Eventi disastrosi e minacce ransomware sono in forte crescita. Un incendio incontrollato, un’inondazione o un crimine informatico perpetrato da una cyber gang a caccia di un riscatto hanno un comune denominatore: un effetto disastroso sulla Business Continuity.
Quando essa si arresta, si producono danni finanziari. Le violazioni dei dati, secondo Ibm, nel 2022 hanno registrato un costo medio pari a 4,35 milioni di dollari. Entro il 2031, si verificherà un attacco informatico ogni due secondi, in grado di interrompere le attività e causare perdite ingenti.
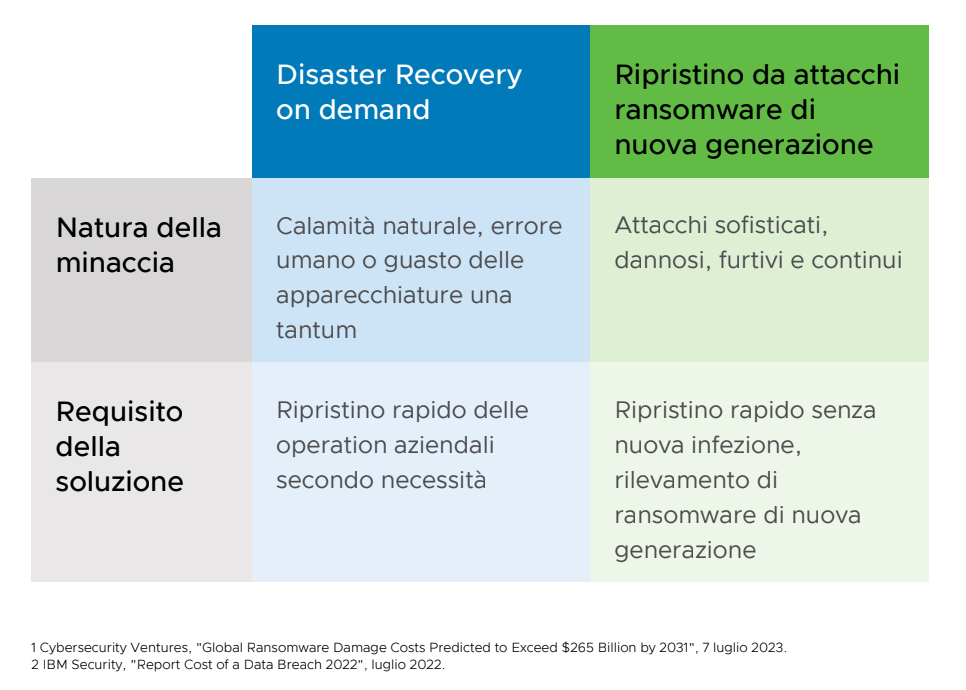
La risposta più diffusa agli eventi disastrosi è l’adozione di una strategia universale di gestione per Disaster Recovery (DR) e il ripristino da attacchi ransomware. Tuttavia, secondo VMware, non è invece l’approccio ideale.
Sebbene DR e ripristino da attacchi ransomware migliorino l’efficienza e il livello di resilienza, il terreno fertile per un evento disastroso è l’incapacità di riconoscere le sfide. Ed è qui che bisogna agire, imparando ad allineare le due strategie.

Disaster Recovery e ripristino da ransomware: la guida per allineare le due strategie
Occorre seguire le best practice, adottando le tecniche e le soluzioni giuste per rendere le organizzazioni in grado di unificare la gestione del DR e del ripristino da attacchi ransomware.
In oltre, secondo VMware, conviene ottimizzare le funzionalità di ripristino e tagliare il costo totale di proprietà (TCO) fino al 60% rispetto al DR on-premise.
Inoltre è necessario semplificare le operation, gli upgrade e la manutenzione. Bisogna allineare RPO (Recovery Point Objective) e RTO (Recovery Time Objective) alle necessità dell’azienda.
I 7 passaggi per un piano di ripristino in caso di “doppia estorsione”
Un processo performante di pianificazione per Disaster Recovery e ripristino da attacchi ransomware individua gli elementi da proteggere e le modalità di protezione. Occorre anche valutare gli scenari potenziali di eventi disastrosi e ransomware in fase di esecuzione dei passaggi, per avviare un ripristino rapido e corretto, a prescindere dallo scenario.
I passaggi da seguire prevedono:
- la valutazione;
- la definizione;
- l’approvvigionamento;
- creazione e replica;
- configurazione;
- test;
- operatività.
Occorre effettuare un’ispezione, catalogo e mappa del patrimonio di dati, stabilendo la protezione efficace per i carichi di lavoro e le macchine virtuali. La valutazione aiuta a migliorare le risorse, per supportare entrambe le operation di ripristino senza pregiudicare l’affidabilità. Il tempo è cruciale per assicurare la Business Continuity.
