电源侧信道攻击利用CPU功耗的数据相关变化来泄露机密信息。本文展示了在现代英特尔(和AMD)x86 CPU上,可以将电源侧信道攻击转化为时序攻击,而无需访问任何功耗测量接口,这源自于动态电压和频率调整(DVFS, Dynamic Voltage & Frequency Scaling)。在某些情况下,DVFS引起的CPU频率变化取决于毫秒级的当前功耗。这些变化可以被远程攻击者观察到,因为频率差异会转化为绝对时间差异。
频率侧信道从理论上来说比当今密码工程实践中考虑的软件侧信道更强,但由于其粗粒度导致很难被利用。然而,现在这一新信道对密码软件的安全构成了真正威胁。本研究首先对现代x86 CPU上的数据、功耗和频率之间的依赖关系进行了逆向工程,发现了一些细微差别,例如一个字中设置位的位置可以通过频率变化来区分。其次提出了一种针对(恒定时间实现)SIKE的新型选择密文攻击,通过远程时序将单个密钥位的猜测放大为成千上万次高功耗或低功耗操作,从而允许通过远程时序进行完整密钥提取。
功耗分析攻击几十年来一直被认为是侧信道信息泄露的一个主要源头。在历史上,这些攻击被用来从嵌入式设备(如智能卡)中使用物理探针泄露密码密钥。最近,功耗分析攻击也被证明可以通过软件功耗测量接口来利用。这些接口在许多现代通用处理器上都可用,已被滥用于网站指纹识别、恢复RSA密钥、破解KASLR,甚至恢复AES-NI密钥。幸运的是,基于软件的功耗分析攻击可以通过阻止(或限制)对功耗测量接口的访问来减轻并且容易检测。直到今天,这样的缓解策略将有效地减少攻击面至仅限于物理功耗分析,这在现代通用x86处理器的环境中是一个明显较小的威胁。
DVFS是一种常用的技术,它包括动态调整CPU频率以降低功耗(在低CPU负载时)以及确保系统在功耗和热量极限下保持稳定(高CPU负载)。在某些情况下,DVFS引起的CPU频率调整取决于毫秒级的当前功耗。因此,由于功耗与数据相关,CPU频率调整也是与数据相关的。此外,数据相关的频率调整可以被远程攻击者观察,而无需任何特殊权限。原因是CPU频率差异直接转化为执行时间差异(因为1赫兹=1秒内的1个周期)。这一发现的安全影响是重大的。它从根本上破坏了恒定时间编程,自1996年以来一直是抵抗时序攻击的基础防御措施。恒定时间编程的前提是通过编写一个只使用“safe”指令的程序,其延迟与数据值无关,程序的执行时间将是与数据无关。然而若是通过频率信道,即使仅使用安全指令,时序也会成为数据的函数。 尽管其理论上具有很大的威力,但如何构建实际的频率侧信道攻击并容易。这是因为DVFS更新取决于数百万CPU周期内的总功耗,只反映了粗粒度的程序行为。
本研究展示了频率侧信道对加密软件安全构成了真正的威胁,通过:
(i)在现代x86英特尔CPU上逆向工程的精确泄露模型,
(ii)展示一些加密原语能够将单个密钥位的猜测放大成数千次高功耗或低功耗操作,足以引发可测量的时序差异。
为了构建泄露模型,对现代x86英特尔CPU上正在计算的数据与功耗/频率之间的依赖关系进行了逆向工程。研究结果显示,功耗和CPU频率取决于数据的汉明权重(HW, Hamming weight)以及跨计算的数据的汉明距离(HD, Hamming distance),这两种影响在现代英特尔CPU上是不同且可累加的。此外,HW效应是非均匀的。也就是说,处理具有相同HW的数据会导致功耗/频率因数据值内个别1的位置而不同。因此,根据秘密进行不同位模式数据的计算可以导致功耗和频率取决于该秘密。
然后,本文描述了一种新的攻击,包括新的密码分析技术,针对恒定时间实现的SIKE(Supersingular Isogeny Key Encapsulation)。SIKE已经有十年的历史,被广泛研究的密钥封装机制。与NIST的后量子密码竞赛中的其他入围者不同,SIKE具有较短的密文和较短的公钥。
