用例是安全监控活动的核心。组织需要一个过程来识别、实现和维护安全监视用例。这些过程不能太复杂,因为安全监控需要快速和持续的变化,以适应不断变化的威胁。在最新发布的《年度SIEM检测风险状态报告》中,C 2023-7-13 16:29:37 Author: www.freebuf.com(查看原文) 阅读量:2 收藏
用例是安全监控活动的核心。组织需要一个过程来识别、实现和维护安全监视用例。这些过程不能太复杂,因为安全监控需要快速和持续的变化,以适应不断变化的威胁。
在最新发布的《年度SIEM检测风险状态报告》中,CardinalOps揭示了企业SIEM中检测覆盖和用例管理的当前状态。
使用MITRE ATT&CK v13中的196种攻击技术作为基准,研究人员发现SIEM实际的检测覆盖率仍然远远低于大多数组织所期望的水平。更糟糕的是,组织通常没有意识到他们假设的理论安全性与实践中的实际安全性之间的差距,从而对他们的检测状态产生了错误的印象。
我们发现,平均而言,企业SIEM有如下特点:
- 仅覆盖所有MITREATT&CK技术的24%。换句话说,他们没有检测到对手用来破坏其环境的76%的MITRE ATT&CK技术。
- 已经获取了足够的数据,可能涵盖所有MITREATT&CK技术的94%。这表明我们不需要收集更多的数据,而是需要扩展我们的检测工程流程,以更快地开发更多的检测。
- 正在跨多个安全层实现“深度检测”,其中最常见的层是Windows、Network和IAM;最后是容器。
- 有12%的规则是破损的,且永远不会因常见问题(如配置错误的数据源、缺少字段和解析错误)而触发警报。
虽然自2022年以来,SIEM的检测覆盖率和规则健康指标都提高了几个百分点,但研究人员将这主要归因于抽样的差异,也因为研究组织在今年的数据集中添加了更多更成熟的组织。
实际和预期覆盖率间存在差距的原因
- 复杂性:一般企业拥有超过130种不同的安全工具(端点、网络、云、电子邮件、IAM等)。这些工具都有自己的日志格式、事件类型和/或警报类型,每个工具都需要基于对其功能的详细了解来开发独特的检测。因此,根据Ponemon的说法,超过80%的安全专业人员认为他们的SOC复杂性非常高,且不到40%的人认为他们的SOC非常有效。
- 变化性:基础设施、安全工具、攻击面、攻击技术和业务优先级(例如云)都在不断变化。
- 没有“一刀切”的通用内容:每个企业都是独一无二的,这使得从SIEM供应商、MSSP、开源社区和市场复制粘贴通用内容变得不切实际。
- 手动和容易出错的流程:这些流程高度依赖于具有专业知识的工作人员,这使得难以有效地扩展和维护高质量的检测。
- 招聘和留住技术人员的挑战:很难找到并留住可以跨不同的场景和日志源类型开发检测的专业人员。
接下来,研究人员提供了一系列最佳实践建议,以帮助CISO和检测工程团队应对这些挑战,并更有意识地了解如何测量检测覆盖率,并随着时间的推移不断对其进行改进。这些建议都是基于安全团队和SIEM专家(如google Cloud首席信息安全官办公室、前Gartner研究副总裁兼杰出分析师Anton Chuvakin博士等)的经验得出的。
这份报告的目标是帮助安全社区认识到将自动化、可重复和一致的流程引入检测工程的重要性,并提供独立的基准,使CISO和SOC领导者能够回答“我们准备如何检测最高优先级的威胁?”
SIEM的重要性持续彰显
根据Forrester Research的说法:
“最终,SIEM仍然是安全运营中心(SOC)的运营系统,是支撑SOC的基础,它不会消失……”
事实上,根据《SANS 2023 SOC调查报告》显示,SIEM和EDR被认为是拥有有效SOC的两大关键技术。
大约一年前,Google Cloud的CISO Anton Chuvakin在Twitter上发起的一项民意调查也支持了这一观点:
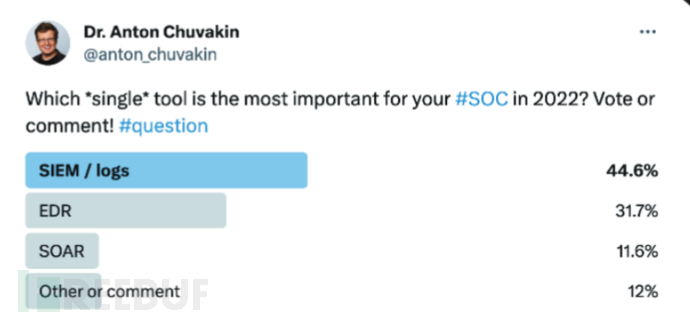
【在被问及“2022年对SOC最重要的工具”时,44.6%的人选择了SIEM】
正如一位安全负责人所解释的那样,即使一个组织正在使用EDR来检测和阻止端点层的恶意活动,它仍然需要一个具有自定义检测功能的SIEM,它可以作为关键的“后盾”来捕获EDR解决方案遗漏的攻击。
发生这种情况可能有几个原因,包括复杂的对手已经找到了禁用或绕过EDR控制的方法;相关的EDR警报因噪音过大而被禁用;或者对手已经设计出了“隐藏在噪音中”的未调优警报。
那么,我们如何衡量并持续改进对组织最重要的威胁的覆盖范围呢?MITRE ATT&CK框架可以提供帮助。
MITRE ATT&CK的重要性
自2013年创建以来,MITRE ATT&CK框架一直受到安全运营专业人士的关注。根据ESG的研究,MITRE ATT&CK的使用现在已经达到了一个拐点。经过9年的发展,MITRE ATT&CK及其用例已经远远超出了参考架构的范畴。在许多方面,MITRE ATT&CK已经成为安全运营的“通用语”。
作为了解对手战术和行为的标准框架,MITRE ATT&CK现在描述了APT28、Lazarus Group、FIN7和LAPSUS$等威胁组织使用的500多种技术和子技术。
根据ESG的研究,89%的组织目前使用MITRE ATT&CK来降低安全运营用例的风险,例如确定检测工程的优先级,将威胁情报应用于警报分类,以及更好地了解对手的战术、技术和程序(TTPs)。
MITRE ATT&CK引入的最大创新是,它扩展了传统的入侵杀伤链模型,超越了静态的IOCs(如攻击者可以不断更改的IP地址),对所有已知的对手TTPs进行了分类。
这些TTP分为以下两类:
- 战术:“为什么”攻击者正在执行活动,例如初始访问或特权升级。
- 技术:他们“如何”执行该活动,例如利用面向公众的应用程序或修改域策略。
MITRE ATT&CK也为进攻和防守团队标准化了分类词汇。正如Palo Alto Networks公司前首席信息安全官、现任The CyberWire首席分析师Rick Howard所说:
“洛克希德·马丁(Lockheed Martin)公司的杀伤链模型是概念性的,而MITRE ATT&CK框架则是可操作的。在该框架出现之前,我们都在关注同样的活动,但却无法以任何有意义的方式集体讨论它,因为每个供应商和政府组织都有自己的语言,而这些组织的任何情报都无法与其他任何人共享,除非进行大量的人工转换工作。”
此外,它也成为了IT领导者与高管沟通防御态势的标准方式,帮助解释它与新闻中听到的最近的攻击和漏洞(如微软Outlook漏洞,Follina或okta PassBleed)的关系,以及回答经典问题“我们准备如何检测最高优先级的威胁?”
MITRE ATT&CK技术的覆盖及健康状态
研究数据显示,企业SIEM平均呈现如下状态:
- 在MITRE ATT&CK v13框架中,仅检测到所有196种技术中的24%。这意味着攻击者可以执行大约150种不被SIEM检测到的不同技术。或者换句话说,SIEM只涵盖了所有可能被对手使用的技术中的大约50种技术。
- 已经摄取了足够的数据来潜在地覆盖94%的MITREATT&CK技术。这表明我们不需要收集更多的数据,我们需要扩展我们的检测工程流程,以更快地开发更多的检测。当然,从不同的安全层(如网络、云、IAM和电子邮件)收集更多的数据是一件好事,并且将通过“深度检测”提供更深入的覆盖,因为它可以以多种方式覆盖给定的技术,而不仅仅是通过在端点等单一层进行一次检测。
- 有12%的规则被打破,并且不会因为常见问题(如配置错误的数据源、丢失字段和解析错误)而触发警报。这通常是由于IT基础设施中的持续更改、供应商日志格式更改以及编写规则时的逻辑错误或意外错误而导致的。攻击者可以利用被破坏的检测产生的漏洞来成功地破坏组织。
以下是Splunk SPL的一些具体例子,说明了规则可能被打破的一些方式:
- Sourcetype不存在;
- 索引不存在;
- 查找不存在;
- 日程安排有时间间隔,导致错过警报;
- Sourcetype在过去的X天内没有报告日志;
- 索引在过去的X天里没有报告日志;
- Sourcetype<-> Indexare不匹配;
- 逻辑运算符不是大写的;
- 解析错误;
- Windows中没有登录进程命令行;
- Azure中没有记录密钥库更改;
企业SIEMs中最常见的安全层
由CardinalOps开发的MITRE ATT&CK安全层首次通过测量检测覆盖的“深度”扩展了ATT&CK覆盖的概念。它通过将每个检测映射到特定的安全层(如端点、网络、电子邮件、云、容器和IAM)来实现这一点,然后枚举给定技术所覆盖的不同层的数量。
这使SecOps团队能够确保他们在多个层面上对对他们最重要的技术进行“深度检测”。
此外,通过立即识别与“皇冠资产”(如最敏感的应用程序和数据)相关的盲点,安全层使组织能够将其覆盖范围与期望的业务成果联系起来。它还揭示了缺失的遥测和数据源,可以纳入他们的探测策略,以增加覆盖深度。
我们的数据显示,企业SIEM中最常见的安全层是:Windows、Network和IAM;紧接着是Linux/Mac、云、电子邮件和生产力套件;最后是容器。

容器的低排名很有趣,因为根据Red Hat research的研究结果显示,68%的组织都在运行容器。然而,我们的数据显示,它们通常没有受到可疑或异常行为的监控。
对此的一种解释可能是,由于基于微服务的应用程序环境的动态性,监控它们可能是一项巨大的挑战,并且它们可能会给SIEM平台带来大量数据。另一种解释可能是,检测工程师面临着为这些高动态资产编写高保真检测以警告异常活动的前景的挑战。
检测态势管理的最佳实践
组织需要在SOC中更有意识地进行检测。但是,我们应该检测什么?我们有这些场景的用例吗?它们真的有用吗?它们能帮助我的SOC分析师有效地进行分类和回应吗?
以下是一系列最佳实践建议,可提高SOC的检测覆盖率和检测质量。
1. 审查当前的SIEM流程
发现假阴性的方法是什么?目前漏掉了哪些敌对的技术、行为和威胁?
用例是如何管理和确定优先级的?通常,我们发现它们是通过一个ad-hoc过程读取到backlog的,这个过程是由以下因素共同驱动的:
- 威胁分析&威胁情报;
- 入侵和攻击模拟(BAS)工具;
- 有关最新备受瞩目的攻击者或漏洞的新闻;
- 手动渗透测试;
- 红队
今天的检测是如何发展的?将威胁知识转化为检测的过程是什么?
开发新检测通常需要多长时间?
是否有一个系统的过程来定期识别由于基础设施变更、发明人变更或日志源格式等原因而不再有效的检测?
2. 对如何开发和管理检测内容要更加有意识
关注有效性、覆盖面和改进。向SOC团队提出以下问题:
我真的检测到它了吗?
我能很好地检测它吗?
我的分类和响应是否正确?
根据我们的业务重点、珍贵资产、行业部门等,我需要检测什么?
我今天检测了什么?
我们是否缺少可以提高我们在高优先领域覆盖率的数据来源?
3. 构建或更新用例管理流程
在商定的时间内,选择3-5个增强部分来解决上一部分的问题。
4. 衡量并持续改进
检测工程流程与其他安全和IT管理流程没有什么不同。随着IT现代化并使用DevOps和SRE方法,SOC也应该如此。无法衡量的东西是无法改进的。许多SOC指标——聚焦人员、流程和技术——都是持续改进所必需的。
最后,围绕如何增加检测覆盖率和减少检测非功能规则的时间设置组织目标。
原文链接:
https://cardinalops.com/wp-content/uploads/2023/06/3rd-Annual-State-of-SIEM-Detection-Risk-CardinalOps-2023.pdf#gf_20
如有侵权请联系:admin#unsafe.sh