背景
任何智能活动的都可以称为人工智能,而机器学习(Machine Learning)属于人工智能的一个分支,深度学习(Deep Learning)则是机器学习的分支。近年来,随着基础设施的完善,海量大数据的积累,机器学习方法理论越来越成熟,算力的大幅度提升,互联网企业也越来越愿意增大在AI领域的投入,AI的优势在于处理海量数据提取捕获其中有用信息上发挥着非常重要的作用,如OCR领域图片鉴黄、自然语言处理方面的恶意言论捕获、风控领域画像、推荐系统等。

概念
| 算法分类 | 解决什么问题 |
|---|---|
| 分类算法 | 是什么 |
| 回归算法 | 是多少 |
| 聚类算法 | 怎么分 |
| 数据降维 | 怎么压 |
| 强化学习 | 怎么做 |
目的
通过机器学习的方式识别恶意流量
特征工程
使用sklearn的TFIDF、2ngram进行分词
什么是TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
词频(TF) = 某个词在文章中的出现次数
逆文档频率(IDF) = log(语料库的文档总数/包含该词的文档总数+1)
公式:TF-IDF = TF * IDF
举例:假设一篇文章中由1万个词组成,其中“跨站脚本”,“web”,“安全”,“攻击”几个词各出现100次,那么他们对应的词频TF就是 TF = 100/10000 = 0.01。
语料库中一共有1000篇文章,其中包含“跨站脚本”的有9篇,包含“web”的有89篇,包含“安全”的有399篇,包含“攻击”的有499篇,那他们对应的TDF如下,由TFIDF值可知这篇文章重点应该是在讲“跨站脚本”
| 词 | IDF | TF*IDF |
| 跨站脚本 | log(1000/10)=6.9 | 6.9 * 0.01 =0.069 |
| web | log(1000/90)=4.7 | 4.7 * 0.01 =0.047 |
| 安全 | log(1000/400)=3.2 | 3.2 * 0.01 =0.032 |
| 攻击 | log(1000/500)=2.9 | 2.9 * 0.01 =0.029 |
流程
数据集正例样本10万,数据集负例样本5万,由于初始负例样本不足,可以在特征工程阶段将负例样本*2扩大负例样本的数据集数量,但效果不会很明显,一般在深度学习的时候特征样本不足我会这样做数据扩展。
对数据做一些基础的特征工程对连续的数字或单独的数字都转化为’8′,将quries里的https|http转化成同一个特征量等等
label 0 标记正例样本,label 1 标记负例样本
class LR(object):
def __init__(self):
self.goodX = self.DecodeQuery("./goodX.txt")
self.badX = self.DecodeQuery("./badqX.txt")
self.goodY = [0] * len(self.goodX)
self.badY = [1] * len(self.badX)
self.vectorizer = TfidfVectorizer(ngram_range=(1, 3))
self.X = self.vectorizer.fit_transform(self.goodX + self.badX)
def DecodeQuery(self, fileName):
data = [x.strip() for x in open(fileName, "r").readlines()]
query_list = []
for item in data:
item = item.lower()
if len(item) > 50 or len(item) < 5:
continue
h = HTMLParser()
item = h.unescape(item)
item = parse.unquote(item)
item, number = re.subn(r'\d+', "8", item)
item, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:]+', "http://u", item)
query_list.append(item)
return list(set(query_list))
模型训练与预测
train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签,其中test_size是代表要划分出多少的数据做为测试集,random_state是种子,也就是说当random_state不为0时,每次train_test_split生成的数据集是一致的,以便与我们在初期阶段保持数据集一致进行调试。
模型使用KNN(K-Nearest neigbour,KNN)Cover和Hart在1968年提出了最初的邻近算法。所谓KNN,就是K个最近邻居的意思。说的是每个样本都可以用它最接近的k个邻居来代表。属于一种有监督的分类(Classification)算法,同时属于懒惰学习(lazy learning)即KNN没有显式的学习过程,也就是没有训练数据的阶段,所以也代表了该阶段的时间开销为零,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。
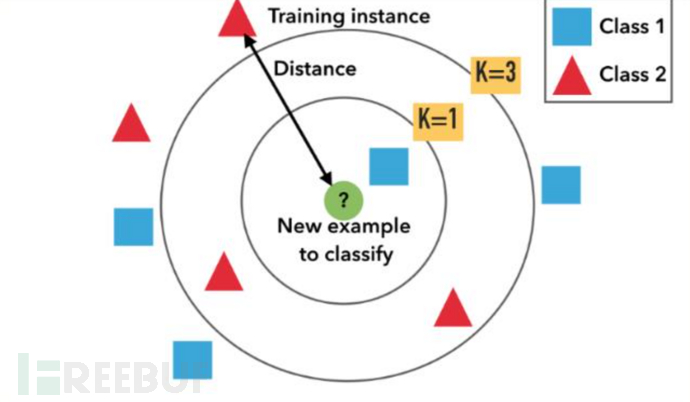
KNN三要素
1.K值的选择:对于K值的选择,如果K值较小表示使用较小邻域中的样本进行预测,训练误差会减少,但是模型会变得复杂,容易过拟合。
2.距离的度量:一般使用欧几里得距离
3.决策规则:分类模型中使用多数表决的方式或者加权表决(距离与权重成反比);在回归模型中,使用平均值法
KNN的优化
当如果有大量的数据输入的时候为了加快检索,引入了优化算法,相当于是使用了特殊的结构来保存数据,以减少数据的检索次数。
KNN的使用
def TrainModel(self):
X_train, X_test, y_train, y_test = train_test_split(self.X, self.goodY + self.badY, test_size=0.2, random_state=16)
knn = neibours.KNeiborsClassifier(n_neibours=5)
knn.fit(X_train, y_train)
joblib.dump(knn, "knn.pickle")
在做模型训练的时候,尤其是在训练集上做交叉验证,通常想要将模型保存下来,然后放到独立的测试集上测试,scikit-learn已经有了模型持久化的操作,存储模型(持久化)一般就两种方式一种是joblib和pickle
倒入模块 from sklearn.externals import joblib
保存模型 joblib.dump(model,’filename.pkl’)
读取模型 joblib.load(modelName)
def Predicts(self, modelName, fileName):
knn = joblib.load(modelName)
input_x = self.DecodeQuery(fileName)
X_predict = self.vectorizer.transform(input_x)
res = knn.predict(X_predict)
res_list = []
for url , y in zip(input_x, res):
label = '正常请求' if y == 0 else '恶意请求'
print(label , url )
最终预测结果
这里算法笔者用的KNN,但KNN属于懒惰算法,最大但缺点之一在于在数据量庞大的时候运算会非常的慢,另外一个会受离群点的影响,这个knn的例子只适合做试验讲解,因为KNN具有良好的可解释性上
恶意请求 /cgi-home/ion-p?page=../../../../../etc/passwd
恶意请求 <svg><script xlink:href=data:,alert(8) />
恶意请求 /./\/././\/././\/././\/././\/././\/././\/./{file}
正常请求 /scripts_photositeprinting/
正常请求 /main.php?stuff="&ver&rem\xa8
总结
机器学习比较痛苦的是调参数、做特征工程,本文没有特意去做特征工程使用了ngram分词实现的特征,调参的话懒人可以通过GridSearch和RandomizedSearchCV进行搜索,下篇换个例子来介绍。
写此文的目的地是笔者在学习过程中踩了很多坑,也是逐步在梳理自己认知的过程,也希望多一些相关的文章给正在研究或刚入门同学多一些参考,学无止境,不喜勿喷哈。
*本文原创作者:邹先生007,本文属FreeBuf原创奖励计划,未经许可禁止转载
如有侵权请联系:admin#unsafe.sh