如果你是想谈业务合作,直接翻到底联系作者。
不闲聊,直接说重点,我能不能做,你有没有预算,相关先介绍(我介绍技术、或者方案产品,你介绍需求带预算)就完事。
云桌面开发相关: 虚拟化(usb、usb透传、显示器、网卡、磁盘、声卡、摄像头)模块。
安全产品(dlp/edr/沙箱)开发相关:文件单/双缓冲透明加解密、网络防火防墙、所有通用外设管控(用户层版/驱动层版)模块、其它管理(恶意进程、模块等)。
通用开发相关:注入、hook、产品方案编写与设计、非黑灰产逆向、具体单独小功能编写。
如果你想系统学习二进制漏洞技能,往最后翻,或者直接翻到底联系作者。
所有最新的华为设备都附带了安全管理程序,这是一种旨在增强内核安全性的纵深防御措施。与其他原始设备制造商不同,华为对这种特权软件进行了加密,因此它几乎没有受到公众的监督。通过这篇博文,我们旨在阐明其内部工作原理,并对其实现进行深入分析,从其入口点到专门用于在运行时保护内核的功能。
目录
介绍
概述
检索虚拟机监控程序二进制文件
分析虚拟机管理程序二进制文件
ARM 虚拟化扩展
华为Hypervisor执行环境
初始化
ARM 虚拟内存管理进修课程
在虚拟机管理程序中映射内存
在第二阶段映射内存
虚拟机监控程序的虚拟地址空间
初始化第二转换阶段
打开主内核的电源
全局和本地状态
主核心引导
辅助内核启动
虚拟内存管理
异常处理
虚拟机监控程序调用
安全监控呼叫
处理内核页表
内核页表写入
第 1 阶段页面表遍历期间的第 2 阶段故障
指令中止处理
数据中止处理
CRn 1:SCTLR_EL1
CRn 2:TTBR0_EL1、TTBR1_EL1和TCR_EL1
CRn 5:AFSR0_EL1、AFSR1_EL1和ESR_EL1
CRn 6:FAR_EL1
CRn 10:MAIR_EL1和AMAIR_EL1
CRn 13:CONTEXTIDR_EL1
陷阱指令处理
指令和数据中止处理
内核页表管理
虚拟机监控程序和安全监控器调用
结论
引用
在移动设备领域,利用单个内核漏洞执行任意代码或修改内核数据结构足以完全破坏系统的日子已经一去不复返了。供应商通过引入新技术来增强其产品的安全性,从而解决了这些问题。对于基于 ARM 的设备,最突出的安全功能是 ARM TrustZone,这是 CPU 中的一个安全区域,在隔离环境中与主操作系统同时执行。
然而,还有其他鲜为人知的组件旨在强化设备,包括依赖于 ARM 虚拟化扩展的安全虚拟机管理程序。虚拟化传统上用于模拟操作系统完全隔离执行的多个硬件环境。在安全虚拟机管理程序的情况下,隔离功能被用来监视单个内核,并确保其在运行时的完整性,主要是通过过滤物理内存访问和拦截关键操作。
大多数主要的Android手机制造商,如高通、三星和华为,都开发了自己的安全管理程序实现。过去,我们详细介绍了三星 RKP 的内部结构,三星的实现,并解释了我们如何破坏它。在这篇博文中,我们将调查华为的安全管理程序,该组件部署在所有最近的华为手机上,据我们所知,该组件从未受到任何公众审查。
我们首先概述了 ARM 虚拟化扩展,并介绍了安全虚拟机管理程序的概念。然后,我们深入探讨了华为的实现,并详细介绍了虚拟机管理程序的启动过程及其内存管理系统。我们继续解释系统寄存器写入的拦截,以及错误内存访问导致的指令和数据中止,如何使虚拟机监控程序能够保持对内核页表的控制。此外,我们还描述了如何使用虚拟机监控程序和监视器调用来保护各种内核数据。
ARM 虚拟化扩展¶
现代软件被拆分为不同的组件,每个组件都需要对系统和处理器资源进行自己的访问级别。在 ARMv8-A 体系结构中,权限分为不同的级别,称为异常级别 (EL),编号范围从 EL0(最低特权)到 EL3(最高特权)。异常级别还分为两种安全状态,即“安全”和“非安全”,它们将系统分为两个环境,其中:
我们直接与之交互的常规用户应用程序是无特权的,并在 EL0 上运行;
内核需要更高级别的访问,在 EL1 处执行;
一个以安全为中心的虚拟机管理程序,甚至是一个成熟的虚拟机管理程序,运行在 EL2 上;
最后是 EL3 的安全监视器,它负责在两个世界之间切换,并可以访问安全和非安全资源。
![]()
当前 EL 只有在处理器发生异常时才能变高,或者当它使用异常返回 (ERET) 指令从一个处理器返回时才会变低。用户应用程序 (EL0) 可以使用 Supervisor 调用 (SVC) 指令调用内核 (EL1),该指令会触发同步异常,然后由内核处理。同样,可以使用虚拟机监控程序调用 (HVC) 指令调入虚拟机监控程序 (EL2),使用安全监控程序调用 (SMC) 指令调入安全监控器。
为了防止在较低 EL 上运行的组件破坏隔离,虚拟机监控程序需要模拟关键操作,包括对特权系统寄存器的读取和写入。为此,虚拟化扩展引入了所谓的捕获特定操作。当操作被捕获时,不会像往常一样在 EL1 上执行,而是引发异常,并在 EL2 上处理该操作。另一个系统寄存器,即虚拟机监控程序控制寄存器(),控制应捕获哪些操作。HCR_EL2
限制也适用于内核的虚拟地址空间。为此,地址转换通过第二阶段进行扩展,该阶段使用自己的一组页表,这些页表完全在虚拟机管理程序的控制之下。启用此机制后,仍会执行阶段 1 页表的标准遍历,从转换表基寄存器中保存的基址开始(对于 EL0 访问和 EL1 访问)。但是,生成的输出地址不是将虚拟地址 (VA) 直接转换为物理地址 (PA),而是中间物理地址 (IPA)。然后,需要通过遍历第 2 阶段页表将该 IPA 转换为最终的 PA,从虚拟化转换表基寄存器()中保存的基址开始。在这两个阶段中的每一个阶段,都可以在转换表中指定不同的访问控制,并将其应用于内存页。TTBR0_EL1TTBR1_EL1VTTBR_EL2
![]()
在简要介绍了ARM架构提供的基本构建模块之后,我们再来关注华为如何使用它们来构建其安全管理程序。
华为Hypervisor执行环境¶
华为Hypervisor Execution Environment(简称HHEE)是华为的安全Hypervisor实现。如上一节所述,它的主要作用是在运行时监督内核,并防止对系统进行导致权限提升的更改。为了分析 HHEE,第一步是检索其二进制文件。
检索虚拟机监控程序二进制文件¶
华为设备的安全研究入门成本很高。关键二进制文件,无论是存储在设备上还是作为 OTA 更新的一部分,都始终是加密的。除非您设法泄露密钥,否则解密它们需要在引导链的早期通过攻击本身加密的组件(如 Bootrom、Xloader 或 Fastboot)来接管设备。但是,在没有目标二进制文件的明文版本的情况下查找和利用漏洞可能非常具有挑战性。
幸运的是,Taszk 和 Pangu 等安全研究团队已经公布了华为 Bootrom 中一个可利用漏洞的详细信息。虽然它不会影响最新的麒麟 9000 芯片组,但所有旧设备都容易受到攻击。但是,华为通过Taszk博客上详述的有趣技巧,设法通过软件更新解决了这个问题。
一旦我们控制了 Bootrom,解密方法就取决于芯片组版本。对于旧版本,加密密钥可以直接从保险丝中提取,而在较新的芯片组上,该设备必须用作解密预言机。在这两种情况下,我们最终都会得到可供分析的明文二进制文件。
分析虚拟机管理程序二进制文件¶
在这篇博文中,我们将记录从华为 P40 Pro 固件中提取的 HHEE 映像的内部工作原理。这个二进制文件的基址,需要将其加载到自己喜欢的SRE框架中,可以在华为开源网站上提供的内核源代码中找到。11.0.0.260
▸ drivers/hisi/ap/platform/kirin990_cs2/global_ddr_map.h
#define HISI_RESERVED_HHEE_PHYMEM_BASE 0x10F00000
#define HISI_RESERVED_HHEE_PHYMEM_SIZE (0x600000)
快速浏览一下拆解的二进制文件就会发现它是独立的,而且相当小(大约 300 个函数)。但是,它没有符号,也没有有用的字符串,这些字符串有助于逆向工程。幸运的是,由于内核必须调用虚拟机管理程序,因此可以使用内核端定义来推断相应虚拟机管理程序函数的预期功能。HVC 的所有名称都可以在 和 文件中找到。include/linux/hisi/hkip_hhee.hinclude/linux/hisi/hhee_prmem.h
本文的其余部分将全面描述虚拟机管理程序的设计选择和内部工作原理,这些都是我们最好的逆向工程工作的结果。应该注意的是,函数、变量和类型的所有名称都是我们自己的。
打开主内核的电源¶
当华为设备开机时,启动Android(或者更确切地说,HarmonyOS)是一个多阶段的过程。它从 Bootrom 开始,它进行第一次初始化操作,并为引导链中的第二阶段准备设备:Xloader(和 UCE)。Xloader 由 Bootrom 解密和验证,然后执行移交给它以继续初始化麒麟特定的组件和设置。然后执行进入第三阶段,即 Fastboot,在这个阶段,事情对我们来说变得有趣。该组件是 Android 生态系统的一部分,可以使用同名协议进行交互。它实现不同的命令,允许用户执行多个操作,例如刷新分区、解锁其设备或更改特定于供应商的设置。但是,在正常启动过程中,它主要负责加载 Android 内核及其依赖的所有组件,即虚拟机管理程序。
到目前为止,每个组件都以 EL3 的速度运行在单个 CPU 内核(主内核)上。在启动过程中,当 Fastboot 的任务是将内核加载到内存中时,主内核将首先加载安全监视器(如果我们遵循 ATF 的命名法,则为 BL31)、安全虚拟机管理程序和受信任的操作系统。然后,我们进入启动阶段,在监视器和虚拟机管理程序中绕道而行,最后跳转到 EL1 的内核。
![]()
下一节将详细解释虚拟机管理程序中发生的情况,从监视器启动虚拟机管理程序的那一刻到将控制权移交给内核的那一刻。虽然它只详细介绍了主内核执行的操作,但之后我们将回到辅助内核。
全局和本地状态¶
在深入研究初始化代码之前,我们首先需要介绍两个被 HHEE 广泛使用的结构。
第一种结构是 ,它实际上是一个链表,可以在使用字段时进行迭代。此结构用于存储每个 CPU 的状态,每个启动的核心都有自己的实例。cpu_listnext
typedef struct cpu_list {
uint64_t mpidr_el1;
cpu_list_t* next;
sys_regs_t* sys_regs;
uint8_t is_booted;
uint8_t kernel_pt_processed;
} cpu_list_t;
链表的头部存储在g_cpu_list全局变量中。
cpu_list_t g_cpu_list;
当前内核的实例也存储在其系统寄存器中,可以使用 current_cpu 宏进行检索。TPIDR_EL2
#define current_cpu (cpu_list_t*)get_tpidr_el2()
第二种结构是 ,它包含最重要的系统寄存器的保存值。sys_regs
typedef struct sys_regs {
uint8_t regs_inited;
uint64_t mair_el1;
uint64_t tcr_el1;
uint64_t ttbr_el1;
uint64_t unkn_20;
uint64_t elr_el2;
uint32_t unkn_30;
uint32_t unkn_34;
} sys_regs_t;
由于所有内核的保存值都相同,因此所有字段都指向单个实例g_sysregs。sys_regscpu_list
sys_regs_t g_sysregs;
主核心引导¶
如前所述,控制权从监视器移交,主 CPU 内核以entrypoint_primary启动虚拟机管理程序的执行。此函数执行下面列出的操作。
由于我们目前只有一个物理地址空间,因此我们确保禁用 MMU、WXN 和 PAN。一旦设置了虚拟地址空间,它们就会被启用。
堆栈 cookie 的全局值使用当前 CPU 物理计时器进行初始化。stack_chk_guard_setup
EL2 线程本地存储器设置为指向 g_cpu_list 的指针,其中包含寄存器值和与执行相关的信息。
异常向量表和堆已初始化。
void entrypoint_primary(saved_regs_t args) {
// SCTRL_EL2, System Control Register (EL2).
