
Loading...


16 min read

Starting on Aug 25, 2023, we started to notice some unusually big HTTP attacks hitting many of our customers. These attacks were detected and mitigated by our automated DDoS system. It was not long however, before they started to reach record breaking sizes — and eventually peaked just above 201 million requests per second. This was nearly 3x bigger than our previous biggest attack on record.
Concerning is the fact that the attacker was able to generate such an attack with a botnet of merely 20,000 machines. There are botnets today that are made up of hundreds of thousands or millions of machines. Given that the entire web typically sees only between 1–3 billion requests per second, it's not inconceivable that using this method could focus an entire web’s worth of requests on a small number of targets.
Detecting and Mitigating
This was a novel attack vector at an unprecedented scale, but Cloudflare's existing protections were largely able to absorb the brunt of the attacks. While initially we saw some impact to customer traffic — affecting roughly 1% of requests during the initial wave of attacks — today we’ve been able to refine our mitigation methods to stop the attack for any Cloudflare customer without it impacting our systems.
We noticed these attacks at the same time two other major industry players — Google and AWS — were seeing the same. We worked to harden Cloudflare’s systems to ensure that, today, all our customers are protected from this new DDoS attack method without any customer impact. We’ve also participated with Google and AWS in a coordinated disclosure of the attack to impacted vendors and critical infrastructure providers.
This attack was made possible by abusing some features of the HTTP/2 protocol and server implementation details (see CVE-2023-44487 for details). Because the attack abuses an underlying weakness in the HTTP/2 protocol, we believe any vendor that has implemented HTTP/2 will be subject to the attack. This included every modern web server. We, along with Google and AWS, have disclosed the attack method to web server vendors who we expect will implement patches. In the meantime, the best defense is using a DDoS mitigation service like Cloudflare’s in front of any web-facing web or API server.
This post dives into the details of the HTTP/2 protocol, the feature that attackers exploited to generate these massive attacks, and the mitigation strategies we took to ensure all our customers are protected. Our hope is that by publishing these details other impacted web servers and services will have the information they need to implement mitigation strategies. And, moreover, the HTTP/2 protocol standards team, as well as teams working on future web standards, can better design them to prevent such attacks.
RST attack details
HTTP is the application protocol that powers the Web. HTTP Semantics are common to all versions of HTTP — the overall architecture, terminology, and protocol aspects such as request and response messages, methods, status codes, header and trailer fields, message content, and much more. Each individual HTTP version defines how semantics are transformed into a "wire format" for exchange over the Internet. For example, a client has to serialize a request message into binary data and send it, then the server parses that back into a message it can process.
HTTP/1.1 uses a textual form of serialization. Request and response messages are exchanged as a stream of ASCII characters, sent over a reliable transport layer like TCP, using the following format (where CRLF means carriage-return and linefeed):
HTTP-message = start-line CRLF
*( field-line CRLF )
CRLF
[ message-body ]
For example, a very simple GET request for https://blog.cloudflare.com/ would look like this on the wire:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLF
And the response would look like:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLF<100 bytes of data>
This format frames messages on the wire, meaning that it is possible to use a single TCP connection to exchange multiple requests and responses. However, the format requires that each message is sent whole. Furthermore, in order to correctly correlate requests with responses, strict ordering is required; meaning that messages are exchanged serially and can not be multiplexed. Two GET requests, for https://blog.cloudflare.com/ and https://blog.cloudflare.com/page/2/, would be:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFGET /page/2 HTTP/1.1 CRLFHost: blog.cloudflare.comCRLF
With the responses:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLF<100 bytes of data>HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLF<100 bytes of data>
Web pages require more complicated HTTP interactions than these examples. When visiting the Cloudflare blog, your browser will load multiple scripts, styles and media assets. If you visit the front page using HTTP/1.1 and decide quickly to navigate to page 2, your browser can pick from two options. Either wait for all of the queued up responses for the page that you no longer want before page 2 can even start, or cancel in-flight requests by closing the TCP connection and opening a new connection. Neither of these is very practical. Browsers tend to work around these limitations by managing a pool of TCP connections (up to 6 per host) and implementing complex request dispatch logic over the pool.
