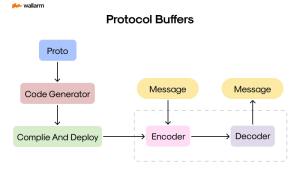
The Introduction: Decrypting Protocol Buffers
When navigating through the intricate world of data encoding and decoding mechanisms, Protocol Buffers, or widely known as Protobuf, have carved their position as a dynamic contender. The brainchild of Google, this binary blueprint aims for advanced compactness and unwavering speed, setting itself apart from its competitors, such as XML or JSON. So, let’s dissect Protobuf and highlight its importance in your forthcoming ventures.
Stripped to its bare essentials, Protobuf serves as a language-independent binary blueprint for encapsulating formatted data. Thanks to Google’s innovative approach, this system swiftly made its mark by addressing the demand for an adaptable, effective, and automated alternative for encoding and decoding organized data. Now, an increasingly extensive number of industries and projects worldwide employ it, courtesy of its uncomplicated nature, top-notch performance, and versatility.
<code class="language-protobuf">message Person {
string name = 1;
int32 id = 2;
string email = 3;
}</code>
In the given Protobuf fragment above, we outline an elementary message type "Person" incorporating three distinct fields: name, id, and email. Each of these fields is paired with a unique numeral for binary encoding purposes.
However, describing Protobuf as merely a data format would be an oversimplification. It also propagates a pool of resources to streamline data handling. The protocol buffer compiler, protoc, comes in handy to derive data access classes in multiple languages from a fundamental schema description.
<code class="language-bash">protoc --java_out=. Person.proto</code>
The command displayed above leverages protoc to formulate Java classes stemmed from the Person.proto schema description.
Protobuf’s prowess lies in its superior efficacy. It outshines JSON or XML by offering condensed and rapid serialization/deserialization of messages. Consequently, Protobuf becomes the go-to choice for intensive data structures, or when speed is of the essence.
| Encoding Technique | Capacity | Encoding Duration | Decoding Duration |
|---|---|---|---|
| Protobuf | Minimal | Quick | Quick |
| JSON | Voluminous | Gradual | Gradual |
| XML | Extensive | Prolonged | Prolonged |
In the above comparison, the capacity and performance metrics of Protobuf, JSON, and XML are juxtaposed. Evidently, Protobuf surpasses the others in terms of both capacity efficiency and pace.
Stay connected through the next sections as we traverse deeper into the world of Protobuf, deciphering its architecture, operational process, and potential applications in practical situations. At this juncture, we will also juxtapose it against other data encoding mechanisms like JSON and XML, assessing the merits and drawbacks of employing Protobuf. So, keep an eye out to gather more insights about this efficient tool for data encoding and decoding.
A Deep Dive into Protobuf: A Modern Remediation for Complex Data Structure Issues
In the continuously evolving world of information systems, the race is on to develop leaner, faster, and more seamless solutions. Swiftly entering the scene, Google’s Protocol Buffers, often referred to as Protobuf, serves as the cutting-edge recourse for such requirements. In this section, we seek to illuminate how Protobuf could bring about a game-changing shift in your prevailing data structuring dilemmas.
Hailing from the tech titan Google, Protobuf emerges as a versatile, effective, and self-sustaining approach to simplify complex data. The translation of Protobuf is delivered in a compact binary model, proposing an expedited, less convoluted, and more concise alternative to options such as JSON or XML. Because of its language-neutral character, Protobuf can concurrently interact with a vast array of coding languages, thereby extending its usefulness for developers.
To grasp the fundamental application of Protobuf, take this base sample of a Python data layout:
<code class="language-python"> class Apprentice:
def __init__(self, moniker, age, email):
self.moniker = moniker
self.age = age
self.email = email</code>
And here’s how Protobuf will replicate the same schema:
<code class="language-protobuf">message Apprentice {
string moniker = 1;
int32 age = 2;
string email = 3;
}</code>
Clearly, this exhibits the neatness and brevity of the Protobuf format. Each field within the message is accorded a distinctive number, ensuring effortless recognition within the binary message makeup, presumed to stay intact after the message type is initiated.
Make a comparative analysis of the relative data sizes when serialized in JSON and Protobuf and it brings to light the true benefits of Protobuf’s succinctness. Suppose we manage a group of 1000 apprentices, the JSON serialized data could potentially be about 50KB, whereas with Protobuf, it might only amount to 10KB.
| Serialization Style | Data Size Post-Serialization |
|---|---|
| JSON | 50KB |
| Protobuf | 10KB |
Thanks to its compactness and efficacy, Protobuf is rapidly becoming the chosen framework for robust, data-intensive apps. Its strength is particularly evident when structuring microservices, which necessitate constant exchange of streamlined, agile, and accurate data snippets. Furthermore, Protobuf gains favor in the IoT ecosystem where devices with limited resources require optimal data movement.
To recap, Protobuf delivers an exceptional performance for managing data structures through its competence, speed, and language-neutrality. It introduces versatility across a vast spectrum of programming scenarios. Whether your goal is to handle massive data dissemination or smooth out inter-service dialogues, Protobuf might just be the ultimate solution in resolving any complex data structuring challenges.
A Deeper Dive Into Protobuf: Interpretation and Summary
Transforming raw data into a uniform format that can be shared and understood by multiple systems, or data serialization, might come off as tricky. Luckily, Google’s Protocol Buffers, fondly referred to as Protobuf, makes this complex process feel like a breeze. Available at no cost, Protobuf is an open-source technology offering an effective and simplified data serialization method that packages data into a format that’s both time-efficient and compact.
Protobuf is versatile and can be used with various programming languages and platforms. Consequently, it finds numerous applications, including data archiving and facilitating communication protocols.
To truly comprehend the functionality of Protobuf, one must be familiar with its essential attributes:
-
Message: Protobuf uses messages as a fundamental unit for data encapsulation. A message is a unique information dataset comprising numerous tag-value pairs.
<code class="language-protobuf">message Person { string name = 1; int32 id = 2; string email = 3; }</code>In this example,
Personis a message entity with the following elements:name,id, andemail. -
Field: Messages are composed of fields, which are the foundational elements of any message structure. A field is unique because of its numeric tag, coupled with a name-value pairing.
-
Data Types: Protobuf handles an array of basic data types, including booleans, integer values, string data type, and floating-point numbers, among others.
<code class="language-protobuf">message Test { int32 x = 1; bool y = 2; string z = 3; }</code>Within this context,
xsignifies an integer,ydenotes a boolean value, andzsymbolizes a string. -
Encoding: Protobuf leverages a binary encoding method, which, when compared with XML and JSON formats, is faster and more compact.
-
Schema: Any data architecture within Protobuf is determined by a schema. It is this schema that is depicted in the
.protofile.<code class="language-protobuf">syntax = "proto3"; message SearchParameters { string query = 1; int32 page_number = 2; int32 result_per_page = 3; }</code>Here,
SearchParametersis defined by a schema incorporating three fields:query,page_number, andresult_per_page. -
Serialization and Deserialization: Serialization refers to the conversion of structured data into binary data, while deserialization is the inverse process of turning binary data into structured data.
<code class="language-python"># Python sample code person = Person(name="John", id=1234, email="[email protected]") serialized_person = person.SerializeToString() deserialized_person = Person() deserialized_person.ParseFromString(serialized_person)</code>
The Python sample code above demonstrates the creation of a Person object, its conversion into a string (serialization), and its conversion back into a Person object (deserialization).
In summary, Protobuf is a powerful tool for handling data serialization, given its compact design and high efficiency. Whether it’s for simple microservices or more complex data storage and processing tasks, Protobuf’s adaptability makes it a preferred option. Gaining mastery of its basics is an important stepping stone in fully appreciating its vast capabilities.
`
`
Unveiling Protobuf – Its Composition and Operational Mechanics
Understanding Protocol Buffers, more casually known as Protobuf, is facilitated by investigating its inherent structure and functionality. Essentially, Protobuf is a mechanism for data serialization, curated by Google. It is characterized by flexibility, ample efficiency, and automated serialization of systematic data collections. Let’s reveal more about the inner framework of Protobuf and precisely how it functions.
1. Decoding Message Format
Protobuf operates by first defining the structure of messages that are to be serialized. This is generally accomplished using a .proto file and a distinct language. A rudimentary example would be:
<code> message Persona {
required string completeName = 1;
required int32 idNumber = 2;
optional string emailContact = 3;
}</code>
In this instance, we specify a message "Persona" that encompasses three elements – "completeName," "idNumber," and "emailContact". The word "required" denotes field values that must be inputted, whereas "optional" stands for values that can be included at will. The numbers function as individual identifiers for each field, promoting binary encoding.
2. Converting Message Structure to Classes
Post defining the message structure, it’s then morphed into its assembled form using Protobuf’s inherent compiler, protoc. The outcome is a set of data access classes, executed in the programming language of your preference (Java, Python, C++, etc.). These classes allow easier access points to each field (like sprintf_completename() and get_completename()) and methods to serialize or parse the entire structure to/from bit sequences.
