
超好用免费 AI 绘图 设计美化 Win, Mac, Linux 2023-07-23当今各种人工智能 AI 炙手可热,比如异次元介绍过的 ChatGPT、Bing、Claude、 2023-7-23 12:23:59 Author: www.iplaysoft.com(查看原文) 阅读量:119 收藏
当今各种人工智能 AI 炙手可热,比如异次元介绍过的 ChatGPT、Bing、Claude、Bard 等等,我们能利用它们完成写作、问答、翻译、编程、分析等等各种生产力与办公相关的用途。
而图像领域 AI 绘图也同样让人震惊!网上很多 AI 美女照片、二次元动漫妹子都非常惊艳。同时 AI 也能制作 Logo 图标、各类艺术插画、设计稿、科幻游戏场景等,甚至能画出一些人类难以完成的作品。如果你也想试试 AI 绘图软件,那免费开源的 Stable Diffusion 就是首选神器了……
Stable Diffusion 绘图软件整合版 - 适合零基础入门上手
Stable Diffusion (简称 SD) 是一款开源免费的以文生图的 AI 扩散模型,它和付费的 Midjourney 被人称为当下最好用的 AI 绘画工具。你在网上看到的绝大多数优秀 AI 图片作品,基本都是出自它俩之手。其中 Midjourney 是在线服务 (需绑信用卡付费),而 Stable Diffusion 则完全免费,可在自己的本地电脑上安装离线使用 (也能租用 VPS 云服务器部署在线使用)。

使用 Stable Diffusion,你可以通过文字的描述 (即常说的 Prompt / 提示词 / 关键词),来凭空生成一张图片 (以文生图功),也能在一张图片的基础上,按要求重新修改、绘制出一幅新的图片 (图生图功能)。而使用不同的模型,可以生成出风格完全不一样的作品。
SD 允许你随意下载安装网上的各种各样 AI 模型,灵活性和可玩性更高,能绘制的图片风格、类型只取决于你所下载的模型,可谓是极其繁多,用途极其广泛!不同的模型能给你生成出不同画风、不同人物、不同的物体、光照效果等等,这也是 SD 最好玩的地方。
Stable Diffusion 不同模型风格的 AI 画图作品演示:

Stable Diffusion 有纯命令行版本,以及带有 WebUI 网页界面的 Stable Diffusion WebUI 之分。纯命令行版的 SD 主要是供开发者们编程使用,我们普通用户平常所说的 Stable Diffusion 其实大多数时候都是指代包含有网页界面的 Stable Diffusion WebUI 版本,一般是通过浏览器进行操作。
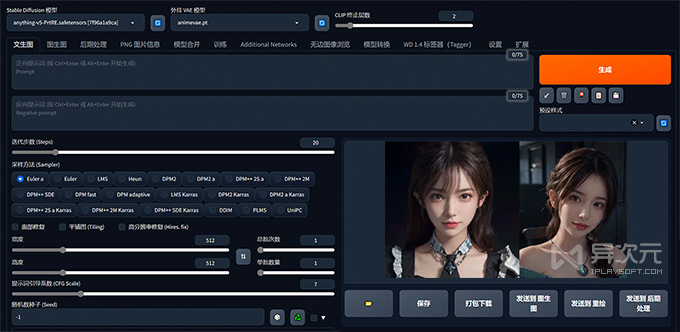
Stable Diffusion WebUI 网页界面截图:
超简单入门!Stable Diffusion 解压即用!适合小白
而由于 Stable Diffusion 项目的依赖众多,配置环境复杂,因此无论是要安装 Stable-Diffusion-Webui 还是安装命令行版的 SD,都需要比较长时间且繁杂的操作过程 (比如你要安装 Python、Git、要准备好能访问 Github 的网络、需要敲一些命令等等),网上虽然有不少教程,但对于懒人或只想简单快速尝试 AI 画图的用户还是不够友好。
因此异次元给大家推荐一款由 @秋葉aaaki 大佬制作的「Stable Diffusion 懒人一键安装启动整合包」,你无需学习各种安装教程,即可以快速一键搞定 Windows 版的 SD 安装配置,无需关心那些乱七八糟的事情,直接解压即用!
