1 vcluster 介绍虚拟集群(virtual cluster, 简称 vcluster)是在常规的 Kubernetes 集群之上运行的一个功能齐全,轻量级,隔离性良好的 Kubernetes 2023-3-8 08:8:8 Author: Docker中文社区(查看原文) 阅读量:38 收藏
1 vcluster 介绍
虚拟集群(virtual cluster, 简称 vcluster)是在常规的 Kubernetes 集群之上运行的一个功能齐全,轻量级,隔离性良好的 Kubernetes 集群。虚拟集群的核心思想是提供运行在“真实”Kubernetes 集群之上隔离的 Kubernetes 控制平面(例如 API Server)。与完全独立的“真实“集群相比,虚拟集群没有自己的工作节点或者网络,工作负载实际上还是在底层宿主集群上调度。
默认情况下,vcluster 作为一个包含 2 个容器的 Pod 运行。(由 StatefulSet 调度),包含:
控制平面:包含 API Server, Controller Manager, 数据存储。默认情况下使用 sqlite 作为数据存储,并且使用 k3s 运行 API Server 和 Controller Manager。 Syncer 同步器:vcluster 本身并没有实际的工作节点或者网络,它使用 syncer 将虚拟集群中创建的资源复制到底层宿主集群中。
vcluster 中的资源分为两种:
高级(纯虚拟):这部分资源只存在于虚拟集群中,例如 Deployment、StatefulSet、CRD 等。 低级(同步资源):一些底层的 Kubernetes 资源需要同步到底层宿主集群中,例如 Pod、Service、Persistent Volume 等等。
vcluster 有以下特点:
可使用集群层面的资源:在虚拟集群中允许租户使用 CRD、Namespaces、ClusterRole 等资源,这比通过命名空间隔离的方式功能更加强大。 轻量级:vcluster 默认使用 k3s 构建虚拟集群,k3s 是一个经过认证的轻量级 Kubernetes 发行版,100% 兼容 Kubernetes API,它将 Kubernetes 的组件编译为小于 100 MB 的单个二进制文件,默认禁用所有不需要的 Kubernetes 功能,例如 Pod 调度器或某些控制器,这使得 k3s 的内存使用仅仅为常规 k8s 的一半。另外 vcluster 还支持其他发行版,例如 k0s 或常规 k8s。 经济高效:创建虚拟集群比“真正的“集群更加便宜和高效,最少只需要创建单个 vcluster Pod(包含 API server, syncer, 后端存储)。 良好的隔离性:每个虚拟集群有独立的控制平面和接入点,并且可以对虚拟集群的网络和工作负载进行限制。 没有性能下降:Pod 实际上被部署在底层主机集群中,因此它们在运行时根本不会受到性能影响。 减少宿主集群上的开销:高级资源(例如 Deployment、StatefulSet、CRD )仅保留在虚拟集群中而不会到达底层宿主集群,从而大大减少对底层宿主集群 Kubernetes API Server 的请求数量。 易于部署 :vcluster 可以通过 vcluster CLI、helm、kubectl、cluster api、Argo CD 等多种工具进行部署(它本质上只是一个 StatefulSet 资源)。 单一命名空间封装:每个虚拟集群及其所有的工作负载都位于底层宿主集群的单一命名空间内。 灵活和多功能:vcluster 支持不同的后端存储(例如 sqlite、mysql、postgresql 和 etcd)、插件,允许自定义资源的同步策略,你甚至还可以在 vcluster 中部署 vcluster。
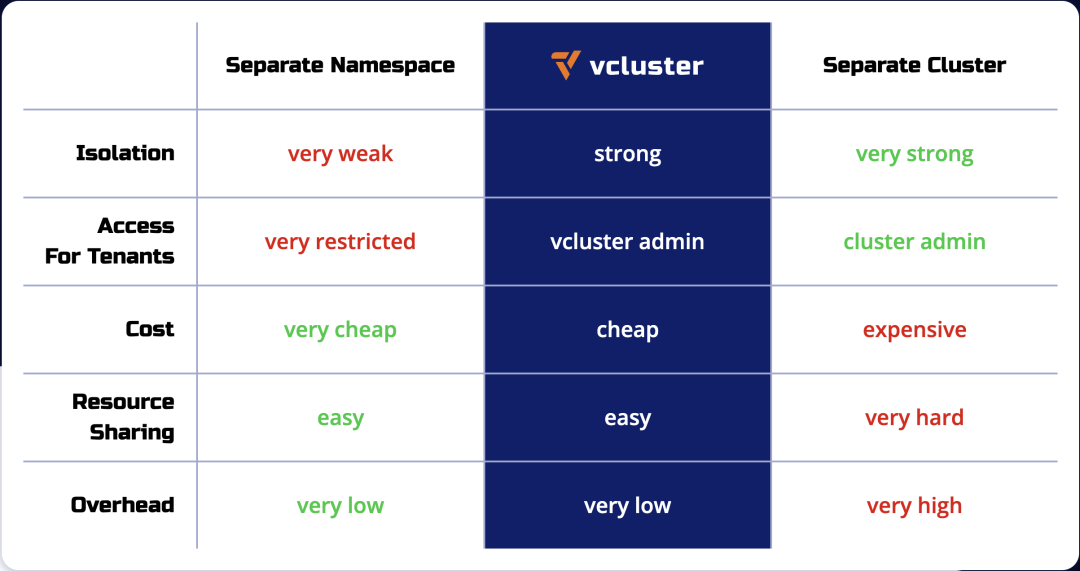
使用虚拟集群相比创建单独的 Kubernetes 集群更经济高效,同时相较于命名空间的隔离方式则能够提供更好的多租户和隔离特性。下表对命名空间、vcluster 和单独的 Kubernetes 集群 3 种方式在隔离性、多租户访问、成本等方面进行了对比。
