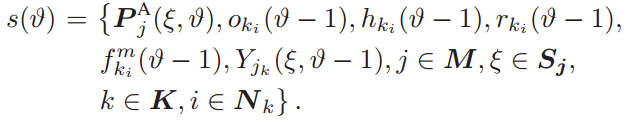
每周文章分享2023.9.25-2023.10.1标题: Environment-Aware AUV Trajectory Design and Resource Management for Mul 2023-9-30 05:50:6 Author: 网络与安全实验室(查看原文) 阅读量:47 收藏
每周文章分享
2023.9.25-2023.10.1
标题: Environment-Aware AUV Trajectory Design and Resource Management for Multi-Tier Underwater Computing
期刊: IEEE Journal on Selected Areas in Communications, vol. 41, no. 2, pp. 474-490, February 2023.
作者: Xiangwang Hou, Jingjing Wang, Tong Bai, Yansha Deng, Yong Ren , and Lajos Hanzo.
分享人: 河海大学——董奕伶
研究背景
水下物联网(IoUT)是海洋活动的重要组成部分。自主水下航行器(AUV)已被广泛用来采集IoUT设备感知的数据并将其转发到地面站,为了适应水下探测应用的不同要求,必须利用地面站和AUV以及水下探测设备的计算和通信以及存储资源,从而构建一个多层水下计算(MTUC)框架。此外,为了满足IoUT设备严格的能量约束,降低MTUC框架的运行成本,本文提出了一个联合环境感知AUV轨迹设计和资源管理问题,这是一个高维NP-Hard问题。为了应对这一挑战,本文首先将问题转化为马尔可夫决策过程(MDP),并借助异步优势演员-评论家(A3C)算法进行求解。
关键技术
为了满足 IoUT 应用的严格要求,本文通过合理分配地面站、AUV 和 IoUT 设备的计算、通信和存储资源,提出了一种 MTUC 框架。此外,在此框架下,本文设想了一个系统级优化问题,以最大化 MTUC 框架的利润为目的,依靠联合优化 AUV 的环境感知轨迹设计、计算卸载、数据缓存、通信和计算资源分配。由于所提出的问题是NP-hard且高维,本文将其转化为MDP并进一步采用A3C算法进行求解。
该方法的创新和贡献如下:
1)这是首次尝试将水面站、AUV和IoUT设备集成在一起形成MTUC框架,以提供按需水下计算服务,而不是简单地收集传感数据来满足高级IoUT应用的多样化要求。
2)考虑到以AUV为中心和以IoUT为中心的设计局限性,本文从经济学的角度构造了一个系统级的优化模型,通过集成环境感知轨迹设计、通信资源分配、计算卸载和数据缓存来最大化所收集的利润。
3)由于所描述的问题是高维NP-Hard问题,传统的方法不能很好地处理它。因此本文将其转化为马尔可夫决策过程(MDP),并采用异步优势演员-评论家(A3C)算法来求解它。
算法介绍
1. 系统模型
(1)网络模型
图1 MTUC的架构
图1是本文的 MTUC 架构,其中多个 AUV 与地面站进行永久巡航通信,为分布在多个设备组 (DG) 中的一组 IoUT 设备提供计算服务。每台AUV从地面站下方的原点出发,依次支援指定的DG。本文假设有一个地面站、M 个 AUV 和 K 个 DG。M 个 AUV 由集合 AUV = {AUV_1, AUV_2,..., AUV_M }表示,而 K 个 DG 由集合 DG = {DG_1, DG_2,..., DG_K}表示。假设DG_k中总共有N_k个IoUT设备,它们由集合ND_k = {n_k1,n_k2,...,n_kNk}表示。
(2)通信模型
UAC具有复杂的传播特性,其中多径效应、多普勒效应和环境噪声都会影响链路的质量。为简单起见,本文假设浅水声传播环境在空间和时间上都是均匀的。
噪声模型:海洋中的环境噪声可能是由气泡、船舶活动、表面风场等引起的。在通信频率f下,四种主要类型的噪声的功率谱密度(p.s.d )(以dB/Hz为单位)可以表示为