3. Modifying and Reinstating Data
The modification process turns data compositions or object states into a form storable or transferrable, with the capability of being reassembled later. Pertaining to Protobuf, this procedure is engaged by employing the generated classes. Here’s an example based in Python language:
<code class="language-python"> import persona_pb2 # Generate a new persona persona = persona_pb2.Persona() persona.idNumber = 1234 persona.completeName = "John Doe" persona.emailContact = "[email protected]" # Modify the persona modified_persona = persona.ModifyToString()</code>
On the flip side, reinstating is the reversing operation, modifying raw binary sequences back into a usable data structure. Here’s how it can potentially be accomplished:
<code class="language-python"> # Define a new persona persona = persona_pb2.Persona() # Decipher the modified data persona.ParseFromString(modified_persona) # Now, the new persona contains the same data as the initial one print(persona.completeName) # prints "John Doe"</code>
4. Data Evolution
Protobuf enables the evolution of data structures. This implies that you can add new fields to your message blueprint without disrupting older applications. If a program comes across a message encompassing unfamiliar fields, it still has the prowess to reinstate the message and even remodel it, maintaining the unknown fields preserved.
In closure, the inner setup of a Protocol Buffer includes defining a message layout, converting it into classes, and using these classes for data modification and reinstatement. With its flexibility, efficiency, and reverse compatibility, Protobuf establishes itself as a highly effective resource. It’s thus suitable for programmers looking for a proficient method for data structure serialization.
Unleashing the Power of Protobuf in Real-World Situations
Protocol Buffers (Protobuf), a leading component in data structuring, has revolutionized data serialization with their adaptability, effectiveness, and automation. Wondering about its practical usefulness? Here, let’s examine some of the tangible uses of Protobuf for a better comprehension of its value.
1. Intercommunication in Microservices
Independently deployable services configured via the modern technique of microservices architecture, frequently employs Protobuf to translate data exchanged among these services.
Imagine Service A needs to communicate a message to Service B. Protobuf introduces efficiency here. Service A creates the blueprint of the message in a .proto file, using this to produce code in the chosen language, and then this code is utilized to convert the message into a binary configuration. Conversely, Service B operates the identical .proto file to transform the message back into an operational format.
<code class="language-proto">syntax = "proto3";
message User {
string name = 1;
int32 age = 2;
string email = 3;
}</code>
The .proto file, as demonstrated above, shapes a User message encompassing three fields: name, age, and email. Post compilation into any preferred language, the acquired code can be applied to transform or reshape User messages.
2. Data Archiving and Recovery
Protobuf performs an essential role in saving and reviving data. Think of a database system scenario where Protobuf performs the task of translating data prior to its storage. When this stored data has to be accessed again, Protobuf aids in reviving it to its initial format.
Several benefits are associated with this methodology. The translated data is condensed, generating a considerable decrease in storage requirements. Moreover, Protobuf allows a distinct structure format to the stored data, easing the processes of data revival and management.
3. Connecting Networks
In the domain of network connectivity, especially where efficiency and signal delay are influential metrics, Protobuf has a key role, thanks to its ability to translate data into an encapsulated binary form, enabling substantial reduction in the volume of data transmitted, thereby enhancing network function and conserving bandwidth.
For example, a mobile app needs to communicate with a server, Protobuf comes in handy by converting the data into a condensed form before being dispatched, reducing the data transmission requirement. This feature proves beneficial particularly in limited bandwidth areas.
<code class="language-proto">syntax = "proto3";
message Request {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}</code>
The .proto file above characterizes a Request message meant to deliver a query to a server. The resultant binary data is compressed and is effectively transported over the network.
To sum up, Protobuf is applied across various tangible situations, ranging from intercommunication in microservices to data archiving and network connections. Its competence in transforming data into an efficient and compact binary framework endorses its stature as a key player in the arena of data serialization.
Conducting an Analytical Evaluation: Protobuf in Comparison with JSON and XML
In the domain of data encapsulation, three prominent entities are universally recognized: Protobuf, JSON, and XML. Each member of this trio presents a unique fusion of skills, positives, and limitations. The subsequent chapter unravels and chalks the dissimilarities amid Protobuf and its rivals – JSON and XML – to facilitate you in electing the most fitting format tailor-made for your specific necessities.
1. Dissecting Data Size and Competence
Protobuf holds a high pedestal due to its dexterity and crispness. It utilizes a binary encapsulation method, crafting a noticeably shrunk data magnitude when juxtaposed against JSON and XML which utilize text-based encapsulation. Owing to its miniature dimension, Protobuf is an optimal choice for networking and storage situations demanding stringent cognizance towards bandwidth conservation and storage efficiency.
<code class="language-protobuf">individual Details {
unique-string name = 1;
integer id = 2;
unique-string email = 3;
}</code>
Corresponding JSON structure:
<code class="language-json">{
"name": "John Doe",
"id": 789,
"email": "[email protected]"
}</code>
Comparable XML structure:
<code class="language-xml"><details> <name>John Doe</name> <id>789</id> <email>[email protected]</email> </details></code>
Evidently, Protobuf maintains a more compact form compared to JSON and XML.
2. Decipherability
While Protobuf excels in robustness, it forfeits in decipherability. JSON and XML models cater a perceptible and comprehensible outlook even to novices in programming. Conversely, Protobuf, due to its binary character, isn’t inherently comprehensible and could lead to complications during troubleshooting or manual data alterations.
3. Metadata Accommodation
XML is self-sufficient in conveying metadata, thereby being self-descriptive. Though JSON is less exhaustive, it does render some degree of metadata. Contrarily, Protobuf deliberately obfuscates metadata. While this leads to a reduced data magnitude during encapsulation, it concurrently cultivates a reliance on the schema to decrypt the data.
4. Schema Revolution
Schema revolution is innately encapsulated within Protobuf. It enables the seamless addition of new fields to message structures, ensuring traditional applications remain unperturbed. JSON provides minimal support for schema evolution, whereas XML fails to match the ease that Protobuf and JSON contribute in this specific attribute.
5. Instruments and Compatibility
Given their prolonged existence, JSON and XML flaunt a comprehensive operational span and abundant language interoperability. Even though Protobuf hasn’t achieved comparable extent in backing, it is in agreement with languages like Java, Python, C++, among others. Nonetheless, for a few languages, dependence on tertiary libraries might be mandated.
In wrapping up, the preference amongst Protobuf, JSON, and XML primarily hinges on your specific scenarios and requisites. If efficiency and performance steer your focus, Protobuf might be your answer. Conversely, if you prefer human-decipherability and wide language interoperability, JSON or XML could suit you better.
`
`
Delving Into Protocol Buffers: Unraveling Its Pros and Cons

The landscape of data serialization has recently seen the rise of Protocol Buffers, commonly known as Protobuf. Like any technology tool, it comes with its own set of advantages and disadvantages. In this section, we will explore the positive and negative sides of using Protobuf to broaden your understanding and help you make a well-informed decision.
Upsides of Protobuf
1. Efficiency in Operation: Protobuf stands out for its efficiency concerning size and quickness. It reduces datasets into a binary format, offering leaner payloads than JSON or XML. This efficiency translates to significant reductions in bandwidth and storage, essential when dealing with large data amounts.
<code class="language-python"># Serialization in Protobuf proto_data = data_pb2.Data() proto_data.name = "Jane Smith" proto_data.id = 5678 proto_data.email = "[email protected]" serialized_proto_data = proto_data.SerializeToString() # Serialization in JSON json_data = { "name": "Jane Smith", "id": 5678, "email": "[email protected]" } serialized_json_data = json.dumps(json_data)</code>
In the provided code snippet, serialized_proto_data is typically smaller than serialized_json_data.
2. Type Rigidity: Protobuf strictly observes data types. This requires a predetermined data structure and type, helping identify mistakes early during the coding process.
3. Backward and Forward Compatibility: Protobuf permits adding new fields to your data structure without breaking older applications that are unaware of these new fields, easing the evolution of your data structure.
4. Cross-Language and Cross-Platform: Protobuf caters to a wide variety of programming languages and platforms, showing its adaptability to different uses.
Downsides of Protobuf Utilization
1. Decipherability Issue: Unlike JSON or XML, Protobuf cannot be readily interpreted by humans, making debugging difficult as opening a Protobuf file in a text editor to browse its contents isn’t feasible.
2. Intricate Structure: Protobuf requires a separate compilation step to generate data access classes, complicating your build process.
3. Lack of Out-of-the-box Support: Even though Protobuf caters to numerous languages, some mainstream ones like JavaScript are not supported natively. Thus, turning to third-party libraries becomes inevitable, potentially introducing compatibility problems and extra dependencies.
4. Limited Metadata: Data serialization in Protobuf doesn’t support comments or other forms of metadata, making it tough to understand data context without additional documentation.
To sum up, Protobuf offers several benefits like efficiency, type rigidity, and compatibility. However, it also has its downsides like decipherability issues, intricate structure, and lack of out-of-the-box support. Therefore, whether to choose Protobuf or not should depend on your specific requirements and conditions.
The post What is Protobuf? appeared first on Wallarm.
*** This is a Security Bloggers Network syndicated blog from Wallarm authored by Ivan Novikov. Read the original post at: https://lab.wallarm.com/what/what-is-protobuf/
如有侵权请联系:admin#unsafe.sh