Node.js发布于2009年
Chrome V8引擎下的Javascript运行环境
Javascript js xx.js
与Java的关系就是雷锋塔与雷峰的关系
JavaScript是负责浏览器端执行的脚本,在HTML负责动态事件响应等功能
简单JS
<script> alert('1') </script>
JS在浏览器端的应用
dom
标签:h1table form
event(监听事件)
<h1 onclick="alert(1);">hello</h1>
时间监听,左键,右键,滑块,双击,跳转,异步请求
js现状
js 围绕浏览器页面展开
设计时,为了安全,js无法
调用操作系统api
访问操作系统的文件系统
做多操作cookie
为了解决xss问题,增加了HttpOnly标签,防止JS钓鱼
原因就是js代码,由服务端发送给浏览器执行如果能够操作系统api和访问文件系统,
那么只要访问含义恶意的js代码的网址就会执行本地的命令,明显,不合乎逻辑
浏览器也是建立沙箱环境来执行js,目前已经极难看到js能够直接调用本地客户端的api或者执行命令
在国外发展快速(成本因素)
js作为前端渲染用,不可获取
再用v8引擎增加功能,让js能够操作操作系统api和访问文件系统,
那么js也就可以作为后端,操作http服务器,处理逻辑问题了
结果,前后端都用的js,
2个人干的活,现在只需要1个人干
Node常见模板
express 渲染模板 render_template 有点类似
Pug 旧版叫jade
Mustache
EJS
处理 数据如何附加到htm1页面上用的
插入数据的地方,写个标记,别人替换的时候,找这个标记,然后替换它对应的值
这个标记就是模板语法
jade的模板 #{username}
ejs的模板语法<%=usenrame %>
JS原型污染原理
子类通过protp执行父类,可以给父类增加没有的属性
简介
JavaScript 原型污染是一种安全漏洞,它利用了 JavaScript 对象的原型继承机制,通过修改原型链上的对象,从而影响到整个应用程序。
原型污染通常发生在从不可信的源加载脚本时。
攻击者可以通过在 Object.prototype 上添加属性或方法,将恶意代码注入应用程序中。
这些恶意代码可能会导致应用程序的不稳定、数据泄露、甚至完全控制应用程序。
以下是一个简单的例子,演示了 JavaScript 原型污染的基本原理:
javascriptCopy code// 在 Object.prototype 上添加一个名为 'isAdmin' 的属性 Object.prototype.isAdmin=true;// 现在所有的对象都有了 'isAdmin' 属性 var obj = {};console.log(obj.isAdmin);// 输出: true // 但是如果我们从不可信的源加载了脚本 // 它可能会修改 Object.prototype 上的属性 var maliciousScript ="<script>Object.prototype.isAdmin = false;</script>"; document.write(maliciousScript);// 现在所有的对象都失去了 'isAdmin' 属性 console.log(obj.isAdmin);// 输出: false
在这个例子中,我们首先在Object.prototype上添加了一个名为isAdmin的属性,并将其设置为true。
然后,我们创建了一个空对象obj,并检查它是否具有isAdmin属性,输出为true。
接着,我们假设从一个不可信的源加载了一个脚本,该脚本修改了Object.prototype上的isAdmin属性,并将其设置为false。
在此之后,我们再次检查obj对象的isAdmin属性,输出为false。
因此,可以看出,通过原型污染技术,攻击者可以修改 JavaScript 对象的行为,从而影响到整个应用程序的安全性和稳定性。
所有 JavaScript 对象都会继承自Object.prototype对象,包括全局对象、数组对象、函数对象、甚至是空对象。
因此,如果在Object.prototype上添加一个属性,那么所有的对象都会继承这个属性,并可以访问它。
在上面的例子中,我们在Object.prototype上添加了一个名为isAdmin的属性,并将其设置为true,这样就让所有的对象都继承了这个属性。
所以,当我们创建一个空对象obj时,它也会继承Object.prototype上的isAdmin属性,因此可以访问它。
这也是 JavaScript 中原型继承机制的一个特点:
当我们访问一个对象的属性或方法时,如果当前对象没有这个属性或方法,那么 JavaScript 引擎会沿着该对象的原型链向上查找,直到找到该属性或方法或到达原型链的顶部为止。
因此,如果在原型链上的某个对象上添加了属性或方法,那么所有继承自该对象的对象都会受到影响。
protp
当我们创建一个 JavaScript 对象时,它会自动获得一个特殊属性 proto,该属性指向该对象的原型对象。原型对象是一个普通的 JavaScript 对象,它包含该对象继承的属性和方法。通过 proto 属性,我们可以访问和操作该对象的原型对象。
简单示例
// 创建一个对象 var person = { name: 'John', age: 30 }; // 访问对象的原型对象 console.log(person.__proto__); // 输出: {} // 创建一个原型对象 var personProto = { greet: function() { console.log('Hello, my name is ' + this.name); } }; // 将对象的原型对象设置为 personProto Object.setPrototypeOf(person, personProto); // 访问对象的原型对象 console.log(person.__proto__); // 输出: { greet: [Function: greet] } // 调用对象的原型对象上的方法 person.greet(); // 输出: Hello, my name is John
在这个例子中,我们首先创建了一个对象 person,它包含了两个属性 name 和 age。
然后,我们通过访问 person.proto 属性,可以看到对象的原型对象是一个空对象 {}。
接着,我们创建了一个原型对象 personProto,它包含了一个方法 greet,该方法用于打招呼并输出对象的名字。
然后,我们使用 Object.setPrototypeOf 方法将 person 对象的原型对象设置为 personProto,从而实现了对象和原型对象的关联。
最后,我们再次访问 person.proto 属性,可以看到对象的原型对象现在包含了一个方法 greet。我们可以通过调用 person.greet() 方法来访问原型对象上的方法,并输出对象的名字。
什么是文件系统模块
fs模块是Node.js官方提供的、用来操作文件的模块,它提供了一系列的方法和属性,用来满足用户对文件的操作需求
读取文件
fs.readFile(path[,options],callback) 参数1:必选参数,字符串,表示文件的路径 参数2:可选参数,表示以什么编码格式来读取文件 参数3:必选参数,文件读取完成后,通过回调函数拿到读取的结果。
// 1.导入fs模块,来操作文件 const fs = require('fs') // 2.调用fs.readFile()方法读取文件 fs.readFile('./file/1.txt', 'utf8', function (err, dataStr) { // 打印失败的结果,如果读取成功,则err的值为null // 如果读取失败,则err的值为错误对象,dataStr的值为undefined if (err) { return console.log('读取文件失败' + err.message) } console.log('读取文件成功' + dataStr) })
dataStr
dataStr 是读取文件后返回的字符串,它表示读取到的文件内容。在 Node.js 中,读取文件时会将文件内容作为字符串返回给回调函数中的第二个参数,因此我们可以通过 dataStr 来获取文件内容,并对其进行处理,例如输出到控制台、写入到其他文件中等操作。
err
err 是 JavaScript 内置的错误对象,它用于表示发生的错误信息。在 Node.js 中,通常将 err 作为回调函数的第一个参数,用于处理异步操作中的错误信息。当发生错误时,err 会被赋值为一个包含错误信息的对象,否则它的值为 null。
err 对象包含多个属性,例如 name 表示错误的名称,message 表示错误的描述信息等,具体取决于错误的类型和发生的原因。在实际开发中,我们通常需要根据具体的错误信息来进行相应的处理,例如输出到日志、返回错误码等操作。
写入文件
fs.writeFile()的语法格式
使用该方法,可以向指定的文件中写入内容,语法格式如下
fs.writeFile(file, data[, options], callback)
参数1:必选参数,字符串,表示文件的存放路径
参数2:必选参数,表示要写入的内容
参数3:可选参数,表示以什么编码格式来读取文件,默认值是utf8
参数4:必选参数,文件写入完成后的回调函数。
//导入fs文件系统模块 const fs = require('fs') // 2.调用fs.writeFile() 方法,写入文件的内容 // 参数1:表示文件的存放路径 // 参数2:表示要写入的内容 // 参数3: 回调函数 fs.writeFile('f:/files/2. txt', ' abcd', function(err) { // 2.1 如果文件写入成功,则err的值等于null “2.2如果文件写入失败,则err的值等于一个错误对象 console. log(err) })
判断文件是否读取成功
可以判断err对象是否为null,从而知晓文件写入的结果:
const fs = require('fs') fs .writeFile( 'F:/files/2.txt', 'Hello Node.js!', function(err) { if (err) { return console.log( '文件写入失败! ' + err. message) } console. log '文件写入成功! ') })
路径动态拼接
在使用fs模块操作文件时,如果提供的操作路径是以.//或./开头的相对路径时,很容易出现路径动态拼接错误的问题。
原因:代码在运行的时候,会以执行node命令时所处的目录,动态拼接出被操作文件的完整路径。
解决方案:在使用fs模块操作文件时,直接提供完整的路径,不要提供./或./开头的相对路径,从而防止路径动态拼接的问题。
fs.readFile(__dirname+'/files/1.txt','utf8',function(err,dataStr){ if(err) return console.log('error!'+err.message) console.log(dataStr) })
path模块是Node.js官方提供的,用来处理路径的模块,它提供一系列的方法和属性,用来满足用户对于路径的处理需求
导入
const path=require('path')
path.join()
path.join可以把多个路径片段拼接为较为完整的路径字符串
const path = require('path'); const fullPath = path.join('/Users/john', 'Desktop', 'file.txt'); console.log(fullPath); // 输出:/Users/john/Desktop/file.txt
在上面的示例中,path.join() 方法将三个参数连接在一起,生成了一个完整的路径 /Users/john/Desktop/file.txt。在这个路径中,/ 符号是分隔符,用于分隔路径中的不同部分。
path.join() 方法还会自动处理不同操作系统下的分隔符,例如在 Windows 系统下,路径分隔符是 \,而在 Unix 或类 Unix 系统下,路径分隔符是 /。因此,使用 path.join() 方法可以确保生成的路径是操作系统兼容的。
需要注意的是,path.join() 方法只是简单地将多个路径连接在一起,并不会检查路径是否真实存在。如果需要检查路径的有效性,可以使用 fs.existsSync() 方法。
path.basename()
path.basename() 方法是 Node.js 中的一个函数,用于获取路径的基本文件名。基本文件名指的是路径中的最后一部分,不包括目录名和扩展名(如果存在)
使用该方法可以获取路径中的最后一部分,经常通过这个方法获取路径中的文件名,语法格式如下
const path = require('path'); const filename = path.basename('/Users/john/Desktop/file.txt'); console.log(filename); // 输出:file.txt
在上面的示例中,path.basename() 方法返回路径 /Users/john/Desktop/file.txt 的基本文件名 file.txt
path.basename() 方法还接受一个可选的参数
path.basename(path[,ext]) 参数:path:必选参数,表示一个路径的字符串 ext可选参数,表示文件拓展名 返回:表示路径中的最后一部分
需要注意的是,path.basename() 方法只是简单地获取路径的基本文件名,并不会检查路径是否真实存在。如果需要检查路径的有效性,可以使用 fs.existsSync() 方法。
path.extname()
使用该方法可以获取路径中的拓展名部分
如果文件名中没有点字符或点字符在文件名的开头,path.extname() 方法返回空字符串
const path = require('path'); const extname = path.extname('/Users/john/Desktop/file.txt'); console.log(extname); // 输出:.txt
如果文件路径中有多个点字符,则 path.extname() 方法只会返回最后一个点字符及其后面的字符作为文件的扩展名
const path = require('path'); const extname1 = path.extname('/Users/john/Desktop/file.txt.jpg'); console.log(extname1); // 输出:.jpg const extname2 = path.extname('/Users/john/Desktop/file'); console.log(extname2); // 输出:''
客户端与服务器
什么是客户端,什么是服务器?
