翻译主题:这是一篇关于编写内存错误漏洞的利用程序时,需要了解堆分配器的内部结构的文章,深入研究了Android libc分配器之一:jemalloc 'new'(jemalloc 5及以上版本)。
在编写一个利用内存破坏漏洞的程序时,通常需要了解堆分配器的内部结构才可以根据需要构造堆结构。这篇文章将就安卓中libc分配器其中之一的jemalloc 'new’来深入分析。scudo是最新引入的的分配器,虽然jemalloc 'new'被广泛使用,但是并没有很好的描述和相关记录。
介绍:
Jemalloc 'new',是一个被引入到安卓10系统中libc的堆分配器,它虽然与jemalloc有相同的名称和部分相同的功能,但是后端部分却有很多的不同之处。现在没有很多公开的主题研究,此外,尽管在最新的安卓11系统中引入了scudo分配器,但是大量的设备使用的内存分配器仍然是jemalloc 'new',包括三星的 Galaxy S23。
这篇博客主要描述关于新的jemalloc的概念和老的jemalloc的不同之处。新的jemalloc是指Jemalloc版本大于等于5的,老的jemalloc是指版本小于5的。

如何知道设备是否使用了新的jemalloc
安卓版本的版本不是同步更新的,在不同的设备上存在多种版本。甚至在两个设备上使用的同一个安卓版本,它们也可能有不同的libc分配器。例如,在谷歌 Pixel 4a 5G版本上使用的安卓13使用scudo作为内存分配器,但是在三星的Galaxy S23上的安卓13使用的却是新的jemalloc内存分配器。
最简单的查看方法是使用命令行查看libc中je_符号开头的数,如果发现使用下面的命令行数字超过100,那么使用的内存分配器是jemalloc(新的或旧的不确定)。如果安卓的版本非常新,那么很有可能使用的是新的jemalloc,而不是旧版本的。
$ readelf -s libc.so | grep je_ | wc -l 292
为了确保正确,找到富豪中包含的的extent,如果是老版本的jemalloc会返回大概10左右,二jemalloc 'new'大概会返回100左右。
$ readelf -s libc.so | grep extent | wc -l 81
概述
新版本Jemalloc涉及几个重要的主题。
- arena (
arena_t):跟踪分配的主要结构 - extent (
extent_t): 虚拟内存段 - region: 小额定位
- slab: 包含相同大小的区域的范围,底层结构是
extent_t - bin (
bin_t): 特定大小和类别堆的extens/slab - tcache (
tcache_t): 所给定线程最近分配的缓存
与scudo和dlmalloc相反,元数据不会内联在malloc()返回的地址之前,他们存储在内存中各个不同的位置。
另一个特别需要注意是缺乏了内存取消映射功能,默认情况下,映射范围将保留到进程结束。(除非opt_retain被设置为false)。
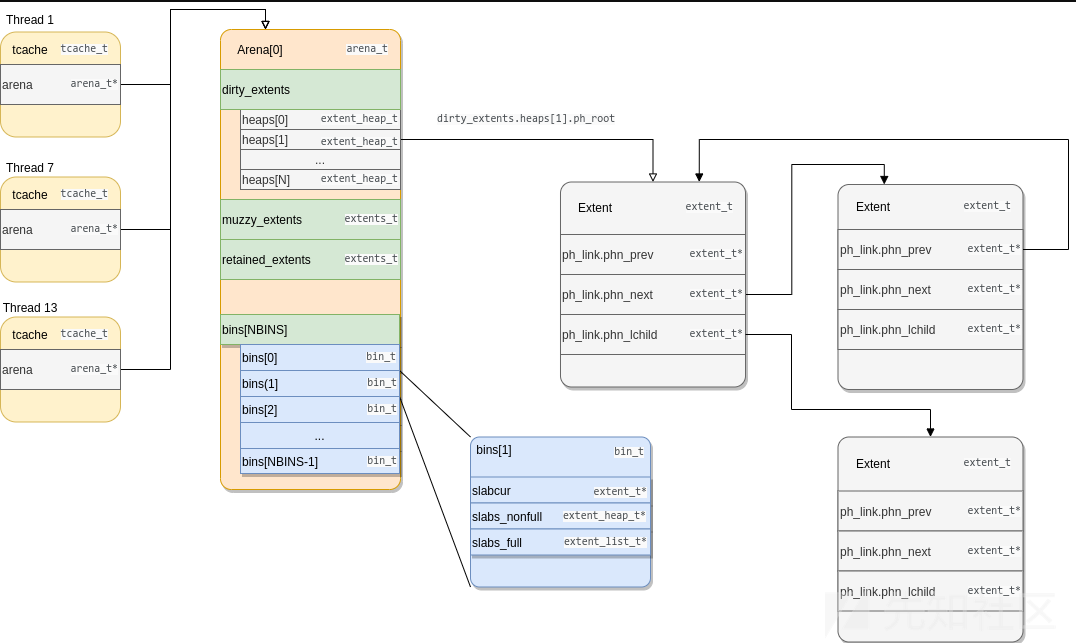
下面这张图是Jemalloc设计的主要结构。
主要结构
Arena结构
Areana结构可以独立管理部分内存以减少并发锁。在安卓中,有2个arenas被使用。每一个线程都被分配给两个arena中的一个。例如,重用一个线程到另一个线程的分配,例如利用释放后攻击,这要求两个线程共享同一块arena。涉及的structarena_s/arena_t结构可以在include/jemalloc/internal/arena_structs_b.h.中找到。
arenas维护已分配的、空闲的、缓存内存块的列表,在jemalloc中,这些基本的chunks块被称为extens,同时它们可以作为一个整体用于大的分配,也可以被用于分配为小的区域。
可用的空间(即空闲空间)extents分布在3个堆上:
dirty: 释放的空间muzzy: 脏的空间retained: 模糊堆中保留的空间这些堆按照从最近释放(脏堆)到最久释放(保留堆)的顺序存储空间,当发生衰减时,空间extents的位置从一个堆转移到下一个堆。
注意:如果全局变量
opt_retain被设置为1,默认下是这种情况,当保留堆中发生衰减时,空间仍会保留在该堆中,且永远不会被取消映射。因此,默认情况下,从进程内存中不会取消映射已映射过的空间。
// include/jemalloc/internal/arena_structs_b.h struct arena_s { // [...] /* * 这些是之前分配的空间块的集合。在分配空间块时,会尝试重用地址空间,这时就会使用这些已分配的空间块集合。 * * Synchronization: internal. */ extents_t extents_dirty; extents_t extents_muzzy; extents_t extents_retained; // [...] }
extents_t 结构体在其堆中按尺寸类别跟踪空闲的空间块。完整的空间块列表也可以通过 lru 字段访问,它是一个简单的双向链表。而 bitmap 字段用于确定哪些堆是非空的。
// include/jemalloc/internal/extent_structs.h struct extents_s { // [...] /* * *量化每个尺寸类别大小的堆 * Synchronization: mtx. */ extent_heap_t heaps[NPSIZES+1]; /* * Bitmap for which set bits correspond to non-empty heaps. *设置位对应给非空堆的bitmap * Synchronization: mtx. */ bitmap_t bitmap[BITMAP_GROUPS(NPSIZES+1)]; /* * LRU of all extents in heaps. *堆中各种LRU * Synchronization: mtx. */ extent_list_t lru; // [...] };
Arenas还按尺寸类别在堆中跟踪具有空闲区域的slab块。在安卓64位处理中,NBINS这个数字是36。
// include/jemalloc/internal/arena_structs_b.h
struct arena_s {
// [...]
/*
* bins被用来存储堆中的空闲区域.
*
* Synchronization: internal.
*/
bin_t bins[NBINS];
// [...]