HTTP/2 addresses many of the issues with HTTP/1.1. Each HTTP message is serialized into a set of HTTP/2 frames that have type, length, flags, stream identifier (ID) and payload. The stream ID makes it clear which bytes on the wire apply to which message, allowing safe multiplexing and concurrency. Streams are bidirectional. Clients send frames and servers reply with frames using the same ID.
In HTTP/2 our GET request for https://blog.cloudflare.com would be exchanged across stream ID 1, with the client sending one HEADERS frame, and the server responding with one HEADERS frame, followed by one or more DATA frames. Client requests always use odd-numbered stream IDs, so subsequent requests would use stream ID 3, 5, and so on. Responses can be served in any order, and frames from different streams can be interleaved.
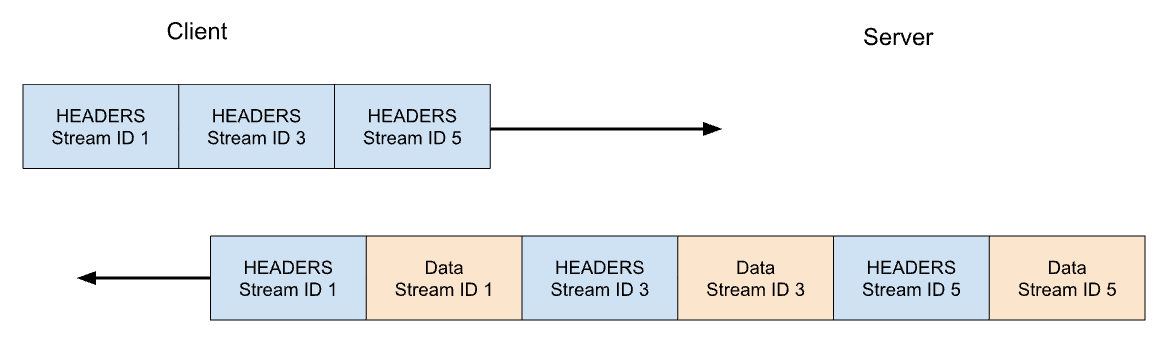
Stream multiplexing and concurrency are powerful features of HTTP/2. They enable more efficient usage of a single TCP connection. HTTP/2 optimizes resources fetching especially when coupled with prioritization. On the flip side, making it easy for clients to launch large amounts of parallel work can increase the peak demand for server resources when compared to HTTP/1.1. This is an obvious vector for denial-of-service.
In order to provide some guardrails, HTTP/2 provides a notion of maximum active concurrent streams. The SETTINGS_MAX_CONCURRENT_STREAMS parameter allows a server to advertise its limit of concurrency. For example, if the server states a limit of 100, then only 100 requests can be active at any time. If a client attempts to open a stream above this limit, it must be rejected by the server using a RST_STREAM frame. Stream rejection does not affect the other in-flight streams on the connection.
The true story is a little more complicated. Streams have a lifecycle. Below is a diagram of the HTTP/2 stream state machine. Client and server manage their own views of the state of a stream. HEADERS, DATA and RST_STREAM frames trigger transitions when they are sent or received. Although the views of the stream state are independent, they are synchronized.
HEADERS and DATA frames include an END_STREAM flag, that when set to the value 1 (true), can trigger a state transition.

Let's work through this with an example of a GET request that has no message content. The client sends the request as a HEADERS frame with the END_STREAM flag set to 1. The client first transitions the stream from idle to open state, then immediately transitions into half-closed state. The client half-closed state means that it can no longer send HEADERS or DATA, only WINDOW_UPDATE, PRIORITY or RST_STREAM frames. It can receive any frame however.
Once the server receives and parses the HEADERS frame, it transitions the stream state from idle to open and then half-closed, so it matches the client. The server half-closed state means it can send any frame but receive only WINDOW_UPDATE, PRIORITY or RST_STREAM frames.
