
2023-11-15 03:52:40 Author: securityboulevard.com(查看原文) 阅读量:8 收藏
In the relentless battleground of bot and fraud prevention, one menacing adversary looms large—the pervasive threat of website scraping. This insidious automated threat, a more pervasive menace than even the scourges of ATOs and carding attacks, has infiltrated the very fabric of the internet. With stealthy algorithms and an insatiable appetite for data, web scraping attacks pose a formidable challenge, breaching the boundaries of privacy and security.
Web scraping is so lucrative and advantageous that it has actually spawned a nefarious industry peddling “scraping-as-a-service.” These shadowy enterprises provide bypasses to bot defenses, opening the floodgates for determined attackers or organizations to plunder data from unsuspecting companies.

RECOMMENDED RESOURCE
2023 Cybercrime Prevention Playbook
All About Scraping-as-a-Service
Essentially, cybercriminals utilizing scraping-as-a-service platforms can deploy a fleet of virtual bots to mimic human behavior, making it exceptionally challenging for traditional security systems to distinguish between legitimate and malicious activities. By harnessing this technology, bad actors can not only harvest sensitive information but also launch targeted attacks, manipulate online content, and even disrupt digital services. In fact, a recent report states nearly 40% of companies surveyed said their organization lost more than 10% of revenue due to web scraping over a month-long period.
The ease of access to scraping-as-a-service exacerbates the cybersecurity landscape, enabling threat actors to exploit vulnerabilities and evade detection, thereby amplifying the risks associated with unauthorized data extraction and cyber intrusions.
For online businesses, and specifically sectors that rely heavily on proprietary data and digital assets, the urgency to fortify security defenses against the growing onslaught of web scraping has never been more pressing.
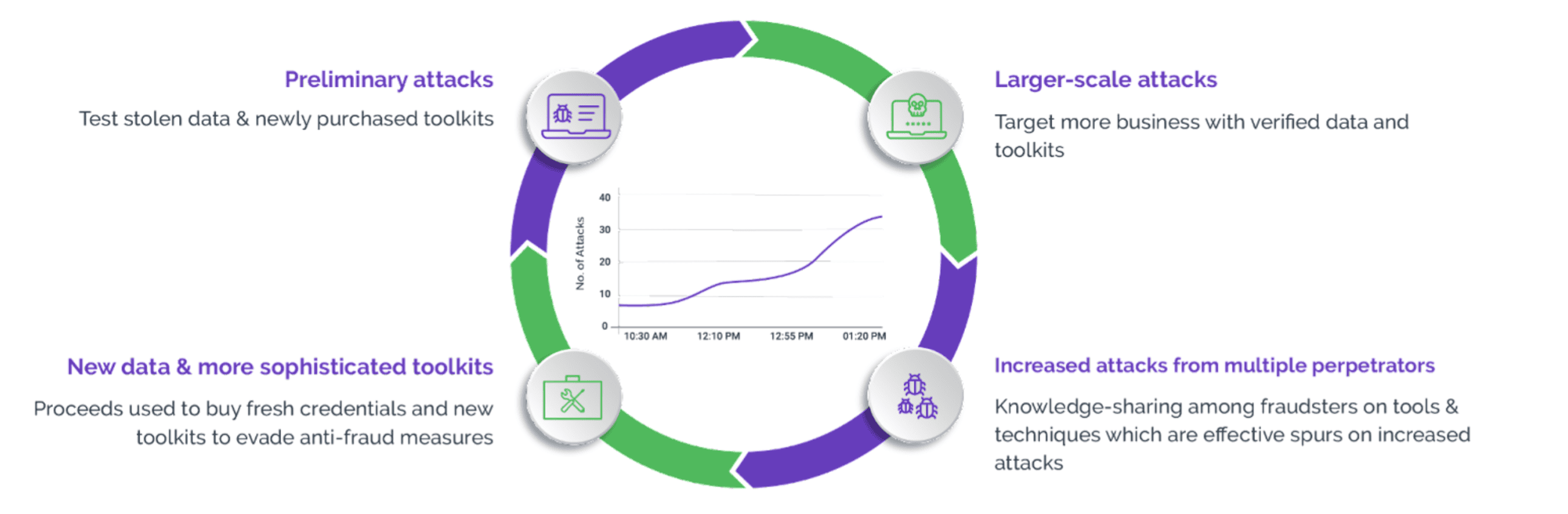

Monetizing Scraping-as-a-Service
The driving force behind web scraping is simple—money. Cybercriminals can monetize web scraping attacks in four different ways:
- Imitating a brand’s website to establish counterfeit sites and collect valuable personal information
- Extracting content through scraping for a competitive edge or to undermine rival businesses
- Scraping pricing details for arbitrage opportunities, where one can buy a product at a lower price from one source and sell it at a higher price on another, thereby profiting from the price difference
- Exploiting pricing errors to acquire complementary or significantly discounted items
Web scraping is distinct from other automated threats, such as credential stuffing, card testing, and ATOs in that the initial challenge involves determining whether a scraping request is from a bot or a human. Identifying a scraper is a one-time session decision, and any subsequent attempts to analyze behaviors using machine learning (ML) or other methods to prevent scraping result in the bot successfully completing its assigned task.
The rising trend of scraping-as-a-service platforms adds a concerning layer to bot management, as threat actors can now conveniently leverage these tools to automate and launch sophisticated scraping attacks, exploiting the challenges associated with distinguishing between bot and human interactions.

Type of Scraping Used in Cyberattacks
Scraping-as-a-service encompasses a diverse array of web scraping techniques, each tailored to meet the specific needs of its users. This clandestine service leverages various methods, ranging from simple HTML parsing to more advanced techniques like browser automation and API abuse. By employing these diverse approaches, scraping-as-a-service not only enhances its adaptability to different target websites but also evades detection by mimicking human interaction patterns.
This multifaceted nature of scraping-as-a-service not only underscores its sophistication but also amplifies the challenges faced by security professionals in effectively mitigating the risks associated with automated data extraction.
Content Scraping
From IP theft to counterfeit websites, content scraping can be serious business. An initial request is sent to load and retrieve the webpage, and the HTML loads the page just once, as the first page load cannot be prevented. At this juncture, the scraper acquires the necessary data swiftly, seizing the information before the business has an opportunity to classify and impede the process.
This move creates an exceedingly brief timeframe to discern whether the incoming request originates from a bot or a human, underscoring the urgent need for rapid decision-making in distinguishing between automated and genuine interactions.
Rival entities engage in the practice of scraping images or entire page content to exploit the investment—be it time, effort, or financial resources—that you’ve dedicated to content development, repurposing it for their own websites. Moreover, content scraping extends beyond mere competition, taking a potentially malicious turn with the aim of sabotaging a competitor’s search ranking. This is achieved through intentional duplication of their content, posing a strategic threat to the targeted competitor’s online visibility and relevance.
Thanks to scraping as-a-service, now anyone armed with a credit card can effortlessly extract information from a variety of websites. These services cater to numerous popular websites and offer customization options for sites tailored to your preferences. Frequently, these services are bundled with a comprehensive suite, encompassing discreet proxies to guarantee that scraping requests remain incognito.
Price Scraping
The landscape of price scraping encompasses both positive and negative aspects. Consider the travel and hospitality sector, where hotels collaborate with travel partners to openly share and analyze pricing information across a wider network. On the flip side, there are instances of malicious price scanning, as witnessed when competitors employ covert scraping bots to meticulously track and undercut pricing strategies. The ambiguity extends to scrapers with uncertain intentions, such as those seeking to exploit arbitrage opportunities by capitalizing on price differentials among various marketplaces.
Despite the motivations behind it, curbing price scraping has proven to be an intricate challenge. Operators employ tactics like disguising their bots to resemble either benign bots (e.g., Google bots that crawl websites) or human behavior. When adopting a human guise, scraping bots leverage residential proxy networks, ensuring that each request mimics a new session. Adding complexity, these residential proxy networks can be tailored specifically for a target website, employing geo-targeting and device-specific configurations to seamlessly blend in with genuine shoppers.
Freebies
The recent surge in “freebie bots” has introduced a fresh set of challenges for retailers grappling with price scraping issues. Unlike conventional price scanners, freebie bots capitalize on pricing errors made by retailers. Upon detecting a configurable $0 or percentage discount off the Manufacturer’s Suggested Retail Price (MSRP), these bots swiftly automate the purchase process before the pricing error is rectified. Across the internet, there’s a wave of promotion for freebie bots, portraying them as a lucrative avenue for obtaining thousands of dollars worth of goods and services without cost.
These freebie bots pose a detection conundrum similar to that of price scanners, relying on residential proxies to evade detection systems. The complexity is heightened by the fact that these bad bots are affordably sold to individual consumers, encouraging widespread use. Moreover, they engage in rapid and repeated scans at extremely short intervals, diligently seeking pricing errors before they are identified and rectified. This places retailers in a formidable predicament, as tens of thousands of users simultaneously bombard their entire product catalog every few seconds, solely in pursuit of the occasional pricing glitch to exploit for free acquisitions.
Arkose Labs Fights Scraping-as-a-Service
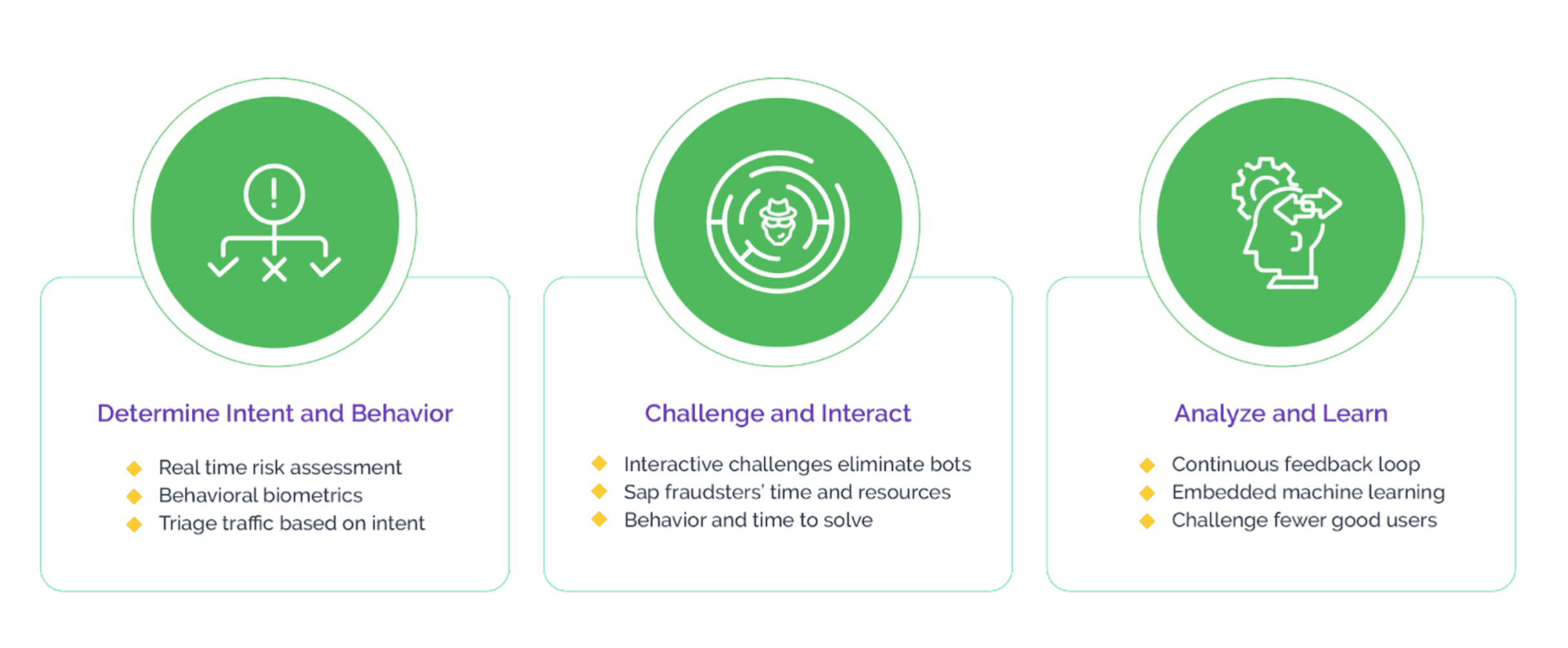
Arkose Labs empowers companies to safeguard their vital data and content, the linchpin of their operations, against the threat of malicious scraping attacks. Utilizing the real-time analytics of Arkose MatchKey, web traffic is meticulously segmented based on its intent, and bot traffic encounters engaging interactive puzzles. The exceptional effectiveness of these challenges underpins Arkose Labs’ industry-leading 100% Service Level Agreement (SLA) guarantee against automated attacks.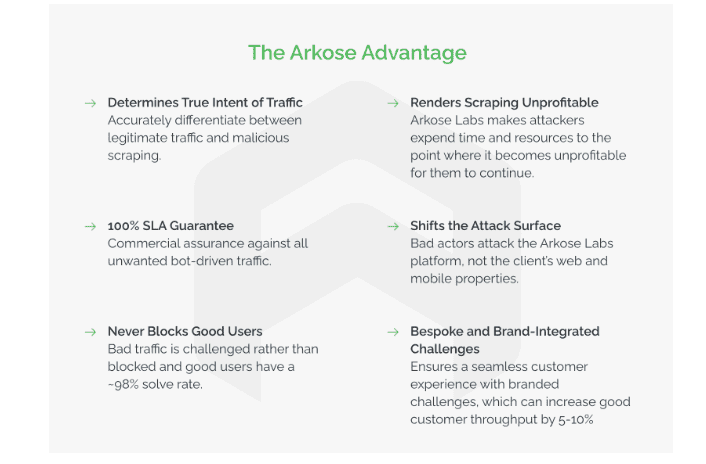
This two-pronged strategy of Arkose Bot Manager ensures a forward-looking defense against scraping attacks, enabling businesses to more effectively discern between legitimate and malicious activities. The scalability of scraping for malicious users is curtailed, preventing any viable return on investment from such activities. Furthermore, this approach ensures that genuine users are never wrongly obstructed, preserving revenue-generating traffic and fostering the long-term commercial success of the company.
*** This is a Security Bloggers Network syndicated blog from Arkose Labs authored by Jenn Jeffers. Read the original post at: https://www.arkoselabs.com/blog/scraping-as-a-service-how-harmless-tool-became-cyber-threat/
如有侵权请联系:admin#unsafe.sh