Occorre definire il contesto di entrambi i piani di ripristino, compresi gli obiettivi (RTO e RPO), gli accordi sui livelli di servizio, le pianificazioni di protezione e la durata dello storage. Bisogna verificare l’opportunità di includere le due tecniche di ripristino rapido di VMware: Cloud Disaster Recovery e Ransomware Recovery.
Bisogna integrare le soluzioni, i vendor, lo storage e le risorse che servono per creare i nuovi piani delineati. Potrebbe risultare efficace sommare una soluzione gestita per DRaaS (Disaster Recovery as-a-Service) e RRaaS (Ransomware Recovery as-a-Service).
Grazie a storage e meccanismi sicuri, è possibile realizzare siti di ripristino e gruppi di protezione e replicare i dati. Bisogna elaborare piani di failover e sperimentarli, allineando i propri siti. Creare una rete isolata per supportare la messa in quarantena, i test e la convalida delle snapshot in caso di attacchi ransomware.
Un test periodico dei propri piani di ripristino permette di valutare che non determinino interruzione del servizio, verificandone l’applicabilità nel caso di un incidente reale. Bisogna adattarli e iterarli continuamente in base ai risultati dei test.
I gruppi di protezione devono essere in esecuzione: è necessario verificarlo, oltre a monitorare le condizioni di ripristino generali, svolgere report ed effettuare un confronto fra i risultati e le aspettative e gli accordi sui livelli di servizio.
In caso di guasti hardware e arresti pianificati a un sistema primario, infine, i meccanismi di failover eseguono un’inversione e un reindirizzo automatico delle richieste verso un sistema secondario in grado di simulare l’ambiente del sistema primario.
Benefici delle soluzioni DRaaS e RRaaS gestite
I complessi requisiti di gestione del ripristino possono preoccupare, avere costi alti, sollevare dubbi sull’affidabilità delle soluzioni
o dei processi adottati. Invece le soluzioni gestite DRaaS e RRaaS si adattano alla propria organizzazione, azzerando i timori su costi e affidabilità.
L’ampia esperienza di un partner DRaaS o RRaaS consente di ridurre i tempi per adottare un piano affidabile, evitando errori che potrebbero risultare costosi o addirittura irrisolvibili.
I partner potrebbero anche agevolare la creazione e l’implementazione di una strategia di protezione e ripristino end-to-end, in grado di venire incontro alle necessità di ripristino e usufruire di integrazioni native. Il tutto mettendo al centro l’agilità.
I vantaggi delle soluzioni DRaaS e RRaaS gestite sono: l’affidabilità secondo le esigenze, il taglio dei costi, la semplificazione delle operation, il veloce ripristino da cyber attacchi di tipo ransomware.
Una soluzione di ripristino gestita ed affidabile permette alle aziende e alle organizzazioni il mantenimento della disponibilità dei dati a seconda delle esigenze, ripristinando velocemente i carichi di lavoro mission critical.
Grazie a uno storage su cloud economico e a pagamenti solo per la capacità di failover secondo le necessità, si azzera il bisogno di un data center secondario e di risorse di ripristino ad hoc.
Soluzioni DRaaS e RRaaS gestite permettono, inoltre, di semplificare la definizione, amministrazione e test di procedure di failover in un ambiente IT che evolve continuamente. Consentono anche di abilitare velocemente la capacità di failover in caso di disastro.
L’automazione guidata e il ripristino sicuro, con opzioni integrate (di disponibilità, sicurezza e networking), permettono infine di minimizzare il downtime e la perdita di dati in caso di minacce ransomware.
Casi di successo: storie reali di resilienza
Grazie alle soluzioni di Disaster Recovery e ripristino di VMware, due organizzazioni hanno migliorato la loro resilienza: Fozzy Group e Merrick.
Fozzy Group, uno dei principali rivenditori al dettaglio in Ucraina, doveva garantire la disponibilità della proproia infrastruttura essenziale anche in caso di attacchi ransomware in periodo di guerra. In precedenza, Fozzy sfruttava diversi sistemi debolmente accoppiati, con cui mettevano a punto piani di ripristino difficili da testare. Oggi VMware Cloud Disaster Recovery consente a Fozzy Group di offrire beni essenziali ai suoi clienti, senza interruzione di servizio.
Merrick ha risparmiato sia sui costi che sui tempi di ripristino, passati da vari giorni a pochi minuti con VMware Cloud Disaster Recovery. Prima l’azienda usava una rete di componenti complessa e costos, noleggiando data center specifici per proteggere eventi disastrosi. Merrick ora è passato a VMware Cloud Disaster Recovery per proteggersi da eventi disastrosi ed attacchi ransomware. Si integra con l’infrastruttura VMware esistente e sfrutta il cloud come destinazione di failover.
Ripristino potenziato e basato su cloud
I clienti possono usare VMware Cloud Disaster Recovery e VMware Ransomware Recovery direttamente dalla Cloud Console VMware vSphere+TM. La soluzione promuove una transizione fluida, passando da operation di DR on-premise multi-vendor, costose e con esecuzione manuale, a operation del cloud unificate, resilienti e automatizzate con ripristino sicuro.
La protezione dei dati è possibile in ogni sede con un’unica soluzione fondata su cloud per il Disaster Recovery e il ripristino da attacchi ransomware. Comprende un workflow ad hoc con funzionalità integrate per individuare, confermare con convalida ed effettuare il ripristino dei carichi di lavoro secondo necessità.
L’ambiente di ripristino, isolato, facile e totalmente gestito, permette inoltre di eseguire test ed iterazioni, consentendo la prevenzione da nuove infezioni. Il provisioning della capacità di failover si esegue solo quando serve, direttamente dalla console VMware Cloud Disaster Recovery, con un ambiente di ripristino isolato per prevenire nuove infezioni dei carichi di lavoro di produzione, attraverso antivirus di ultima generazione e funzionalità di analisi comportamentale integrati e grazie alla selezione guidata dei punti di ripristino.
Vantaggi
Gli utenti VMware vSphere, passando a vSphere+, possono così adottare una soluzione DRaaS.
Questi servizi scalabili e on demand gestiti da VMware permettono alle organizzazioni di conseguire valore in poche ore; usare l’automazione per distribuire, gestire e testare; ridurre i costi per hardware, manutenzione e manodopera; effettuare risparmi su CapEx e tagliare il TCO fino al 60% rispetto al classico DR.
La guida al Disaster Recovery (DR) e ripristino in 7 passi
In caso di eventi disastrosi, occorre impostare un ripristino altamente prevedibile. Nell’arco degli ultimi anni hanno registrato un aumento gli eventi disastrosi con impatti devastanti per l’IT: sia causati da calamità naturali (uragani, incendi eccetera) sia provocati dall’uomo come gli attacchi informatici (+38% nel 2022 rispetto al 2021).
In questi casi, bisogna effettuare il ripristino dell’infrastruttura IT della propria organizzazione il più velocemente possibile per assicurare la Business Continuity (BC).
Per questo motivo, entra in gioco il piano di Disaster Recovery (DR) e protezione dal ransomware. Occorre analizzare ogni fase con cura, snellire i processi e proteggere i dati mission critical con backup affidabili, senza downtime aggiuntivi.
Secondo VMware, conviene scegliere una soluzione di Disaster Recovery e protezione da ransomware il più possibile noiosa.
VMware ha sintetizzato 7 raccomandazioni che aiutano a prepararsi a tutto ciò che potrebbe avvenire in futuro, senza farsi cogliere dal panico e puntando su un ripristino prevedibile. Ecco i passaggi.
Serve un team di ripristino con ruoli ben chiari
Prima di un evento disastroso, conviene vagliare il team da coinvolgere nel ripristino sotto il profilo dell’IT, per sapere cosa deve succedere e quando. Ogni minuto è prezioso. Tutti i membri del team di ripristino dovrebbero avere chiari e definiti i loro ruoli: sapere chi supervisiona il ripristino dei dati e come prevede, chi comunica al team più vasto cosa sta succedendo, e se ci sono terze parti, come vendor, da coinvolgere.
Le necessità del backup
Il team deve fare luce sui dati da classificare come essenziali e decidere come proteggerli di conseguenza durante un evento disastroso fisico o digitale.
Il piano deve focalizzarsi su 5 punti: cosa sollecita backup o ricollocazione, chi deve effettuare i backup, come implementarli; quando e con quale frequenza eseguire i backup e come proteggerli.
Non c’è un’unica strategia di backup per tutte le necessità. Le organizzazioni possono coniugare vari approcci, per esempio on-premise, multi-cloud, Disaster Recovery as-a-Service (DRaaS), Ripristino da attacchi ransomware as-a-Service (RRaaS), virtualizzazione e snapshot immutabili di tipo air-gap. L’obiettivo è quello di centrare gli obiettivi monitorando il costo totale di proprietà (TCO).
Per esempio, soluzioni cloud convenienti e con pagamento secondo necessità, come VMware Cloud Disaster Recovery e VMware Ransomware Recovery, possono tagliare in maniera significativa TCO e CapEx, permettendo allo stesso tempo alle organizzazioni di recuperare, riprendendosi dalle cyber minacce in modo sicuro e veloce con l’automazione guidata, con un approccio cloud-first per facilitare le operation di ripristino.