//
// - M, bit [0] = 0: MMU disabled.
// - WXN, bit [19] = 0: WXN disabled.
// - SPAN, bit [23] = 1: The value of PSTATE.PAN is left unchanged on taking an exception to EL2.
set_sctlr_el2(0x30c5103a);
// Initializes the stack cookie using the CNTPCT_EL0 system register.
stack_chk_guard_setup();
// TPIDR_EL2 holds a per-CPU object that contains saved register values and information related to the execution.
set_tpidr_el2(&g_cpu_list);
// Sets the exception vector table (VBAR_EL2) for the current CPU.
set_vbar_el2(SynchronousExceptionSP0);
// ...
// Initializes the heap.
g_heap_start = &heap_start;
g_heap_size = 0x5b7680;
// Boots the primary core.
boot_primary_core(&args);
// Now that the hypervisor has been initialized, the execution can continue in the kernel at EL1.
asm("eret");
}
然后,我们到达 boot_primary_core 函数,该函数调用 init_memory_mappings 来创建虚拟机管理程序的虚拟地址空间,并调用map_stage2来设置第二个转换阶段。
void boot_primary_core(saved_regs_t* regs) {
// Initializes the shared buffers used to send logs from the hypervisor to other components.
init_log_buffers(regs);
// ...
// Allocates the hypervisor page tables, maps the hypervisor internal ranges, and enables addresses translation.
init_memory_mappings();
// ...
current_cpu->sys_regs = &g_sysregs;
// Maps the whole physical memory in the stage 2 translation tables, except for protected regions, including the
// hypervisor memory ranges.
map_stage2();
// Sets a second batch of per-core system registers.
hyp_set_el2_and_enable_stage_2_per_cpu();
regs->x0 = hyp_set_elr_el2_spsr_el2_sctlr_el1(regs->x3, regs->x0);
// ...
}
虚拟机监控程序的虚拟地址空间¶
目前,HHEE 可以直接访问物理内存,因此没有启用内存保护。init_memory_mappings通过以下方式解决此问题:
使用 allocate_hypervisor_page_tables 为虚拟机管理程序的页表分配内存;
用map_hypervisor_memory对应的物理页进行1:1映射,使物理内存到虚拟内存的过渡尽可能平滑;
调用 hyp_config_per_cpu 以设置相关的系统寄存器并使虚拟映射生效。
void init_memory_mappings() {
allocate_hypervisor_page_tables();
// First set all hypervisor phyiscal memory as read-write.
map_hypervisor_memory(0x10f00000, 0x10f00000, 0x00600000, HYP_READ | HYP_WRITE | INNER_SHAREABLE);
// Then set the code + rodata range as read-only executable.
map_hypervisor_memory(0x10f00000, 0x10f00000, 0x00010000, HYP_READ | HYP_EXEC | INNER_SHAREABLE);
// Maybe this was meant to be the rodata range?
map_hypervisor_memory(0x10f10000, 0x10f10000, 0x00000000, HYP_READ | INNER_SHAREABLE);
// Map the device internal memory as read-write.
map_hypervisor_memory(0xe0000000, 0xe0000000, 0x20000000, HYP_READ | HYP_WRITE);
// Sets a first batch of per-core system registers.
hyp_config_per_cpu();
}
在 allocate_hypervisor_page_tables 中实现的分配阶段首先调用以检索对物理地址空间的大小进行编码所需的位数。在我们的示例中,设备使用 48 位物理地址。get_parange_in_bits
根据此大小,它准备将存储在 EL2 系统寄存器中的值。
设置为页面全局目录 (PGD) 的地址,这是地址转换期间使用的第一个页表。TTBR0_EL2
在 中注册内存属性。MAIR_EL2
配置以设置物理和虚拟地址空间的大小以及粒度的大小,粒度是可以转换的最小内存块。TCR_EL2
通过更改 启用 MMU、WXN 和缓存。SCTLR_EL2
一旦映射了物理内存,这些值将有效地写入hyp_config_per_cpu中的相应寄存器。
然后,该函数初始化全局位图,该位图跟踪虚拟机管理程序地址空间中的虚拟分配。最后,通过调用 allocate_page_tables_per_addr_range 来执行实际的内存分配。g_bitmaps_array
我们将在后面关于页表的部分中回到位图和分配函数,以在更广泛的上下文中描述它们。
uint64_t allocate_hypervisor_page_tables() {
// ... // Retrieves the number of bits used for the physical address range.
parange_in_bits = get_parange_in_bits();
// Default values used for a 48-bit address space, the most common size.
if (parange_in_bits == 48) {
g_page_size_log2 = 0xc;
g_hyp_first_pt_level = 0;
pgd_size = 0x1000;
g_nb_pt_entries = 0x200;
g_va_range_start = 0x800000000000;
phys_addr_size_bits = 0b101 /* 48 bits */;
} else {
/* ... */
}
// TTBR0_EL2, Translation Table Base Register 0 (EL2).
g_ttbr0_el2 = alloc_memory(pgd_size, pgd_size);
// ...
// MAIR_EL2, Memory Attribute Indirection Register (EL2).
g_mair_el2 = 0x4ff;
// TCR_EL2, Translation Control Register (EL2).
//
// - T0SZ, bits [5:0] = 16: TTBR0_EL2 region size is 2^48.
// - TG0, bits [15:14] = 0b00: TTBR0_EL2 granule size is 4KB.
// - PS, bits [18:16] = 0b101: PA size is 48 bits.
g_tcr_el2 = (0x40 - parange_in_bits) | 0x80803500 | (phys_addr_size_bits << 0x10);
// SCTLR_EL2, System Control Register (EL2).
//
// - M, bit [0] = 1: MMU enabled.
// - C, bit [2] = 1: Data access Cacheability control for accesses at EL2.
// - WXN, bit [19] = 0: WXN enabled.
g_sctlr_el2 = get_sctlr_el2() | 0x80005;
// Initializes a global bitmap that tracks virtual allocations in the hypervisor's address space.
for (i = 0; i != 8; ++i) {
atomic_set(-1, &g_bitmaps_array[i]);
}
// Allocates the page tables needed for the mapping from a pool of physical pages.
return allocate_page_tables_per_addr_range(g_ttbr0_el2, g_va_range_start, 0, 0x1000, g_hyp_first_pt_level,
g_page_size_log2, g_nb_pt_entries, 0);
}
我们还将推迟map_hypervisor_memory细节。现在,只需知道映射了以下范围:
| 物理地址 | 虚拟地址 | 大小 | R | W | X | 内部可共享 | 描述 |
|---|
| 0x10F00000 | 0x10F00000 | 0x10000 | • |
| • | 是的 | 代码和只读数据 |
| 0x10F10000 | 0x10F00000 | 0x5F0000 | • | • |
| 是的 | 读写数据 |
| 0xE0000000 | 0xE0000000 | 0x20000000 | • | • |
| 不 | 读写内部设备存储器 |
最后,如前所述,调用hyp_config_per_cpu来修改 EL2 系统寄存器并激活虚拟内存范围以及随之而来的保护。
void hyp_config_per_cpu() {
// Puts the global/shared values into the per-core system registers.
set_ttbr0_el2(g_ttbr0_el2);
set_mair_el2(g_mair_el2);
set_tcr_el2(g_tcr_el2);
// Invalidates all TLBs for EL2.
tlbi_alle2();
set_sctlr_el2(g_sctlr_el2);
}
初始化第二转换阶段¶
boot_primary_core的第二个作用是通过调用map_stage2来设置虚拟地址转换系统的第二阶段。
第一步是在第二阶段映射整个物理内存,但 DDR 孔除外,DDR 孔是外部内存芯片没有物理支持的内存区域。映射是使用 map_stage2_memory 和 unmap_stage2_memory 执行的,但就像其他内存映射函数一样,我们将这个函数留给页表部分。
第二步是从第二阶段取消映射关键范围和受保护范围。通过这样做,我们确保内核无法映射某些物理区域,即使它完全受到损害。相关区域如下:
| 物理内存区域 | 开始 | 结束 |
|---|
Hypervisor | 0x10F00000 | 0x114CF000 |
LPMCU | 0x11A40000 | 0x11B00000 |
SENSORHUB | 0x11B00000 | 0x12800000 |
SUPERSONIC | 0x2C200000 | 0x2CBB0000 |
SEC_CAMERA | 0x2CE00000 | 0x2DA00000 |
HIFI | 0x2DA00000 | 0x2E980000 |
NPU_SEC | 0x30660000 | 0x31060000 |
MODEM | 0xA0000000 | 0xB1280000 |
第三步也是最后一步是重新映射具有不同权限的某些范围。
设备内部存储器范围将重新映射为设备存储器。0xE0000000-0x100000000
紧跟在虚拟机管理程序之后的内存范围(包含虚拟机管理程序和日志缓冲区(监视器日志缓冲区除外)使用的全局变量)将重新映射为只读。0x114CF000-0x114F1000
包含监视器日志缓冲区的内存范围将重新映射为只读。0x114F1000-0x114FF000
void map_stage2() {
// ...
// Sets global variables related to the second translation stage, in particular g_vttbr_el2, which contains the second
// stage's PGD.
init_stage2_globals();
// ...