}对于每个尺寸类别都有一个bin,这些bin_t字段包含具有空闲区域(小分配的上下文也叫做slab)的空间块,同时还包含一个完整的slab块的列表。
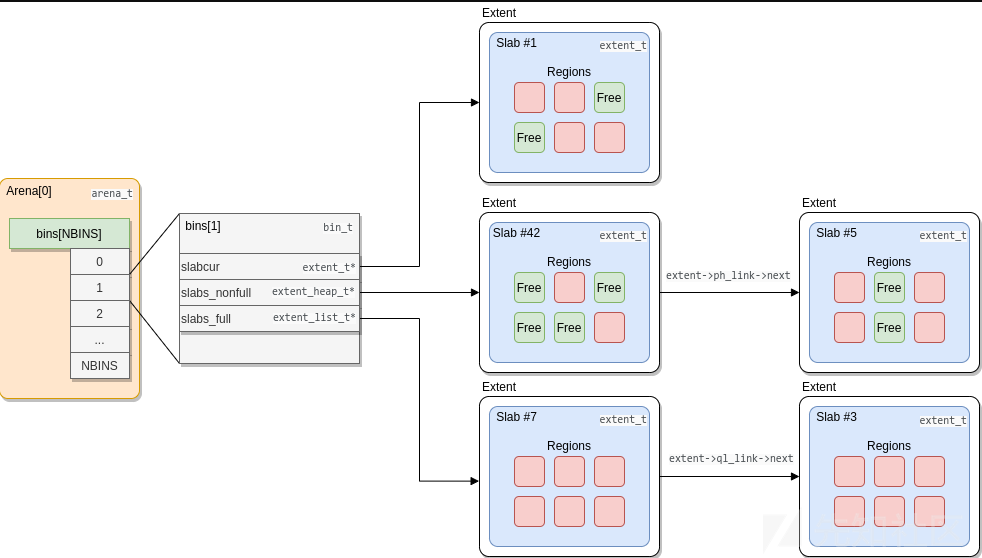
// include/jemalloc/internal/bin.h typedef struct bin_s bin_t; struct bin_s { // [...] /* *当前用于为此尺寸类别的分配提供服务的slab块。slabcur与slabs_{nonfull,full}无关;每当重新分配slabcur时,前一个slab块必须被释放或插入到slabs_{nonfull,full}中。 */ extent_t *slabcur; /* * 非满slab块的堆,该堆用于确保新的分配来自在内存中最旧/最低的非满slab块。 */ extent_heap_t slabs_nonfull; /* 用于跟踪满slab块的列表。 */ extent_list_t slabs_full; // [...] };
slabcur字段保存了最近一次使用的包含空闲区域的slab块。这个字段被jemalloc用于加速小分配。如果slabcur中没有更多的空闲区域,该slab块将被插入到slabs_full列表中,然后从slabs_nonfull中选择另一个包含空闲区域的slab块来取代它。
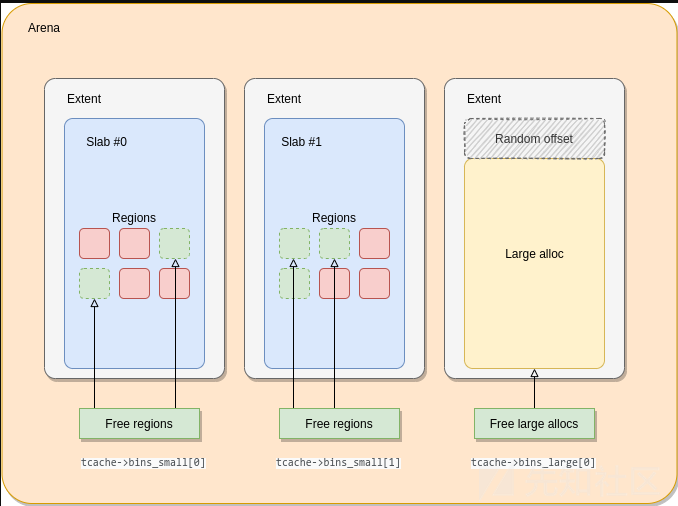
无处不在的EXTENTS扩展
关于新版的jemalloc与老版的jemalloc的主要区别是用哦extents来替代了chunks的概念。所有的分配都由extents范围支持,甚至包括jemalloc的元数据,有关更多jemalloc的信息,可以查看这篇文章:https://blog.nsogroup.com/a-tale-of-two-mallocs-on-android-libc-allocators-part-2-jemalloc/
在Android系统上,jemalloc的“old”chunks具有固定的大小为2MB,而new extents的大小可以变化,但始终是页大小(4096字节)的倍数。内存预留是通过在pages_map中调用mmap完成的。新创建的空间范围被分配一个序列号(上一个空间范围的序列号 + 1)。根据jemalloc的需要,可以讲这些映射的空间范围合并或者拆分。在拆分时,被拆分的自范围会继承父区的序列号。在合并的时候,会保留最小的序列号。当两个范围块在内存中连续且属于同一个区域arena时,才可以合并它们。
所有创建的空间块的引用都被保存在名为extents_rtree的全局基数树(radix tree)中,其类型为rtree_t。这个树主要在释放内存时使用,用于查找与正在释放的指针对应的空间块。在释放内存时,jemalloc会使用extents_rtree来找到相应的空间范围,并进行相应的处理。这样可以高效地管理内存的分配和释放。
- 小分配(<= 0x3800字节):在这种情况下,空间范围被称为slab,并包含多个相同大小的区域(区域数量取决于尺寸类别)。
- 大分配(> 0x3800字节):空间范围包含单个分配。
// include/jemalloc/internal/extent_structs.h struct extent_s { uint64_t e_bits; // extents范围的元数据,序列号 ... void *e_addr; // 实际被映射的指针 /* * 用于多种列表: * - bin_t的slabs_full * - extents_t的LRU * - 临时存储的dirty extents * - arena的大型分配 */ ql_elm(extent_t) ql_link; /* * 链接用于每个尺寸类别按照序列号/地址排序的堆,以及extent_avail(空间块可用性链表)。 */ phn(extent_t) ph_link; union { /* 小区域slab元数据。 */ arena_slab_data_t e_slab_data; // [...] }; }
下面是比较注意的字段:
e_bits:extent元数据e_addr:指向实际映射内存的指针ql_link和ph_link:extents可以存储在列表和堆中,ql_link包含当前extent的列表点,ph_link包含堆节点。e_slab_data: 如果空间块是slab,则该字段包含slab元数据(主要是一个位图,描述该slab中的空闲/已分配区域)。
注意:
为了简单和易读,在这些图示中,数据被定义在extent_t内部。元数据(
extent_t)和真实数据(mmap指出e_addr字段)存储不是物理连续的,他们之间甚至可以非常远。
Small allocations
如果被分配的范围大小小于0x3800,那么会视为较小的allocation,在这种情况下,extents范围被每一个包含相似大小的slab区域区域调用。
对于每一种分配大小的类别,会有一个称为slab/extent size的区域,假设被分配的空间大小是N,slab块大小是M,那么区域的数字被成为M/N。
关于在安卓64位的小的区域分配处理如下表:
| # | Allocation Size | Slab/Extent Size | # | Allocation Size | Slab/Extent Size | # | Allocation Size | Slab/Extent Size |
|---|---|---|---|---|---|---|---|---|
| 0 | 8 | 4096 (0x1000) | 12 | 256 (0x100) | 4096 (0x1000) | 24 | 2048 (0x800) | 4096 (0x1000) |
| 1 | 16 (0x10) | 4096 (0x1000) | 13 | 320 (0x140) | 20480 (0x5000) | 25 | 2560 (0xa00) | 20480 (0x5000) |
| 2 | 32 (0x20) | 4096 (0x1000) | 14 | 384 (0x180) | 12288 (0x3000) | 26 | 3072 (0xc00) | 12288 (0x3000) |
| 3 | 48 (0x30) | 12288 (0x3000) | 15 | 448 (0x1c0) | 28672 (0x7000) | 27 | 3584 (0xe00) | 28672 (0x7000) |
| 4 | 64 (0x40) | 4096 (0x1000) | 16 | 512 (0x200) | 4096 (0x1000) | 28 | 4096 (0x1000) | 4096 (0x1000) |
| 5 | 80 (0x50) | 20480 (0x5000) | 17 | 640 (0x280) | 20480 (0x5000) | 29 | 5120 (0x1400) | 20480 (0x5000) |
| 6 | 96 (0x60) | 12288 (0x3000) | 18 | 768 (0x300) | 12288 (0x3000) | 30 | 6144 (0x1800) | 12288 (0x3000) |
| 7 | 112 (0x70) | 28672 (0x7000) | 19 | 896 (0x380) | 28672 (0x7000) | 31 | 7168 (0x1c00) | 28672 (0x7000) |
| 8 | 128 (0x80) | 4096 (0x1000) | 20 | 1024 (0x400) | 4096 (0x1000) | 32 | 8192 (0x2000) | 4096 (0x1000) |
| 9 | 160 (0xa0) | 20480 (0x5000) | 21 | 1280 (0x500) | 20480 (0x5000) | 33 | 10240 (0x2800) | 20480 (0x5000) |
| 10 | 192 (0xc0) | 12288 (0x3000) | 22 | 1536 (0x600) | 12288 (0x3000) | 34 | 12288 (0x3000) | 12288 (0x3000) |
| 11 | 224 (0xe0) | 28672 (0x7000 | 23 | 1792 (0x700) | 28672 (0x7000) | 35 | 14336 (0x3800) | 28672 (0x7000 |
这些大小是根据这个文件中提供的信息计算的https://cs.android.com/android/platform/superproject/+/android-13.0.0_r42:external/jemalloc_new/include/jemalloc/internal/size_classes.h,如下。
// include/jemalloc/internal/size_classes.h /* * ... * SIZE_CLASSES: Complete table of SC(index, lg_grp, lg_delta, ndelta, psz, * bin, pgs, lg_delta_lookup) tuples. * index: Size class index. * lg_grp: Lg group base size (no deltas added). * lg_delta: Lg delta to previous size class. * ndelta: Delta multiplier. size == 1<<lg_grp + ndelta<<lg_delta * psz: 'yes' if a multiple of the page size, 'no' otherwise. * bin: 'yes' if a small bin size class, 'no' otherwise. * pgs: Slab page count if a small bin size class, 0 otherwise. * lg_delta_lookup: Same as lg_delta if a lookup table size class, 'no' * */ #define SIZE_CLASSES \ /* index, lg_grp, lg_delta, ndelta, psz, bin, pgs, lg_delta_lookup */ SC( 0, 3, 3, 0, no, yes, 1, 3) \ // size == 8 SC( 1, 3, 3, 1, no, yes, 1, 3) \ // size == 16 (0x10) SC( 2, 4, 4, 1, no, yes, 1, 4) \ // size == 32 (0x20) SC( 3, 4, 4, 2, no, yes, 3, 4) \ // size == 48 (0x30) SC( 4, 4, 4, 3, no, yes, 1, 4) \ // size == 64 (0x40) ...
每一种大小的size都有对应的索引,第一个参数SC macro(经常在源代码中被称为szind),这个SIZE_CLASSES被用于分配大型allocation,计算公式如下:
size == 1<<lg_grp + ndelta<<lg_delta
在安卓64位处理中,计算size为1的结果如下:
注意:
在include/jemalloc/internal/size_classes.h中定义了
SIZE_CLASSES,实际取决于具体的底层架构,在一个64位的aarch64架构上,SIZE_CLASSES实际上根据下面的条件来定义。
# if (LG_SIZEOF_PTR == 3 && LG_TINY_MIN == 3 && LG_QUANTUM == 4 && LG_PAGE == 12)
而对于一个32位的处理器来说,LG_SIZEOF_PTR的值为2,LG_TINY_MIN的值为3。
Extents范围和slab块会通过e_slab_data根据包含可用的区域位图来寻找空闲的区域。
小内存分配关系结构关系如下:
large allocation
当所产生的大小大于0x3800时,考虑使用专属于大的分配策略,与小的分配类似,大型分配在 include/jemalloc/internal/size_classes.h中的相同宏中有可用的大小类(使用no值查找bin列的大小)。
#define SIZE_CLASSES \ /* index, lg_grp, lg_delta, ndelta, psz, bin, pgs, lg_delta_lookup */ \ ... SC( 35, 13, 11, 3, no, yes, 7, no) \ // last small alloc size class SC( 36, 13, 11, 4, yes, no, 0, no) \ // first large alloc size class \ SC( 37, 14, 12, 1, yes, no, 0, no) \ SC( 38, 14, 12, 2, yes, no, 0, no) \ ...
这是一个64位进程的第一个列表list:
| # | Extent size | in tcache |
|---|---|---|
| 36 | 16384 (0x4000) | yes |
| 37 | 20480 (0x5000) | yes |
| 38 | 24576 (0x6000) | yes |
| 39 | 28672 (0x7000) | yes |
| 40 | 32768 (0x8000) | yes |
| 41 | 40960 (0xa000) | yes |
| 42 | 49152 (0xc000) | yes |
| 42 | 57344 (0xe000) | yes |
| 44 | 65536 (0x10000) | yes |
| 45 | 81920 (0x14000) | no |
| 46 | 98304 (0x18000) | no |
| ... | no | |
| 231 | 8070450532247928832 (0x7000000000000000) | no |
当需要一个大小为N的大内存分配时,会选择最接近且满足M >= N大小的M。然后会申请一个大小为M+0x1000的内存块。
而实际被分配的空间地址(返回给用户的地址),会在基址base和base+0x1000字节上以0x40粒度字节的大小来随机划分,可以在这篇文章中查看更多的内容。(在 include/jemalloc/internal/extent_inlines.h查看extent_addr_randomize 定义)。
现在需要分配一个0x9000字节大小的空间,使用 malloc(0x9000):
- 选择最接近0xa000大小的区域
- 选择一个大小为0xb000的区域,即base size+0x1000的大小
- 按64字节对齐随机返回一个范围内的指针,该指针指向第一页
只有当从一个范围列表中提取范围时,才会出现这种情况,而不是从tcache(请参阅tcache部分)中提取。从tcache中提取时,基地址与之前相同,并不再随机化。
Extent选择算法
当进程需要一个新的slab块和一个大的空间区域时,那么就需要检索extent,步骤铷下:
- 从当前线程所在的区域检索
- 检查是否
arena->extents_dirty包含正在匹配的范围extent- 在安卓上,找到一个老的extent空间需要使用最低位(在源代码中也叫'first-fit')
- 如果检索到的extent过大,则划分位两个extent
- 检查如果
arena->extents_muzzy包含了正在匹配的extent,与上一种情况处理类似。 - 检查如果
arena->extents_retained包含正在匹配的extent,与上一种情况处理类似。 - 除此以外,就需要使用
mmap创建一个新的extent
当使用第五步中的方法使用mmap创建一个新的extent时,它的大小取决于在结构体arena_t中extent_groq_next字段的值的大小。extent_grow_next字段定义了新创建的extent的索引大小。在创建extent之后,这个值就会增加。创建的extent的范围将被分割为:
- 将立即使用所请求大小的第一个extent
- 第二个extent将会被放在
arena->extents_retained堆中
全局表sz_pind2sz_tab包含了每个索引对应的mmap的大小。所以,推荐新的范围大小是多少的方法是转储该表并查看索引:
下面这就是表的内容:
var je_sz_pind2sz_tab = [ 0x1000, 0x2000, 0x3000, 0x4000, 0x5000, 0x6000, 0x7000, 0x8000, 0xA000, 0xC000, 0xE000, 0x10000, 0x14000, 0x18000, 0x1C000, 0x20000, 0x28000, 0x30000, 0x38000, 0x40000, 0x50000, 0x60000, 0x70000, 0x80000, 0xA0000, 0xC0000, 0xE0000, 0x100000, 0x140000, 0x180000, 0x1C0000, 0x200000, 0x280000, 0x300000, 0x380000, 0x400000, 0x500000, 0x600000, 0x700000, 0x800000, 0xA00000, 0xC00000, 0xE00000, 0x1000000, 0x1400000, 0x1800000, 0x1C00000, 0x2000000, 0x2800000, 0x3000000, 0x3800000, 0x4000000, 0x5000000, 0x6000000, 0x7000000, 0x8000000, 0xA000000, 0xC000000, 0xE000000, 0x10000000, 0x14000000, 0x18000000, 0x1C000000, 0x20000000, 0x28000000, 0x30000000, 0x38000000, 0x40000000, 0x50000000, 0x60000000, 0x70000000, 0x80000000, 0xA0000000, 0xC0000000, 0xE0000000, 0x100000000, 0x140000000, 0x180000000, 0x1C0000000, 0x200000000, 0x280000000, 0x300000000, 0x380000000, 0x400000000, 0x500000000, 0x600000000, // ... ]
注意:
在jemalloc 5.2.1版本之前,选择
