By: Flush对于任何希望了解 Web3 领域的人来说,浏览链上数据是一项基本技能。了解构成区块链的数据结构有助于我们思考创造性的方法来解析这些数据。同时,这些链上数据构成了可用数据的很大一部分。 2023-5-20 10:3:21 Author: 慢雾科技(查看原文) 阅读量:28 收藏
By: Flush
对于任何希望了解 Web3 领域的人来说,浏览链上数据是一项基本技能。了解构成区块链的数据结构有助于我们思考创造性的方法来解析这些数据。同时,这些链上数据构成了可用数据的很大一部分。此篇将深入研究 EVM 中的一个关键数据结构,交易收据和其相关的事件日志。
开始之前,我们先简单地聊聊作为 solidity 的开发者,为什么需要使用事件日志:
事件日志是数据存储的一个更便宜的选择,无需被合约访问,还可以通过测试智能合约中的特定变量,索引变量来重建存储状态。
事件日志是一种触发监听特定事件日志的 Web3 应用程序的方法。
EVM 节点不需要永久保留日志,可以通过删除旧日志来节省空间。合约无法访问日志存储,因此节点不需要它们来执行合约。另一方面,合约存储是执行所必需的,因此无法删除。
以太坊区块默克尔根
在第 4 部分,我们深入探讨了以太坊框架,尤其是状态默克尔根部分。状态根(State Root)是区块头中所包含的三个默克尔根之一。另外两个是 Transaction Root 和 Receipt Root。
为了输入构建这个框架,我们将参考以太坊上的区块 15001871(https://etherscan.io/block/15001871),其中包含 5 个交易及其相关收据和发送的事件日志。
区块头
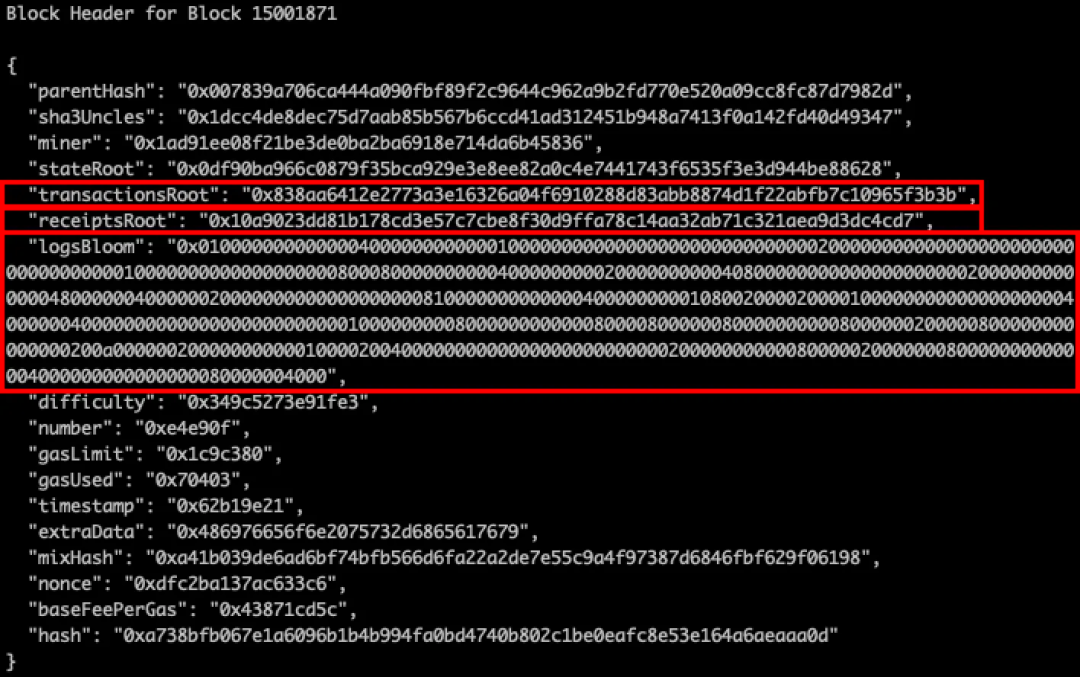
我们将从区块头中的 3 个部分开始, Transaction Root,Receipt Root 和 Logs Bloom(对区块头的简单介绍可以在第 4 部分中回顾)。
(图源:https://ethereum.stackexchange.com/questions/268/ethereum-block-architecture/757#757)
在 Transaction Root 和 Receipt Root 下的以太坊客户端中,Merkle Patricia Tries 包含该区块内所有交易数据和收据数据。而本文将只关注于节点可以访问的所有交易和收据。
通过以太坊节点查询到 15001871 区块的区块头信息如下:
区块头中的 logsBloom 是一个关键的数据结构,将在本文后面提到。首先让我们从位于 Transaction Root 下的数据开始,即 Transaction Trie。
交易树 Transaction Trie
Transaction Trie 是生成 transactionsRoot 并记录交易请求向量的数据集,交易请求向量是执行一个交易所需的信息片段,一个交易包含的数据字段如下:
Type - 交易类型(LegacyTxType 传统交易、AccessListTxType EIP-2930 引入、DynamicFeeTxType EIP-1559 引入)
ChainId - 交易的 EIP155 链 ID
Data - 交易的输入数据 input data
AccessList - 交易的访问列表
Gas - 交易的 gas limit
GasPrice - 交易的 gas price
GasTipCap - 交易的单位 gas 超过基础费用最多的矿工优先打包的激励溢价,Geth 中的 maxPriorityFeePerGas 由 EIP1559 定义
GasFeeCap - 交易的单位 gas 费用上限,Geth 中的 maxFeePerGas (GasFeeCap ≥ baseFee + GasTipCap)
Value - 交易的以太坊数额
Nonce - 交易账户发起者的 nonce
To - 交易的接收者地址。对于合约创建交易而言,To 返回为 nil 值
RawSignatureValues - 交易数据的签名值 V、R、S
在了解了以上数据字段之后,让我们来看一下 15001871 区块的第一笔交易 https://etherscan.io/tx/0x311ba3a0affb00510ae3f0a36c5bcd0a48cdb23d803bbc16f128639ffb9e3e58。
通过 Geth 的 ethclient 查询,可以看到 ChainId 和 AccessList 都有 "omitempty",这意味着如果该字段为空,则将在响应中被省略,以减少或甚略序列化后数据的大小。