// Maps all the physical memory in the stage 2 except the DDR holes.
last_end_paddr = 0;
for (int32_t i = 0; i < 32; i++) {
if (g_ddr_holes_table[i].valid) {
size = g_ddr_holes_table[i].beg_paddr - last_end_paddr;
map_stage2_memory(last_end_paddr, last_end_paddr, size, NORMAL_MEMORY | READ | WRITE | EXEC_EL0 | EXEC_EL1, 0);
// ...
last_end_paddr = g_ddr_holes_table[i].last_end_paddr;
}
} // Maps the device internal memory range.
map_stage2_memory(0xe0000000, 0xe0000000, 0x20000000, READ | WRITE | EXEC_EL0 | EXEC_EL1, 1);
// ...
// Unmap critical/protected memory ranges.
for (int32_t i = 0; i < 32; i++) {
if (g_unmapped_regions[i].valid) {
beg_paddr = g_unmapped_regions[i].beg_paddr;
unmap_stage2_memory(beg_paddr, g_unmapped_regions[i].end_paddr - beg_addr);
// ...
}
}
// Unmap the hypervisor memory range.
unmap_stage2_memory(0x10f00000, 0x5cf000);
// ...
// Sets the memory range containing g_ddr_holes_table, g_unmapped_regions as well as all the log buffers but the
// monitorlog buffer as read-only.
set_memory_config_as_ro();
// Sets the memory range containing the monitorlog buffer as read-only.
set_monitorlog_buffers_as_ro();
}
然后,我们继续boot_primary_core调用的下一个函数,即 hyp_set_el2_and_enable_stage_2_per_cpu。此功能设置多个 EL2 系统寄存器(如 )以执行以下操作:HCR_EL2
void hyp_set_el2_and_enable_stage_2_per_cpu() {
uint64_t hypervisor_config = 0x84080004;
uint64_t attrs = get_id_aa64isar1_el1(); // Configuration for PAC-compatible devices.
//
// ID_AA64ISAR1_EL1, AArch64 Instruction Set Attribute Register 1.
//
// The checked bits indicate whether QARMA or Architected algorithm, or support for an implementation defined
// algorithm are implemented in the PE for address authentication and generic code authentication.
if ((attrs & 0xff000ff0) != 0) {
hypervisor_config = 0x30084080004;
}
// HCR_EL2, Hypervisor Configuration Register.
//
// - VM, bit [0] = 0: EL1&0 stage 2 address translation disabled.
// - PTW, bit [2] = 1: translation table walks that end up accessing device memory generate stage 2 permission
// faults.
// - TSC, bit [19] = 1: traps SMC instructions.
// - TVM, bit [26] = 1: traps EL1 writes to the virtual memory control registers to EL2 (SCTLR_EL1, TTBR0_EL1,
// TTBR1_EL1, TCR_EL1, ESR_EL1, FAR_EL1, AFSR0_EL1, AFSR1_EL1, MAIR_EL1, AMAIR_EL1,
// CONTEXTIDR_EL1).
// - RW, bit [31] = 1: the Execution state for EL1 is AArch64, and the Execution state for EL0 is determined by the
// current value of PSTATE.nRW when executing at EL0.
// - E2H, bit [34] = 0: The facilities to support a Host Operating System at EL2 are disabled (influences the format
// of the TCR_EL2 system register).
set_hcr_el2(hypervisor_config);
set_cptr_el2(0x33ff);
set_hstr_el2(0);
set_cnthctl_el2(3);
set_cntvoff_el2(0);
set_vpidr_el2(get_midr_el1());
set_vmpidr_el2(get_mpidr_el1());
set_vttbr_el2(0);
enable_stage2_addr_translation();
}
最终,调用enable_stage2_addr_translation设置第二阶段 PGD 的地址。第二阶段最终由该函数配置和启用。VTTBR_EL2
void enable_stage2_addr_translation() {
// ...
parange_in_bits = get_parange_in_bits();
if (parange_in_bits == 48) {
vtcr_el2 = (0b101 << 0x10) | 0x80003580;
} else {
/* ... */
} // VTCR_EL2, Virtualization Translation Control Register.
//
// - T0SZ, bits [5:0] = 16: VTTBR0_EL2 region size is 2^48.
// - SL0, bits [7:6] = 0b10: start at level 0.
// - TG0, bits [15:14] = 0b00: VTTBR0_EL2 granule size is 4KB.
// - PS, bits [18:16] = 0b101: PA size is 48 bits.
set_vtcr_el2(vtcr_el2 | (0x40 - parange_in_bits));
set_vttbr_el2(g_vttbr_el2);
// HCR_EL2, Hypervisor Configuration Register.
//
// VM, bit [0] = 1: EL1&0 stage 2 address translation enabled.
set_hcr_el2(get_hcr_el2() | 1);
}
最后,我们到达了主核心初始化的末尾。剩下的就是准备虚拟机管理程序以跳转到内核。这是通过调用内核的入口点作为第一个参数的 hyp_set_elr_el2_spsr_el2_sctlr_el1 来实现的。此功能首先使用 hyp_set_ttbr_el1_tcr_el1_mair_el1 初始化 EL1 系统寄存器。然后,它设置:
uint64_t hyp_set_elr_el2_spsr_el2_sctlr_el1(uint64_t entrypoint, uint64_t context_id) {
hyp_set_ttbr_el1_tcr_el1_mair_el1();
// ELR_EL2, Exception Link Register (EL2).
set_elr_el2(entrypoint);
// SPSR_EL2, Saved Program Status Register (EL2).
//
// M, bits [3:0] = 0b0101: EL1h (SPx Stack Pointer).
set_spsr_el2(0x3c5);
// SCTLR_EL1, System Control Register (EL1).
//
// - M, bit [0] = 0: MMU disabled.
// - WXN, bit [19] = 0: WXN disabled.
// - SPAN, bit [23] = 1: the value of PSTATE.PAN is left unchanged on taking an exception to EL1.
set_sctlr_el1(0x30d50838);
return context_id;
}
void hyp_set_ttbr_el1_tcr_el1_mair_el1() {
// ...
if (atomic_get(¤t_cpu->sys_regs->regs_inited)) {
ttbr1_el1 = sys_regs->ttbr1_el1;
tcr_el1 = sys_regs->tcr_el1;
mair_el1 = sys_regs->mair_el1;
} else {
ttbr_el1 = tcr_el1 = mair_el1 = 0;
} set_ttbr0_el1(0);
set_ttbr1_el1(ttbr1_el1);
set_tcr_el1(tcr_el1);
set_mair_el1(mair_el1);
// Ensures that the MMU, WXN are enabled, among other things.
check_sctlr_el1(get_sctlr_el1());
current_cpu->ttbr1_el1_processed = 0;
}
此时,当虚拟机管理程序在 entrypoint_primary 中达到 ERET 指令时,执行级别将下降到 EL1 并进入内核。内核将执行其工作,并最终启动辅助内核。
辅助内核启动¶
为了引导辅助内核,内核使用设备树中的 ARM 电源协调接口条目 (PSCI)。
psci{
compatible = "arm,psci";
cpu_off = <0x84000002>;
cpu_on = <0xC4000003>;
cpu_suspend = <0xC4000001>;
method = "smc";
system_off = <0x84000008>;
system_reset = <0x84000009>;
};
我们可以看到,内核使 SMC 打开 CPU 内核,这对应于安全监视器中的命令。但是,当启用虚拟机管理程序时,此 SMC 将被捕获并由boot_hyp_cpu处理。0xC4000003PSCI_CPU_ON_AARCH64
此函数将首先检索或分配当前辅助核心的线程本地存储(如果不存在)。之后,它调用执行初始 SMC,并向其传递内核的入口点,即 entrypoint_secondary。然后,安全监视器处理 SMC,最终启动相应的 CPU 内核,并在 entrypoint_secondary 功能中跳回 EL2。do_smc_psci_cpu_onPSCI_CPU_ON_AARCH64
注意:如果您想了解有关 CPU 内核启动时安全监视器执行的操作的更多详细信息,您可以查看 ATF 的源代码并按照 psci_cpu_on 中的执行流程进行操作。
uint64_t boot_hyp_cpu(uint64_t target_cpu, uint64_t entrypoint, uint64_t context_id) {
// ... // Try to find the thread local storage of the target CPU.
spin_lock(&g_cpu_list_lock);
for (cpu_info = &g_cpu_list; cpu_info != NULL; cpu_info = cpu_info->next) {
if (target_cpu == cpu_info->mpidr_el1) {
break;
}
}
// If no thread local storage exists for this CPU, allocate one.
if (cpu_info == NULL) {
// Allocate the CPU stack and TLS structure.
cpu_stack = alloc_memory(0x40, 0x1480);
// ...
cpu_info = (cpu_list_t*)cpu_stack + 0x1440;
memset_s(cpu_info, 0x40, 0, 0x40);
cpu_info->mpidr_el1 = target_cpu;
// Add the TLS structure to the global CPU list.
cpu_info->next = g_cpu_list.next;
g_cpu_list.next = cpu_info;
}
// If the CPU hasn't already booted, save the original arguments into the CPU stack, replace them with the secondary
// entry point in the hypervisor and execute the PSCI_CPU_ON_AARCHXX SMC.
if (!cpu_info->is_booting) {
cpu_info->is_booting = 1;
spin_unlock(&g_cpu_list_lock);
*(uint64_t*)((void*)cpu_info - 0x10) = entrypoint;
*(uint64_t*)((void*)cpu_info - 8) = context_id;
// ...
return do_smc_psci_cpu_on(target_cpu, entrypoint_secondary, cpu_info_ptr);
}
spin_unlock(&g_cpu_list_lock);
return 0xfffffffc;
}
在这个阶段,我们终于可以在辅助内核上运行代码,并使用 entrypoint_secondary 初始化它们的 EL2 状态。该函数初始化线程本地存储、异常向量表和与内存控制相关的 EL2 系统寄存器,从而将此辅助内核置于与主内核相同的状态。
void entrypoint_secondary(saved_regs_t args) {
// TPIDR_EL2 holds a per-CPU object that contains saved register values and information related to the execution.
set_tpidr_el2(args->x0);
// Sets the exception vector table (VBAR_EL2) for the current CPU.
set_vbar_el2(SynchronousExceptionSP0);
// Sets a first batch of per-core system registers.
hyp_config_per_cpu();
// Boot the secondary core.
boot_secondary_cores(&args);
// Continue the execution in the kernel at EL1.
asm("eret");
}
剩下的就是通过再次调用 hyp_set_el2_and_enable_stage_2_per_cpu 来启用第二个翻译阶段。
void boot_secondary_cores(saved_regs_t* regs) {
// Flag the CPU as no longer booting (in the secure monitor).
spin_lock(&g_cpu_list_lock);
current_cpu->is_booting = 0;
spin_unlock(&g_cpu_list_lock);
current_cpu->sys_regs = &g_sysregs;
// Sets a second batch of per-core system registers.
hyp_set_el2_and_enable_stage_2_per_cpu();
uint64_t entrypoint = *(uint64_t*)(regs->x0 - 0x10);
uint64_t context_id = *(uint64_t*)(regs->x0 - 0x8);
regs->x0 = hyp_set_elr_el2_spsr_el2_sctlr_el1(entrypoint, context_id);
}
一旦entrypoint_secondary命中 ERET 指令,内核就会返回到 EL1 处的内核并继续执行。虚拟机管理程序在所有内核上初始化,并准备监督内核。下图总结了本节中描述的有关打开设备电源的整个过程。
![]()
完成初始化后,我们可以继续下一个主题:虚拟内存管理。
虚拟内存管理¶
可以说,虚拟机管理程序最重要的元素是它的第二个转换阶段实现,更广泛地说,是它如何处理页表。在本节中,我们将解释到目前为止我们搁置的组件,即第二阶段的内存映射和虚拟机管理程序的地址空间。
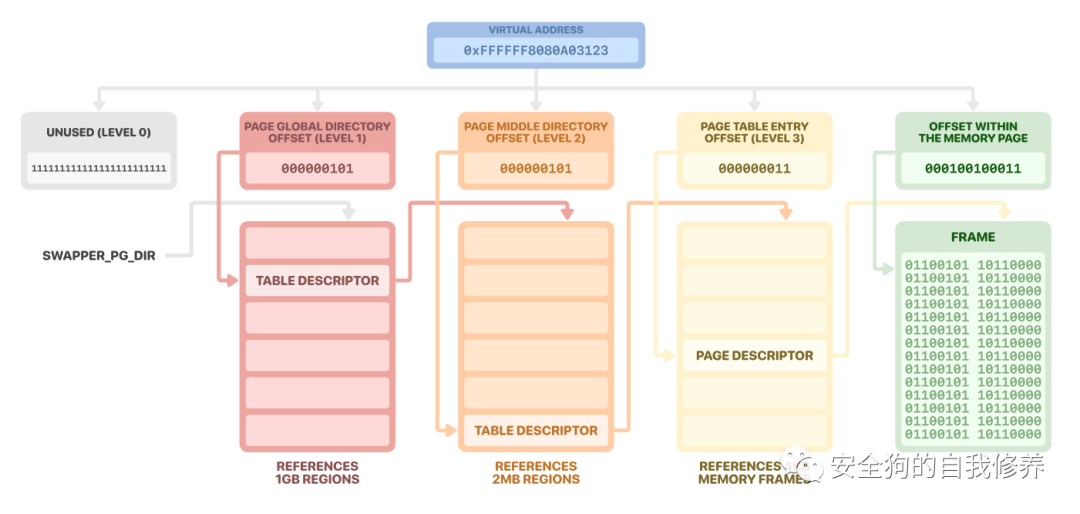
ARM 虚拟内存管理进修课程¶
![]()
默认情况下,当设备启动时,每个异常级别都可以直接访问物理内存。没有隔离或内存保护。例如,在 EL0 上运行的代码可以访问其他 EL0 应用程序的地址空间,甚至可以修改内核资源。这可以通过实现虚拟内存系统来防止,其中一个或多个虚拟地址映射到给定的物理地址。
从虚拟地址到物理地址的转换由内存管理单元 (MMU) 执行。但要执行这种转换,MMU 需要一种方法来使虚拟地址和物理地址相对应。这就是页表的用武之地。物理内存位置被细分并组织成多级表。
![]()
ARM 虚拟内存实现的另一个重要方面是内核在 EL1 上使用的转换表,以及在 EL0 上运行的进程使用的转换表。由于 EL0 上的任务通常是并发运行的,因此它们都有自己的一组转换表,并且当发生上下文切换时,内核会定期在它们之间切换。但是,这不适用于内核,因为内存映射不太可能更改。因此,为了提高效率,虚拟地址空间分为两个区域:
EL2 和 EL3 不存在这种区别。
![]()
最后,转换中的虚拟地址被划分为块,这些块在页表中形成索引。这允许我们从最高级别到最低级别遍历页表,并检索关联的物理页。
![]()
在虚拟机管理程序和 Android 内核的情况下,它们都使用 4 级转换表。在 ARM 规范中,页表称为 n 级,在本例中,n 的范围从 0(最高级别)到 3(最低级别)。但是,Linux 内核使用下面给出的不同命名法:
在本文的其余部分,我们可以互换使用这些术语,因为某些函数可以同时处理虚拟机管理程序和内核页表。
我们在这篇博文中处理的页表都共享相同的配置。它们长 4096 字节,因此包含 512 个 64 位条目。每个条目(称为描述符)只能属于下面列出的类型之一。
页面描述符:
存储物理页面的地址以及应用的内存属性和保护;
必须将其最低有效位设置为0b11;
只能在 3 级页表中使用。
![]()
![]()
![]()
![]()
页面和块描述符包含应用于它们所映射的内存的属性。这些属性被拆分为上部块和下部块,如下所示。
![]()
具体而言,我们感兴趣的是以下属性:
或非安全位,指定输出地址是安全的还是非安全的;NS
或访问权限位,控制内存是否可从 EL0 读取/写入,以及是否可以从更高的 EL 写入;AP[2:1]
,或 Unprivileged eXecute-Never 位,控制内存是否可从 EL0 执行;UXN
或 Privileged eXecute-Never 位,用于控制内存是否可从更高的 EL 执行。PXN
此外,以下鲜为人知的属性与安全虚拟机管理程序相关:
位,表示该条目是可能缓存在单个 TLB 条目中的一组连续条目之一;Contiguous
位,或脏位修饰符,指示页面或部分内存是否被修改,并更改位的功能以记录脏状态而不是访问权限;DBMAP[2]
或 Access Flag 位,用于跟踪条目所涵盖的区域是否已被访问。AF
在虚拟机管理程序中映射内存¶
map_pa_into_hypervisor是将物理内存映射到虚拟机管理程序时遇到的主要功能。它映射包含物理地址的物理页面,并返回虚拟机管理程序虚拟空间中的地址。但是,虚拟地址的选择留给虚拟机管理程序。phys_addr
为了跟踪正在使用的虚拟内存,虚拟机管理程序使用一个简单的线性分配器,从存储在 中的虚拟地址开始。分配器是用一个由八个 64 位整数组成的数组实现的,其中一位表示一个虚拟页面。如果设置了位,则分配是免费的;否则,它正在使用中。因此,分配器最多可以映射 0x200000 个字节。g_va_range_start
当虚拟机监控程序想要映射物理地址时,它会通过遍历每个整数来检查位图中是否有虚拟页面可用。然后,在返回其虚拟地址之前,使用 map_hypervisor_memory 将页面映射到页表中。
uint64_t map_pa_into_hypervisor(uint64_t phys_addr) {
// Column and row indices in the bitmap used to compute the resulting virtual address.
bitmap_idx = 0;
tracker = 0xffffffffffffffff;
for (;;) {
expected_tracker = tracker;
// RBIT reverses the bit order of an integer, e.g. RBIT(0x1) returns 0x8000000000000000.
//
// CLZ counts the number of leading zeroes of an integer, e.g. CLZ(0xffff) returns 48.
//
// Using RBIT followed by CLZ returns the index of the last bit equal to 0 starting from the right. In our context,
// it returns the bit position that corresponds to the free virtual page with the lowest possible address.
next_alloc_bit_idx = clz(rbit(tracker));
// Generates the new tracker value.
new_tracker = tracker & (1 << next_alloc_bit_idx);
// Atomically checks if the tracker is in the expected state. If it's the case, then atomically stores the new state
// that takes the allocation into account.
tracker = exclusive_load(g_bitmaps_array[bitmap_idx]);
if (tracker == expected_tracker) {
if (!exclusive_store(new_tracker, g_bitmaps_array[bitmap_idx])) {
break;
}
}
// If no more allocations can be made with the current bitmap integer, we move to the next one. If the end of the
// bitmaps is reached, start over from the beginning.
if (!tracker) {
if (bitmap_idx++ >= 8) {
bitmap_idx = 0;
}
tracker = 0xffffffffffffffff;
}
} // Maps the physical page and returns the virtual address that corresponds to the input physical address.
page_size = 1 << g_page_size_log2;
offset_mask = page_size - 1;
addr_mask = -(1 << page_size);
phys_page_addr = phys_addr & addr_mask;
virt_page_addr = g_va_range_start + (bitmap_idx * 64 + next_alloc_bit_idx) * page_size;
map_hypervisor_memory(virt_page_addr, phys_page_addr, 0x1000, HYP_WRITE | HYP_READ | INNER_SHAREABLE);
virt_addr = virt_page_addr | phys_addr & offset_mask;
return virt_addr;
}
map_hypervisor_memory 将作为参数传递的物理地址开始构建将存储在页表中的页(或块)描述符。它根据提供的权限设置以下属性:
如果未指定,则将范围映射为不可执行;HYP_EXEC
如果指定,则将范围映射为内部可共享,否则将范围映射为外部可共享;INNER_SHAREABLE
如果指定了范围,则将范围设置为读写,否则设置为只读。HYP_WRITE
然后,执行继续map_memory_range。
uint64_t map_hypervisor_memory(uint64_t virt_addr, uint64_t phys_addr, uint64_t size, hyp_attrs_t perms) {
// ... desc = phys_addr;
// If a range is not executable, we set XN[54] to 1.
if (!(perms & HYP_EXEC)) {
desc |= 1 << 54;
}
// Sets the Access Flag to 1.
desc |= 1 << 10;
if (perms & INNER_SHAREABLE) {
// Sets SH[9:8] to 0b11 if our range should be inner Shareable.
desc |= 0b11 << 8;
} else {
// Sets SH[9:8] to 0b10 if our range should be outer Shareable.
desc |= 0b10 << 8;
}
if (perms & HYP_WRITE) {
// Sets AP[7] to 0 if our range should be read/write.
desc |= 0b0 << 7;
} else {
// Sets AP[7] to 1 if our range should be read-only.
desc |= 0b1 << 8;
}
map_memory_range(g_ttbr0_el2, virt_addr, desc | 0b01 /* Block descriptor by default */, size, g_hyp_first_pt_level,
g_page_size_log2, g_nb_pt_entries, 0);
// ...
}
map_memory_range首先从物理地址池中分配映射所需的页表,并使用 allocate_page_tables_per_addr_range 进行设置,该函数也在 allocate_hypervisor_page_tables 中使用。
然后,该函数使用 add_page_table_entries 将块和/或页面描述符添加到这些表中。
uint64_t map_memory_range(uint64_t page_table_addr,
uint64_t virt_addr,
uint64_t desc,
uint64_t size,
uint32_t pt_level,
uint32_t next_table_size_in_bits,
uint64_t nb_pt_entries,
uint8_t invalidate_by_ipa) {
phys_addr = desc & 0xfffffffff000;
// ...