arena->extents_dirty的范围的算法是best-fit算法,即最佳拟合算法,无论序列号多少,都匹配最小尺寸。然而,现在看来,算法的实现可能导致泄露内存风险。因此在后面的版本中,即5.2.1之后就可以看到使用了first-fit算法。源文件参考如下// ANDROID // The best-fit selection is reported to possiblity cause a memory leak. // This code has been completely removed from 5.2.0, so remove it from // our tree rather than risk a leak. // See https://github.com/jemalloc/jemalloc/issues/1454
Rcache结构
除了与arena响关联的arena之外,每个线程还在本地存储中保存了一个scache_t/struct_tcache_s结构(include/jemalloc/internal/tcache_structs.h),为了加速内存的过程,一些空闲的空间分配记录在被使用之前还会保留在tcache中。
当需要查找一段内存时,jemalloc会在bins_small中查找小的分配,在bins_large中查找大的分配,如果没有找到相应的索引,分配器将使用绑定到线程的内存区域(arena)。在Android默认情况中,只有小型分配和大小、小于或等于0x10000的大型分配会被放置在bins_large中。最大的分配尺寸大小有全局变量`opt_lg_tcache_max (max_size = 1 << opt_lg_tcache_max).`定义。
// include/jemalloc/internal/tcache_structs.h struct tcache_s { // [...] /* Drives incremental GC. */ ticker_t gc_ticker; /* * The pointer stacks associated with bins follow as a contiguous array. * During tcache initialization, the avail pointer in each element of * tbins is initialized to point to the proper offset within this array. */ cache_bin_t bins_small[NBINS]; // [...] /* The arena this tcache is associated with. */ arena_t *arena; /* Next bin to GC. */ szind_t next_gc_bin; // [...] /* * We put the cache bins for large size classes at the end of the * struct, since some of them might not get used. This might end up * letting us avoid touching an extra page if we don't have to. */ cache_bin_t bins_large[NSIZES-NBINS]; };
每一个bins_small/bins_large索引对应特定的分配大小,并且类型是 cache_bin_t,更多可以查看资料include/jemalloc/internal/cache_bin.h
// include/jemalloc/internal/cache_bin.h typedef struct cache_bin_s cache_bin_t; struct cache_bin_s { /* Min # cached since last GC. */ cache_bin_sz_t low_water; /* # of cached objects. */ cache_bin_sz_t ncached; // [...] /* * Stack of available objects. * * To make use of adjacent cacheline prefetch, the items in the avail * stack goes to higher address for newer allocations. avail points * just above the available space, which means that * avail[-ncached, ... -1] are available items and the lowest item will * be allocated first. */ void **avail; };
在cache_bin_s中,avail是一个动态分配的堆栈,其中包含地址,并且始终指向分配缓冲区的末尾。可以使用最大元素数量ncached_max检索avail缓冲区的起始地址:start_avail = &avail[-ncached_max]。这个堆栈是负索引的,因此第一个条目(最近添加的)位于avail[-ncached],最后一个条目(最近添加的)位于avail[-1]。
当从tcache中弹出一个分配时,将返回avail[-ncached]处的条目,并且ncached会减少。当一个分被释放并推送到tcache时,ncached会增加,并地址存储在avail[-ncached]处。
tcache的逻辑结构如下:
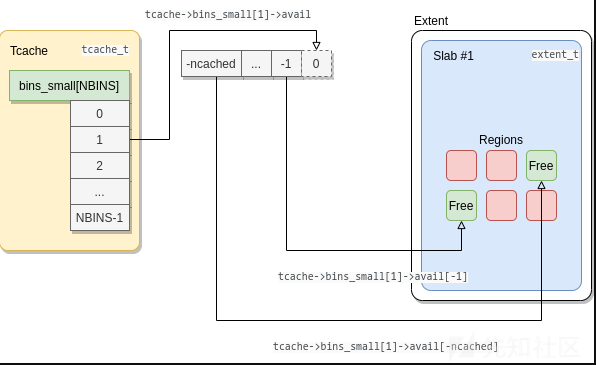
注意:
每个线程都有自己的tcache,并与一个arena相关联,但它tcache可能包来自其他arenaextents或slabs分配的指针。
对于每个缓存容器大小类别,允许并存储在类型为cache_bin_info_t的全局数组tcache_bin_info中的最大缓存对象数量。
// include/jemalloc/internal/cache_bin.h typedef struct cache_bin_info_s cache_bin_info_t; struct cache_bin_info_s { /* Upper limit on ncached. */ cache_bin_sz_t ncached_max; // int32_t };
Flush缓存刷新机制
内存并非无限的,如果缓存的内存太旧了,应该将其重新提供给其他线程。这就是为什么需要清空tcaches->bins_{small,large}的原因。这可以通过以下两个事件触发:
- 当
tcache->bins_XXX[i].ncached达到tcache_bin_info[i].ncached_max时,表示缓存已满。 - 当
tcache->g_ticket.tick的初始值为tcache->g_ticket.nticks,并且每次执行tcache操作时都会递减。当tcache->g_ticket.tick达到0时,将触发垃圾回收:指向索引tcache->next_gc_bin的bin将被清空,并且tcache->next_gc_bin会在总bin数量上进行模运算(在src/tcache.c中的tcache_event_hard)。
根据触发它们的事件,tcache bin的清空方式有两种:
- 缓存已满:从缓存中删除一半最旧的条目。
- 触发了垃圾回:从低于tcache->bins_XXX[i].low_water值的缓存中删除3/4最旧的条目,其中low_water取ncached的值。
当tcache被清空时:
- 小型分配对象(即regions)被放回它们对应的arena->bin[i]中,并标记为可用。
- 大型分配对象(即extents)被放回到它们所属arena的可用ents堆中(即arena->extents_dirty堆)。
内存使用机制
分配策略
小区域分配策略
假设szind是索引类大小,jemalloc用于分配小区域的过程如下所示:
- 直接在
tcache->bins_small[szind]堆中查找匹配的区域。 - 在
arena->bins[szind]堆中查找具有匹配空闲区域的slab。 - 从一个extent(扩展)创建一个新的slab:
- 在extents堆中查找一个extent:
arena->extents_dirtyarena->extents_muzzyarena->extents_retained
- 如果没有可用的extent,则创建一个新的extent。
- 将extent/slab划分为多个区域,并将其放入
arena->bins[szind]堆中。
- 在extents堆中查找一个extent:
大区域分配策略
假设szind是索引类大小,jemalloc用于执行大内存分配的过程如下所示:
- 如果大小
<= 0x10000,直接在tcache->bins_large[szind]堆中查找匹配的大内存分配。 - 在extents堆中查找一个extent:
arena->extents_dirtyarena->extents_muzzyarena->extents_retained
- 如果没有可用的extent,则创建一个新的extent。
内存区域释放
释放指针ptr时,处理过程如下所示:
查找包含
ptr的extent。找到此extent对应的大小类索引
szind。如果它属于小型大小类(小于或等于0x3800):
- 将
ptr放入tcache->bins_small[szind]缓存。 - 如果缓存bin已满,则清空它。
- 将
如果它属于大型大小类,并且其大小是
<= 0x10000- 将
ptr放入tcache->bins_large[szind]缓存。 - 如果缓存bin已满,清空它。
- 将
如果它属于大型大小类,并且其大小是
> 0x10000- 获取
ptr所在的extent,并将其放回可用extents堆中,即arena->extents_dirty堆。
- 获取
文章结论
Jemalloc的内部实现相当复杂,并使用许多不同的结构来提高速度并在多线程进程中最小化内存碎片化。
从攻击者的角度来看,以下是一些要点:
- 在利用堆溢出漏洞时,与Scudo不同,jemalloc在分配之间没有放置canaries(指针哨兵)。根据分配的大小,可能会覆盖相邻的区域或extent。然而,通过jemalloc添加的随机偏移量,阻碍了在大型分配上利用此类漏洞。
在利用使用后释放漏洞时,tcache机制使得在同一线程上重复使用一个分配变得很容易。然而,当尝试从另一个线程重复使用一个分配时,情况会变得复杂,因为tcache需要被清空,并且两个线程需要共享同一个arena。
另一个需要考虑的重要行为是缺乏extent的解除映射(unmapping),因为
opt_retain选项默认设置为true。
https://android.googlesource.com/platform/external/jemalloc_new/
https://blog.nsogroup.com/a-tale-of-two-mallocs-on-android-libc-allocators-part-2-jemalloc/
如有侵权请联系:admin#unsafe.sh