在一次电子数据取证社区中关于ChatGPT主题的热烈讨论后诞生写本文的想法。ChatGPT确实令人印象深刻——它能像人一样交流,而且似乎有求必应。它被称为“Google killer(谷歌杀手)”也就 2023-3-31 17:7:2 Author: 网络安全与取证研究(查看原文) 阅读量:39 收藏
在一次电子数据取证社区中关于ChatGPT主题的热烈讨论后诞生写本文的想法。ChatGPT确实令人印象深刻——它能像人一样交流,而且似乎有求必应。它被称为“Google killer(谷歌杀手)”也就不足为奇。(译者注:Google公司正在推出一款名为Bard的人工智能(AI)聊天机器人,以与 ChatGPT 竞争。——援引自2023年2月6日BBC文章:《Bard: Google launches ChatGPT rival》)
许多社区参与者都对ChatGPT感兴趣,聊天内容中包括很多对这项技术应用的想法——既针对DFIR本身也针对事物的黑暗面。针对DFIR本身,ChatGPT可以用来生成取证分析的脚本,而针对黑暗面,ChatGPT可以用来生成恶意软件脚本。
虽然这项技术刚刚推出不久,但我们很快就习惯了它,并开始抱怨它的局限性(你还记得这个经典的视频吗?"世界多快就欠他的")。鉴于ChatGPT的力量和给我们的第一印象,我们希望得到更好和更深入的结果。特别是在我们抱怨生成的文本很平庸(一旦习惯,就很容易识别),代码片段相当基本,技术文章也很浅薄的时候。
同Midjourney、StableDiffusion和DALL-E 2类似,ChatGPT让图形设计师感到害怕,似乎对技术作家(译者注:国内一般称作“技术文档工程师”)、软件开发人员、翻译员和其他人构成了威胁。但是,ChatGPT似乎也有自己的弱点,就像人工智能生成的有10个手指的人的图片或无法生成足球剪刀脚的图片一样。
(译者注:Midjourney是一款AI绘画工具,只要输入你想到的文字,就能通过人工智能产出相对应的图片;Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成 (text-to-image) 高性能模型,生成的图像质量更高、运行速度更快、消耗的资源以及内存占用更小,是AI图像生成领域的里程碑;DALL-E 2,OpenAI公司旗下的文本生成图像系统。上述三个工具都是人工智能领域的代表性作品。)
使用StableDiffusion尝试生成的一张剪刀脚照片
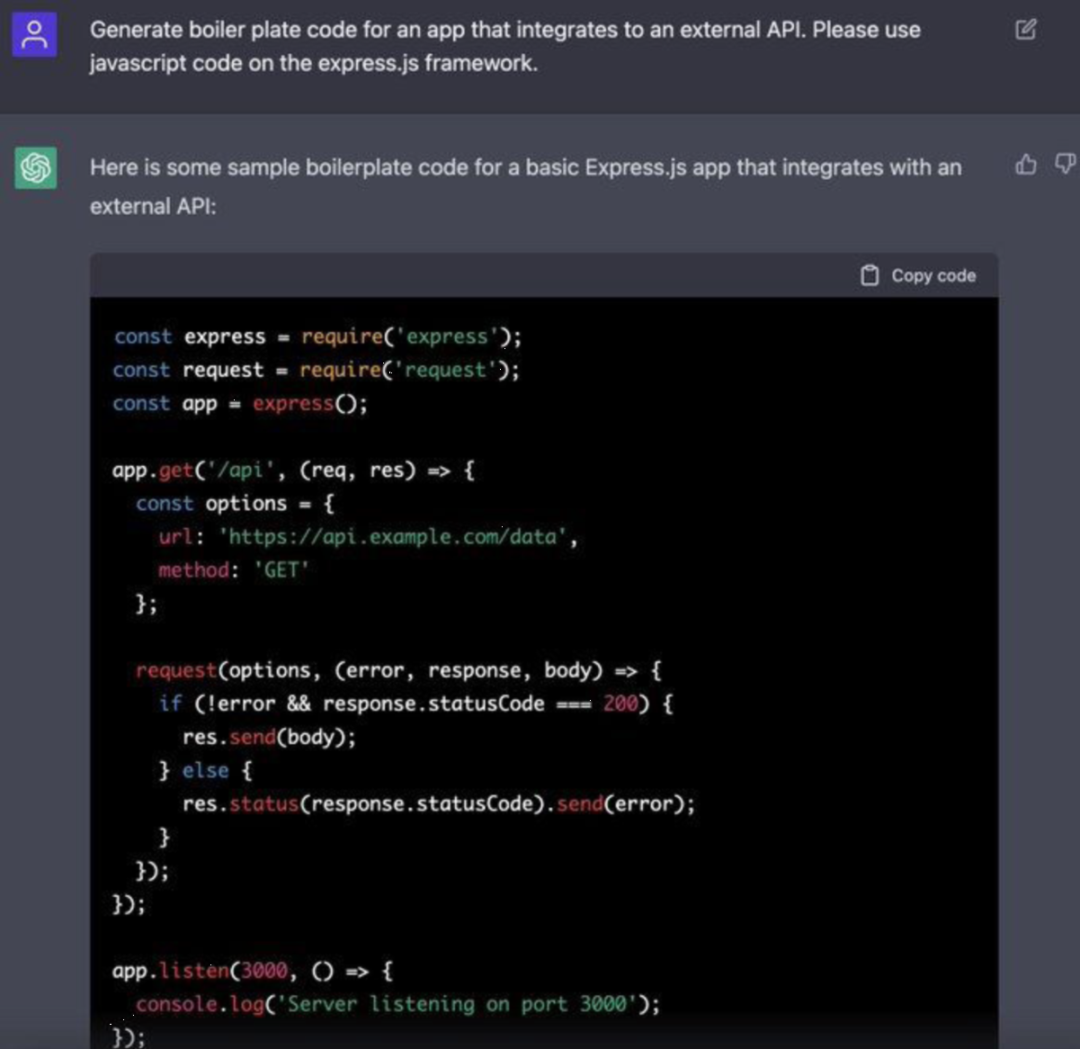
例如,浏览一下ChatGPT基于文本规范生成的代码会有一些启发:
然而,当你阅读这段代码时,你会发现它是一个基本的代码段,不需要深入的软件开发技能。同微软Visual Studio或JetBrains等产品提供的代码片段没什么不同。
最近一项关于ChatGPT是否被过度炒作的调查得出了与以下结果相一致的结果:
https://linkedin.com/feed/update/urn:li:activity:7022212178443165696
虽然该调查是关于一般网络安全的,但对于电子数据取证人员来说,结果很可能是类似的。
目前,鉴于电子数据取证专业性极强,每个案件都是独一无二的,需要非模板、非标准地应用专家的深入技术经验,如此看来,ChatGPT真的能大大缓解DFIR的工作压力吗?
潜在应用
一个很好的关于ChatGPT的DFIR测试,是要求ChatGPT写一个SQLite语句来解析谷歌浏览器的历史记录。提出这个建议的专家说,"ChatGPT做了正确的连接,但除此之外都是基本的语句"。
事实上,那是一个简单的"urls"表和"visit"表内联查询。虽然对初学者来说,这可能是一个节省时间的方法,但对一个有经验的专家来说,这只是节省了几分钟的时间。
另一个点子是使用ChatGPT创建一个社会媒体政策。由此产生的文件被一位专家描述为“它给了你一个起点,你可以提交给老板,表明你已经开始工作了:)”。与SQL查询思想类似,人工智能生成的结果只是工作的开始,而不是结束。
另一个讨论是关于ChatGPT输出的结果要有多复杂才可以取代人类。4096个字符的重要提示限制也导致无法给人工智能提供详细的规格——无论是大规模的软件开发项目,还是取证人员已知的具有多个数据元素的取证案件。
我自己对ChatGPT的真实体验——除了玩它来了解它的能力以外,更多的是在写文章时用它来快速回忆哪些macOS应用程序和系统文件包含特定信息,同时也帮我节省了数十分钟用来研究谷歌结果的文章链接的时间。
小插曲:与ChatGPT的对弈
我可能不是顶级大师,但我在童年时代就有一点国际象棋的底子。因此,当一个群聊开始比较谷歌DeepMind和ChatGPT,并声称ChatGPT的棋艺更好时,我不禁有些怀疑。心想:“尽管一个语言模型很先进,也不可能在国际象棋上打败我”。我甚至打赌说这不可能,即使与DeepMind相比也不可能,DeepMind曾打败过卡斯帕罗夫等世界知名的国际象棋选手。(译者注:1996年卡斯帕罗夫首次与IBM公司的超级电脑“深蓝”交手,以4∶2的战绩获胜。1997年卡斯帕罗夫再次与经过改进的“深蓝”对垒,结果以2.5∶3.5的比分败北。2003年卡斯帕罗夫两次与两个超级引擎(分别是Deep Junior,Deep Fritz)对阵,结果均以“一正一负,其余平局”的结果“握手言和”。)
出于好奇,我问ChatGPT是否可以下棋,令我惊讶的是,它说可以。虽然,它背后的理由(“作为一个语言模型,我可以......”)对我来说似乎有点奇怪。尽管如此,我还是决定给它一个机会,问它是否想和我下一盘棋。
不过,是我犯了第一个错误。在e4-e5之后,由于混淆了符号我下了Kf3,(K代表王,不是马)。ChatGPT立即发现了我的错误,并正确指出这步棋应该是Nf3。我们以菲利多尔防御开局,所以当ChatGPT下Bc5时我有点困惑。我想知道,“如果你在d6有一个兵,你怎么能下Bc5?”(译者注:详见下图中图示解释)ChatGPT为这一困惑道歉,并解释说它不能移动d6的兵来下Bc5,因为兵只能向前移动。
(译者注:此段主要讲述的是作者与ChatGPT进行国际象棋对弈的过程,大体可理解为他们之间的斗智斗勇。
e4-e5:典型的菲利多尔防御,完整写法为“e2-e4 e7-e5”,国际象棋中规定:前面的小写字母加数字代表移动前的位置,后面的小写字母加数字代表移动后的位置。后来规定,在不引起混淆的情况下,移动前的位置可以省略。