(代码源:https://github.com/ethereum/go-ethereum/blob/c503f98f6d5e80e079c1d8a3601d188af2a899da/core/types/transaction_marshalling.go)
这笔交易表示将 USDT 代币转移到 0xec23e787ea25230f74a3da0f515825c1d820f47a 地址。To 地址是 ERC20 USDT 的合约地址 0xdac17f958d2ee523a2206206994597c13d831ec7。通过 input data 我们可以看到函数签名 0xa9059cbb 对应为函数 transfer(address,uint256),将数量为 0x2b279b8(十六进制的 45251000)的 42.251 枚 USDT(精度为 6)转到 0xec23e787ea25230f74a3da0f515825c1d820f47a 地址。
你可能注意到这个交易数据结构并没有告诉我们任何关于交易结果的信息,那么交易成功了吗?它消耗了多少 gas?又触发了哪些事件记录呢?此时我们将引入 Receipt Trie。
收据树 Receipt Trie
如同购物收据会记录交易的结果一样, Receipt Trie 中的一个对象为以太坊交易做同样的事情而且还会记录一些额外细节。回到上面提出有关交易收据的问题,我们将重点关注触发了以下事件的日志。
再次查询 0x311b 的链上数据并获取其交易收据,此时将获取到以下字段:
(代码源:https://github.com/ethereum/go-ethereum/blob/f5037185aa6ebea0f7e6765b2439a3c8a066e85e/core/types/receipt.go)
Type - 交易类型(LegacyTxType、AccessListTxType、DynamicFeeTxType)
PostState(root) - 执行交易后生成的状态树的根节点 StateRoot,图中查询到对应的数值为 0x,可能是因为 EIP98
CumulativeGasUsed - 此交易和同一区块中所有先前交易累积消耗的总 Gas
Bloom(logsBloom) - 事件日志的 Bloom 过滤器,用于在区块链上有效地搜索和访问合约事件日志,允许节点快速检索某个事件是否在一个区块中发生,而无需完全解析该区块中的所有交易收据
Logs - 日志对象的数组,包含了由交易执行过程中触发的合约事件生成的日志条目
TxHash - 收据相关联的交易哈希
ContractAddress - 如果该交易是创建合约,则为部署合约的地址。如果交易不是合约创建,而是如转账或与已部署的智能合约交互,那么 ContractAddress 字段将为空
GasUsed - 这笔交易所消耗的 gas
BlockNumber - 这笔交易发生的区块的区块编号
TransactionIndex - 区块内的交易索引,索引确定首先执行哪个交易。该交易位于区块顶部,因此索引为 0
现在我们知道了交易收据的组成,接下来进一步了解交易收据中的 logsBloom 和日志数组 logs。
事件日志 Event Logs
通过以太坊主网上的 USDT 合约代码,可以看到 Transfer 事件在合约的第 86 行进行了声明,其中 2 个输入参数均有关键字 "indexed"。
(代码源:https://etherscan.io/token/0xdac17f958d2ee523a2206206994597c13d831ec7#code)
当事件输入被 “索引” 时,它可以让我们通过该输入快速查找日志。例如,使用上面的索引 "from" 时,可以在区块 X 和 Y 之间获取所有 "from" 地址为 0x5041ed759dd4afc3a72b8192c143f72f4724081a 的 Transfer 类型的事件日志。我们还可以看到,在第 138 行调用 transfer 函数时,会触发事件日志。值得注意的是,当前合约使用的 solidity 版本较早,因此缺少 emit 关键字。
再回到获取到的链上数据:
(代码源:https://github.com/ethereum/go-ethereum/blob/f5037185aa6ebea0f7e6765b2439a3c8a066e85e/core/types/log.go)
让我们更深入其中的 address、topics 和 data 字段。
主题 Topics
Topics 是索引值。从上图能看到链上查询的数据中有 3 个 topics 的索引参数,而 Transfer 事件只有 2 个索引参数(from 和 to)。这是因为第一个 topics 始终是事件的函数签名哈希值。当前事例中的事件函数签名是 Transfer(address,address,uint256)。通过对其进行 keccak256 哈希,得到结果 ddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef。
(在线工具:https://emn178.github.io/online-tools/keccak_256.html)
当我们按照之前讲到的对 from 字段进行查询,但同时又想限制查询的事件日志类型仅为 Transfer 类型的事件日志时,就需要通过索引事件签名来完成按事件类型进行过滤筛选的操作。
我们最多可以有 4 个 topics,每个 topic 的大小为 32 字节(如果索引参数的类型大于 32 字节(即字符串和字节),则不会存储实际数据,而是存储数据的 keccak256 摘要)。我们可以声明 3 个索引参数,因为第一个参数由事件签名获取。但存在有一种情况是第一个 topic 不是哈希事件签名。这种情况就是声明匿名事件的时候。此时开启了使用 4 个而不是之前的 3 个索引参数的可能性,但失去了对事件名称进行索引的能力。匿名事件的另一个优点是它们的部署成本更低,因为它们不会强制使用 1 个额外的 topic。而其他 topics 就是来自 Transfer 事件的索引 "from" 和 "to" 的值。
数据 Data
当前示例向 Transfer 事件添加了一个额外的 "tax" 字段。假设设定的 tax 为 20%,那么税收值应该是 45251000 * 20% = 9050200,其十六进制为 0x8a1858,由于这个数的类型是 uint256,而 data 的类型为 32 字节,则需要将十六进制值填充为 32 字节,data 项结果为 0x000000000000000000000000000000000000000000000000000000000002b279b8000000000000000000000000000000000000000000000000000000000008a1858。
地址 Address
address 字段是发出事件的合约地址,有关这个字段的一个重要说明是,尽管它未包含在 topic 部分中,它也将被索引。原因在于 Transfer 事件是 ERC20 标准的一部分,这意味着当需要过滤筛选 ERC20 转账事件的日志时,将从所有的 ERC20 合约中获取转账事件。而通过索引合约地址,可以将搜索范围缩小到特定的合约 / 代币,如示例中的 USDT。
操作码 Opcodes
最后就是 LOG 操作码。它们从不包含 topic 时的 LOG0 到包含 4 个 topics 时的 LOG4。LOG3 是我们示例中使用的内容。包含如下:
offset - 内存偏移量,表示数据域输入的起始位置
length - 要从内存中读入的数据长度
topic x(0 - 4) - topic x 的值
(图源:https://www.ethervm.io/)
offset 和 length 定义数据在内存中位于 data 部分的位置。
了解了 log 的结构以及一个 topic 是如何被索引后,我们再来了解索引项是如何被查找的。
Bloom 过滤器 Bloom Filters
索引项能够被更快查找的秘诀就是 Bloom filter。
Llimllib 文章(https://llimllib.github.io/bloomfilter-tutorial/)对这个数据结构有很好的定义与解释。
“Bloom filter 是一个数据结构,它可以用来判断某个元素是否在集合内,具有运行快速,内存占用小的特点。而高效插入和查询的代价就是,Bloom Filter 是一个基于概率的数据结构:它只能告诉我们一个元素绝对不在集合内或可能在集合内。Bloom filter 的基础数据结构是一个比特向量。”
下面是一个比特向量的例子。白色单元格代表值为 0 的位,绿色单元格代表值为 1 的位。
通过采取一些输入和哈希将这些比特位设置为 1,由此产生的哈希值被用作哪个比特位上应被更新的位索引。上面的比特向量是对值 "ethereum" 使用 2 个不同的哈希处理得到 2 位索引的结果。哈希表示十六进制数,要获得索引,可以取这个数字并将其转换为 0 到 14 之间的值。有很多方法可以做到这一点,比如说 mod 14。
回顾
有了一个用于交易的 Bloom filter,也就是一个比特向量,可以在以太坊中通过哈希处理,确定要更新比特向量中的哪些位的输入是地址字段和事件日志的 topic。让我们回顾一下交易收据中的 logsBloom,这是一个特定交易的 Bloom filter。一个交易可以有多个日志,其包含所有日志的 address / topic。
如果再向上回顾到区块头,会发现另一个 logsBloom。这是该区块内所有交易的 Bloom filter。其中包含每个交易的每个日志中的所有 addresses / topics。
这些 Bloom filters 用十六进制表示而不是二进制。它们的长度为 256 字节,表示一个 2048 位的向量。如果参考上面的 Llimllib 示例,我们的位向量长度为 15,位索引 2 和 13 翻转记为 1。若将其转换为十六进制,来看看会得到什么。
虽然十六进制表示得并不像是比特向量,但是在 logsBloom 中就是如此。
查询 Queries
之前提到过一个查询内容 “查找区块 X 和 Y 之间获取所有 "from" 地址为 0x5041ed759dd4afc3a72b8192c143f72f4724081a 的 Transfer 类型的事件日志”。我们可以获取事件签名 topic,它表示类型 Transfer 以及 from(0x5041…)值的 topic,并确定 Bloom filter 中的哪些位索引应该设置为 1。
如果在区块头中使用 logsBloom,可以检查到这些位中的任何一个是否未设置为 1。如果不是,可以确定区块中没有符合该条件的日志。而如果发现这些位已被设置,我们就会知道匹配的日志可能就在块中。但是不能完全确定,原因是区块头 logsBloom 由多个地址和主题组成。其他的事件日志可能已设置匹配位。这就是 Bloom filter 是一种概率数据结构的原因。位向量越大,与其他日志发生位索引冲突的可能性就越小。一旦有了匹配的 Bloom filter,就可以使用相同的方法查询各个收据的 logsBloom。当获取到匹配项时,可以查看实际的日志条目来检索对象。
按照上述操作在区块 X 到 Y 执行,就可以快速查找和检索符合标准的所有日志。这也就是 Bloom filter 从概念上讲的工作原理。
现在来看看以太坊中使用的实现。
Geth 实现 - Bloom Filters
我们了解了 Bloom filter 是如何工作的,下面来学习 Bloom filter 是如何从 address / topic 到 logsBloom 的一步步在一个实际的块中完成筛选的。
首先从以太坊黄皮书的定义来看:
(图源:https://ethereum.github.io/yellowpaper/paper.pdf)
“我们定义 Bloom filter 函数为 M,将日志条目缩减到单个 256 字节哈希中:
其中 是一个专门的 Bloom filter,它在给定任意字节序列的情况下设置 2048 中的三位。通过在字节序列的 Keccak-256 哈希散列中获取前三对字节中每对字节的低位 11 位来实现这一点。”
下面将提供一个示例和对 Geth 客户端实现的参考来简化上述定义的理解。
这是我们在 Etherscan 上面查看的交易日志。
第一个 topic 是事件签名 0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef 并以将这个值转换为应更新的位索引。
以下是来自 Geth 代码库的 bloomValues 函数。
这个函数接收事件签名 topic,如:0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef 等数据,并返回需要在 Bloom filter 中更新的位索引。
(代码源:https://github.com/ethereum/go-ethereum/blob/d8ff53dfb8a516f47db37dbc7fd7ad18a1e8a125/core/types/bloom9.go)
1. 这个 bloomValues 函数接收输入的数据是一个 topic(在示例中是事件签名)和一个 hashbuf(一个长度为 6 的空字节数组)。
1)参考黄皮书片段,“字节序列的 Keccak-256 哈希散列中的前三对字节”。这三对字节也就是 6 个字节,即 hashbuf 的长度。
2)示例数据:0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef。
2. 第 140 - 144 行之间的 sha 命令将输入数据哈希并把输出加载到 hashbuf 中。
1)使用 keccak256 的 sha 输出的十六进制结果为(当使用 keccak 256 作为函数签名时,输入是文本类型,而这里是十六进制类型):ada389e1fc24a8587c776340efb91b36e675792ab631816100d55df0b5cf3cbc。
2)hasbuf 现有内容 [ad, a3, 89, e1, fc, 24](十六进制)。每个十六进制字符代表 4 位。
3. 计算 v1。
1)hashbuf [1] = 0xa3 = 10100011 用于与 0x7 按位与。0x7 = 00000111。
2)一个字节由 8 位组成,如果想获得一个位索引,需要确保得到的值在零索引数组的 0 到 7 之间。使用按位与将 hashbuf [1] 限制为 0 到 7 之间的值。示例中计算得,10100011 & 00000111 = 00000011 = 3。
3)该位索引值与位移运算符一起使用,也就是向左位移 3 位,得到 8 位字节索引 00001000 ,以创建一个翻转位。
4)v1 是整个字节而不是实际的位索引,因为这个值之后将在 Bloom filter 上进行按位或运算。OR 或运算将确保 Bloom filter 中的所有相应位也被翻转。
4. 现在有了字节值,但仍需字节索引。Bloom filter 的长度为 256 字节(2048 位),因此我们需要知道在哪个字节上运行按位或运算。值 i1 表示此字节索引。
1)将 hashbuf 通过 big-endian uint16 字节序,这使其限制位数组的前 2 个字节,也就是示例中的 0xada3 = 1010110110100011。
2)将此值与 0x7ff = 0000011111111111 进行按位与运算。其中 0x7ff 设置为 1 的位数有 11 个。在黄皮书中有提到,“它通过获取前三对中每一对的低 11 位来实现这一点”。这将得到值 0000010110100011,也就是 1010110110100011 & 0000011111111111 的结果。
3)然后将这个值右移 3 位。这会将 11 位数字转换为 8 位数字。我们想要一个字节索引,而 Bloom filter 的字节长度为 256,因此需要字节索引值在该范围内。而一个 8 位的数正好可以是 0 到 255 之间的任何值。在我们的例子中,这个值是 0000010110100011 右移 3 位的结果 10110100 = 180。
4)通过 BloomByteLength 计算我们的字节索引,知道它是 256 减去计算出的 180,再减 1。减 1 是为了将结果保持在 0 到 255 之间。这给了我们要更新的字节索引,在这种情况下它结果是字节 75,也就是我们计算出 i1 的结果。
5. 更新 Bloom filter 第 75 个字节中的位索引 3(0 索引所以第 4 位),可以通过对 Bloom filter 中的第 75 个字节进行 v1 的按位或运算来完成。
1)我们只涵盖了第一个字节对 0xada3,这是针对字节对 2 和 3 再次完成的。每个 address / topic 将更新 2048 位向量中的 3 位。在黄皮书中提到,“Bloom filter 在给定任意字节序列的情况下设置 2048 中的三位”。
2)字节对 2 状态更新字节 195 中的位索引 1(按照过程 3,4 执行,结果如图)。
3)字节对 3 状态更新字节 123 中的位索引 4。
4)如果要更新的位已经被另一个 topic 翻转,它将保持原样。如果没有,将翻转为 1。
通过上面的操作过程,可以确定事件签名 topic 将翻转 Bloom filter 中的以下位:
字节 75 中的位索引 3
字节 195 中的位索引 1
字节 123 中的位索引 4
查看交易收据中的 logBlooms,将其转换为二进制文件,就可以验证这些位索引是否已设置。
同时,对于那些有兴趣深入了解更多关于日志搜索和 Bloom filter 的实现的读者,可以参考 BloomBits Trie(https://github.com/zsfelfoldi/go-ethereum/wiki/BloomBits-Trie)文章。
到此,我们深入探讨 EVM 系列文章告一段落,之后还会给大家带来更多优质的技术文章。
原文链接:
https://noxx.substack.com/p/evm-deep-dives-the-path-to-shadowy-16e
往期回顾
慢雾导航
慢雾科技官网
https://www.slowmist.com/
慢雾区官网
https://slowmist.io/
慢雾 GitHub
https://github.com/slowmist
Telegram
https://t.me/slowmistteam
https://twitter.com/@slowmist_team
Medium
https://medium.com/@slowmist
知识星球
https://t.zsxq.com/Q3zNvvF
如有侵权请联系:admin#unsafe.sh