The response to the GET contains message content, so the server sends HEADERS with END_STREAM flag set to 0, then DATA with END_STREAM flag set to 1. The DATA frame triggers the transition of the stream from half-closed to closed on the server. When the client receives it, it also transitions to closed. Once a stream is closed, no frames can be sent or received.
Applying this lifecycle back into the context of concurrency, HTTP/2 states:
Streams that are in the "open" state or in either of the "half-closed" states count toward the maximum number of streams that an endpoint is permitted to open. Streams in any of these three states count toward the limit advertised in the SETTINGS_MAX_CONCURRENT_STREAMS setting.
In theory, the concurrency limit is useful. However, there are practical factors that hamper its effectiveness— which we will cover later in the blog.
HTTP/2 request cancellation
Earlier, we talked about client cancellation of in-flight requests. HTTP/2 supports this in a much more efficient way than HTTP/1.1. Rather than needing to tear down the whole connection, a client can send a RST_STREAM frame for a single stream. This instructs the server to stop processing the request and to abort the response, which frees up server resources and avoids wasting bandwidth.
Let's consider our previous example of 3 requests. This time the client cancels the request on stream 1 after all of the HEADERS have been sent. The server parses this RST_STREAM frame before it is ready to serve the response and instead only responds to stream 3 and 5:
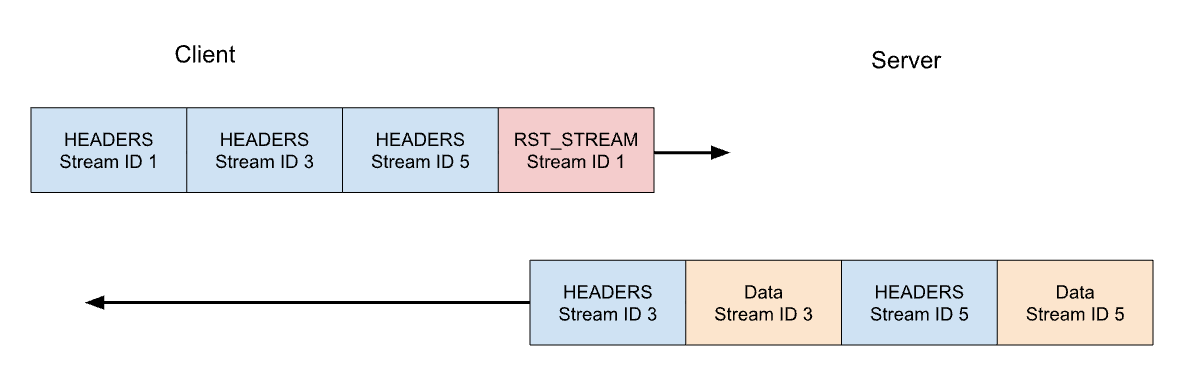
Request cancellation is a useful feature. For example, when scrolling a webpage with multiple images, a web browser can cancel images that fall outside the viewport, meaning that images entering it can load faster. HTTP/2 makes this behaviour a lot more efficient compared to HTTP/1.1.
A request stream that is canceled, rapidly transitions through the stream lifecycle. The client's HEADERS with END_STREAM flag set to 1 transitions the state from idle to open to half-closed, then RST_STREAM immediately causes a transition from half-closed to closed.

Recall that only streams that are in the open or half-closed state contribute to the stream concurrency limit. When a client cancels a stream, it instantly gets the ability to open another stream in its place and can send another request immediately. This is the crux of what makes CVE-2023-44487 work.
Rapid resets leading to denial of service
HTTP/2 request cancellation can be abused to rapidly reset an unbounded number of streams. When an HTTP/2 server is able to process client-sent RST_STREAM frames and tear down state quickly enough, such rapid resets do not cause a problem. Where issues start to crop up is when there is any kind of delay or lag in tidying up. The client can churn through so many requests that a backlog of work accumulates, resulting in excess consumption of resources on the server.
A common HTTP deployment architecture is to run an HTTP/2 proxy or load-balancer in front of other components. When a client request arrives it is quickly dispatched and the actual work is done as an asynchronous activity somewhere else. This allows the proxy to handle client traffic very efficiently. However, this separation of concerns can make it hard for the proxy to tidy up the in-process jobs. Therefore, these deployments are more likely to encounter issues from rapid resets.
When Cloudflare's reverse proxies process incoming HTTP/2 client traffic, they copy the data from the connection’s socket into a buffer and process that buffered data in order. As each request is read (HEADERS and DATA frames) it is dispatched to an upstream service. When RST_STREAM frames are read, the local state for the request is torn down and the upstream is notified that the request has been canceled. Rinse and repeat until the entire buffer is consumed. However this logic can be abused: when a malicious client started sending an enormous chain of requests and resets at the start of a connection, our servers would eagerly read them all and create stress on the upstream servers to the point of being unable to process any new incoming request.
Something that is important to highlight is that stream concurrency on its own cannot mitigate rapid reset. The client can churn requests to create high request rates no matter the server's chosen value of SETTINGS_MAX_CONCURRENT_STREAMS.
Rapid Reset dissected
Here's an example of rapid reset reproduced using a proof-of-concept client attempting to make a total of 1000 requests. I've used an off-the-shelf server without any mitigations; listening on port 443 in a test environment. The traffic is dissected using Wireshark and filtered to show only HTTP/2 traffic for clarity. Download the pcap to follow along.

It's a bit difficult to see, because there are a lot of frames. We can get a quick summary via Wireshark's Statistics > HTTP2 tool:
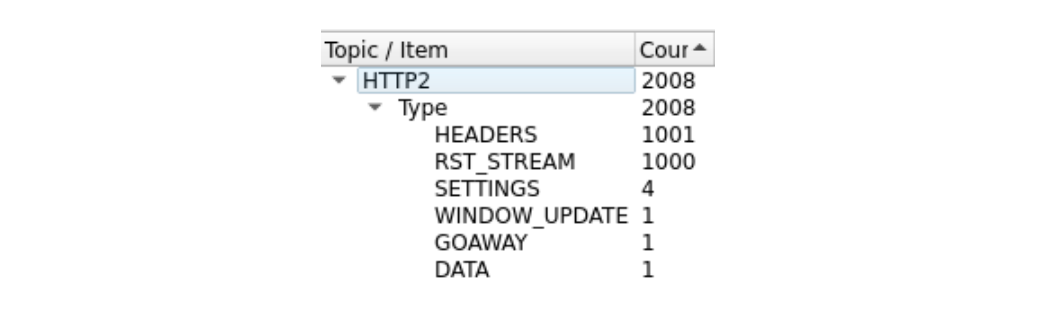
The first frame in this trace, in packet 14, is the server's SETTINGS frame, which advertises a maximum stream concurrency of 100. In packet 15, the client sends a few control frames and then starts making requests that are rapidly reset. The first HEADERS frame is 26 bytes long, all subsequent HEADERS are only 9 bytes. This size difference is due to a compression technology called HPACK. In total, packet 15 contains 525 requests, going up to stream 1051.
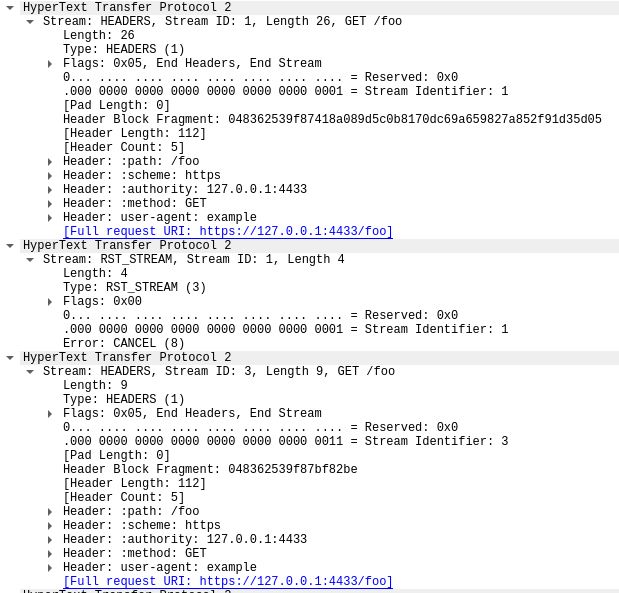
Interestingly, the RST_STREAM for stream 1051 doesn't fit in packet 15, so in packet 16 we see the server respond with a 404 response. Then in packet 17 the client does send the RST_STREAM, before moving on to sending the remaining 475 requests.
Note that although the server advertised 100 concurrent streams, both packets sent by the client sent a lot more HEADERS frames than that. The client did not have to wait for any return traffic from the server, it was only limited by the size of the packets it could send. No server RST_STREAM frames are seen in this trace, indicating that the server did not observe a concurrent stream violation.
Impact on customers
As mentioned above, as requests are canceled, upstream services are notified and can abort requests before wasting too many resources on it. This was the case with this attack, where most malicious requests were never forwarded to the origin servers. However, the sheer size of these attacks did cause some impact.
First, as the rate of incoming requests reached peaks never seen before, we had reports of increased levels of 502 errors seen by clients. This happened on our most impacted data centers as they were struggling to process all the requests. While our network is meant to deal with large attacks, this particular vulnerability exposed a weakness in our infrastructure. Let's dig a little deeper into the details, focusing on how incoming requests are handled when they hit one of our data centers:
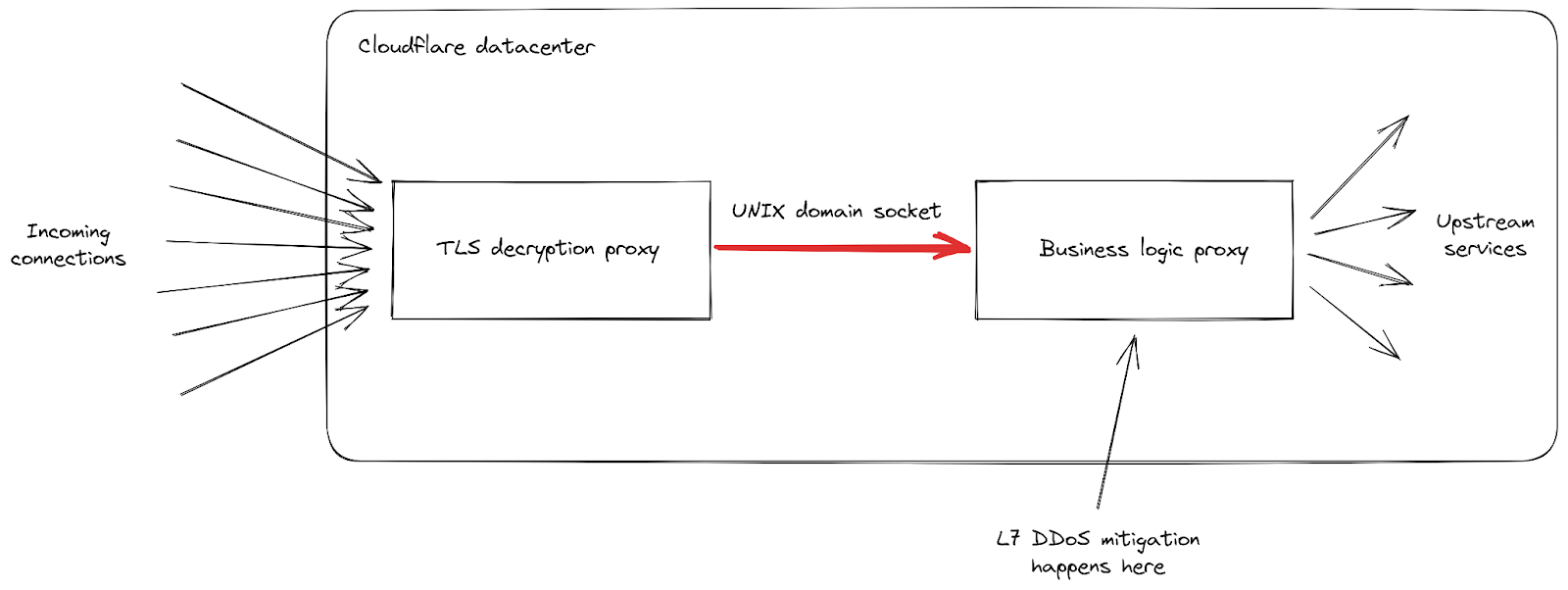
We can see that our infrastructure is composed of a chain of different proxy servers with different responsibilities. In particular, when a client connects to Cloudflare to send HTTPS traffic, it first hits our TLS decryption proxy: it decrypts TLS traffic, processes HTTP 1, 2 or 3 traffic, then forwards it to our "business logic" proxy. This one is responsible for loading all the settings for each customer, then routing the requests correctly to other upstream services — and more importantly in our case, it is also responsible for security features. This is where L7 attack mitigation is processed.
The problem with this attack vector is that it manages to send a lot of requests very quickly in every single connection. Each of them had to be forwarded to the business logic proxy before we had a chance to block it. As the request throughput became higher than our proxy capacity, the pipe connecting these two services reached its saturation level in some of our servers.
When this happens, the TLS proxy cannot connect anymore to its upstream proxy, this is why some clients saw a bare "502 Bad Gateway" error during the most serious attacks. It is important to note that, as of today, the logs used to create HTTP analytics are also emitted by our business logic proxy. The consequence of that is that these errors are not visible in the Cloudflare dashboard. Our internal dashboards show that about 1% of requests were impacted during the initial wave of attacks (before we implemented mitigations), with peaks at around 12% for a few seconds during the most serious one on August 29th. The following graph shows the ratio of these errors over a two hours while this was happening:

We worked to reduce this number dramatically in the following days, as detailed later on in this post. Both thanks to changes in our stack and to our mitigation that reduce the size of these attacks considerably, this number is today is effectively zero.

499 errors and the challenges for HTTP/2 stream concurrency
Another symptom reported by some customers is an increase in 499 errors. The reason for this is a bit different and is related to the maximum stream concurrency in a HTTP/2 connection detailed earlier in this post.
HTTP/2 settings are exchanged at the start of a connection using SETTINGS frames. In the absence of receiving an explicit parameter, default values apply. Once a client establishes an HTTP/2 connection, it can wait for a server's SETTINGS (slow) or it can assume the default values and start making requests (fast). For SETTINGS_MAX_CONCURRENT_STREAMS, the default is effectively unlimited (stream IDs use a 31-bit number space, and requests use odd numbers, so the actual limit is 1073741824). The specification recommends that a server offer no fewer than 100 streams. Clients are generally biased towards speed, so don't tend to wait for server settings, which creates a bit of a race condition. Clients are taking a gamble on what limit the server might pick; if they pick wrong the request will be rejected and will have to be retried. Gambling on 1073741824 streams is a bit silly. Instead, a lot of clients decide to limit themselves to issuing 100 concurrent streams, with the hope that servers followed the specification recommendation. Where servers pick something below 100, this client gamble fails and streams are reset.
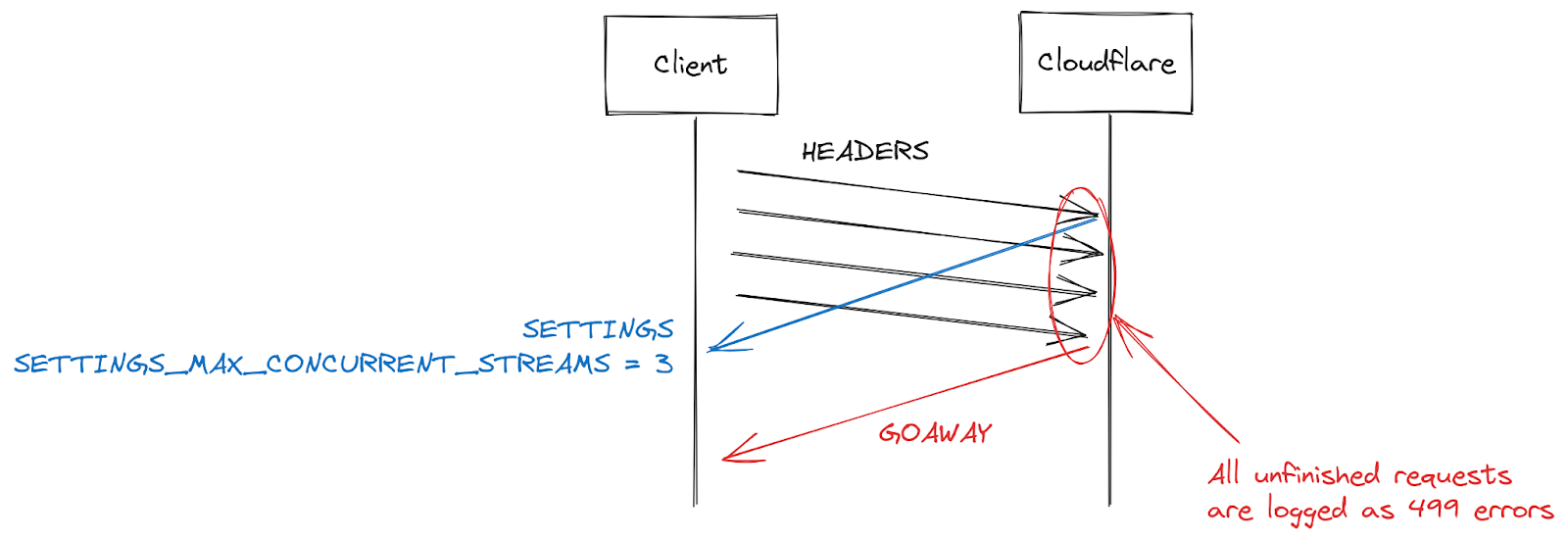
There are many reasons a server might reset a stream beyond concurrency limit overstepping. HTTP/2 is strict and requires a stream to be closed when there are parsing or logic errors. In 2019, Cloudflare developed several mitigations in response to HTTP/2 DoS vulnerabilities. Several of those vulnerabilities were caused by a client misbehaving, leading the server to reset a stream. A very effective strategy to clamp down on such clients is to count the number of server resets during a connection, and when that exceeds some threshold value, close the connection with a GOAWAY frame. Legitimate clients might make one or two mistakes in a connection and that is acceptable. A client that makes too many mistakes is probably either broken or malicious and closing the connection addresses both cases.
While responding to DoS attacks enabled by CVE-2023-44487, Cloudflare reduced maximum stream concurrency to 64. Before making this change, we were unaware that clients don't wait for SETTINGS and instead assume a concurrency of 100. Some web pages, such as an image gallery, do indeed cause a browser to send 100 requests immediately at the start of a connection. Unfortunately, the 36 streams above our limit all needed to be reset, which triggered our counting mitigations. This meant that we closed connections on legitimate clients, leading to a complete page load failure. As soon as we realized this interoperability issue, we changed the maximum stream concurrency to 100.
Actions from the Cloudflare side
In 2019 several DoS vulnerabilities were uncovered related to implementations of HTTP/2. Cloudflare developed and deployed a series of detections and mitigations in response. CVE-2023-44487 is a different manifestation of HTTP/2 vulnerability. However, to mitigate it we were able to extend the existing protections to monitor client-sent RST_STREAM frames and close connections when they are being used for abuse. Legitimate client uses for RST_STREAM are unaffected.
In addition to a direct fix, we have implemented several improvements to the server's HTTP/2 frame processing and request dispatch code. Furthermore, the business logic server has received improvements to queuing and scheduling that reduce unnecessary work and improve cancellation responsiveness. Together these lessen the impact of various potential abuse patterns as well as giving more room to the server to process requests before saturating.
Mitigate attacks earlier
Cloudflare already had systems in place to efficiently mitigate very large attacks with less expensive methods. One of them is named "IP Jail". For hyper volumetric attacks, this system collects the client IPs participating in the attack and stops them from connecting to the attacked property, either at the IP level, or in our TLS proxy. This system however needs a few seconds to be fully effective; during these precious seconds, the origins are already protected but our infrastructure still needs to absorb all HTTP requests. As this new botnet has effectively no ramp-up period, we need to be able to neutralize attacks before they can become a problem.
To achieve this we expanded the IP Jail system to protect our entire infrastructure: once an IP is "jailed", not only it is blocked from connecting to the attacked property, we also forbid the corresponding IPs from using HTTP/2 to any other domain on Cloudflare for some time. As such protocol abuses are not possible using HTTP/1.x, this limits the attacker's ability to run large attacks, while any legitimate client sharing the same IP would only see a very small performance decrease during that time. IP based mitigations are a very blunt tool — this is why we have to be extremely careful when using them at that scale and seek to avoid false positives as much as possible. Moreover, the lifespan of a given IP in a botnet is usually short so any long term mitigation is likely to do more harm than good. The following graph shows the churn of IPs in the attacks we witnessed:
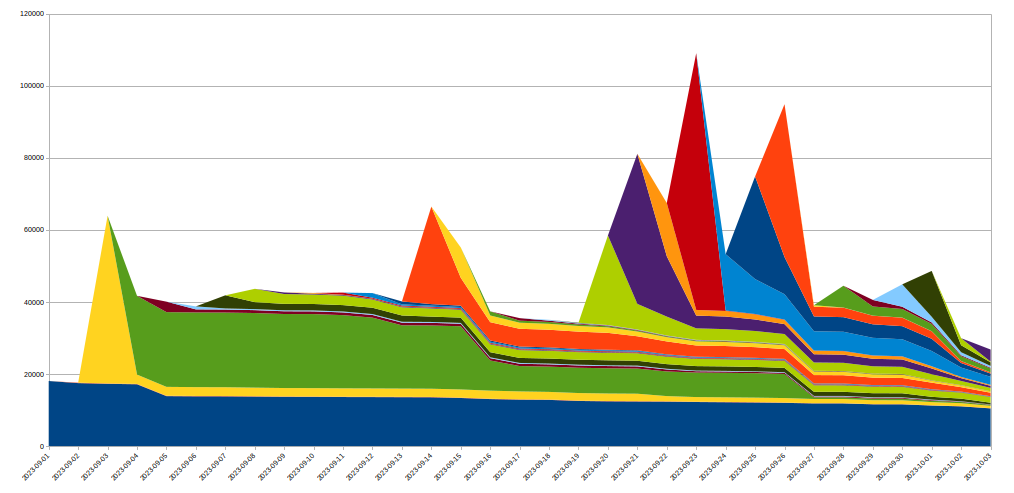
As we can see, many new IPs spotted on a given day disappear very quickly afterwards.
As all these actions happen in our TLS proxy at the beginning of our HTTPS pipeline, this saves considerable resources compared to our regular L7 mitigation system. This allowed us to weather these attacks much more smoothly and now the number of random 502 errors caused by these botnets is down to zero.
Observability improvements
Another front on which we are making change is observability. Returning errors to clients without being visible in customer analytics is unsatisfactory. Fortunately, a project has been underway to overhaul these systems since long before the recent attacks. It will eventually allow each service within our infrastructure to log its own data, instead of relying on our business logic proxy to consolidate and emit log data. This incident underscored the importance of this work, and we are redoubling our efforts.
We are also working on better connection-level logging, allowing us to spot such protocol abuses much more quickly to improve our DDoS mitigation capabilities.
Conclusion
While this was the latest record-breaking attack, we know it won’t be the last. As attacks continue to become more sophisticated, Cloudflare works relentlessly to proactively identify new threats — deploying countermeasures to our global network so that our millions of customers are immediately and automatically protected.
Cloudflare has provided free, unmetered and unlimited DDoS protection to all of our customers since 2017. In addition, we offer a range of additional security features to suit the needs of organizations of all sizes. Contact us if you’re unsure whether you’re protected or want to understand how you can be.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.