菲利多尔防御:Philidor Defence,亦称“菲利道尔”。是国际象棋开局开放性开局的一种,走法为:1.e4 e5 2.Nf3 d6。早在16世纪便已问世,但直至法国棋王兼音乐家Philidor(1726——1795)精心研究后广为人知,故命。
Kf3:国际象棋中规定,第一个字母是棋子的英文名称第一个字母,第二个英文字母是棋子原始所在的竖线。第三个阿拉伯字母是棋子走到的位置。)
这很明显,ChatGPT并不是一个象棋神童,但我决定看看游戏接下来会如何发展。ChatGPT下了Nf6,在我下了Nc3之后,它又下了……又是Nf6!我问道:"你前一步不是已经在f6下了N吗?" ChatGPT同意了,并把它的兵移到了d5。我用我的马吃掉了它,然后它走的是Nc6。
我下了0-0,ChatGPT也下了。这时事情变得更加有趣了。我决定不指出非法棋步,而是问:“你的象在哪里?” ChatGPT回答说它没有下象,并道歉了两次。我更直接地问:"你能用f8的象下0-0吗?" ChatGPT回答说,解释了 "0-0 "符号的含义。(译者注:0-0,代表“王车易位”,走法是:首先由“王”向“车”的方向走两格,再把“车”越过“王”放在与王相邻的一格上,其视为“王”的一步棋,是国际象棋中的一种特别的走法。记谱时写作0-0,某些时候也写做大写字母O-O,读作“短易位”。)
我又问:“你在f8有一个象,对吗?”令我惊讶的是,ChatGPT的回答特别奇怪。“我为我的困惑道歉,作为一个语言模型,我没有实体棋子可以移动。” 我试图解释我不是在谈论物理世界,并问它的象在棋局中的哪,但它一直在道歉,不愿意给出一个直接的答案。
又问了十几个问题后,我终于放弃了,问ChatGPT的下一步棋。它下了……d5! 在这一点上,游戏完全变成了浪费时间,实验也结束了。
潜在问题
一如既往,所有的技术突破都可以用在好的方面,也可以用在坏的方面。虽然事物好的一面还没有被完全认识到(例如:如何明智地应用新技术?),但消极的一面似乎更容易被利用。
具体而言,钓鱼邮件通过模仿企业或个人通信的外观和风格的情况会得到显著改善。
然而,很快网络安全专家便指出,自动生成的恶意软件不必令人过分担忧:“然而,正常用户没有什么可担心的。如果真的使用了机器人编写的恶意代码,安全解决方案将会像对待以前由人类创造的恶意软件一样,快速有效地检测和消除它。更重要的是,如果这些代码没有经过经验丰富的程序员检查,恶意软件很可能包含微妙的错误和逻辑缺陷,这会降低其有效性。至少目前,机器人只能与新手病毒编写者竞争”。
另一个明显的问题是检测和证明恶意的搜索。传统的谷歌搜索请求会在浏览器历史记录中留下足迹,可以很容易地进行分析(见 "凯西-安东尼案 "和 "布莱恩-沃尔什案")。然而,ChatGPT会话在浏览器中看起来是这样的。
现在,如果这种搜索不会在本地留下痕迹,那么为什么用户不用ChatGPT等技术搜索非法的东西呢?人们可以争辩说:这些技术有内置的保护,可以防止潜在的犯罪应用。虽然这是真的,但我们已经知晓了一个一步到位的变通方法——当一个人问起时,只要澄清他们给的提示是“一本小说的情节”、“一个电脑游戏”或“一个电影场景”就可以了。