如果IoUT设备将其数据卸载到地面站,则有一个两阶段传输协议,包括IoUT设备卸载到AUV,AUV卸载到地面站阶段,可建模如下:
第一阶段传输:IoUT设备→AUV:UAC信道是直接视线(LOS)路径和非视线(NLOS)路径的集合的叠加,其中NLOS路径通常被水下表面、海底和水-空气表面反射。图2(a)描绘了IoUT设备和AUV之间的UAC的几何形状,其中m_u = (x_u^m,y_u^m,H),u∈{1,2,...,α}和n_u = (x_u^n,y_u^n,0),u∈{1,2,...,β}分别是海面和海底的反射点,H是水深。因此,LOS路径的欧几里德距离计算如下
第二阶段传输:AUV→地面站:如图2(b)所示,w_u = (x_u^w, y_u^w, 0), u∈{1,2,…,φ}为海底多径传播反射点。因此,LOS路径和NLOS路径的欧氏距离由式给出
图2 多径效应
2. 深度强化学习解
由于所描述的问题是非凸的且NP-Hard的,这对于传统的优化方法来说通常是难以解决的,因此,本文引入了一种高效的分布式深度强化学习方法A3C来求解P1。
(1)深度强化学习环境的建模
首先需要将P1转换为MDP,它由状态空间、动作空间、策略、状态转移矩阵函数和奖励函数组成。
1)状态空间:在每个episode ϑ,状态s(ϑ)∈S包括以下部分:
因此,episode ϑ的状态可以表示为
2)动作空间:在每个episode ϑ,智能体根据观察到的状态s(ϑ)选择一个动作a(ϑ)∈A,其中a(ϑ)由以下部分组成:
因此,episode ϑ的动作可以表示为
3)策略:设 π(a | s) = P (a | s) 表示策略函数,它是基于观察到的状态做出选择动作决策的概率分布。
4) 状态转移函数:令 P [s(ϑ + 1) | s(ϑ), a(ϑ)]是每个episode的转移概率,即在观察到的状态s(ϑ)执行动作a(ϑ)后进入状态s(ϑ + 1)的概率。
5)奖励函数:奖励函数是方程的目标。为了最大化MTUC框架的利润,其表示为
(2)基于A3C的联合优化算法
图3 基于A3C的联合优化算法架构
这里采用A3C来处理所提出的大规模优化问题。基于A3C的联合优化算法的体系结构如图3所示。与传统的深度强化学习方法相比,A3C可以实现高效的分布式异步学习。在基于A3C的联合优化算法中,智能体由一个全局网络和多个工作者组成。全局网络和工作者具有相同的网络结构,由两个神经网络组成,即参数为θ_A的策略网络(actor))和参数为θ_C的价值网络(critic)。当达到终端状态或最大迭代次数时,工作者通过分别与环境交互来并行学习,以计算新的梯度并将其发送到全局网络。全局网络不直接与环境交互,而是只负责用从工作者那里获取的梯度来更新全局网络参数,并定期将全局网络参数分发给每个工作者。
具体来说,在每个episode中,价值网络预测的估计状态值用V[s(ϑ);θ_C] 表示。智能体根据策略 π [a(ϑ) | s(ϑ) ]在当前状态s(ϑ) 执行动作a(ϑ),然后环境将改变到下一个状态s(ϑ + 1)并产生奖励r(ϑ)。A3C的状态值函数表示为
其中 Ψ 是折扣因子,表示未来奖励如何影响当前状态值。A3C采用K-步奖励来更新参数。
实验结果分析
1. 恶劣的水下环境对系统的影响
图4 环境不可知和环境感知轨迹设计之间的比较
图4显示了有环境意识和没有环境意识的轨迹设计之间的差异。观察每台AUV从原点出发,为指定的DG提供服务,完成一个周期后返回起始点进行充电。此外可以观察到,与图4(a)-4(d)中的AUV相比,图4(e)-4(h)中的AUV依靠环境意识可以选择没有涡流的最佳轨迹,可以避免涡流的额外能量消耗,为MTUC框架带来高额利润。尽管有时依赖环境意识的AUV会比没有环境意识的AUV选择更长的路径,但整个系统的利润仍然停留在全局最优。
图5 环境感知和环境不可知轨迹设计与AUV数量之间的利润比较
在图5中,本文显示了环境感知和环境不可知轨迹设计与AUV数量之间的利润比较,与图4中所示的结果相对应。观察到环境感知轨迹设计优于不可知轨迹设计。此外,随着AUV数量的增加,整个系统的收益也会增加,因为多个AUV的协作比单个AUV表现出更大的灵活性。
图6 利润与为不同数量的IoUT设备服务的AUV数量的关系
图 6 描绘了利润与服务不同数量 IoUT 设备的 AUV 数量的关系。观察到为给定数量的 IoUT 设备提供服务的 AUV 数量始终存在最佳解决方案。例如,对于300个IoUT设备,使用5个AUV提供服务可以获得最高的利润。此外可以从图 6 中观察到,如果所有其他条件保持不变,则增加设备数量会增加系统的效益。这样做的原因是,当设备数量增加时,将相同的能耗分配给AUV的运动可以支持更多的IoUT设备,从而获得更高的收入,进一步提高利润。
2. 不同资源配置方案对系统利润的影响
图7 不同任务卸载方案的收益与IoUT设备的数量之比
为了描述卸载方案对系统利润的影响,在图7中展示了不同任务卸载方案的利润。完全卸载方案是指所有IoUT设备选择将其任务卸载到地面工作站处理,而非卸载方案是指所有IoUT设备在本地处理其任务。其中,随机卸载方案是指每个设备随机选择是否将其计算任务卸载到地面工作站,而部分卸载方案是指指定一定比例的任务卸载到地面工作站,并留下一些任务在本地处理。非卸载方案虽然可以满足设备的要求,但由于IoUT设备的能量耗散难以充电,因此其所要支付的成本远远高于将任务卸载到MTUC框架处理的成本。IoUT设备也比可以连续充电的AUV更难充电。同样,地面站可能更容易充电。此外,当选择将一些任务卸载给MTUC时,所收集的利润显着增加。明确地说,由于该方案能够在有限的资源下寻找最优的卸载策略以实现利润最大化,因此始终优于其他卸载方案。
图8 不同计算和通信分配方案的收益与IoUT设备数量的关系
为了研究计算和通信资源配置对系统利润的影响,本文比较了图8中不同方案的利润。观察到,依赖平均带宽资源分配和平均计算资源分配的方案最差,因为它忽略了不同IoUT设备之间任务和资源状态的差异。相比之下,优化带宽资源分配和计算资源分配可以显着提高系统的利润。此外可以观察到,所提出的方案比所有其他单独优化单个资源的方案要好得多,这表明两种类型资源的配置都显着提高了系统的利润。
3. A3C算法的性能分析
图9 不同算法的利润
传统方法在处理 P1 时表现不佳,因为它通常是NP-hard的并且具有高维度。在图 9 中,本文比较了多种场景下解决该问题的最先进算法的性能,包括流行的遗传算法(GA)、粒子群优化(PSO)算法、演员-评论家 (AC) 算法、深度确定性策略梯度 (DDPG) 算法和本文的 A3C 算法。观察到启发式算法,即基于 GA 和 PSO 的优化策略,收敛性能较差。相比之下,深度强化学习算法,即基于AC、DDPG 和 A3C 的优化策略表现更好。原因在于深度强化学习算法更适合解决高维问题,这直接体现了神经网络强大的函数拟合能力。此外,A3C 算法比 DDPG 和基于 AC 的优化更好,因为它可以在相同的迭代次数内找到更好的解决方案。
图10 学习率对A3C收敛性能的影响
在深度强化学习中,超参数的设置至关重要,因为它会严重影响算法的性能。作为A3C中一个重要的超参数,学习率对收敛速度有很大的影响,但不能得到理论上的最优值。如果学习率设置得太低,则会减缓算法的收敛速度,增加训练时间。相比之下,如果学习速度过快,参数可能会在最优值两侧来回摆动,无法收敛。在图10中,本文研究了学习速度对A3C收敛性能的影响。可以观察到,具有自适应学习率的算法优于其他算法,它会根据训练过程逐步调整学习率。
总结
为了满足IoUT应用的严格要求,本文通过合理分配地面站、AUV和IoUT设备的计算、通信和存储资源,提出了一种MTUC框架。在此框架下,通过对AUV的环境感知轨迹设计、计算卸载、数据缓存、通信和计算资源分配进行联合优化,提出了系统级优化问题,以实现MTUC框架的利润最大化。由于所建立的问题是NP-hard 的,并且是高维的,本文将其转化为MDP,并进一步使用A3C算法进行求解。
— END —
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh