Early last week, Google released a new stable update for Chrome. The update included a single security fix that was reported by Apple's Security Engineering and Architecture (SEAR) team. The issue, CVE-2023-4863, was a heap buffer overflow in the WebP image library, and it had a familiar warning attached:
"Google is aware that an exploit for CVE-2023-4863 exists in the wild."
This means that someone, somewhere, had been caught using an exploit for this vulnerability. But who discovered the vulnerability and how was it being used? How does the vulnerability work? Why wasn't it discovered earlier? And what sort of impact does an exploit like this have?
There are still a lot of details that are missing, but this post attempts to explain what we know about the unusual circumstances of this bug, and provides a new technical analysis and proof-of-concept trigger for CVE-2023-4863 ("the WebP 0day").
This work was made possible by major technical contributions from @mistymntncop -- thank you!
Unraveling the Timeline
Immediately after the Chrome security update was released, experts began to speculate that there was a link between CVE-2023-4863 and an earlier CVE from Apple, CVE-2023-41064. The theory goes something like this.
Early in September (exact date unknown), Citizen Lab detected suspicious behavior on the iPhone of "an individual employed by a Washington DC-based civil society organization":
BLASTPASS: NSO Group iPhone Zero-Click, Zero-Day Exploit Captured in the Wild
They attributed the behavior to a "zero-click" exploit for iMessage being used to deploy NSO group's Pegasus spyware, and sent their technical findings to Apple. Apple responded swiftly, and on September 7 they released a security bulletin that featured two new CVEs from the attack Citizen Lab identified. On each CVE they note: "Apple is aware of a report that this issue may have been actively exploited."
Citizen Lab called this attack "BLASTPASS", since the attackers found a clever way to bypass the "BlastDoor" iMessage sandbox. We don't have the full technical details, but it looks like by bundling an image exploit in a PassKit attachment, the malicious image would be processed in a different, unsandboxed process. This corresponds to the first CVE that Apple released, CVE-2023-41061.
But you'd still need an image exploit to take advantage of this situation, and indeed, the second CVE that Apple released is CVE-2023-41064, a buffer overflow vulnerability in ImageIO. ImageIO is Apple's image parsing framework. It will take a sequence of bytes and attempt to match the bytes to a suitable image decoder. Several different formats are supported, and ImageIO has been an active area of security research. We don't have any technical details about CVE-2023-41064 yet, so we don't know which image format it affects.
But we do know that ImageIO recently began to support WebP files, and we know that on September 6 (one day before the iOS/macOS security bulletin), Apple's security team reported a WebP vulnerability to Chrome that was urgently patched (just 5 days after the initial report) and marked by Google as "exploited in the wild". Based on this, it seems likely that the BLASTPASS vulnerability and CVE-2023-4863 ("the WebP 0day") are the same bug.
The WebP 0day -- Technical Analysis
By cross-referencing the bug ID from Chrome's security bulletin with recent open source commits to the libwebp library code, it's possible to find the following patch:
Fix OOB write in BuildHuffmanTable
This patch was created on September 7 (one day after Apple's report), and corresponds to CVE-2023-4863. Based on an initial review of the patch, we learn the following:
- The vulnerability is in the "lossless compression" support for WebP, sometimes known as VP8L. A lossless image format can store and restore pixels with 100% accuracy, meaning that the image will be displayed with perfect accuracy. To achieve this, WebP uses an algorithm called Huffman coding.
- Although Huffman coding is conceptually based on a tree data structure, modern implementations have been optimized to use tables instead. The patch suggests that it was possible to overflow the Huffman table when decoding an untrusted image.
- Specifically, the vulnerable versions use memory allocations based on pre-calculated buffer sizes from a fixed table, and will then construct the Huffman tables directly into that allocation. The new version does a "first pass" construction that calculates the total size that the output table will require, but doesn't actually write the table to the buffer. If the total size is bigger than the pre-calculated buffer size, then a larger allocation is made.
This is a great start, but it's non-constructive. We want to be able to construct an example file that can actually trigger the overflow, and to do that we have to understand how this code is actually working and why the pre-calculated buffer sizes weren't sufficient.
Stepping back, what is the vulnerable code actually doing? When a WebP image is compressed in a lossless way, a frequency analysis of the input pixels is performed. The basic idea is that input values that occur more frequently can be assigned to a shorter sequence of output bits, and values that occur less frequently can be assigned to longer sequences of output bits. The real trick is that the output bits are cleverly chosen so that the decoder can always work out the length of that particular sequence -- i.e. it's always possible to disambiguate between a 2-bit code and a 3-bit code, and so on, and so the decoder always knows how many bits to consume.
To achieve this, the compressed image has to include all of the statistical information about frequencies and code assignments, so that the decoder can reproduce the same mapping between codes and values. As mentioned, internally webp uses a table for this (they call it the "huffman_table")... but the tables themselves can be quite large, and including them alongside the compressed image would make the file size increase. The solution is to use Huffman coding to compress the tables as well. It's turtles all the way down.
This means that there's a non-trivial amount of mental gymnastics involved in analyzing/triggering the bug. Based on a review of the patch, we can isolate the memory allocation that is the most likely candidate for being overflowed and come up with a plan.
We're trying to overflow the huffman_tables allocation in ReadHuffmanCodes (src/dec/vp8l_dec.c), and the idea is to use the VP8LBuildHuffmanTable/BuildHuffmanTable call in ReadHuffmanCode (not the one in ReadHuffmanCodeLengths) to shift the huffman_table pointer past the pre-calculated buffer size. To add to the complexity, there's actually 5 different segments of the Huffman table, each with a different alphabet size (e.g. number of possible output symbols for that particular segment of the table) -- and we'll probably have to craft all 5 of those to get close enough to the end of the buffer to cause an overflow.
At this point I had come up with a basic theory of how to proceed and started manually crafting a file that could reach this deep into the code, and around this time I started chatting with @mistymntncop. It turns out that they had also been attempting to reproduce this issue, and they had built harness code to create a well-formed WebP with arbitrary Huffman coding data ("code lengths"). I tried it out and it worked perfectly, we could pass arbitrary code_lengths array into the BuildHuffmanTable call that we were targeting. Brilliant.
Now the challenge was to find a group of code_lengths that would make BuildHuffmanTable exceed the pre-calculated buffer size. I started with some manual experimentation -- changing the code_lengths array to affect the internal histogram (essentially the count array in BuildHuffmanTable), and then watching what affect each of the 16 histogram entries had on total_size, the key variable that we needed to increase to a larger than expected value.
It quickly became clear that there was a complex interaction between the histogram's starting state, the tree statistics (num_open and num_nodes), and the "key" variable that tracks the starting location of the "ReplicateValue" operation that wrote entries into the output table that we're trying to overflow. It reminded me of watching the internal state of a cryptographic hash function, and without knowing a lot more about Huffman trees and WebP's specific implementation choices, I didn't feel confident that I'd be able to manually craft an input that would even be considered correct by BuildHuffmanTable, let alone one that makes BuildHuffmanTable return an unexpectedly large value.
My next idea was to brute-force a solution. I had noticed that the first 9 entries in the histogram (e.g. count[0] .. count[8], which are called the "root table") wouldn't have much influence on the total_size, but could influence the internal state for subsequent computations (such as by pushing the number of nodes too high). The final entries in the histogram (e.g. count[9] .. count[15], which are called the "second level tables") had a direct effect on the final total_size value. With this in mind I created a few different statistical distributions that generally kept the values of the root table low (typically summing to less than 8) and the second level table higher. This approach managed to find correct inputs, and some of them resulted in output tables that were quite large, but still less than the pre-calculated buffer sizes.
I decided I needed to understand how the pre-calculated sizes were derived. There are actually several different pre-calculated size buckets depending on the number of color cache bits that are specified. The buckets are defined in kTableSize, which includes a helpful description of the values and an invaluable tip: "All values computed for 8-bit first level lookup with Mark Adler's tool: https://github.com/madler/zlib/blob/v1.2.5/examples/enough.c"
The "enough" tool emits the histogram for the largest possible Huffman tree lookup table for any given alphabet size, root table size, and maximum code length. Using Mark Adler's tool, I could replicate the pre-calculated buffer sizes, and using @mistymntncop's tool I could verify that the specific code_lengths emitted by "enough" would 100% fill up the huffman_tables allocation. That's great, but the whole idea of a heap overflow would be to fill up the allocation to 101%...