Gli obiettivi di ripristino
Quando si pianifica un Disaster Recovery e si protegge dal ransomware, occorre comprendere Recovery Point Objective (RPO) che segnalino la frequenza dei backup e Recovery Time Objective (RTO) che stabiliscano il downtime massimo permesso per ogni gruppo di protezione.
Occorre coordinarsi con le principali parti coinvolte, orchestrandole per delineare questi RPO e RTO.
Per esempio, VMware ha ridotto di cinque volte il Recovery Time Objective per i carichi di lavoro mission critical di Shriram Value Services.
Ripristino più efficace con l’automazione guidata
Rispondere velocemente è una priorità in caso di incidenti.
Occorre minimizzare gli interventi manuali, automatizzando il più possibile il Disaster Recovery e il ripristino da attacchi ransomware.
Bisogna analizzare i processi del piano di ripristino, formulando strategie per automatizzare il percorso nel senso della prevedibilità.
VMware Cloud Disaster Recovery e VMware Ransomware Recovery permettono, per esempi, di valutare la possibilità di automatizzare: la scelta dei punti di ripristino; convalidare e analizzare i punti di ripristino; provisioning dell’ambiente di ripristino isolato (IRE); workflow di ripristino da attacchi ransomware; ripristino orchestrato secondo le esigenze; aggiornamenti e rinnovi dei prodotti; monitoraggi dello stato del ripristino; report di audit.
Verifica periodica dei piani
Occorre verificare continuamente il proprio piano di ripristino, in modo da verificarne l’efficacia e da prevenire potenziali sorprese in presenza di scenari di eventi disastrosi in continua evoluzione.
È necessario valutare e delineare tutti i potenziali rischi, interni ed esterni, che potrebbero causare interruzioni delle attività. Inoltre bisogna eseguire il progetto, l’implementazione e l’automatizzazione dei test periodici e i controlli dello stato e convalidare ogni scenario. Bisogna dunque effettuare un aggiornamento periodico del programma dei test per non restare indietro nel panorama delle potenziali cyber minacce. L’obiettivo è condurre l’organizzazione a un ripristino noioso e prevedibile.
Inoltre, test e failover non devono essere mai motivo di interruzione delle attività. In caso contrario, bisogna riprendere in esame la soluzione di ripristino adottata. È conveniente rivalutare la possibilità di rimpiazzare il DR on-premise tradizionale, sostituendolo con una soluzione RRaaS e DRaaS basata su cloud in grado di effettuare i test cruciali senza interruzione delle operation aziendali.
I requisiti di ripristino da attacchi ransomware
Molte aziende si aspettano che le loro soluzioni di backup e DR di base tutelino i loro dati in caso di attacco ransomware. Tuttavia, i ransomware attuali possono restare silenti e inosservati per mesi, diffondendosi in maniera lenta, per infettare non solo i dati fondamentali di un’organizzazione, ma anche i loro backup.
Il ransomware evolve anche senza file, lavorando in memoria per evitare footprint da seguire. Il ransomware non è rilevabile mediante la scansione tradizionale dei file di backup. Inoltre dopo un attacco ransomware non è semplice individuare punti di ripristino e dati puliti.
Le organizzazioni necessitano invece di soluzioni ad hoc per il ripristino da attacchi ransomware. Occorre selezionare una soluzione scelta che includa un antivirus di nuova generazione con analisi comportamentale dei carichi di lavoro attivi. E il provisioning deve anche includere un ambiente di ripristino isolato al fine della convalida dei punti di ripristino e della prevenzione da una nuova infezione.
Verificare la soluzione attuale
Bisogna valutare la propria soluzione di ripristino, assicurandosi di esaudire i requisiti di BC.
A questo fine, bisogna capire se la soluzione di ripristino è in grado di resistere ai potenziali eventi disastrosi che potrebbero affliggere l’organizzazione, compresi i moderni ransomware. Inoltre occorre comprendere se fornisce le funzionalità per il ripristino moderno da attacchi ransomware, tra cui la scelta guidata dei punti di ripristino, convalida e ripristino secondo le necessità.
Altra considerazione riguarda la possibilità di capire se è economicamente conveniente e se è abbastanza versatile e scalabile da soddisfare le necessità in continua evoluzione dell’organizzazione.
Bisogna capire se è in grado di soddisfare in modo affidabile i requisiti di RTO, RPO e accordi sui livelli di servizio.
Ma occorre comprendere se è semplice da gestire e distribuire, se il testa non comporta interruzioni dell’attività e se comprende controlli dello stato frequenti (ogni 30 minuti o più).
Contributo editoriale sviluppato in collaborazione con VMware
@RIPRODUZIONE RISERVATA