// Allocates physical memory pages for the page tables needed to map the requested range.
ret = allocate_page_tables_per_addr_range(page_table_addr, virt_addr, phys_addr, size, pt_level,
next_table_size_in_bits, nb_pt_entries, invalidate_by_ipa);
if (ret) {
return 0xffffffff;
} // Updates the page tables and adds the page table descriptors to effectively map the requested range.
add_page_table_entries(page_table_addr, virt_addr, attrs, size, pt_level, next_table_size_in_bits, nb_pt_entries,
invalidate_by_ipa);
return 0;
}
allocate_page_tables_per_addr_range获取我们想要映射的地址范围,递归地在其上执行页表遍历,分配任何尚不存在的页表,并存储相应的页表描述符。但是,它不会在页表中注册任何页面或块。这就是add_page_table_entries的作用。
uint64_t allocate_page_tables_per_addr_range(uint64_t page_table_addr,
uint64_t vaddr,
uint64_t paddr,
uint64_t size,
uint32_t pt_level,
uint32_t table_size_log2,
uint64_t nb_pt_entries,
uint8_t invalidate_by_ipa) {
// ... // If we've reached the third level of the page table, we're done, other functions will take care of the page
// allocations.
if (pt_level == 3 || size == 0) {
return 0;
}
vaddr_end = vaddr + size;
nb_pt_entries_log2 = table_size_log2 - 3;
nb_pt_entries = 1 << nb_pt_entries_log2;
next_pt_level = pt_level + 1;
// Computes the position in the virtual address of the index into the current page table level (e.g. 12 at level 3, 21
// at level 2, etc.).
pt_level_idx_pos = (4 - pt_level) * nb_pt_entries_log2 + 3;
next_pt_level_idx_pos = (3 - pt_level) * nb_pt_entries_log2 + 3;
is_not_level0_or_level1 = pt_level_idx_pos < 31;
// Computes the size mapped by the current level (e.g. 0x1000 at level 3, 0x200000 at level 2, etc.).
pt_level_size = 1 << pt_level_idx_pos;
next_pt_level_size = 1 << next_pt_level_idx_pos;
// Virtual address mask for the current page table level (e.g. 0xffff_ffff_ffff_f000 at level 3).
pt_level_mask = -pt_level_size;
// Mask to apply to get a page table index from a virtual address (e.g. 0x1ff for page tables with 0x200 entries).
pt_idx_mask = nb_pt_entries - 1;
// Current page table level descriptor address of the virtual address we want to map.
desc_addr = page_table_addr + 8 * ((vaddr >> pt_level_idx_pos) & pt_idx_mask);
for (;;) {
// Checks if the range covered by the current page table level is large enough to contain the region we want to map.
next_range_addr = (vaddr + pt_level_size) & pt_level_mask;
range_vaddr_end = (next_range_addr > vaddr_end) ? vaddr_end : next_range_addr;
size_to_map = range_vaddr_end - vaddr;
// If we're at level 2 or 3 and the whole region is covered, we continue to the next one without any allocation.
// Because in these cases, we would either allocate a block at level 2 or a page at level 3, but this is taken care
// of in another function.
if (is_not_level0_or_level1 && pt_level_size == size_to_map && (vaddr | paddr) & (pt_level_size - 1) == 0) {
goto CONTINUE;
}
desc = *desc_addr;
// If the descriptor is invalid or doesn't exist, we allocate a page table for the lower level and make the
// descriptor point to it.
if (desc & 1 == 0) {
new_pt_addr = alloc_memory(next_pt_level_size, next_pt_level_size);
*desc_addr = new_pt_addr | 3;
goto HANDLE_NEXT_PT_LEVEL;
}
// If the descriptor is a block descriptor, we split the block into lower level blocks (e.g. a 0x4000_0000-long
// block at level 1 would be split into 512 0x20_0000-long blocks at level 2).
if (desc & 2 == 0) {
new_pt_addr = alloc_memory(next_pt_level_size, next_pt_level_size);
next_desc = desc;
// Transforms block descriptors into page descriptors if the next level is 3.
if (next_pt_level == 3) {
next_desc = desc | 2;
}
// Splits the block into lower-level blocks (or pages if we're currently at level 2).
if (nb_pt_entries) {
for (idx = 0; idx != nb_pt_entries; idx++) {
*(uint64_t*)(new_pt_addr + 8 * idx) = next_desc;
next_desc += next_pt_level_size;
}
}
// ...
*desc_addr = new_pt_addr | 3;
goto HANDLE_NEXT_PT_LEVEL;
}
HANDLE_NEXT_PT_LEVEL:
if (allocate_page_tables_per_addr_range(new_pt_addr, vaddr, paddr, size_to_map, next_pt_level, table_size_log2,
nb_pt_entries, invalidate_by_ipa)) {
return 0xffffffff;
}
CONTINUE:
size -= size_to_map;
paddr += size_to_map;
++desc_addr;
vaddr = range_vaddr_end;
if (!size) {
return 0L;
}
}
}
add_page_table_entries还执行页表遍历,但这次是注册作为参数传递的页面和/或块描述符。此函数返回后,内存已成功映射到虚拟机监控程序中。
void add_page_table_entries(uint64_t page_table_addr,
uint64_t vaddr,
uint64_t desc,
uint64_t size,
uint32_t pt_level,
uint32_t table_size_log2,
uint64_t nb_pt_entries,
uint8_t invalidate_by_ipa) {
vaddr_end = vaddr + size;
nb_pt_entries_log2 = table_size_log2 - 3;
nb_pt_entries = 1 << nb_pt_entries_log2; // Computes the position in the virtual address of the index into the current page table level (e.g. 12 at level 3, 21
// at level 2, etc.).
pt_level_idx_pos = (4 - pt_level) * nb_pt_entries_log2 + 3;
// Computes the size mapped by the current level (e.g. 0x1000 at level 3, 0x200000 at level 2, etc.).
pt_level_size = 1 << pt_level_idx_pos;
// Virtual address mask for the current page table level (e.g. 0xffff_ffff_ffff_f000 at level 3).
pt_level_mask = -pt_level_size;
// Mask to apply to get a page table index from a virtual address (e.g. 0x1ff for page tables with 0x200 entries).
pt_idx_mask = nb_pt_entries - 1;
// Current page table level descriptor address of the virtual address we want to map.
desc_addr = page_table_addr + 8 * ((vaddr >> pt_level_idx_pos) & pt_idx_mask);
is_not_level0_or_level1 = pt_level_idx_pos < 31;
while (size) {
// Checks if the range covered by the current page table level is large enough to contain the region we want to map.
next_range_addr = (vaddr + pt_level_size) & pt_level_mask;
range_addr_end = (next_range_addr > vaddr_end) ? vaddr_end : next_range_addr;
size_to_map = range_addr_end - vaddr;
// If we're at level 3, we add our input descriptor desc into the page table. All descriptors passed to this
// function have their least significant bit set, so we set bit 1 to make it a page descriptor.
if (pt_level == 3) {
*desc_addr = desc | 2;
// ...
} else {
// Since all descriptors are blocks by default, we deviate from a block mapping if:
//
// - we're at page table level 0 or 1.
// - the size we're trying to map doesn't cover the region at this page table level.
// - the address we're trying to map is not block-aligned.
if (!is_not_level0_or_level1 || pt_level_size != size_to_map || (vaddr | paddr) & (pt_level_size - 1) != 0) {
lower_level_page_table_addr = *desc_addr & 0xfffffffff000;
page_table_addr = add_page_table_entries(lower_level_page_table_addr, vaddr, desc, size_to_map, pt_level + 1,
table_size_log2, nb_pt_entries, invalidate_by_ipa);
}
// Otherwise, we map a block.
else {
*desc_addr = desc;
}
// ...
}
size -= size_to_map;
desc += size_to_map;
desc_addr++;
vaddr = next_range_addr;
}
}
从虚拟机管理程序中取消虚拟地址的映射非常简单。我们首先调用 unmap_hypervisor_memory,它只是用无效的描述符替换与我们想要取消映射的内存范围相对应的描述符。然后,我们更新在虚拟机管理程序中跟踪映射的位图,我们就完成了。
void unmap_hva_from_hypervisor(uint64_t virt_addr) {
page_size = 1 << g_page_size_log2;
addr_mask = -page_size;
virt_addr_aligned = virt_addr & addr_mask;
unmap_hypervisor_memory(virt_addr_aligned, page_size);
page_idx = (virt_addr_aligned - g_va_range_start) / page_size;
// Gets a pointer to the integer tracking the allocations for the corresponding page index.
tracker_idx = page_idx / 64;
tracker_p = &g_bitmaps_array[tracker_idx];
// Retrieves the current tracker integer, updates it and tries storing it until it works.
do {
tracker = exclusive_load(tracker_p);
new_tracker = tracker | (1 << page_idx);
} while (exclusive_store(new_tracker, tracker_p));
}
uint64_t unmap_hypervisor_memory(uint64_t addr, uint64_t size) {
ret = map_memory_range(g_ttbr0_el2, addr, 0, size, g_hyp_first_pt_level, g_page_size_log2, g_nb_pt_entries, 0);
if (ret) {
panic();
}
}
在第二阶段映射内存¶
第 2 阶段转换允许虚拟机监控程序控制虚拟机如何感知物理内存。它通过删除对地址范围的访问、更改其权限或将其重新映射到其他位置来确保来宾只能访问物理内存的特定部分。
我们在引言中已经解释过,第 2 阶段是第二个转换阶段,它使用自己的页表,其中基址存储在系统寄存器中。这些页表控制给定客户机看到的映射,以及关联的内存保护和属性。第 2 阶段将物理地址映射到中间物理地址,然后可以在操作系统的第一个转换阶段使用这些地址来映射虚拟地址。VTTBR_EL2
![]()
阶段 2 页表与阶段 1 页表非常相似,但描述符具有不同的属性。表描述符的上层属性都保留为 0。页面和块描述符的属性具有不同的字段,这些字段特定于第二阶段,如下所示。
![]()
阶段 2 属性类似于阶段 1 属性:
或第 2 阶段访问权限位控制内存在所有较低 EL 上是否可读/可写;S2AP
或 eXecute-Never 位,控制内存是否在 EL0 处可执行,在 EL1 处可执行;XN[1:0]
、 和 位的用途与第一阶段的对应项相同。ContiguousDBMAF
华为还使用描述符的“软件保留”位 55 至 58 实施了额外的安全功能。这些位存储有关描述符映射的基础物理内存的使用情况信息,下面列出了它们的可能值。
| 软件属性 | 描述 |
|---|
0b0000 | 无名 |
0b0100 | 级别 0 页表 |
0b0101 | 1 级页表 |
0b0110 | 2 级页表 |
0b0111 | 3 级页表 |
0b1000 | 操作系统只读 |
0b1001 | 操作系统模块只读 |
0b1010 | 虚拟机监控程序介导的操作系统只读 |
0b1011 | 虚拟机监控程序介导的操作系统模块只读 |
0b1100 | 共享对象保护仅执行 |
例如,通过将页面的软件属性设置为 ,虚拟机管理程序指示它是级别为 1 的内核页面表。它稍后可以使用此信息来防止对受保护的内存进行禁止的更改,例如使此页表再次可写。0b0101
get_software_attrs宏可用于从第 2 阶段描述符中检索软件属性。
#define get_software_attrs(desc_s2) ((desc_s2 >> 55) & 0b1111)
为了在第二个转换阶段映射内存,虚拟机监控程序使用 map_stage2_memory 函数。它首先使用物理地址、权限和作为参数传递的软件属性创建一个描述符。papermssoftware_attrs
如果包含 ,则将映射设置为位于 EL0 的可执行文件。permsEXEC_EL1
如果包含 ,则将映射设置为 EL1 的可执行文件。permsEXEC_EL0
如果包含 ,则将映射设置为可写。permsWRITE
如果包含 ,则将映射设置为可读。permsREAD
如果包含,则将映射设置为普通内存,否则设置为设备内存。permsNORMAL_MEMORY
然后,map_stage2_memory调用 map_memory_range,map_hypervisor_memory用于在虚拟机监控TTBR0_EL2VTTBR_EL2
void map_stage2_memory(uint64_t ipa,
uint64_t pa,
uint64_t size,
stage2_attrs_t perms,
software_attrs_t software_attrs) {
// ... // Sets the descriptor's software attributes.
desc = pa | (software_attrs << 55);
// If execution is disabled for EL0, we set XN[1] to 1.
if (!(perms & EXEC_EL0)) {
desc |= 1 << 54;
}
// If execution is disabled at EL1, but permitted at EL0 (or conversely), we set XN[0] to 1.
if (!(perms & EXEC_EL0) != !(perms & EXEC_EL1)) {
desc |= 1 << 53;
}
// Sets the Access Flag bit.
desc |= 1 << 10;
// If our range is writable, S2AP[1] is set to 1.
if (perms & WRITE) {
desc |= 1 << 7;
}
// If our range is readable, S2AP[0] is set to 1.
if (perms & READ) {
desc |= 1 << 6;
}
// Sets the memory attributes that correspond to the type of memory being mapped (i.e. normal or device memory).
desc |= (perms & NORMAL_MEMORY) ? 0x3c : 0xc;
// Maps the descriptor in the second translation stage.
map_memory_range(g_vttbr_el2, ipa, desc | 0b01 /* Block descriptor by default */, size, g_start_s2_pt_level, 0xc,
g_nb_s2_pt_entries, 1);
}
为了在第二阶段取消映射内存,虚拟机监控程序调用 unmap_stage2_memory,它是 map_memory_range 的包装器,将相应的描述符替换为全零描述符。这将删除内存映射以及标记该区域的软件属性。
uint64_t unmap_stage2_memory(uint64_t ipa, uint64_t size) {
// Replaces the descriptor that corresponds to the IPA by 0 in the second translation stage.
map_memory_range(g_vttbr_el2, ipa, 0, size, g_start_s2_pt_level, 0xc, g_nb_s2_pt_entries, 1);
}
虚拟机管理程序还实现了更改给定内存范围的权限和软件属性的功能。change_stage2_software_attrs_per_va_range对内核虚拟地址进行操作,并遍历其页表以查找相应的 IPA 范围,然后对每个虚拟地址调用 change_stage2_software_attrs_per_ipa_range,从而完成大部分工作。
uint64_t change_stage2_software_attrs_per_va_range(uint64_t virt_addr,
uint64_t size,
stage2_attrs_t perms,
software_attrs_t software_attrs,
uint8_t set_attrs, ) {
// An error is returned for userland addresses.
if ((virt_addr & (1 << 0x3f)) == 0) {
return 0xfffffffe;
}
// Retrieves page table information using system register values configured by the kernel.
ret = get_kernel_pt_info(1, &pgd, &pt_size_log2, &pt_level, &nb_pt_entries);
if (ret) {
return 0xfffffffe;
}
page_offset_mask = (1 << pt_size_log2) - 1;
// Makes sure the address and size are page-aligned.
if ((virt_addr | size) & page_offset_mask) {
return 0xfffffffe;
} while (size) {
// Retrieves page table information depending on which address space the address is part of (userland or kernel).
// However, because userland addresses are ignored by this function, virt_addr is always a kernel address.
is_kernel = virt_addr >> 0x3f;
ret = get_kernel_pt_info(is_kernel, &pgd, &pt_size_log2, &pt_level, &nb_pt_entries);
if (ret) {
return 0xfffffff7;
}
nb_pt_entries_log2 = pt_size_log2 - 3;
// Mask to apply to get a page table index from a virtual address (e.g. 0x1ff for page tables with 0x200 entries).
pt_idx_mask = nb_pt_entries - 1;
// Computes the position in the virtual address of the index into the current page table level (e.g. 12 at level 3,
// 21 at level 2, etc.).
pt_level_idx_pos = (4 - pt_level) * nb_pt_entries_log2 + 3;
pt_level_max_va = -(nb_pt_entries << pt_level_idx_pos);
if (pt_level_max_va > virt_addr) {
return 0xfffffff7;
}
desc_oa = pgd;
for (;;) {
// Maps the kernel PGD.
pt_hyp_va = map_page_table_hyp_and_stage2(desc_oa, pt_size_log2, pt_level, nb_pt_entries, &was_not_marked);
if (!pt_hyp_va) {
return 0xfffffff7;
}
desc = *(uint64_t*)(pt_hyp_va + (8 * (virt_addr >> pt_level_idx_pos) & pt_idx_mask));
unmap_va_from_hypervisor(pt_hyp_va);
desc_oa = desc & 0xfffffffff000;
// ...
// Checks if the descriptor is valid.
if ((desc & 1) == 0) {
return 0xfffffff7;
}
// Checks if it's a page or block descriptor.
if (pt_level == 3 || (desc & 2) == 0) {
pt_level_size = 1 << pt_level_idx_pos;
// Descriptor adjusted to contain the IPA offset into a block, if it's a block descriptor.
ipa = desc_oa | (pt_level_size - 1) & virt_addr;
if (ipa == 0xffffffffffffffff) {
return 0xfffffff7;
}
// Finds the smallest range covered by a page table level that contains the address range to map.
while (pt_level_size > size || ((pt_level_size - 1) & ipa) != 0) {
pt_level_size >>= nb_pt_entries_log2;
}
ret = change_stage2_software_attrs_per_ipa_range(ipa, pt_level_size, perms, software_attrs, set_attrs);
if (ret) {
return ret;
}
// Once we have reached the last level entry of a memory mapping the size and address are updated and we
// continue walking the page tables for the next entries.
size -= pt_level_size;
virt_addr += pt_level_size;
break;
}
++pt_level;
pt_level_idx_pos -= nb_pt_entries_log2;
}
}
return 0;
}
change_stage2_software_attrs_per_ipa_range首先通过调用 allocate_page_tables_per_addr_range 来确保 IPA 范围存在于第 2 阶段页表中。然后,它使用 get_stage2_page_table_descriptor_for_ipa 获取 IPA 范围跨越的所有阶段 2 描述符。
change_stage2_software_attrs_per_ipa_range执行的主要检查涉及软件属性。使用以下参数调用该函数:
该函数遍历每个阶段 2 描述符,并确保当前软件属性为:
未标记(即等于 0),当它们被设置时,
等于它们被清除时。software_attrs
如果一切按预期进行,则调用 map_stage2_memory 进行实际更改。
uint64_t change_stage2_software_attrs_per_ipa_range(uint64_t ipa,
uint64_t size,
stage2_attrs_t perms,
software_attrs_t software_attrs,
uint8_t set_attrs, ) {
// Allocates the stage 2 page tables that correspond to the input address range, in case they have not been mapped
// yet.
ret =
allocate_page_tables_per_addr_range(g_vttbr_el2, ipa, ipa, size, g_start_s2_pt_level, 0xc, g_nb_s2_pt_entries, 1);
if (ret) {
return 0xfffffffa;
} for (offset = 0; offset < size; offset += pt_level_size) {
desc = get_stage2_page_table_descriptor_for_ipa(ipa + offset, &pt_level_size);
// Checks if the descriptor is valid.
if ((desc & 1) == 0) {
return 0xfffffff7;
}
software_attrs_from_desc = get_software_attrs(desc);
// If set_attrs is true, we want to change the software attributes, so we make sure the memory range is currently
// unmarked.
//
// If set_attrs is false, we want to clear the software attributes, so we make sure the memory range is marked with
// the expected software attributes before unmarking it.
expected_software_attrs = set_attrs ? 0 : software_attrs;
if (software_attrs_from_desc != expected_software_attrs) {
if (software_attrs_from_desc == OS_RO) {
return 0;
} else {
return 0xfffffff8;
}
}
}
perms |= NORMAL_MEMORY;
if (!set_attrs) {
software_attrs = 0;
perms = EXEC_EL0 | WRITE | READ | NORMAL_MEMORY;
}
// Remaps the input range with the new software and stage 2 attributes.
for (offset = 0; offset < size; offset += pt_level_size) {
desc = get_stage2_page_table_descriptor_for_ipa(ipa + offset, &pt_level_size);
desc_oa = desc & 0xfffffffff000;
map_stage2_memory(ipa + offset, desc_oa, pt_level_size, perms, software_attrs);
}
return ret;
}
我们要详细说明的处理第 2 阶段页表的最后一个函数是 get_stage2_page_table_descriptor_for_ipa。每当虚拟机管理程序需要与给定 IPA 对应的阶段 2 描述符时,都会使用它。调用时,它会遍历第 2 阶段页表,并返回映射 IPA 的页面或块描述符。
uint64_t get_stage2_page_table_descriptor_for_ipa(uint64_t ipa, uint64_t* desc_va_range) {
// ... // Gets stage 2 page table information.
pt_level = g_start_s2_pt_level;
nb_pt_entries = g_nb_s2_pt_entries;
nb_pt_entries_log2 = g_page_size_log2 - 3;
// Computes the position in the virtual address of the index into the current page table level (e.g. 12 at level 3, 21
// at level 2, etc.).
pt_level_idx_pos = (4 - pt_level) * nb_pt_entries_log2 + 3;
// Computes the size mapped by the current level (e.g. 0x1000 at level 3, 0x200000 at level 2, etc.).
pt_level_size = 1 << pt_level_idx_pos;
// Checks that the IPA is in the correct range.