I followed a dead-end here, which is that the "enough" tool only works for color_cache sizes up to 8-bits. How did they derive the values for 9-bit, 10-bit, or 11-bit caches, all of which are considered valid? Maybe they just guessed and these values are wrong? I think Google must have modified "enough" to work on larger alphabet sizes, because I managed to replicate their numbers by making some minor changes to "enough" (things like using the 128-bit integer scalar type compiler extension to be able to count the number of trees without overflow).
At this point there was a long process of angst. The "enough" tool is clear in its documentation that it calculates the maximum value for valid and complete codes. There must be some configuration of this input histogram that produces a tree that WebP considers to be valid and complete, but is actually incomplete/invalid in a way that produces a larger expansion than anticipated. The patch even hints in this direction, saying: "make sure that valid (but unoptimized because of unbalanced codes) streams are still decodable"
In the end I managed to convince myself that this wasn't possible by enumerating all of the possible valid trees in the smallest of the tables (a symbol size of 40), which also happened to be the last of the 5 tables we needed to fill. The purported maximum size for a symbol size of 40 with a root table of 8-bits and a maximum code length of 15 is 410. If you can generate anything bigger than 410, then you win. But none of the codes that BuildHuffmanTable would consider valid had a size bigger than 410 (and most of them were much smaller). It seems like the consistency check at the end of BuildHuffmanTable, e.g. checking that the number of output nodes is an expected value, was ensuring that the codes it accepted were in line with "enough" and the pre-calculated buffer sizes it gave.
But the BuildHuffmanTable function is writing values to the output table using the "ReplicateValue" operation mentioned earlier. What if we built 4 valid Huffman trees that resulted in 4 maximally sized output tables, and then supplied an invalid Huffman tree for the last table? Could we get ReplicateValue to write out-of-bounds from an invalid starting key prior to the final consistency check on the node count? The answer is: yes, we can.
Here's how to replicate the bug:
# checkout webp
$ git clone https://chromium.googlesource.com/webm/libwebp/ webp_test
$ cd webp_test/
# checkout vulnerable version
$ git checkout 7ba44f80f3b94fc0138db159afea770ef06532a0
# enable AddressSanitizer
$ sed -i 's/^EXTRA_FLAGS=.*/& -fsanitize=address/' makefile.unix
# build webp
$ make -f makefile.unix
$ cd examples/
# fetch mistymntncop's proof-of-concept code
$ wget https://raw.githubusercontent.com/mistymntncop/CVE-2023-4863/main/craft.c
# build and run proof-of-concept
$ gcc -o craft craft.c
$ ./craft bad.webp
# test trigger file
$ ./dwebp bad.webp -o test.png
=================================================================
==207551==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x626000002f28 at pc 0x56196a11635a bp 0x7ffd3e5cce90 sp 0x7ffd3e5cce80
WRITE of size 1 at 0x626000002f28 thread T0
#0 0x56196a116359 in BuildHuffmanTable (/home/isosceles/source/webp/webp_test/examples/dwebp+0xb6359)
#1 0x56196a1166e7 in VP8LBuildHuffmanTable (/home/isosceles/source/webp/webp_test/examples/dwebp+0xb66e7)
#2 0x56196a0956ff in ReadHuffmanCode (/home/isosceles/source/webp/webp_test/examples/dwebp+0x356ff)
#3 0x56196a09a2b5 in DecodeImageStream (/home/isosceles/source/webp/webp_test/examples/dwebp+0x3a2b5)
#4 0x56196a09e216 in VP8LDecodeHeader (/home/isosceles/source/webp/webp_test/examples/dwebp+0x3e216)
#5 0x56196a0a011b in DecodeInto (/home/isosceles/source/webp/webp_test/examples/dwebp+0x4011b)
#6 0x56196a0a2f06 in WebPDecode (/home/isosceles/source/webp/webp_test/examples/dwebp+0x42f06)
#7 0x56196a06c026 in main (/home/isosceles/source/webp/webp_test/examples/dwebp+0xc026)
#8 0x7f7ea8a8c082 in __libc_start_main ../csu/libc-start.c:308
#9 0x56196a06e09d in _start (/home/isosceles/source/webp/webp_test/examples/dwebp+0xe09d)
0x626000002f28 is located 0 bytes to the right of 11816-byte region [0x626000000100,0x626000002f28)
allocated by thread T0 here:
#0 0x7f7ea8f2d808 in __interceptor_malloc ../../../../src/libsanitizer/asan/asan_malloc_linux.cc:144
#1 0x56196a09a0eb in DecodeImageStream (/home/isosceles/source/webp/webp_test/examples/dwebp+0x3a0eb)
SUMMARY: AddressSanitizer: heap-buffer-overflow (/home/isosceles/source/webp/webp_test/examples/dwebp+0xb6359) in BuildHuffmanTable
...In practice there are many such inputs that will overflow huffman_tables. I've found code lengths that result in writes as far as 400 bytes past the end of the huffman_tables allocation. Even with only partial control of the value being written, it definitely looks exploitable. To exploit this issue you would likely need to use the color cache bits (or num_htree_groups) to get a huffman_tables allocation that is roughly page aligned, but that shouldn't be a problem. It may be that there are other ways of causing an OOB write on the huffman_tables allocation, but this method looks like an acceptable approach.
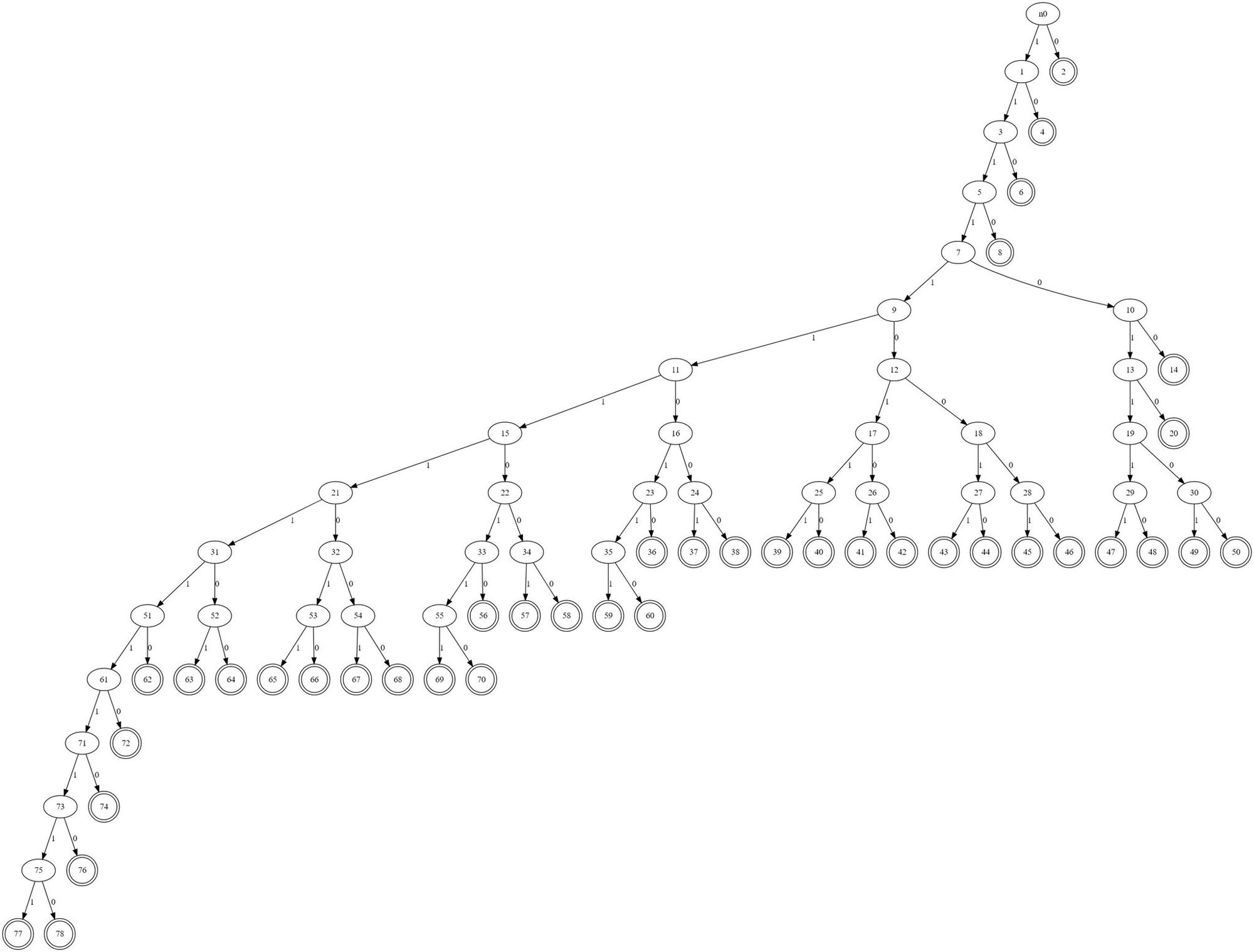
The invalid input itself is quite unusual -- mistymntncop provided the following visualization of the Huffman tree it creates using a tool they wrote to assist in this analysis:
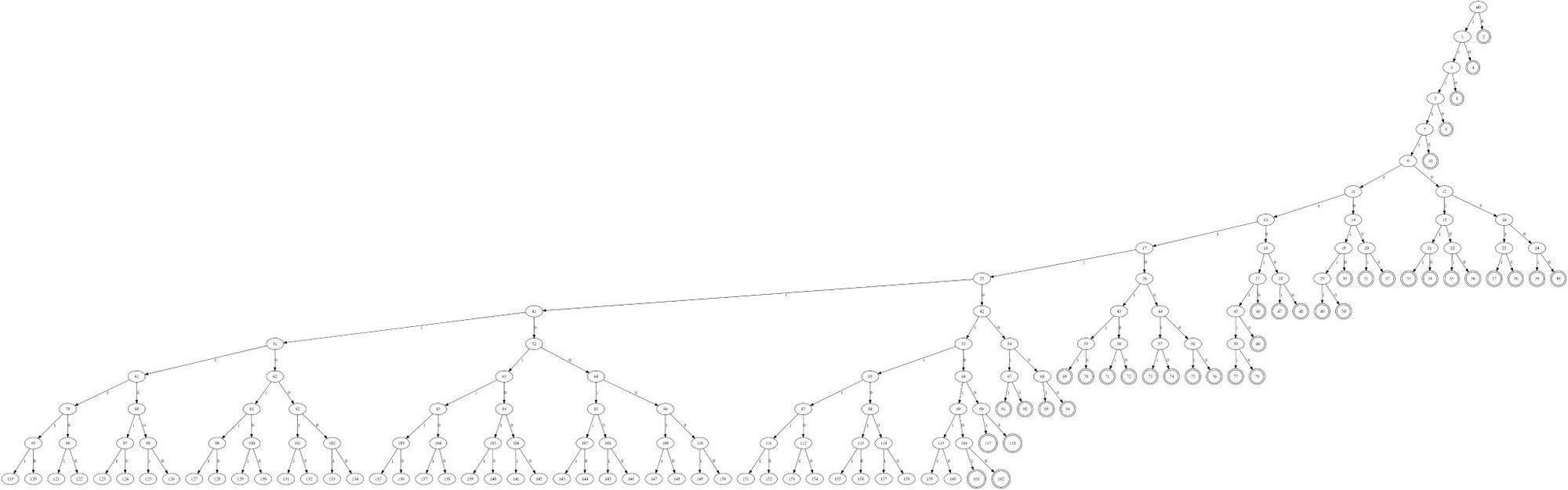
If you zoom in, you can see that the tree is partially unbalanced, and that a section of the unbalanced branch has a large number of internal nodes with no children in them at all. This structure results in a "key" index that a valid tree would never be able to reach. Here's what a valid tree looks like:
As for the patch, it seems to work almost by accident. As mentioned earlier, the patched version does a first pass with BuildHuffmanTable to calculate the total size required. In practice, this issue is patched because BuildHuffmanTable will fail (return 0) for all of the invalid inputs that would otherwise have resulted in an out-of-bounds write, and since the first pass is explicitly not writing to the table, it doesn't matter that the invalid tree is partially processed. In other words, I thought the patch was dynamically increasing the size of the buffer as needed to prevent heap overflow, but it's actually just denying the inputs that would cause a heap overflow instead. It's definitely hard to reason about, but I searched for "valid and complete" codes that would still trigger this overflow, and I couldn't find any. So it looks like the patch should be sufficient.
Early Discovery?
Immediately after Chrome's security update, there was some discussion about fuzzing. A binary file format implemented by a C code library is an ideal target for fuzzing -- so why hadn't this bug been found earlier? Had the library not been fuzzed enough? Or had it not been fuzzed right?
Google's OSS-Fuzz project has fuzzed hundreds of open source libraries for many years now, including libwebp and many other image decoding libraries. It's possible to look in full detail at the code coverage for OSS-Fuzz projects, and it's clear that lossless support for WebP was being fuzzed extensively:
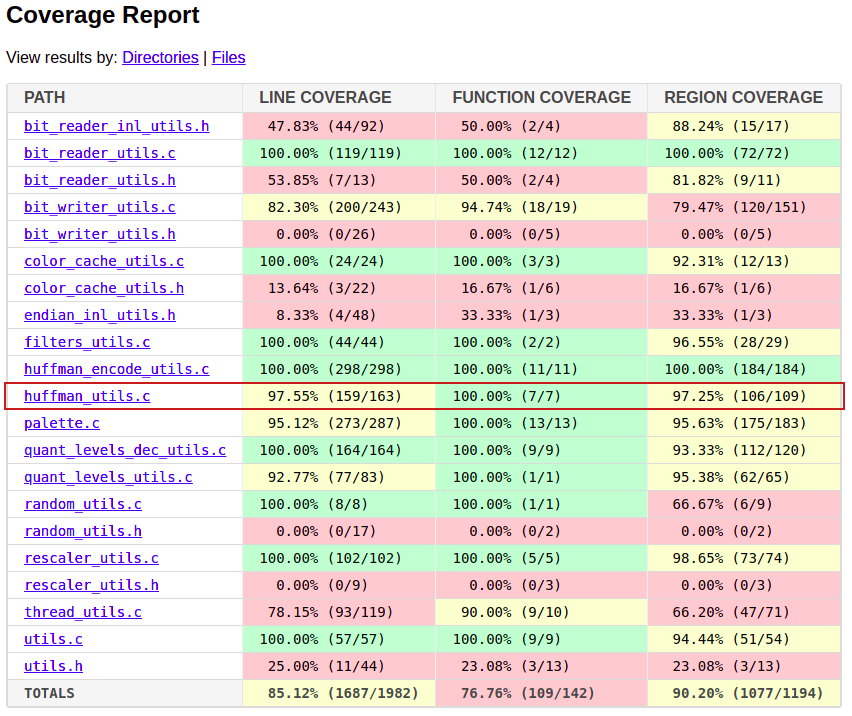
The problem, we now know, is that this format is incredibly complex and fragile, and the preconditions to trigger this issue are immense. Out of billions of possibilities, we have to construct a sequence of 4 valid Huffman tables that are maximally sized for two different alphabet sizes (280 and 256) before constructing a very specific type of invalid Huffman table for a third alphabet size (40). If a single bit is wrong at any stage, the image decoder throws an error and nothing bad happens.
In fact one of the first things that Google did after the WebP 0day was fixed was to release a new fuzzer specifically for the Huffman routines in WebP. I tried running this fuzzer for a bit (with a bit of backporting required due to API changes) and it predictably did not find CVE-2023-4863.
Perhaps I'm wrong and some of the newer techniques involving symbolic execution (like Quarkslab's TritonDSE) would be able to solve this -- but standard approaches based on bitflip mutations with a code-coverage feedback loop, and even slightly more sophisticated approaches like CmpLog (input-to-state), would not be able to navigate through all of these intermediary steps to reach this extremely pessimal state.
It's interesting to contrast this bug with an earlier vulnerability, the Load_SBit_Png bug in FreeType, which was also discovered "in the wild" in an advanced 0day exploit. It's similar in the sense of being a heap overflow in a common library for a binary file format (for fonts in this instance) written in C, it's similar that it affected Chrome, and it's similar in the sense that FreeType had been heavily fuzzed in the months and years leading up to this attack. The difference was that the Load_SBit_Png bug wasn't found during fuzzing due to a lack of adequate harnessing, rather than some specific constraint of the vulnerability that made it difficult to fuzz. If the fuzzing harnesses had been updated earlier to better reflect the APIs usage, the Load_SBit_Png bug would have been discovered with fuzzing.
That's not the case for the WebP 0day (CVE-2023-4863) -- unless, perhaps, you got incredibly lucky by having a file in your fuzzing corpus that was already extremely close to the bug and your fuzzer was very well calibrated in terms of its mutation rates.
In practice, I suspect this bug was discovered through manual code review. In reviewing the code, you would see the huffman_tables allocation being made during header parsing of a VP8L file, so naturally you would look to see how it's used. You would then try to rationalize the lack of bounds checks on the huffman_tables allocation, and if you're persistent enough, you would progressively go deeper and deeper into the problem before realizing that the code was subtly broken. I suspect that most code auditors aren't that persistent though -- this Huffman code stuff is mind bending -- so I'm impressed.
What's The Big Deal
There's some good news, and some bad news.
✓ The good news is that the team at Citizen Lab has, once again, done an amazing job of catching a top tier exploit being used in the wild. They have cultivated a lot of trust with the organizations and individuals that are most likely to be harmed by exploits. It's very impressive.
✗ The bad news is that exploits like this continue to have societal ramifications, and we can only guess how bad the situation really is. The truth is that nobody knows for sure, even the people with exploits.
✓ The good news is that Apple and Chrome did an amazing job at responding to this issue with the urgency that it deserves. It looks like both groups pushed out an update to their billions of users in just a number of days. That's an impressive feat, it takes an incredible effort and coordination across threat analysis, security engineering, software engineering, product management, and testing teams to make this even remotely possible.
✗ The bad news is that Android is still likely affected. Similar to Apple's ImageIO, Android has a facility called the BitmapFactory that handles image decoding, and of course libwebp is supported. As of today, Android hasn't released a security bulletin that includes a fix for CVE-2023-4863 -- although the fix has been merged into AOSP. To put this in context: if this bug does affect Android, then it could potentially be turned into a remote exploit for apps like Signal and WhatsApp. I'd expect it to be fixed in the October bulletin.
✓ The good news is that the bug seems to be patched correctly in the upstream libwebp, and that patch is making its way to everywhere it should go.
✗ The bad news is that libwebp is used in a lot of places, and it could be a while until the patch reaches saturation. Also, the code is still very difficult to reason about, and we can't rely on fuzzers to find any other bugs that are lurking here.
Final Thoughts
The WebP 0day (CVE-2023-4863) is a subtle but powerful vulnerability in a widely used open source library that is highly exposed to attacker inputs. It's both very difficult to fuzz, and very difficult to manually trigger -- but the prize is an exploitable heap overflow that works on multiple browsers, operating systems, and applications. It's likely that CVE-2023-4863 is the same vulnerability used in the BLASTPASS attacks.
I started this technical analysis shortly after releasing last week's blog post on Phineas Fisher, which means I was several days late to the party. In practice it took about 3 full work days worth of work (with a lot of additional help from @mistymntncop) to figure out the bug and build a reproducing testcase.
The lack of available technical information from the vendors here made verification challenging, and it's questionable who this really benefits. Attackers are clearly highly motivated to track and exploit N-day vulnerabilities, and the lack of technical details being released won't significantly slow them down. On the other hand, very few defenders are resourced to be able to perform the type of technical analysis I've shared today. It's counter-intuitive, but withholding basic technical details about how these attacks are working in an asymmetry that mostly benefits attackers -- you quickly end up in a situation where attackers have access to insights about the vulnerability/exploit that defenders don't have.
This bug also shows that we have an over-reliance on fuzzing for security assurance of complex parser code. Fuzzing is great, but we know that there are many serious security issues that aren't easy to fuzz. For sensitive attack surfaces like image decoding (zero-click remote exploit attack surface), there needs to 1) be a bigger investment in proactive source code reviews, and 2) a renewed focus on ensuring these parsers are adequately sandboxed.
Finally, thanks again to @mistymntncop for both their encouragement and huge technical contributions to this post.
如有侵权请联系:admin#unsafe.sh