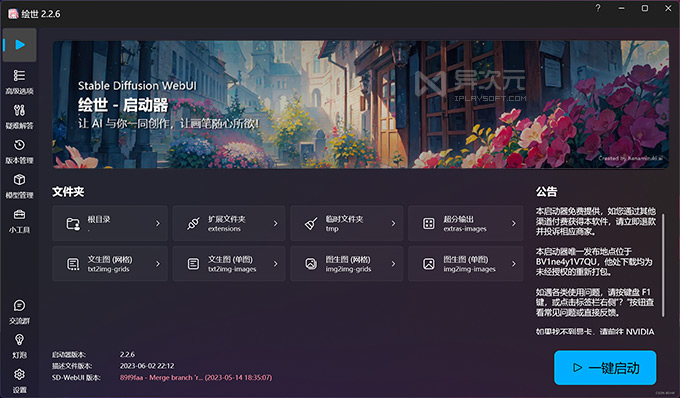
而且本整合版里面还额外提供了一个「绘世·启动器」,提供了众多便捷直观的功能 (如上图),「一键启动」就能运行并打开 SD WebUI,轻松解决 Stable Diffusion 新手入门上手难的问题。
电脑配置要求:
由于 Stable Diffusion 是部署在你电脑本地运行的,AI 的运算对电脑硬件配置有较高要求。建议你电脑最好配备英伟达 NVIDIA 的独立显卡 (俗称 N 卡),推荐 RTX 2060 或以上的显卡,显存推荐 8G (至少也要 4G 起步),否则生图的速度会大打折扣。
而 AMD 显卡 虽然也可以用,但据说性能损耗很大,而且还需要额外的配置比较麻烦 (网上有不少教程),否则 SD 会自动选择调用 CPU 来生成,速度会非常慢,所以强烈不推荐新手使用 A 卡。
另外,内存方面推荐 16G 或以上,硬盘建议使用 SSD 固态硬盘,否则 SD 软件的启动、生图速度都会很慢。SD 对 CPU 的要求倒是不高,一般现在的主流电脑的 CPU 都可以的。
注意事项
Stable Diffusion 懒人整合包由于内置了一些常用模型,因此体积会比较大,足足有 10 多 GB 之巨,没有「开通百度网盘会员」的话可能下载时间会比较长。另外,你还得准备好足够大的硬盘空间,因为日后还要下载更多的模型来制作各种风格的图片,所以建议最好至少预留 50 GB 以上的空间给 SD。
该 Stable Diffusion 整合包只有 Windows 版本,适合广大初学入门同学。但如果你希望在 macOS、Linux 系统使用,那么还是需要按网上相关教程去一步步安装,这里就不多阐述了。
最后,作者表示如整合包的“SD 启动器”被杀毒软件报毒属于误报,属正常现象,可以添加到信任区让其不再提示。如果你确实对此不放心,那么建议不要下载冒险了,自己斟酌考虑。
版本升级建议:
对于使用过旧版整合包的同学,升级新版本时建议不要覆盖安装,最好把你的模型、Lora、扩展插件、Tag 预设之类要保留的数据,全部剪切出来,删掉老版整合包,然后全新解压新版整合包,再把这些数据移动进去,这样可以避免很多奇奇怪怪的问题。
生成图片 (初入门):
使用 Stable Diffusion「文生图」生成一张图片的步骤其实很简单,你需要的做就是:选择模型 → 输入正向提示词 → 负向提示词 → 生成。
其中,正向提示词 (关键词) 是告诉 AI 你要画什么,必须用英文 (建议使用 ChatGPT、Claude 等帮助翻译生成 Prompt),词语之间用英文逗号分割。而负向提示词则相反,表示你不希望图片里出现什么。比如我希望画一个美女、长发、有花,最好真实一点,那么就输入:
1 girl, long hair, flowers, realistic这样就能搞出一张图女孩的图来了。当然你的描述细节越多越丰富,加上合适优秀的模型,出图的效果才会更好。建议大家多多查看别人好作品分享的 Prompt 再去尝试。
Stable Diffusion 出图的质量很大程度上由模型和 Prompt 提示词所决定。你希望生成各种各样的图片,那么就需要下载各种不同模型多多尝试。下面我们再说说 SD 模型的下载。
Stable Diffusion 不同模型可生成不同风格的绘图作品:

那么,我们去哪里可以下载到 Stable Diffusion 的模型呢?