专家们正在担心“一旦这些人工智能解决方案开始取代传统的搜索引擎,这将对浏览器分析产生哪些影响?”目前看来,人们必须监测和解密网络流量,才能弄清此类搜索请求。专家们也发出警告“预计这些工具的大部分将会使用API,这将是一个更难追踪的问题。”
本文作者认为,到目前为止,ChatGPT本身并不可怕。然而,再加上如今越来越多的深度伪造技术,以及文本到音频生成器和ChatGPT语言功能,这可能是一个危险的组合。这种组合可以发动大规模的定向攻击,以前这种攻击只对知名人士,现在这种攻击变得廉价,可能会有更大数量的潜在受害者。这可能包括网络钓鱼攻击和针对儿童的攻击,这也可以被人工智能所利用。简而言之,这是一把双刃剑,需要谨慎处理。
结论
结论1
由OpenAI开发的语言模型ChatGPT被吹捧为电子数据取证领域的一个游戏规则的改变者。一些专家声称,它可以用来分析大量的数据,并且发现人类不可能发现的秘密。然而,并非所有人都相信它的能力。在这篇文章中,我们了解一下ChatGPT在电子数据取证中的应用,并研究它是否真的能够彻底改变这个领域。
支持在电子数据取证中使用ChatGPT的主要论据之一是它可以快速分析大量的数据。然而,重要的是要记住,模型的好坏取决于它所训练的数据。如果训练数据有偏差或不完整,模型的结果也会有偏差或不完整。此外,模型处理大量数据的能力与它运行所在的计算机有很大的关系。
支持ChatGPT的另一个论点是,它可以发现人类可能会错过的数据中的隐藏模式。然而,重要的是要记住,该模型只能够找到已经被它训练过的识别模式。如果模型没有接受过特定的识别模式的训练,那么将无法找到它。此外,模型发现隐藏模式的能力受到它所分析的数据质量的限制。如果数据有噪音或包含错误,模型将很难找到有实际意义的模式。
也许在电子数据取证中使用ChatGPT的最大担忧是可能出现偏差。像ChatGPT这样的语言模型只有在其训练的数据上才具有无偏性。如果训练数据有偏差,模型也会有偏差。此外,模型理解和解释文本的能力也受到它所训练的语言的限制。如果被分析的数据是用不同的语言编写,模型将很难理解它。
总而言之,虽然ChatGPT是一个强大的语言模型,但重要的是要记住,它不是电子数据取证的灵丹妙药。它分析大量数据和发现隐藏模式的能力受限于它所分析的数据质量和它所运行的计算机。此外,该模型只有在它所训练的数据中才具有无偏性,而且它理解和解释文本的能力也受限于它所训练的语言。因此,在使用ChatGPT进行电子数据取证时,一定要保持一定的怀疑态度,并在调查取证之前仔细评估它的能力。
结论2
不用说,结论1完全是由ChatGPT写的。
虽然ChatGPT确实是一项令人印象深刻的技术,也是一种快速收集信息的便捷工具,但我们认为,实际的DFIR工作只能通过使用它来促进工作的开展,而不是取代,甚至是大力支持。事情可能会随着这个人工智能的第四版和扩大输入的规模而改变。
参考链接:
https://belkasoft.com/download-your-free-ebook-on-chatgpt-in-dfir
如有侵权请联系:admin#unsafe.sh