引言
对于攻击者来说,暴力的收集数据通常会暴露基础设施和初始访问技术,他们使用的恶意软件也会被安全分析师轻松地分解掉。 机器学习在防御空间中的应用不仅增加了攻击者的成本,而且严重地限制了技术的使用寿命。 在攻击者目前所处的世界中:
· 大量的数据收集和分析对于防御软件是可以访问的,通过扩展,安全防御分析师也可以访问;
· 机器学习正在被广泛的用于加速安全防御的成熟;
· 攻击者总是处于劣势,因为我们人类试图击败自动学习系统,而自动学习系统利用每一个绕过尝试来了解更多关于我们的信息,并预测未来的绕过尝试。 对于公开的研究和静态绕过来说尤其如此。
然而,正如我们将在本文中所展示的,机器学习不仅仅是为了防御。 这篇文章将探讨攻击者如何利用他们拥有的少量数据来执行他们自己的机器学习。 我们将介绍一个侧重于初始访问的案例研究。 在这篇文章的最后,我们希望你能更好地理解机器学习,以及我们作为攻击者该如何为了自己的利益应用机器学习。
进程列表作为机器学习的数据
在讨论机器学习之前,我们需要仔细研究攻击者是如何处理信息的。 我认为,攻击者在任何一台主机或网络上收集到的可用信息不到1% ,并使用不到 3% 的收集到的信息来做出明智的决定(不要过分在意百分比)。 以机器学习的名义增加数据收集的努力将会付出隐形的代价,没有可预见的好处。 对于攻击者来说,收集更多的数据并不是最好的解决方案; 攻击者需要提高他们搜集到的数据的利用率。 但是,由于命令输出的文本性质,提升数据利用率是有困难的。 例如,除了显示特定的进程、体系结构和用户,下面的进程列表还能提供什么?
PID | ARCH | SESS | NAME | OWNER | PATH |
1 4 236 312 348 360 400 444 452 460 564 632 688 804 852 964 1004 1044 1052 1064 1120 1188 1344 1836 1972 508 828 652 684 2712 2796 2852 2928 | x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 x64 | 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 1 1 0 0 1 0 0 | System smss.exe csrss.exe wininit.exe csrss.exe winlogon.exe services.exe lsass.exe lsm.exe svchost.exe svchost.exe svchost.exe svchost.exe svchost.exe svchost.exe spoolsv.exe taskhost.exe dwm.exe svchost.exe explorer.exe svchost.exe svchost.exe UI0Detect.exe svchost.exe taskhost.exe taskhost.exe WinSAT.exe conhost.exe unsecapp.exe WmiPrvSE.exe conhost.exe svchost.exe svchost.exe svchost.exe | NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\NETWORK SERVICE NT AUTHORITY\LOCAL SERVICE NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\LOCAL SERVICE NT AUTHORITY\SYSTEM Admin-PC\Admin Admin-PC\Admin NT AUTHORITY\LOCAL SERVICE Admin-PC\Admin NT AUTHORITY\NETWORK SERVICE NT AUTHORITY\LOCAL SERVICE NT AUTHORITY\SYSTEM NT AUTHORITY\NETWORK SERVICE NT AUTHORITY\LOCAL SERVICE Admin-PC\Admin Admin-PC\Admin Admin-PC\Admin NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM Admin-PC\Admin NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM NT AUTHORITY\SYSTEM | \SystemRoot\System32\smss.exe C:\Windows\system32\csrss.exe C:\Windows\system32\wininit.exe C:\Windows\system32\csrss.exe C:\Windows\system32\winlogon.exe C:\Windows\system32\services.exe C:\Windows\system32\lsass.exe C:\Windows\system32\lsm.exe C:\Windows\system32\svchost.exe C:\Windows\system32\svchost.exe C:\Windows\System32\svchost.exe C:\Windows\System32\svchost.exe C:\Windows\system32\svchost.exe C:\Windows\system32\svchost.exe C:\Windows\System32\spoolsv.exe C:\Windows\system32\taskhost.exe C:\Windows\system32\Dwm.exe C:\Windows\system32\svchost.exe C:\Windows\Explorer.EXE C:\Windows\System32\svchost.exe C:\Windows\system32\svchost.exe C:\Windows\system32\UI0Detect.exe C:\Windows\system32\svchost.exe C:\Windows\system32\taskhost.exe C:\Windows\system32\taskhost.exe C:\Windows\system32\winsat.exe C:\Windows\system32\conhost.exe C:\Windows\system32\wbem\unsecapp.exe C:\Windows\system32\wbem\wmiprvse.exe C:\Windows\system32\conhost.exe C:\Windows\System32\svchost.exe C:\Windows\System32\svchost.exe C:\Windows\System32\svchost.exe |
文本数据也使得描述两个进程列表之间的差异变得困难——所以,问题来了,你如何描述不同主机上的进程列表之间的差异?
这个问题的解决方案已经存在——我们可以用数字来描述一个进程列表。 看看上面的进程列表,我们可以推导出一些简单的数值数据:
· 上面共有33个过程
· 进程与用户的比率为8.25
· 有4个可观察的用户
通过对项目进行数字化描述,我们可以开始分析项目的差异、排列和分类。 让我们添加第二个进程列表。
Process List A | Process List B | |
进程数 | 33 | 157 |
进程数/用户数 | 8.25 | 157 |
用户数量 | 4 | 1 |
查看并排的数字描述,显示了每个进程列表之间的明显差异。 我们现在可以得出任何给定主机上的进程列表,而不需要确切知道正在运行的进程是什么。 到目前为止,这似乎没有什么用处,但是了解到 进程列表 a 是沙箱中的,而进程列表 b 不是,我们可以检查下面的四个新的进程列表。 看看哪些是沙箱?
A | B | C | D | E | F | ||
进程数 | 33 | 157 | 30 | 84 | 195 | 34 | |
进程数/用户数 | 8.25 | 157 | 7.5 | 84 | 195 | 8.5 | |
用户数 | 4 | 1 | 4 | 1 | 1 | 4 | 主机得分 |
主机总数 | 59.25 | 315 | 54.5 | 226 | 480 | 65.5 | 168.04 |
沙箱得分 | 1 | 0 | 1 | 0 | 0 | 1 |
我们该怎么解决这个问题呢? 我们的解决方案是对每个列的值求和,然后计算主机总数的平均值。 对于每个主机总数,低于平均值的标记为沙箱也就是1,高于平均值的标记为正常主机也就是0。
A | B | C | D | E | F | ||
进程数 | 33 | 157 | 30 | 84 | 195 | 34 | |
进程数 / 用户数 | 8.25 | 157 | 7.5 | 84 | 195 | 8.5 | |
用户数量 | 4 | 1 | 4 | 1 | 1 | 4 | 主机平均得分 |
主机总数 | 59.25 | 315 | 54.5 | 226 | 480 | 65.5 | 168.04 |
沙箱得分 | 1 | 0 | 1 | 0 | 0 | 1 |
我们的解决方案似乎效果不错,然而,这完全是武断的。 很可能在使用我们的解决方案之前,你已经可以指出哪些是沙箱的进程列表。 你不仅正确地对进程列表进行了分类,而且还根据你从未见过的四个进程列表在没有文本数据的情况下进行了分类! 使用相同的数据点,我们可以使用机器学习来正确地对进程列表进行分类。
机器学习简明科普
机器学习中使用的数学技术试图复制人类的学习。 就像人类的大脑有神经元、突触和电脉冲,这些都是相互连接的; 人工神经网络有节点、权重和激活函数,这些都是相互连接的。 通过重复和在每次迭代之间做一些小的调整,人类和人工神经网络都能够进行调整,以便更接近预期的输出。 实际上,机器学习试图用数学复制你的大脑。 这两个网络也以类似的方式运作。

在生物学中,电脉冲被引入到神经网络中,电脉冲穿过突触,并被神经元处理。 来自突触的电脉冲的强度决定了神经元是否被激活。
在机器学习中,输入被引入到人工神经网络中。 输入沿着一个链接权重传递到一个节点,在那里它被传递到一个激活函数。 激活函数的输出决定了节点是否被激活。 通过迭代检查相对于目标值的输出,可以调整链接权重以减少误差。

人工神经网络(ANN)可以有任意大小。 这篇文章探讨的网络有3个输入,3个隐藏层和一个单一的输出。 关于较大的人工神经网络,需要注意的一点是每个节点之间的连接数量。 每个连接都代表我们可以执行的额外计算,这既提高了网络的效率,也提高了网络的准确性。 此外,随着人工神经网络规模的增加,数学计算并没有改变(除非你想变得复杂) ,只是计算的数量增加了。

收集和准备数据
收集进程列表的数据集相对比较容易。 任何带有宏的文档都会在沙箱中被任何一个像样的邮件过滤器执行,其余的都是普通的主机。 要从沙箱或远程系统获取进程列表,宏需要收集并提交进程列表,以便进行收集和处理。 为了进行处理,需要解析数据集。 需要计算和保存进程数量、进程与用户的比率和唯一进程数。 最后,数据集中的每个项目都需要正确地标记为0或1。 或者,宏可以从进程列表中收集数字数据并将结果提交回来。 你可以选择你自己的方式。 为了便于操作,我们更喜欢使用原始进程列表。
我们还需要对进程列表数据集进行一个转换。 前面我们将每个进程列表的总和与每个进程列表总和的平均值进行比较。 以这种方式使用平均值是有问题的,因为非常大或非常小的进程列表结果可以显著地影响到平均值。 较大的变化将重新分类潜在的大量主机,所以,我们在我们的预测中引入波动性。 为了帮助实现这一点,我们对数据集进行缩放(标准化)。 有一些技巧可以做到这一点。 我们测试了 skiket-learn 中的所有缩放函数,并选择了 StandardScalar 转换。 这里有个重要的好处是,过大或过小的值不会再对分类产生如此不稳定的影响。
A | B | C | D | E | F | |
进程数 | -0.786 | 1.285 | -0.836 | -0.065 | 1.92 | -0.770 |
进程数 / 用户数 | -0.501 | 1.652 | -0.663 | 0.521 | 0.846 | -0.648 |
唯一进程数 | 0.812 | -0.902 | 0.813 | -0.902 | -0.902 | 0.813 |
标签 | 1 | 0 | 1 | 0 | 0 | 1 |
构建和训练网络
上面示例中使用的数据是从我们的数据集中提取的。 有了它,我们就可以开始探索机器学习如何帮助攻击者检测沙箱。 在高层次上,为了成功地训练一个人工神经网络,我们将迭代:
· 将比例数据引入人工神经网络
· 计算激活函数的输出
· 以0或1(其标签)的形式向网络提供反馈
· 计算输出和反馈之间的差异
· 更新链接权重,以减少步骤4中计算的差异
你们中的一些人可能对第三步感到疑惑。我们早期成功探测沙箱的一个小而重要的细节是,我们告诉了你一个事实——“进程列表 A”是沙箱中产生的。 从那时起,进程列表 a 的值为其他所有事情提供了一个参考点。 一个人工神经网络需要一个类似的参考点,以衡量它是多么“错误”。
使用 skiket-learn,我们在190个独特的进程列表上训练了3个模型。 这些数据以3种不同的方式进行扩展,甚至合并。 最后,我们只是选择了表现最好的模式。 当网络接收到以前从未见过的进程列表数据时,网络将(希望)输出一个准确的预测。

将主机分类为1或0

上述分类的预测置信度
神经网络的暂存码可以在这里找到。 我们决定不解释所有涉及到的数学问题,尽管我们确实把它写了出来。 如果你有问题,请随时向我们提出来。 否则,如果你只是感兴趣,我们强烈推荐 Tariq Rashids 的书——《建立自己的神经网络》。
人工神经网络武器化
是时候让人工神经网络(ANN)发挥作用了。 为了测试我们的概念验证(PoC),我们编写了一个简单的宏:
· 收集了一个进程列表
· 计算输入(进程数、进程数与用户数的比值以及用户数)
· 将这些数据发回我们的服务器,并通过神经网络进行预测
· 如果神经网络预测到一个正常的主机,则执行代码,否则什么也不做
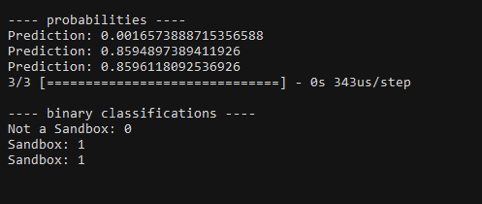
接下来,我们将恶意文档上传到几个恶意软件在线扫描器(virustotal、 malware-analysis等)并等待一会儿。我们在一个非沙箱上执行宏(第一个高亮显示的输出值),在几分钟后,两个不同的沙箱执行宏并将采集到的数据的计算值发回了我们的服务器。通过神经网络运行后,输出了3个准确的预测!

下图中显示了3个输出值(正常,沙箱,沙箱)

宏采集的数据是否为沙箱的概率和分类
根据预测的值,可以用来判断是否继续执行恶意软件。 回顾一下我们的成果:
· 从进程列表中推导出数值
· 建立这些值的数据集,并适当进行缩放
· 训练一个人工神经网络成功地根据数据集对沙箱进行分类
· 编写了一个宏来提交我们所需的值
· 发送一些测试有效载荷并使用上一步的值来预测分类
总结
希望本文是一个很好的关于攻击者如何利用机器学习能力的介绍。我们成功地将沙箱识别了出来。最值得注意的是,检查不是静态的,它利用了数据集中每个进程列表的知识。另外,我们创建的网络可以嵌入Excel文档,并在客户端进行检查。
无论我们创建的人工神经网络位于何处,机器学习无疑将改变攻击性安全的面貌。 从嵌入式网络的恶意软件,到有攻击者协助的恶意软件,可能性是无穷的(而且非常令人兴奋)。
致谢和参考来源
首先,我要感谢 Tariq Rashid (@rzeta0)的新书《构建你自己的神经网络》(Make Your Own Neural Network)。 这就是你想知道的所有关于机器学习的知识,没有所有的“数学解释”。塔里克也很友好地回答了我提出的一些问题。
其次,我要感谢微软的詹姆斯 · 麦卡弗里(James McAffrey),他帮我检查了我们的数学逻辑,让我恢复了一些理智。
如果这篇文章激起了你对机器学习的兴趣,我强烈建议你从《构建你自己的神经网络》(Make Your Own Neural Network)作为起点。
这里还有一些对我们有帮助的参考链接:
· http://hmkcode.github.io/ai/backpropagation-step-by-step/
· https://stats.stackexchange.com/questions/162988/why-sigmoid-function-instead-of-anything-else
· http://neuralnetworksanddeeplearning.com/chap1.html
· http://neuralnetworksanddeeplearning.com/chap2.html
本文翻译自:https://silentbreaksecurity.com/machine-learning-for-red-teams-part-1/本文如若转载,请注明原文地址:
如有侵权请联系:admin#unsafe.sh