推荐的 Stable Diffusion 模型下载网站:
- Civitai.com - 俗称 C 站,是最受欢迎的 AI 图像模型网站之一 (但国内需要魔法)
- Huggingface.co - 界面比较朴素,模型也非常丰富,好处是国内可以直接访问 (暂时)
- Liblibai.com 哩布哩布 - 国内较大的 AI 模型分享网站,大多搬运自 C 站,但也有积累到部分人气的原创国产模型
- 炼丹阁 - 国内 AI 模型分享网站,主要也是搬运 C 站资源
各种 AI 模型类型说明
- Checkpoint / 大模型 / 底模型 / 主模型
Checkpoint 模型指是 SD 能够直接绘图的基础模型,因此被称为大模型、底模型或者主模型,在 WebUI 上就叫它 Stable Diffusion 模型。安装完 SD 软件后,必须搭配主模型才能使用。不同的主模型,其画风和擅长的领域都会有不同侧重。 - LoRA 模型
目前最热门的微调模型,它可在原有大模型的基础上,对模型进行微调,从而能够生成特定的人物、物品或画风,比如很火的各种专门生成亚洲网红脸的真人美女 LoRA 模型。它们通常体积不会太大,且必须与 Checkpoint 模型一起使用。 - VAE 美化模型 (变分自编码器)
VAE 的全名叫 Variational autoenconder,中文叫变分自编码器。主要作用就是给图片加滤镜以及微调,有各种比如二次元、写实风格的不同 VAE。一些大模型会自带了 VAE (比如Chilloutmix)。如果你再加 VAE 则可能让图片效果变得混乱。 - Embedding / Textual lnversion / 文本反转模型 / Hypernetworks
Embeddings / Textual lnversion 文本反转,必须与 Checkpoint 模型一起使用。通过仅使用几张图像,就能让模型学习新的风格和概念,主要用于个性化图像生成。Embeddings 由于训练简单,文件小,因此也颇受欢迎。而且安装后,只需要在 Prompt 提示词中提到它就相当于调用了,很方便。不过由于 Embeddings 训练集较小,因此出图往往做不太到“形神兼似”,所以大多数人还是更喜欢使用 LoRA 模型。 - LyCORIS 模型
LyCORIS 可看作是一个优化版的 LoRA 微调模型,只是实现算法不同,在 SD 实现更多的参数有效微调,层级更多,因此可理解为是算法更优化更简洁更节约训练资源的微调模型。实际出图效果似乎也都比较好。 - ControlNet 模型
主要用于控制图片的主体结构、构图、线条、边界等,比如控制人物的动作、通过简单的线稿、原图来生成对应构图的 AI 作品。
SD 绘图演示:

了解大概的提示词 (Prompt) 和模型的概念,就能开始进入正式的 AI 绘图之旅了!想要使用 Stable Diffusion 生成精美的图片,主要就是要多尝试、多学习别人的作品,从入门到精通需要学习的知识还很多,需要一些耐心的哦。
总结:
无论是好奇尝鲜,学习 AIGC 相关技术,还是设计行业相关从业者希望利用 AI 生成图片,开源免费的 Stable Diffusion 都是必学的必用的 AI 绘图工具,小伙伴们都应该试一试!
而安装 Stable Diffusion WebUI 对初学者入门来说虽然难度不高但还是颇为繁琐,因此在 Windows 系统下,使用制作好的 SD 一键安装包 (整合版) 解压即用能省下不少时间,直接专心投入到 AI 生图的技术学习中去。好了,祝你早日借助 SD 制作出让人惊艳的 AI 图片作品吧。
相关文件下载地址
官方网站:访问
软件性质:开源免费
更多 AI 相关:ChatGPT | Bing | Claude | Bard
相关工具:Upscayl 图像无损放大
解压密码:www.iplaysoft.com
下载 Stable Diffusion WebUI 懒人整合包 (Windows) | 设计相关 | 智能相关 | 图片相关
/ 关注 “异次元软件世界” 微信公众号,获取最新软件推送 /
如有侵权请联系:admin#unsafe.sh