【A9】GPT代码漏洞挖掘小实践
01—简介在GPT出来后,发现能做的事情实在太多了。尤其是技术方面,当有思路就可以找GPT锻炼(tou lan)一下它的技术能力,让它帮忙写代码啥的,这感觉是真的舒服,但是GPT目前弊端也很明显,无法 2023-4-11 21:46:32 Author: NOVASEC(查看原文) 阅读量:31 收藏
01—简介在GPT出来后,发现能做的事情实在太多了。尤其是技术方面,当有思路就可以找GPT锻炼(tou lan)一下它的技术能力,让它帮忙写代码啥的,这感觉是真的舒服,但是GPT目前弊端也很明显,无法 2023-4-11 21:46:32 Author: NOVASEC(查看原文) 阅读量:31 收藏
01
—
简介
在GPT出来后,发现能做的事情实在太多了。尤其是技术方面,当有思路就可以找GPT锻炼(tou lan)一下它的技术能力,让它帮忙写代码啥的,这感觉是真的舒服,但是GPT目前弊端也很明显,无法上传文件,只能以文本输入问题,而输出也有局限性,3.5版本输出只有4096个tokens,4的版本虽然有32K的tokens,回答也比3.5准确多了,但是GPT4每天有使用限制,而且API接口也没有全开放,只能申请。
什么是llama_index
04
—
1、准备一个GPT和训练数据集。训练数据集包含了大量文本信息;
2、使用llama_index对训练数据集进行索引。这个过程就像给一本书建立目录一样,目的是帮助模型更快地查找到相关的信息;
3、将训练数据集的文本向量化;
4、使用llama_index查找与问题相关的文本。查找会从训练数据集的索引中找到;
5、将找到的相关文本片段作为提示提供给GPT模型;
6、GPT模型根据提示生成回答,并反馈回答。
主要核心是llama_index提供的索引信息,让GPT模型更快地找到与问题相关的知识片段,从而提高回答问题的准确性和效率。
代码如下:
# -*- coding: utf-8 -*-# 导入所需库import openaiimport osfrom langchain.chat_models import ChatOpenAI# 设置openai的API密钥openai.api_key = "your api key"os.environ["OPENAI_API_KEY"] = openai.api_key# 导入llama_index库中的相关组件from llama_index import (GPTSimpleVectorIndex,SimpleDirectoryReader,LLMPredictor,PromptHelper,ServiceContext)# 设置最大输入大小max_input_size = 4096# 设置输出令牌数量num_output = 1000# 设置最大块重叠max_chunk_overlap = 20# 设置块大小限制chunk_size_limit = 1000# 初始化PromptHelperprompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap, chunk_size_limit=chunk_size_limit)# 初始化LLMPredictorllm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=num_output))# 初始化ServiceContextservice_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper, chunk_size_limit=1000)# 从文档中读取数据documents = SimpleDirectoryReader("./taocms", recursive=True, errors='ignore').load_data()# 构建索引index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)#保存索引index1.jsonindex.save_to_disk('index1.json')# 对输入问题进行查询response = index.query("请审计这套源码,请将审计出的源码构造出http包,并用中文描述。",service_context=service_context,similarity_top_k=3,mode="default")# 输出查询结果print(response)
效果测试:
拿靶场测试了一下,有时候会构造HTTP包,但也有时候不会构造。存在有不稳定性,而且也因为GPT3输出tokens大小只有4096,反馈的时候也会停顿,或者只能审计出一个漏洞后就没下文了。
05
—
由于llama_index目前还在实验阶段,实操的时候踩了好多坑,翻阅官方资料和操作demo,目前也将踩坑记录下。
踩坑一:
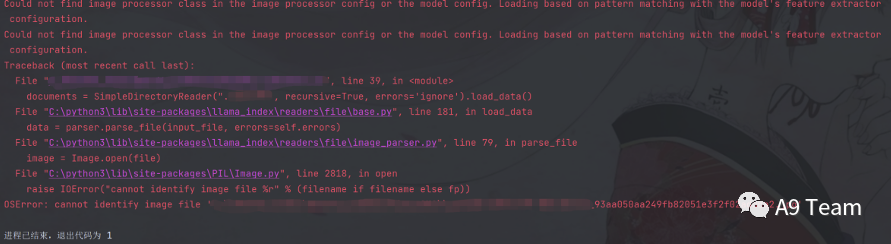
源码中可能因为图片的原因导致报错,解决方案去掉源码里的图片即可。
踩坑二:
分块的时候出现错误,表示无解,换套源码试试玩吧...
踩坑三:
文章来源: http://mp.weixin.qq.com/s?__biz=MzUzODU3ODA0MA==&mid=2247488819&idx=1&sn=32f76f80e4e9574357f55333e47915c2&chksm=fad4c824cda34132effefe3e5f2d72ea720622847aacad7ab8bb739fd10dc9b283bc946f5cb3#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh