
read file error: read notes: is a directory 2023-6-20 22:2:0 Author: portswigger.net(查看原文) 阅读量:51 收藏
Tom Shelton-Lefley | 20 June 2023 at 14:02 UTC
There’s a running joke on the scanner development team; for the longest time I had net negative lines of code added to the Burp Suite codebase, and everyone’s convinced that I’m trying to regain that accolade.
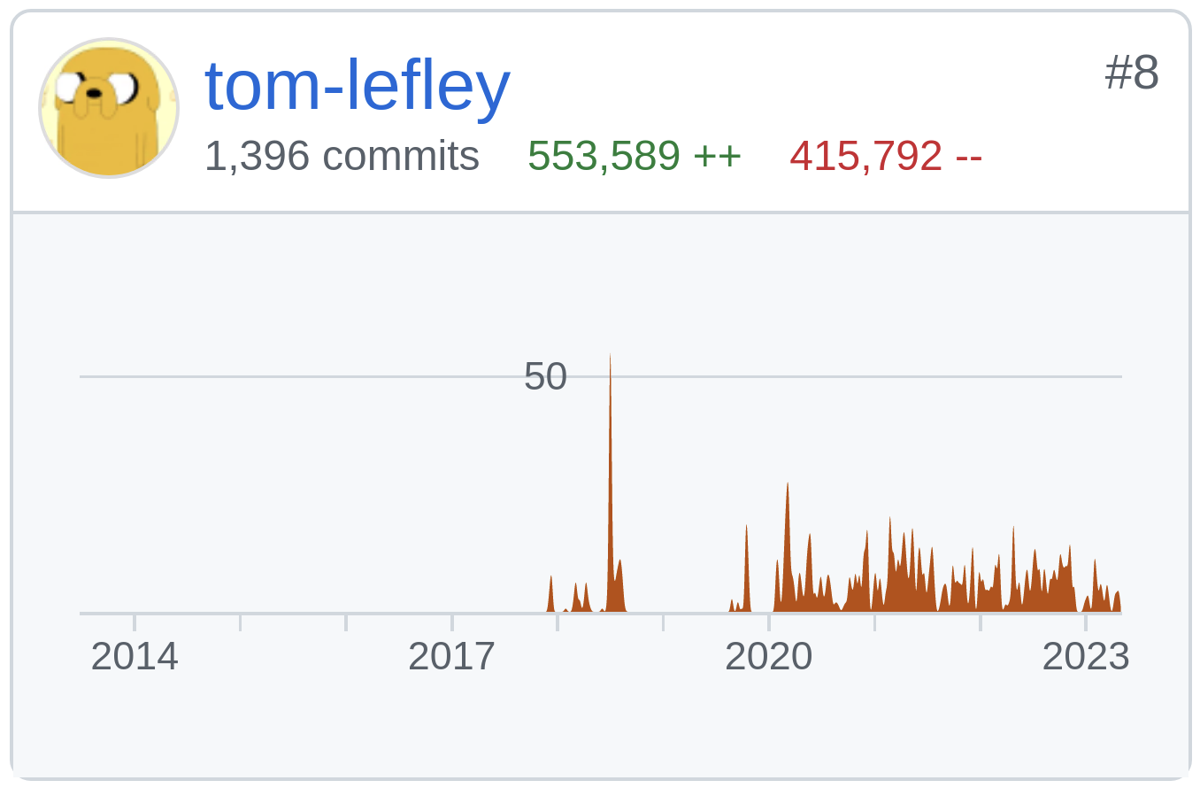
As you can see, I’m not far off. And over the last month or so, you’d certainly be forgiven for thinking that I was doing everything I could to earn back my crown. I have done nothing but delete code for three weeks.
Burp Scanner’s crawler is full of complexity, perhaps too much complexity (definitely too much, that’s what I’m building up to here). However, up until now, it’s been our own secret, dirty, hidden complexity. No one had to understand exactly what was going on under the hood except us.
With the crawl paths view that’s all changed. To quote teammate Dave: “our can is open and our worms are all over the table”. For the first time, you can now see the graph Burp Scanner is building up of your target application whilst it’s crawling, and so for the first time that graph has to actually be readable.
Merge conflicts
Let’s look at a concrete example of something I’ve recently taken my scythe to: merges.
As Burp Scanner is crawling around, it’s taking an abstract view at each location (web page) it finds, and comparing this against all previous locations to see if it’s been there before. In this way it constructs a directed graph of locations and edges (clicks, form submissions, etc.) between them. However, this abstract location view can change over time if notable features (anchor links, click handlers, etc.) aren’t completely stable with every visit, and as a result we can end up retroactively deciding that two locations were the same. This is what we call called a merge.
When a merge happened, it could trigger whole sections of the graph to collapse together. If two locations are the same, all of their edges must be the same. And if all of those edges are the same, then all of the locations those edges lead to must be the same. And if all of those locations are the same, then all of their edges must be the same. Et cetera, et cetera, you get the idea.
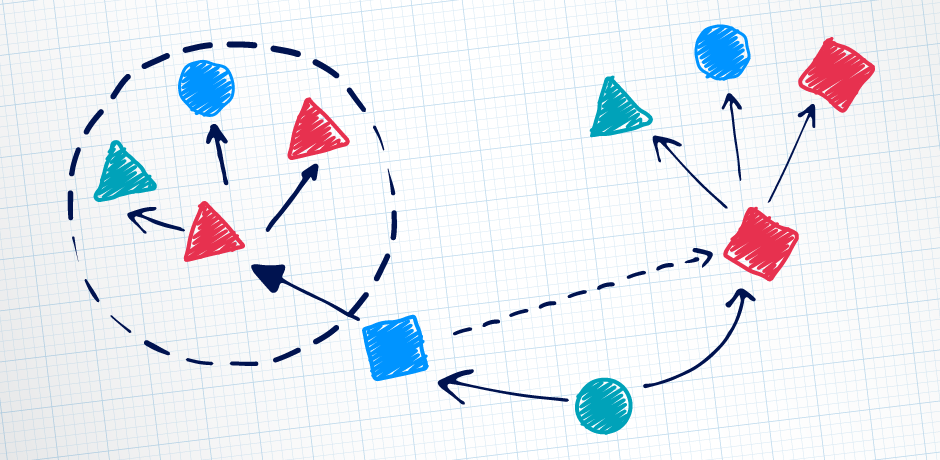
Merging existed as an optimization to make the crawler graph as small as possible, reducing the number of locations to explore, and the number of edges to audit. Without it, we can end up with identical, redundant subgraphs.
So why did we (I didn’t go rogue) decide to remove this behavior? It boils down to three reasons:
1. Complex code
Working out whether two subgraphs are the same, formally graph homomorphism, is really hard. NP-hard, in fact. This meant that the code written to implement it was hard to read, and harder to maintain.
That’s not to say the code was bad, not at all. It’s just that it added lots of hoops that any new code would have to jump through to work with it. In Java terms, there were many interface methods on our location and edge related classes - core classes that naturally get changed a lot - that had fiddly implementations and only existed so that they could be called in the merging algorithm. Ultra-specific methods like these are always a pain to work with because they often (and in this case, definitely did) end up dragging in obscure dependencies and obfuscating what the core class actually does.
This elephant right in the middle of our room also had to be addressed with every new member of the team, as they’d definitely have to squeeze around it at some point. There’s an ancient development proverb that states: “it’s harder to read code than it is to write it”. I can confirm that it’s harder still to explain it to a group of horrified onlookers on a whiteboard.
The development overhead this code constantly contributed wasn’t reason enough alone to delete it - otherwise we would have done so a long time ago - but it was definitely a factor.
2. Cognitive load
The second factor was the premise I lead this post with - crawler behavior was soon going to be visible, and that meant it had to be understandable.
Because merging involved deleting locations and rerouting edges, it had the potential to pull the rug out from under any users who were in the wrong place at the wrong time.
Let’s say you have the crawl paths tab open, and a location selected. If that location gets merged away, what happens to your view? Does it go back to an unselected state? Does the other location involved in the merge get selected instead? Neither of these are particularly intuitive, and because something has been removed (rather than added) there’s also nowhere to attach any explanation for what’s just happened.
This is going to be a recurring theme for us as a team now going forward. It’s important that the crawler behavior continues to be innovative, functional, and optimal. But it’s now just as important that it’s understandable and predictable.
3. What usage showed
Finally, and arguably most importantly, when we looked at statistics it turned out that 96% of crawls over the last year had 0 merges, and 99% had 5 or fewer (when you turn on performance feedback, it really does aid our development!).
If this hadn’t been the case and merges were very prevalent, it would have been much harder to justify removing them: merging is an optimization, so its necessity is directly linked to its frequency.
Spring cleaning
It’s these three principles that we’ve been applying to many of the different crawler functions and behaviors, and how we’ve been choosing what to set me loose on: if it does not spark joy for developers, users, or performance … then it can go.
A tidier codebase should also make new crawler changes easier, and faster, to implement. If not then it’s fine because I’ve had a ton of fun doing it. However, there’s at least one new feature (that we’re not quite ready to talk about yet) that’s been made possible by reducing dependencies - something we’ve wanted to do for a long time and we’re very excited about!

如有侵权请联系:admin#unsafe.sh