当攻击者提供一个经过特别制作的输入时,SIKE的解密算法会产生依赖密钥的单个位的异常值。这些值会导致算法卡住,并在剩下的解密过程中操作中间值,这些值在剩余的解密中也都是0。当这种情况发生时,处理器的功耗较低,运行频率较高,因此解密所需的绝对时间较短。这种时序信号非常稳定,以至于可以在网络中进行密钥提取,最后,还展示了频率侧信道也可以用来进行无需计时器的时序攻击,例如KASLR破解和隐蔽信道。
Intel P-States:在英特尔处理器中,动态电压和频率调整(DVFS)以P-states的粒度工作。P-states对应于不同的操作点(电压-频率对),以100 MHz频率递增。不同CPU型号的P-states数量各不相同。现代英特尔处理器提供两种控制P-states的机制,即SpeedStep和Speed Shift / Hardware Controlled Performance States (HWP)。使用SpeedStep,P-states由操作系统(OS)使用硬件协调反馈寄存器进行管理。使用HWP时,P-states完全由处理器进行管理,提高了整体响应性。HWP是在Skylake微架构中引入的。启用HWP时,操作系统只能向处理器的内部P-state选择逻辑提供提示,包括限制可用P-states的范围。否则,可用的P-states范围仅取决于活动内核的数量以及是否启用了“Turbo Boost”。本文的P-state命名约定遵循Linux中使用的约定。最低的P-state对应于支持的最低CPU频率。最高的P-state对应于处理器的“最大睿频”频率。然而,当禁用Turbo Boost时,最高可用的P-state是基本频率,将P-state和频率视为可以互换使用的术语。
P-state管理也与功耗管理相关。每个英特尔处理器都有一个热设计功耗(TDP),表示在持续工作负载下的稳定状态下的预期功耗。在最大睿频模式下,处理器可以超过其名义TDP。然而,如果CPU在最大睿频模式下达到一定的功耗和热量极限,硬件将自动减小频率以保持TDP在工作负载的持续时间内。
数据相关功耗:众所周知,处理器的功耗取决于正在处理的数据。数据和功耗之间的精确依赖关系取决于处理器的实现,但可以使用泄露模型进行近似。两种常用的泄露模型是汉明距离(HD)和汉明权重(HW)模型。在HD模型中,功耗取决于计算过程中数据中发生的1 → 0和0 → 1位转换的数量。在HW模型中,功耗仅取决于正在处理的数据中位为1的位数。
功耗侧信道攻击:功耗侧信道攻击针对加密系统首次在1998年公开讨论,引入了分析技术,利用功耗与数据依赖性来揭示秘密密钥。随后的工作展示了针对多个加密算法的功耗分析攻击,包括AES、DES、RSA和ElGamal。然而,所有这些攻击都针对智能卡,需要物理接触设备。最近,功耗侧信道攻击也被应用于更复杂的设备,如智能手机和PC。其中一些攻击仅依赖于软件功耗测量接口,这意味着它们不需要接近设备。然而,尽管其中一些工作使用了HW和HD泄露模型,但其中没有一个对现代英特尔x86 CPU上功耗和数据之间的依赖关系进行了系统逆向工程。此外,所有这些攻击都可以通过限制对这类功耗测量接口的访问来阻止。
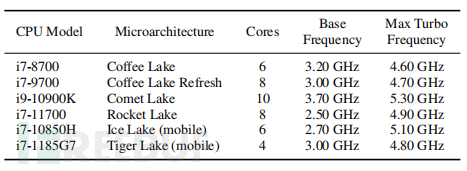
实验设置:在多台不同的计算机上运行实验。每台计算机的CPU特性都在下表中。所有计算机都运行Ubuntu,版本为18.04或20.04,内核为4.15或5.4,并安装了最新的微码补丁。除非另有说明,使用默认的系统配置,不限制P-states。为了监视CPU频率,使用了MSR_IA32_MPERF和MSR_IA32_APERF寄存器,就像Linux内核中所做的那样。为了监视功耗,使用RAPL接口的MSR。
A. 指令区分
作为分析的第一步,需要着手了解运行不同工作负载如何影响CPU的P-state选择逻辑。从stress-ng基准测试套件中选择了两个工作负载。第一个工作负载包括32位整数和浮点运算(int32float方法),而第二个工作负载仅包括32位整数运算(int32方法)。在所有内核上运行这两个基准测试,从空闲状态开始。在基准测试的执行过程中,每5毫秒采样一次CPU频率和(包域)功耗。
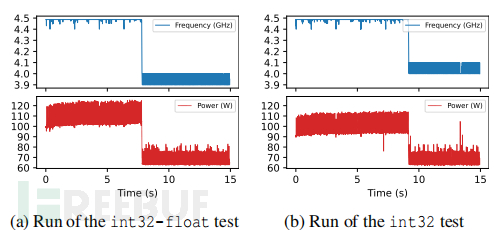
上图a显示了在i7-9700 CPU上进行int32float测试的结果。频率开始时为4.5 GHz,在CPU上,当所有内核都处于活动状态时,这是最高的P-state。在大约8秒的时间内,允许功耗超过TDP。然后,CPU降至较低的P-state,将功耗降至TDP(在CPU上为65W)。从那时开始,CPU保持在稳态,并在工作负载的持续时间内保持功率在TDP水平左右。示例中在稳态下,频率在两个P-states之间波动,分别对应3.9 GHz和4.0 GHz的频率。
上图b显示了int32压力测试的结果。这里,频率也从4.5 GHz开始,然后降至较低的P-state。但与图a相比,降低发生在10秒后,且降低后使用的P-states更高,分别对应4.0 GHz和4.1 GHz。这是因为int32测试的功耗较低。因此,处理器不仅可以更长时间地维持最高可用的P-state,而且可以在稳态下使用更高的P-states,而不会超过TDP。
以上结果的关键要点是:
(i)处理器可以在最大可用P-state上花费的时间,
(ii)稳态下P-states的分布都取决于CPU功耗。
由于CPU功耗取决于工作负载,根据传递属性,可以得出P-states也取决于工作负载。这意味着P-states的动态调整会泄露有关处理器上当前运行的工作负载的信息。
B. 数据区分
已经看到P-state信息泄露了有关正在执行的指令(即工作负载)的信息。现在探讨频率泄露信道是否可以泄露有关指令正在处理的数据的信息。问题是由于已知x86处理器上的功耗与数据相关,数据相关的功耗差异是否会在P-states的分布中显示出来?
为了回答这个问题,在执行相同的指令时,只改变输入寄存器的内容,同时监视CPU频率。例如使用shlx指令不断将源寄存器的位向左移动,并将结果写入循环中的不同目标寄存器,只变化源寄存器的内容。在所有内核上运行这个实验,并比较稳态下P-states的分布。下图a显示了将源寄存器的内容设置为16、32或48个1时的结果。在所有情况下,P-state在4.3 GHz和4.4 GHz之间波动。然而,汉明权重越大,频率停留在较低的P-state上的时间越长。从空闲状态开始,频率降至稳态的时间也会随着汉明权重的增加而减少(参见下图b)。汉明权重越大,频率降至稳态的速度越快。这是因为,处理具有较大汉明权重的数据消耗的功率比处理具有较低汉明权重的数据要多。
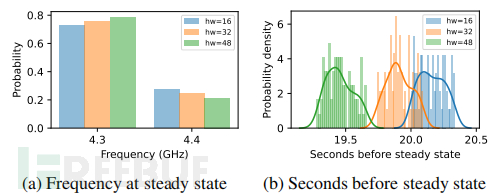
也使用其他指令获得类似的结果。例如,当运行or、xor、and、imul、add、sub以及处理从内存加载的数据时,观察到了数据相关的影响。唯一需要注意的是,对于某些指令,仅在所有内核上运行目标指令的功耗不足以导致P-state降至稳态。这些情况下在后台运行了额外的固定工作负载,以增加总功耗。
以上结果的关键是,P-states的动态调整会泄
如有侵权请联系:admin#unsafe.sh