在网络节点中,负责消费资源的电脑,叫做客户端。
负责对外提供网络资源的电脑,叫做服务器。
Http模块是Node.js官方提供的,用来创建web服务器的模块。通过http模块提供的Http.createServer()方法,就能方便的把一台普通电脑,变成一台web服务器,从而对外提供Web资源服务。
const http=require('http')
创建web服务器
导入Http模块
const http=require('http')
创建web服务器实例
const server=http.createServer()
绑定request事件,监听客户端的请求
//使用服务器实例的.on()方法,为服务器绑定一个request事件 server.on('request',(req,res)=>{ //只要有客户端来请求我们自己的服务器,就会触发request事件,从而调用这个事件处理函数 console.log('someone visit our web server.') })
启动服务器
//调用server.listen(端口号,cb回调)方法,即可启动web服务器 server.listen(80,()=>{ console.log('http server running at http://127.0.0.1') })
只要服务器接收到了客户端的请求,就会调用server.on()为服务器绑定的request事件处理函数
在事件处理函数中,访问与客户端相关的数据或属性
req
//req是请求对象,它包含了与客户端相关的数据和属性
- //req.url是客户端相关的数据和属性
- //req.url是客户端请求的url地址
- //req.method 是客户端的method请求类型
server.on('request',(req,res)=>{ const str='Your request url is ${req.url},and request method is ${req.method}' console.log(str) })
res
server.on('request',(req,res)=>{ //res是响应对象,它包含了与服务器相关的数据和属性,例如: //要发送到客户端的字符串 const str='Your request url is ${req.url},and request method is ${req.method}' //res.end()方法的调用: //向客户端发送指定内容,并结束这次请求的处理过程 res.end(str) })
中文乱码
当调用res.end()方法,向客户端发送中文内容的时候,会出现乱码问题,此时,需要手动设置内容的编码格式 server.on('request',(req,res)=>{ //发送的内容包含中文 conststr='您请求的url地址是${req.url},请求的method类型是${req.method}' //为了防止中文显示乱码的问题,需要设置响应头 res.setHeader('Content-Type','text/html;charset=utf-8') //把包含中文的内容,响应给客户端 res.end(str) })
初步实现
server.on('request',function(req,res){ const url =req.url //1.获取请求的Url地址 let content ='<h1>404 Not found!</h1>'//2.设置默认的内容 if(url=='/'||url ==='/index.html'){ content='<h1>首页</h1>'//3.用户请求的是首页 }else if(url==='/about.html'){ content='<h1>关于页面</h1>' } //为了防止中文显示乱码的问题,需要设置响应头 res.setHeader('Content-Type','text/html;charset=utf-8') //把包含中文的内容,响应给客户端 res.end(str) })
在 Node.js 中,模块是一种组织和封装代码的方式,用于将代码划分为一些独立的功能单元。
Node.js 的模块系统是基于 CommonJS 规范实现的,它支持使用 require 和 exports 两个关键字进行模块的导入和导出。
Node.js 中有三种类型的模块
- 核心模块(Core Module):Node.js 内置的模块,如
http、fs、path等,可以通过require直接引用。 - 文件模块(File Module):开发者编写的模块,通常放在文件中,可以通过
require引用,也可以通过module.exports导出模块内容。 - 第三方模块(Third-party Module):由其他开发者编写的模块,发布在 NPM(Node.js Package Manager)上,可以通过
npm命令安装,然后通过require引用。
核心模块
const http = require('http'); const fs = require('fs');
文件模块
我们可以在一个 js 文件中定义一个模块,然后通过 module.exports 导出模块内容
// myModule.js function add(x, y) { return x + y; } module.exports = { add: add //add: add 的意思是将 add 函数导出,并将它赋值给一个名为 add 的属性, //这样在其他模块中引用该模块时,就可以通过 myModule.add 访问到这个函数。 //也就是说,我们将 add 函数打包成一个模块,使其可以在其他模块中复用。 };
在另一个文件中使用 require 来引用这个模块
const myModule = require('./myModule'); console.log(myModule.add(1, 2)); // 输出 3
第三方模块
我们可以通过 npm 命令安装第三方模块,比如 lodash,然后在代码中使用 require 引用它:
相当于python的pip 和 import
const _ = require('lodash'); console.log(_.chunk([1, 2, 3, 4], 2)); // 输出 [[1, 2], [3, 4]]
Express是基于Node.js平台,快速,开放,极简的Web开发框架
Express是基于内置的http模块进一步封装起来的,能够极大的提高开发效率
基本使用
GET
app.get('/', function(req, res) { res.send('Hello, world!'); }); app.get('/users/:id', function(req, res) { const userId = req.params.id; res.send('User ID: ' + userId); });
以上代码定义了两个路由:一个用于处理根路径 / 的请求,另一个用于处理 /users/:id 路径的请求,其中 :id 是一个参数,用于匹配 URL 中的任意字符串,并将其存储在 req.params 对象中。当浏览器访问这些 URL 时,服务器会调用相应的路由处理函数,并返回相应的结果。
POST
app.post('/login', function(req, res) { const username = req.body.username; const password = req.body.password; // TODO: check username and password //TODO: check username and password 是一种常见的注释格式,用于标识需要进行实现或修改的代码部分。它表示 "待办事项"(To Do),提示开发人员在未来的某个时候需要将该部分代码完善或修复。 通常,程序员在编写代码时,会遇到一些需要进一步思考或完善的问题,或者需要留下一些待处理的任务,此时可以使用 TODO 标记来记录这些问题或任务。这样可以使得代码更易于维护和管理。 在实际开发中,IDE(集成开发环境)或代码编辑器通常会提供特定的功能来识别和管理 TODO 标记,以便开发人员能够更方便地跟踪和处理这些标记。 res.send('Welcome, ' + username + '!'); });
以上代码定义了一个用于处理 /login 路径的 POST 请求的路由处理函数,当浏览器提交表单数据到这个 URL 时,服务器会解析请求体中的数据,并将其存储在 req.body 对象中。然后,路由处理函数可以从 req.body 中获取表单数据,并进行相应的处理,最后返回响应结果给浏览器。
res.send() 内容响应给客户端
res.send() 是 Express 框架中用于发送 HTTP 响应的函数之一,它可以将指定的内容作为响应体发送给客户端,并结束响应。
res.send() 可以接收多种类型的参数,包括字符串、JSON 对象、二进制数据等。当参数为字符串时,它会将字符串作为文本内容发送给客户端;当参数为 JSON 对象时,它会将对象序列化为 JSON 字符串,并设置响应头中的 Content-Type 为 application/json;当参数为二进制数据时,它会将数据作为二进制流发送给客户端,并设置响应头中的 Content-Type 为对应的 MIME 类型。
const express = require('express'); const app = express(); // 发送文本响应 app.get('/hello', function(req, res) { res.send('Hello, world!'); }); // 发送 JSON 响应 app.get('/data', function(req, res) { const data = { name: 'Alice', age: 18 }; res.send(data); }); // 发送二进制响应 app.get('/image', function(req, res) { const fs = require('fs'); const path = require('path'); const imagePath = path.join(__dirname, 'public', 'images', 'logo.png'); fs.readFile(imagePath, function(err, data) { if (err) { res.status(500).send('Internal Server Error'); } else { res.type('png').send(data); } }); }); app.listen(3000, function() { console.log('Server is running at http://localhost:3000'); });
查询 req.query
const express = require('express'); const app = express(); app.get('/user', function(req, res) { const name = req.query.name; const age = req.query.age; res.send(`Hello, ${name}! You are ${age} years old.`); }); app.listen(3000, function() { console.log('Server is running at http://localhost:3000'); });
在上述示例中,当客户端访问 /user 路径时,服务器会通过 req.query 获取查询参数,并返回包含查询参数的响应。
获取URL的动态参数
在 Express 框架中,req.params 属性可以用于获取请求路径中的参数。例如,假设我们有如下路由定义:
app.get('/user/:id', function(req, res) { const userId = req.params.id; // ... });
当客户端请求 /user/123 路径时,Express 框架会将请求路径中的参数 123 保存到 req.params 中,可以通过 req.params.id 来获取该参数的值。
需要注意的是,路由定义中的 :id 表示一个参数,其名称为 id,在实际使用中,参数的名称可以是任意合法的 JavaScript 变量名。
如果请求路径中包含多个参数,可以在路由定义中使用多个 : 符号来指定不同的参数名,例如:
app.get('/user/:id/address/:city', function(req, res) { const userId = req.params.id; const city = req.params.city; // ... });
在上述代码中,路由 /user/:id/address/:city 包含两个参数,分别是 id 和 city,它们分别对应请求路径中 /user/123/address/beijing 中的 123 和 beijing。可以通过 req.params.id 和 req.params.city 来获取这两个参数的值。
托管静态资源
express.static
express提供express.static()函数
通过它,我们可以非常方便地创建一个静态资源服务器,
通过如下代码就可以将public 目录下的图片、CSS 文件、JavaScript 文件对外开放访问了:
app.use(express.static('public'))
借此便可以访问任何public目录下的资源
托管多个目录
app.use(express.static('public')) app.use(express.static('image'))
访问静态资源文件时,express.static0 函数会根据目录的添加顺序查找所需的文件。
挂载路径
我们将静态资源目录设置为 public,并通过 app.use() 方法将其挂载到 /static 路径下。这样,在客户端请求 /static/image.png 时,Express 框架会自动到 public/image.png 中查找相应的文件,并将其返回给客户端。
挂载路径前缀的作用在于,可以为静态资源指定一个统一的访问路径,这样既可以保证访问路径的统一性,也可以防止静态资源与动态路由发生冲突。例如,如果不指定路径前缀,静态资源和动态路由都可能会存在 /user 这样的路径,这样会导致路由解析出现问题。而通过指定路径前缀,可以避免这样的冲突,保证路由解析的正确性。
const express = require('express'); const app = express(); app.use('/static', express.static('public')); app.listen(3000, function() { console.log('Server is running at http://localhost:3000'); });
nodemon
当基于Node.js编写了一个网站应用的时候,传统的方式,是运行node.app.js命令,来启动项目。这样做的坏处是:当代码被修改之后,需要手动重启项目。
现在,我们可以node命令替换为nodemon命令,使用nodemon app.js来启动项目,这样做的好处是:代码被修改之后,会被nodemon监听到,从而实现自动重启项目的效果
路由
Express中的路由分三部分组成,分别是请求的类型,请求的URL地址,处理函数
app.METHOD(PATH,HANDLER)li
例
//匹配GET请求,且请求URL为/ app.get('/',function(req,res){ res.send('Hello World!') }) //匹配post请求,且请求URL为/ app.post('/',function(req,res){ res.send('Got a POST request') })
在express中使用路由最简单的方式,就是把路由器挂载到APP上
const express=require('express') //创建web服务器,命名为app const app= express() //挂载路由 app.get('/',(req,res)=>{ res.send('hello world') }) app.post('/',(req,res)=>{ res.send('Post Request.') }) //启动web服务器 app.listen(80,()=>{ console.log('http://127.0.0.1') })
模块化路由
为了方便对路由进行模块化的管理,Express不建议将路由直接挂载到app上,而是推荐将路由抽离为单独的模块。将路由抽离为单独模块的步骤如下:
- 创建路由模块对应的.js文件
- 调用express.Router()函数创建路由对象
- 向路由对象挂载具体的路由
- 使用module.exports向外共享路由对象
- 使用app.use()函数注册路由模块
关于挂载操作
在 Node.js 中使用 Express 框架时,app.use() 方法可以用来注册中间件函数或路由。
当传入的第一个参数是一个路径前缀(如 /api)时,表示该中间件或路由会应用到该路径前缀下的所有路由中。
const express = require('express'); const app = express(); const userrouter = require('./userrouter'); // 所有以 /api 开头的请求都会经过 userrouter 处理 app.use('/api', userrouter); app.listen(3000, function() { console.log('Server is running at http://localhost:3000'); });
在上述代码中,我们使用 app.use() 方法将 userrouter 路由挂载到了 /api 路径下。这样,所有以 /api 开头的请求都会先经过 userrouter 处理,然后再根据具体的路由进行分发。
需要注意的是,使用 app.use() 方法挂载路由时,该路由处理函数中的路径前缀已经被去掉了。例如,在上述代码中,userrouter 中的路由处理函数中,如果定义了路径为 /users,则实际处理的请求路径是 /api/users。这是因为 /api 已经被挂载到了路由处理函数的路径前缀中,因此处理函数只需要关注后面的路径即可。
例如,我们使用下面的代码来挂载路由:
const express = require('express'); const app = express(); const userrouter = require('./userrouter'); // 所有以 /api 开头的请求都会经过 userrouter 处理 app.use('/api', userrouter);
在上述代码中,我们使用 app.use() 方法将 userrouter 路由挂载到了 /api 路径下。这样,当客户端发送 /api/users 的请求时,实际上会先经过 userrouter 的处理函数,然后再交由 /users 的处理函数进行处理。在 userrouter 路由处理函数中,我们只需要关注 /users 的路径即可,因为 /api 路径前缀已经被去掉了。
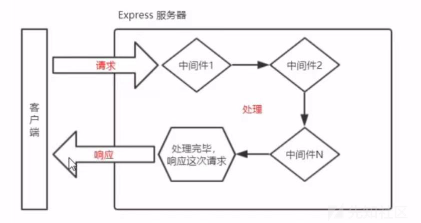
中间件
当一个请求到达Express的服务器之后,可以连续调用多个中间件,从而对这次请求进行预处理。

在 Express 中,中间件(middleware)是一种函数,它可以访问请求对象(request object)、响应对象(response object)以及应用程序的请求/响应循环中的下一个中间件函数。中间件函数可以执行一些操作,例如修改请求对象、响应对象或者调用下一个中间件函数。每个中间件函数可以通过调用 next() 函数来将控制权传递给下一个中间件函数,或者在请求/响应循环中结束请求-响应周期。
在 Express 中,中间件分为应用级别的中间件和路由级别的中间件。应用级别的中间件将作用于整个应用程序,而路由级别的中间件只会作用于特定的路由。
应用级别
const express = require('express'); const app = express(); // 应用级别的中间件 app.use((req, res, next) => { console.log('Time:', Date.now()); next(); }); app.get('/', (req, res) => { res.send('Hello, world!'); }); app.listen(3000, () => { console.log('Server started on port 3000'); });
在上面的例子中,我们使用 app.use() 方法定义了一个应用级别的中间件。这个中间件会在每个请求中被调用,输出当前的时间戳,并通过调用 next() 函数将控制权传递给下一个中间件或者路由处理函数。在 / 路由处理函数中,我们调用了 res.send() 方法来发送一个简单的响应。最后,我们使用 app.listen() 方法启动了 Express 应用程序,监听在 3000 端口上。
需要注意的是,应用级别的中间件会作用于所有的请求,因此它们通常用于处理通用的任务,例如日志记录、身份验证、跨域资源共享等。
路由级别
路由级别的中间件是一种特殊的中间件,它只会对与其对应的路由进行拦截处理。它通常会被用来对特定路由的请求进行一些额外的处理,比如权限校验、日志记录等等。
在 Express 中,可以使用 router.use() 方法来定义路由级别的中间件,这个方法的使用方式和 app.use() 方法类似,不同之处在于它只会对特定的路由生效。
const express = require('express') const router = express.Router() router.use('/users', (req, res, next) => { // 对所有以 /users 开头的请求进行权限校验 if (req.session.user) { next() } else { res.status(401).send('Unauthorized') } }) router.get('/users', (req, res) => { // 只有经过权限校验的请求才能访问这个路由 res.send('User list') }) module.exports = router //将自定义中间件封装为模块
它会对所有以 /users 开头的请求进行权限校验。如果校验失败,则返回 401 状态码;如果校验通过,则调用 next() 方法将请求传递给后面的处理函数。只有经过权限校验的请求才能访问 /users 路由。
为了方便,可以把自定义中间件封装为模块
GET接口
const express = require('express'); const apiRouter = express.Router(); apiRouter.get('/get', (req, res) => { // 1. 获取到客户端通过查询字符串,发送到服务器的数据 const query = req.query; // 2. 调用 res.send() 方法,把数据响应给客户端 res.send({ status: 0, // 状态,0 表示成功,1 表示失败 msg: 'GET 请求成功!', // 状态描述 data: query // 需要响应给客户端的具体数据,这行代码是将从客户端请求中获取的数据对象 query 作为响应数据发送给客户端。其中 query 是通过 req.query 获取的客户端通过查询字符串发送到服务器的数据。在这个例子中,响应数据中的 data 属性直接使用了从客户端获取的数据对象,因此客户端发起的请求参数会被原封不动地返回给客户端。在实际的应用中,通常会对请求参数进行处理,将处理后的数据作为响应数据返回给客户端。 }); });
POST接口
apiRouter.post('/post', (req, res) => { // 1.获取客户端提交的数据 const body = req.body; // 2.在这里对客户端提交的数据进行处理,可以调用其他模块或者服务进行处理 // 3.将处理后的数据响应给客户端 res.send({ status: 0, msg: 'POST 请求成功!', data: body }); });
CORS跨域
跨域请求
跨域请求是指浏览器从一个域名的网页去请求另一个域名的资源,例如在域名A的页面上通过ajax请求域名B的数据,由于浏览器的同源策略,这种跨域请求会被浏览器限制。在同一个域名下的请求不会受到跨域限制。
CORS 响应头部的基本语法如下:
Access-Control-Allow-Origin: <origin> | * Access-Control-Allow-Methods: <method>[, <method>]* Access-Control-Allow-Headers: <header-name>[, <header-name>]* Access-Control-Allow-Credentials: true | false Access-Control-Max-Age: <delta-seconds>
- Access-Control-Allow-Origin:指定允许的跨域请求的来源域名,可以使用通配符 * 表示允许任意域名访问。
- Access-Control-Allow-Methods:指定允许的 HTTP 请求方法,例如 GET、POST、PUT、DELETE 等。
- Access-Control-Allow-Headers:指定允许的 HTTP 请求头部信息。
- Access-Control-Allow-Credentials:表示是否允许发送 Cookie。
- Access-Control-Max-Age:指定预检请求的有效期,单位为秒。
其中,<origin> 表示允许的跨域请求来源域名,可以使用 * 表示允许任意域名访问;<method> 表示允许的 HTTP 请求方法;<header-name> 表示允许的 HTTP 请求头部信息;<delta-seconds> 表示预检请求的有效期,单位为秒。</delta-seconds></header-name></method></origin>
JSONP接口
有缺陷,仅支持GET请求
JSONP(JSON with Padding)是一种跨域请求的解决方案。由于浏览器的同源策略,不允许客户端脚本从不同域的服务器上获取数据,而 JSONP 利用了 script 标签可以跨域加载资源的特性,通过动态创建 script 标签来获取数据。
在使用 JSONP 的时候,需要服务器端提供一个回调函数名,客户端请求服务器时,将回调函数名作为查询参数传递给服务器。服务器端接到请求后,将数据包装在回调函数中返回给客户端,客户端得到响应后会自动执行该回调函数,从而实现跨域请求
在网页中使用jQuery发起JSONP请求
$.ajax({ url: "http://example.com/api/data", dataType: "jsonp", jsonp: "callback", success: function(response) { // 处理响应数据 }, error: function(xhr, status, error) { // 处理错误 } });
如有侵权请联系:admin#unsafe.sh