if (g_nb_s2_pt_entries << pt_level_idx_pos <= ipa) {
return 0;
}
pt_addr = g_vttbr_el2;
for (;;) {
desc = *(uint64_t*)(pt_addr + (8 * (ipa >> pt_level_idx_pos)));
// Checks if the descriptor is valid.
if ((desc & 1) == 0) {
return 0;
}
// Computes the offset into the address range of the current page table level.
addr_offset = (pt_level_size - 1) & ipa;
// If it is a block descriptor, returns a descriptor adjusted to contain the IPA offset into the block.
if ((desc & 2) == 0) {
return desc | addr_offset & (0xffffffffffffffff << g_page_size_log2);
}
// If we have reached level 3, returns the corresponding page descriptor.
if (pt_level == 3) {
return desc;
}
// ...
pt_addr = desc & 0xfffffffff000;
pt_level_idx_pos -= nb_pt_entries_log2;
pt_level++;
}
}
关于内存管理、虚拟机管理程序的内存映射和第 2 阶段实现的部分到此结束。下一部分是关于异常,以及虚拟机管理程序如何拦截它们以增强设备在运行时的安全性并与内核交互。
ARM 规范将异常定义为“可能导致当前正在执行的程序挂起并导致状态更改以执行代码以处理该异常的任何事件”。在下面的列表中,您可以看到在 AArch64 上实现的不同类型的异常。
同步:由于执行或尝试执行指令而产生的异常。它们通常由 SVC、HVC 或 SMC 等指令引发,但也可能由于对齐错误、PXN 指令的执行等而发生。
IRQ 或 Interrupt ReQuest:当硬件设备向 CPU 发送中断时,通常会引发此异常。此异常可以是物理异常,也可以由软件虚拟生成。
FIQ 或快速中断 reQuest:与 IRQ 相同,但优先级更高。
SError 或 System Error:一种异常类型,通常用于响应错误的内存访问。
异常是给定异常级别与其对应项交互的最常见方式。当引发异常时,它始终由当前 EL 或更高的 EL 处理,但 EL0 除外,它始终由更高的 EL 处理。同样,当从异常返回时,我们只能返回到当前 EL 或更低的 EL。
当异常被引发到特定 EL 时,根据其类型,它将由异常向量表中引用的特定函数处理。此表的地址存储在系统寄存器中,其中是当前 EL 的编号。异常向量表的布局如下:VBAR_ELnn
| 地址 | 异常类型 | 源 |
|---|
| +0x000 | 同步 | 带 SP0 的当前 EL |
| +0x080 | IRQ/vIRQ | 带 SP0 的当前 EL |
| +0x100 | FIQ/vFIQ | 带 SP0 的当前 EL |
| +0x180 | SError/vSError | 带 SP0 的当前 EL |
| +0x200 | 同步 | 带 SPx 的当前 EL |
| +0x280 | IRQ/vIRQ | 带 SPx 的当前 EL |
| +0x300 | FIQ/vFIQ | 带 SPx 的当前 EL |
| +0x380 | SError/vSError | 带 SPx 的当前 EL |
| +0x400 | 同步 | 使用 AArch64 降低 EL |
| +0x480 | IRQ/vIRQ | 使用 AArch64 降低 EL |
| +0x500 | FIQ/vFIQ | 使用 AArch64 降低 EL |
| +0x580 | SError/vSError | 使用 AArch64 降低 EL |
| +0x600 | 同步 | 使用 AArch32 降低 EL |
| +0x680 | IRQ/vIRQ | 使用 AArch32 降低 EL |
| +0x700 | FIQ/vFIQ | 使用 AArch32 降低 EL |
| +0x780 | SError/vSError | 使用 AArch32 降低 EL |
默认情况下,虚拟机监控程序能够处理:
但是,这些操作不足以提供适当的内核监督,这就是陷阱的用武之地。虚拟机管理程序可以配置为使 EL1 通常允许的某些操作导致更高 EL 的异常。也可以从内核重定向特定的异常,并让虚拟机管理程序来处理它们。所有这些都可以使用HCR_EL2系统寄存器进行自定义,其值是在hyp_set_el2_and_enable_stage_2_per_cpu中设置的。
如果我们考虑到所有这些,我们可以推断出 HHEE 将处理以下异常情况:
现在回到虚拟机管理程序的实现,当 EL1 异常引发到 EL2 时,它将由异常向量表中的相应条目处理。在我们的示例中,来自 EL1 的所有异步异常(即 IRQ、FIQ 和 SErrors)都不会重新路由到 EL2。实际上,在 中,相应的位 、 和 设置为 0。这意味着虚拟机管理程序必须处理的所有异常都是同步的。因此,我们只需要关注 addresses 和 处的条目,它们分别是 SynchronousExceptionA64(使用 AArch64 的较低 EL 的同步异常的处理程序)和 SynchronousExceptionA32(用于使用 AArch32 的较低 EL 的异常)。HCR_EL2IMOFMOAMOVBAR_EL2 + 0x400VBAR_EL2 + 0x600
SynchronousExceptionA64 读取 EL2 异常综合征寄存器 () 的字段,以确定我们正在处理的异常类别。它首先检查它是否来自 SVC、HVC 或 SMC。虽然,不需要 SVC 检查,因为 SVC 捕获默认处于禁用状态(和位重置为 0)。对于任何其他来源的例外情况,我们称之为hhee_handle_abort_from_aarch64。ECESR_EL2SVC_EL1SVC_EL0HFGITR_EL2
void SynchronousExceptionA64(saved_regs_t args) {
// Enables asynchronous exceptions.
asm("msr daifclr, #4");
// Determine which exception occured by checking the exception class.
ec = (get_esr_el2() >> 26) & 0b111111;
if (ec == 0b010101 /* SVC instruction execution in AArch64 state */
|| ec == 0b010110 /* HVC instruction execution in AArch64 state */
|| ec == 0b010111 /* SMC instruction execution in AArch64 state */) {
hhee_handle_hvc_smc_instructions(&args);
} else {
hhee_handle_abort_from_aarch64(&args);
}
asm("eret");
}
如果异常源自 HVC,则hhee_handle_hvc_smc_instructions将执行流重定向到 hhee_handle_hvc_instruction,如果异常来自 SMC,则将执行流重定向到 hhee_handle_smc_instruction。这些指令的处理将在后面的部分中详细介绍。
saved_regs_t* hhee_handle_hvc_smc_instructions(uint64_t x0,
uint64_t x1,
uint64_t x2,
uint64_t x3,
saved_regs_t* saved_regs) {
// ...
call_type = (get_esr_el2() >> 0x1a) & 3;
if (call_type == 2 /* HVC */) {
hhee_handle_hvc_instruction(x0, x1, x2, x3, saved_regs);
return saved_regs;
}
if (call_type == 3 /* SMC */) {
// Updates the exception return address to the instruction after the SMC, because trapping an instruction does not
// update the ELR_EL2 register like a regular HVC would.
set_elr_el2(get_elr_el2() + 4);
hhee_handle_smc_instruction(x0, x1, x2, x3, saved_regs);
return saved_regs;
}
// Normally unreachable.
log_and_wait_for_interrupt();
}
hhee_handle_abort_from_aarch64再次检查异常类,然后:
调用 hhee_trap_system_registers 如果异常来自对被困系统寄存器的访问;
handle_inst_abort_from_lower_el是否是指令中止;
handle_data_abort_from_lower_el是否是数据中止。
void hhee_handle_abort_from_aarch64(saved_regs_t* regs) {
// ...
// Determine which exception occured by checking the exception class.
esr_el2 = get_esr_el2();
ec = (esr_el2 >> 26) & 0b111111;
switch (ec) {
case 0b011000: /* Trapped MSR, MRS or System instruction execution in AArch64 state */
hhee_trap_system_registers(regs, esr_el2);
break;
case 0b100000: /* Instruction Abort from a lower Exception level */
handle_inst_abort_from_lower_el(regs, esr_el2);
break;
case 0b100100: /* Data Abort from a lower Exception level */
handle_data_abort_from_lower_el(regs, esr_el2);
break;
default:
log_and_wait_for_interrupt();
}
}
另一方面,SynchronousExceptionA32 仅处理指令和数据中止。它首先调用 hhee_handle_abort_from_aarch32,然后将执行重定向到 handle_inst_abort_from_lower_el(如果发生指令中止)或 handle_data_abort_from_lower_el(如果发生数据中止)。
void SynchronousExceptionA32(saved_regs_t args) {
// Enables asynchronous exceptions.
asm("msr daifclr, #4");
hhee_handle_abort_from_aarch32(args);
asm("eret");
}
void hhee_handle_abort_from_aarch32(saved_regs_t* regs) {
// ...
esr_el2 = get_esr_el2();
ec = (esr_el2 >> 26) & 0b111111;
switch (ec) {
case 0b100000: /* Instruction Abort from a lower Exception level */
handle_inst_abort_from_lower_el(regs, esr_el2);
break;
case 0b100100: /* Data Abort from a lower Exception level */
handle_data_abort_from_lower_el(regs, esr_el2);
break;
default:
log_and_wait_for_interrupt();
}
}
为了便于解释,我们可以将异常处理分为三个主要类别:
被困指令处理;
指令和数据中止处理;
HVC 和 SMC 处理。
在接下来的部分中,我们将逐一介绍它们,并解释它们如何与我们在本文开头列出的安全保证相关联。
陷阱指令处理¶
如前所述,虚拟机管理程序已配置为捕获一组系统寄存器。对这些寄存器的访问由 hhee_trap_system_registers 处理。此功能的主要目标是在修改关键寄存器时增加额外的安全层。虚拟机监控程序检查内核尝试执行的操作,并决定是否允许执行。
为了知道我们正在处理哪个操作,CPU 将有关相应指令的信息编码为:ESR_EL2
这些信息将被提取并相应地处理。对于初学者,根据 的值,调用与 sysregs_handlers_by_crn 数组不同的函数。CRn
uint64_t (*sysregs_handlers_by_crn[16])(uint64_t, uint64_t, uint64_t) = {
0, hhee_sysregs_crn1, hhee_sysregs_crn2, 0,
0, hhee_sysregs_crn5, hhee_sysregs_crn6, 0,
0, 0, hhee_sysregs_crn10, 0,
0, hhee_sysregs_crn13, 0, 0,
};
void hhee_trap_system_registers(saved_regs_t* regs, uint64_t esr_el2) {
// ...
// Direction, bit [0] = 0: Write access, including MSR instructions.
if ((esr_el2 & 1) == 0) {
op0 = (esr_el2 >> 20) & 0b11;
op2 = (esr_el2 >> 17) & 0b111;
op1 = (esr_el2 >> 14) & 0b111;
crn = (esr_el2 >> 10) & 0b1111;
rt = (esr_el2 >> 5) & 0b11111;
crm = (esr_el2 >> 1) & 0b1111; reg_val = *(uint64_t*)(®s->x0 + rt);
if (op0 == 0b11 /* Moves to and from Non-debug System registers */
&& op1 == 0b000 /* Accessible from EL1 or higher */) {
handler = sysregs_handlers_by_crn[crn];
if (handler) {
handler(reg_val, crm, op2);
}
}
}
// Updates the exception return address by adding the size of the instruction to the current value of ELR_EL2.
//
// IL, bit [25]: Instruction Length for synchronous exceptions.
il = (esr_el2 >> 25) & 1;
set_elr_el2(get_elr_el2() + 2 * il);
}
从这一点开始,它相对简单。我们知道哪些寄存器访问被捕获以及处理程序在哪里。现在我们只需要根据寄存器的值将寄存器映射到它们的处理程序。CRn
| 系统寄存器 | 操作0 | 操作1 | CRn的 | 客户关系管理 | 操作2 | 处理器 |
|---|
SCTLR_EL1 | 3 | 0 | 1 | 0 | 0 | hhee_sysregs_crn1 |
TTBR0_EL1 | 3 | 0 | 2 | 0 | 0 | hhee_sysregs_crn2 |
TTBR1_EL1 | 3 | 0 | 2 | 0 | 1 | hhee_sysregs_crn2 |
TCR_EL1 | 3 | 0 | 2 | 0 | 2 | hhee_sysregs_crn2 |
AFSR0_EL1 | 3 | 0 | 5 | 1 | 0 | hhee_sysregs_crn5 |
AFSR1_EL1 | 3 | 0 | 5 | 1 | 1 | hhee_sysregs_crn5 |
ESR_EL1 | 3 | 0 | 5 | 2 | 0 | hhee_sysregs_crn5 |
FAR_EL1 | 3 | 0 | 6 | 0 | 0 | hhee_sysregs_crn6 |
MAIR_EL1 | 3 | 0 | 10 | 2 | 0 | hhee_sysregs_crn10 |
AMAIR_EL1 | 3 | 0 | 10 | 3 | 0 | hhee_sysregs_crn10 |
CONTEXTIDR_EL1 | 3 | 0 | 13 | 0 | 1 | hhee_sysregs_crn13 |
CRn 1:SCTLR_EL1¶
我们将要研究的第一个陷阱处理程序是 hhee_sysregs_crn1,它验证对系统寄存器所做的修改。该函数首先检查系统寄存器存储在线程本地存储中的结构是否已初始化。一旦虚拟机监控程序处理了内核页表,就会初始化此结构。SCTLR_EL1
如果check_sctlr_el1成功返回,则表示所有操作都已被允许,我们使用内核提供的值进行更新。SCTRL_EL1
uint64_t hhee_sysregs_crn1(uint64_t rt_val, uint32_t crm, uint32_t op2) {
if (crm) {
return 0xfffffffe;
} // ACTLR_EL1 - should be unreachable with the current configuration.
if (op == 1) {
return 0xffffffff;
}
// CPACR_EL1 - should be unreachable with the current configuration.
else if (op == 2) {
return 0xfffffffe;
}
sys_regs = current_cpu->sys_regs;
// If the structure storing system register values has not been initialized yet, jumps to the SCTLR_EL1 validation
// routine.
if (!atomic_get(&sys_regs->regs_inited)) {
goto SCTLR_CHECK;
}
// Checks which translation base address registers defines the address space ID. If it's TTBR0_EL1, we move on to the
// SCTLR_EL1 validation routine.
//
// A1, bit [22]: Selects whether TTBR0_EL1 or TTBR1_EL1 defines the ASID.
if (!(sys_regs->tcr_el1 & (1 << 22))) {
goto SCTLR_CHECK;
}
ttbr1_el1 = get_ttbr1_el1();
// If no ASID has been specified, we go to the SCTLR_EL1 validation routine.
if (!(ttbr1_el1 & 0xffff000000000000)) {
goto SCTLR_CHECK;
}
// If we try to disable the MMU, an error is returned.
//
// M, bit [0]: MMU enable for EL1&0 stage 1 address translation.
if (!(rt_val & 1)) {
debug_print(0x100, "Disallowed turning off of MMU");
return 0xfffffff8;
}
// Processes the translation table referenced by TTBR1_EL1.
ret = process_ttbr1_el1(sys_regs, ttbr1_el1);
if (ret) {
return ret;
}
// If no error occured, mark the kernel page tables as processed.
current_cpu->kernel_pt_processed = 1;
SCTLR_CHECK:
// Checks the value of SCTLR_EL1 and updates the system register if changes were allowed by the hypervisor.
ret = check_sctlr_el1(rt_val);
if (!ret) {
set_sctlr_el1(rt_val);
}
return ret;
}
如果系统寄存器已保存在 g_sysregs 全局结构中,则process_ttbr1_el1不允许更改存储在 中的地址。否则,它将使用 process_kernel_page_tables 处理内核页表,并在成功后将 、 和 的值存储在此结构中。process_kernel_page_tables的内部结构将在本文后面的页表管理部分中详细介绍。TTBR1_EL1TCR_EL1MAIR_EL1TTBR1_EL1
uint64_t process_ttbr1_el1(sys_regs_t* sys_regs, uint64_t ttbr1_el1) {
// ...
// Checks if the ASID is determined by TTBR1_EL1.
//
// A1, bit [22]: Selects whether TTBR0_EL1 or TTBR1_EL1 defines the ASID.
if (((sys_regs->tcr_el1 >> 22) & 1) != 0) {
// Remove the ASID from TTBR1_EL1.
ttbr1_el1 &= 0xffffffffffff;
} // Check if the system registers have been stored.
if (atomic_get(&sys_regs->regs_inited)) {
// Changing TTBR1_EL1 is not allowed afterwards.
if (sys_regs->ttbr1_el1 == ttbr1_el1 && sys_regs->tcr_el1 == get_tcr_el1() &&
sys_regs->mair_el1 == get_mair_el1()) {
return 0;
} else {
return 0xfffffff8;
}
} else {
// Locking is required to modify the global structure containing the system registers values.
spin_lock(&g_sys_regs_lock);
// Retry the atomic read after taking the lock.
if (!atomic_get(&sys_regs->regs_inited)) {
// Store the system registers values.
sys_regs->tcr_el1 = get_tcr_el1();
sys_regs->mair_el1 = get_mair_el1();
sys_regs->ttbr1_el1 = ttbr1_el1;
// Only mark the registers as stored if the processing of the kernel page tables succeeded.
ret = process_kernel_page_tables();
if (!ret) {
atomic_set(1, &sys_regs->regs_inited);
}
}
spin_unlock(&g_sys_regs_lock);
return ret;
}
}
然后,关于函数check_sctlr_el1,它执行下面列出的多个验证。
还进行了其他杂项检查,但此处不进行解释。您可以查看下面的代码以获取更多信息。
uint64_t check_sctlr_el1(int32_t rt_val) {
// If kernel page table have been processed by the hypervisor and the MMU is enabled, the kernel is not allowed to
// disable it.
//
// M, bit [0]: MMU enable for EL1&0 stage 1 address translation.
if (!(rt_val & 1) && current_cpu->kernel_pt_processed && get_sctlr_el1() & 1) {
debug_print(0x100, "Disallowed turning off of MMU");
return 0xfffffff8;
} // If WXN is enabled, the kernel is not allowed to disable it.
//
// WXN, bit [19]: Write permission implies XN (Execute-never).
if (!(rt_val & (1 << 19)) && get_sctlr_el1() & (1 << 19)) {
debug_print(0x102, "Disallowed turning off of WXN");
return 0xfffffff8;
}
// If SPAN is enabled, the kernel is not allowed to disable it.
//
// SPAN, bit [23]: Set Privileged Access Never, on taking an exception to EL1.
if (rt_val & (1 << 23) && !(get_sctlr_el1() & (1 << 23))) {
return 0xfffffff8;
}
// If PAN is not supported on the platform, returns an error.
//
// PAN, bits [23:20]: Privileged Access Never, indicates support for the PAN bit.
else if (!(get_id_aa64mmfr1_el1() >> 20) & 0xf) {
return 0xfffffffe;
}
// Makes sure endianness of data accesses are little-endian at EL1.
//
// EE, bit [25]: Endianness of data accesses at EL1.
if (rt_val & (1 << 25)) {
return 0xfffffffd;
}
// Checks the endianness at EL0. Keeps going if we're in little endian, otherwise checks in ID_AA64MMFR0_EL1 if mixed-
// endian is supported on the platform, and if it's not, returns an error.
//
// E0E, bit [24]: Endianness of data accesses at EL0.
if ((rt_val & (1 << 24)) && !((get_id_aa64mmfr0_el1() >> 8) & 0xf)) {
return 0xfffffffe;
}
// Having SCTRL_EL1 & 0x520c40 equal to 0x500800 means we want the following bit to have fixed values:
//
// - nAA, bit [6]: Non-aligned access.
// * 0b0: certain load/store instructions are generate an Alignment fault if all bytes being accessed are not
// 16-byte aligned.
// - EnRCTX, bit [10]: Enable EL0 Access to the CFP RCTX, DVP RCT and CPP RCTX instructions.
// * 0b0: EL0 access to these instructions is disabled and are trapped to EL1.
// - EOS, bit [11]: Exception Exit is Context Synchronizing.
// * 0b1: An exception return from EL1 is a context synchronizing event.
// - TSCXT, bit [20]: Trap EL0 Access to the SCXTNUM_EL0 register.
// * 0b1: EL0 access to SCXTNUM_EL0 is disabled, causing an exception to EL1.
// - EIS, bit [22]: Exception Entry is Context Synchronizing.
// * 0b1: The taking of an exception to EL1 is a context synchronizing event.
if (rt_val & 0x520c40 != 0x500800) {
return 0xfffffffe;
}
// Returns without error if the kernel wants to disable the SETEND instruction at EL0.
//
// SED, bit [8]: SETEND instruction disable.
if (rt_val & (1 << 25)) {
return 0;
}
// Otherwise it checks if:
//
// - ID_AA64MMFR0_EL1, if mixed-endian is supported.
// - ID_AA64PFR0_EL1, if EL0 can be executed in either AArch64 or AArch32 state.
if ((get_id_aa64pfr0_el1() & 0xf) > 1 && !(get_id_aa64mmfr0_el1() >> 8) & 0xf) {
return 0;
}
return 0xfffffffe;
}
CRn 2:TTBR0_EL1、TTBR1_EL1和TCR_EL1¶
下篇继续...
二进制漏洞(更新中)
![]()
其它课程
windows网络安全一防火墙
![]()
windows文件过滤(更新完成)
![]()
USB过滤(更新完成)
![]()
游戏安全(更新中)
![]()
ios逆向
![]()
windbg
![]()
恶意软件开发
![]()
还有很多免费教程(限学员)
![]()
![]()
![]()
更多详细内容添加作者微信
![]()
![]()