xAA'
def define_memory_size(size):
if size % 4096 != 0:
size = math.ceil(size/4096)*4096
return size
if __name__ == "__main__":
logging.basicConfig()
uc = Uc(UC_ARCH_RH850, UC_MODE_LITTLE_ENDIAN)
# Loading appli
with open("bin_files/appli.bin","rb") as f:
app = f.read()
f.close()
uc.mem_map(CODE_ADDRESS, define_memory_size(len(app)))
uc.mem_write(CODE_ADDRESS, app)
# Loading calib
with open("bin_files/calib.bin","rb") as f:
calib = f.read()
f.close()
uc.mem_map(CALIB_ADDRESS, define_memory_size(len(calib)))
uc.mem_write(CALIB_ADDRESS , calib)
# Bootloader memory initialization
uc.mem_map(BOOT_ADDRESS, BOOT_LEN)
# Stack initialization
uc.mem_map(STACK_ADDRESS, STACK_LEN)
uc.reg_write(UC_RH850_REG_SP, STACK_ADDRESS + STACK_LEN)
# RAM initialization
uc.mem_map(RAM_ADDRESS, RAM_LEN)
# Registers initialization
uc.reg_write(UC_RH850_REG_PC, START_ADDRESS)
# State data
uc.mem_write(0xFFFF0625, b'\x01') # UDS message length
uc.mem_write(0xFEDD93CD, UDS_PAYLOAD) # UDS message payload
uc.mem_write(0xFEDE0C03, b'\xFF') # Virgin status (0x00 or 0xFF)
# Emulate all the things
try:
logging.info(f"UDS payload: {UDS_PAYLOAD.hex().upper()}")
logging.info("Emulating function RDBI")
logging.info(f"Starting emulation @{START_ADDRESS:#010x} to {END_ADDRESS:#010x}\n")
uc.emu_start(START_ADDRESS, END_ADDRESS, timeout=0, count=0)
except unicorn.UcError as e:
logging.error(f"Crash - Address : {uc.reg_read(UC_RH850_REG_PC):#08x}")
logging.error(e)
# Exec cmd post run
logging.info("Execution ended")
virgin_value = int.from_bytes(uc.mem_read(0xFEDE0C03, 1), 'little')
logging.info(f" Virgin: {virgin_value:#03x}")
ptr = int.from_bytes(uc.mem_read(0xFFFF6630, 4), 'little') # Pointer to UDS response
logging.info(hexdump(uc.mem_read(ptr, 0x10)))
uc.emu_stop()
Giving the following output:
user@qb:~/RH850_fuzzing$ ./emulator_harness.py
[INFO] UDS payload: 22F2AA
[INFO] Emulating function RDBI
[INFO] Starting emulation @0x00018DAE to 0x00018EAE
[INFO] Execution ended
[INFO] Virgin: 0xFF
[INFO] 00000000 00 62 F2 AA FF 00 00 00 00 00 00 00 00 00 00 00 │·bòª│ÿ···│····│···│
Unicorn and the Captain Hook
As we have our base emulator harness working, we want to be able to execute as many function as possible.
However, in the previous example, only a few parts of the
RAM are set, leading to a lot of errors when the
application wants to read the value of a pointer, as none of them are set.
We will also need to set some of the calibration data into the
RAM, like the UDS and DID (Data IDentifier used by
Read Data By Identifier) databases, which are browsed by
specific UDS handlers into the application. Those databases are arrays
of structures containing pointers to target functions, trigger conditions
(for example is a Security Access required, awaited input
length...) and other values.
To help us fix our harness, Unicorn-engine provides useful
hooks, allowing you to trigger a callback on a specific event:
UC_HOOK_INTR: hook all interrupt/syscall eventsUC_HOOK_INSN: hook a particular instruction (not all instructions supported)UC_HOOK_CODE: hook a range of codeUC_HOOK_BLOCK: hook basic blocksUC_HOOK_MEM_READ_UNMAPPED: hook for memory read on unmapped memoryUC_HOOK_MEM_WRITE_UNMAPPED: hook for invalid memory write eventsUC_HOOK_MEM_FETCH_UNMAPPED: hook for invalid memory fetch for execution eventsUC_HOOK_MEM_READ_PROT: hook for memory read on read-protected memoryUC_HOOK_MEM_WRITE_PROT: hook for memory write on write-protected memoryUC_HOOK_MEM_FETCH_PROT: hook for memory fetch on non-executable memoryUC_HOOK_MEM_READ: hook memory read eventsUC_HOOK_MEM_WRITE: hook memory write eventsUC_HOOK_MEM_READ_AFTER: hook memory read events, but only successful access
To set a hook, we need to use the function hook_add of the
Unicorn-engine. Depending on the hook, the callback will
await different parameters.
For example, if we want to get some feedback on each read attempt on a
memory address inside our RAM, we can use the following
code:
def mem_trace(uc, access, addr, size, value, user_data):
"""
mem_trace : basic hook to trace memory access (R/W)
:param uc: unicorn class
:param access: memory access type
:param addr: memory address
:param size: requested memory size
:param value: passed value for write request
:param user_data: custom data passed to the hook
"""
if access == 16 and addr >= RAM_ADDRESS:
logging.info(f"Read MEM error : {addr:#010x}")
logging.info(f" PC : {uc.reg_read(UC_RH850_REG_PC):#010x}")
logging.info(f" LP : {uc.reg_read(UC_RH850_REG_LP):#010x}")
# Set the following line before the `uc.emu_start` call
uc.hook_add(UC_HOOK_MEM_READ, mem_trace)
Using a UC_HOOK_CODE we can trigger a callback on each
instruction parsed by our emulator, allowing us to follow the execution
path:
def exec_trace(uc, address, size, user_data):
"""
exec_trace : callback to save reached addresses into a coverage file
:param uc: unicorn class
:param addr: value of PC
:param user_data: custom data passed to the hook
"""
global coverage_DB
if COVERAGE == True and address not in coverage_DB:
coverage_DB[address] = size
# Set the following line before the `uc.emu_start` call
uc.hook_add(UC_HOOK_CODE, exec_trace)
Code coverage
Our last hook allows us to record the address and length of each instruction our emulator executes. With this information we can generate a coverage file, which we can load using specific extensions like Lighthouse for IDA or Lightkeeper for Ghidra.
Using code coverage is really useful when reverse-engineering a firmware as it allows us to quickly see and understand execution paths, missed conditions and many more things.
To do so, we need to convert the address we recorded into a compatible
format for the two plugins listed above. On this assessment, we used the
drcov format.
A drcov file is defined with the following header:
DRCOV VERSION: 2
DRCOV FLAVOR: drcov
Then, it provides a Module table, listing all loaded
modules, like the various compiled libraries. As we are assessing a bare
metal firmware, we only have one module, our firmware.
Columns: id, base, end, entry, path
0, 0x00000000, 0x00177fff, 0x0000000000000000, appli.bin
The various columns are the following:
id: incremental value of each module;base: base address of the moduleend: end address of the modulepath: location of the file
Finally, the drcov file has a table of each instruction
entry, stored as a structure which can be described as follows:
struct instruction_entry {
uint32_t address;
uint16_t size;
uint16_t id; // ID of the module where the instruction is executed
}
In our case, the id will always be 0.
Before the instructions table, a final entry of the drcov
file header specifies the number of instructions stored:
For example, one drcov file generated by our emulator
could be the following:
DRCOV VERSION: 2
DRCOV FLAVOR: drcov
Module Table: version 2, count 1
Columns: id, base, end, entry, path
0, 0x00000000, 0x00177fff, 0x0000000000000000, appli.bin
BB Table: 2036 bbs
<instruction entries in binary format>
To generate a coverage file into our Python script, we used the following code:
DRCOV_HEAD = """DRCOV VERSION: 2
DRCOV FLAVOR: drcov
Module Table: version 2, count 1
Columns: id, base, end, entry, path
0, 0x00000000, 0x00177fff, 0x0000000000000000, appli.bin
BB Table: {X} bbs
"""
def save_coverage():
cov = DRCOV_HEAD.replace("{X}",str(len(coverageDB))).encode('utf-8')
for address in coverage_DB:
cov += int(address).to_bytes(4,'little')
cov += int(coverage_DB[address]).to_bytes(2,'little')
cov += int(0).to_bytes(2,'little')
with open("coverage/" + COVERAGE_FILENAME+".cov","wb") as coverage_file:
coverage_file.write(cov)
coverage_file.close()
Back to the analysis of the Virgin status, if we emulate a
simple Write Data by Identifier service to set this data
from 0x00 to 0xFF and load the generated
coverage file into Ghidra, it gives us the following result:

Code coverage listing using Lightkeeper on Ghidra
Which, once displayed as a function graph, allows us to quickly identify the non-triggered path.

Function graph using Lightkeeper on Ghidra
With such information, we can adapt our emulator to assess if it is
possible to reset the Virgin status, which can lead to a
vulnerability on the ECU (Spoiler alert: it was correctly done by the
manufacturer).
Not only with our RH850 emulator and Unicorn-engine we can
generate code coverage, but we are also able to fuzz the provided
firmware, in order to automate the findings of crashes that can also
lead to potential vulnerabilities.
Release
A pull request has been made to the Unicorn Engine Github repository that provides RH850 architecture support, but has not been merged yet.
Acknowledgments
Thanks to Anthony Rullier for his contribution to this project and the Quarkslab team for reviewing this blogpost.
If you would like to learn more about our security audits and explore how we can help you, get in touch with us!
如有侵权请联系:admin#unsafe.sh