2 vcluster 快速上手
2.1 准备持久化存储
创建虚拟集群默认需要使用持久化存储,如果集群中已经配置好了默认的持久化存储,可以跳过此步骤。
执行以下命令,安装 OpenEBS。
kubectl apply -f https://openebs.github.io/charts/openebs-operator.yaml
设置 StorageClass openebs-hostpath 作为默认的 StorageClass。
kubectl patch storageclass openebs-hostpath -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
确认 OpenEBS 各组件正常运行。
2.2 安装 vcluster CLI
参照 Install vcluster CLI[1] 根据对应的操作系统版本安装 vcluster CLI 工具。
2.3 创建虚拟集群
执行以下命令创建一个名为 my-vcluster 的虚拟集群,默认会在 vcluster-<vcluster-name> (本例中是 vcluster-my-vcluster)Namespace 中创建虚拟集群,也可以使用 -n 参数指定创建虚拟集群的 Namespace。
vcluster create my-vcluster
虚拟集群创建成功后,vcluster 会自动帮我们通过端口转发连接到虚拟集群。如果使用 kubectl 或者 helm 的方式安装虚拟集群,则可以使用 vcluster connect <cluster-name> 命令手动连接到虚拟集群。
打开另一个窗口执行 kubectl 命令查看 Pod 和 Namespace,可以看到这是一个全新的集群,并不能看到虚拟集群所属的 vcluster-my-vcluster Namespace,因为该 Namespace 存在于宿主集群中。
2.4 在虚拟集群中创建资源
在虚拟集群中创建一个 Namespace,并在里面部署一个 nginx Deployment。
kubectl create namespace demo-nginx
kubectl create deployment nginx-deployment -n demo-nginx --image=nginx
查看创建的 Pod。
> kubectl get pod -n demo-nginx
NAME READY STATUS RESTARTS AGE
nginx-deployment-5fbdf85c67-42rmp 1/1 Running 0 13s
键盘按 ctrl + c 断开和虚拟集群的连接,kubectl 的上下文会自动切换回宿主集群。
在宿主集群查看 Namespace,并没有看到在虚拟集群中创建的 demo-nginx Namespace,因为该 Namespace 只存在于虚拟集群中。
在宿主集群同样也看不到 nginx-deployment。
Pod 在虚拟集群所属的 Namespace 中是存在的,vcluster 中有一个 syncer 控制器,主要负责将虚拟集群中的资源同步到底层宿主集群中,并通过一定的规则对资源的名称进行重写,例如在虚拟集群中的 Pod 最终在宿主集群中会根据 <pod-name>-x-<namespace>-x-<vcluster-name> 的规则进行重写。Pod 的实际调度默认情况下还是依靠宿主集群上的调度器完成的。
2.5 清理虚拟集群
使用 vcluster delete 命令可以删除虚拟集群。
vcluster delete my-vcluster
3 暴露 vcluster
默认情况下,vcluster 只能通过远程集群中的端口转发进行访问。要想直接访问虚拟集群可以选择通过使用 LoadBalancer 或者 NodePort 类型的 Service 将虚拟集群暴露到集群外。
最简单的方式就是在创建虚拟集群的时候指定 --expose 参数,vcluster 会创建 LoadBalancer 类型的 Service 暴露虚拟集群(前提要有公有云托管的 Kubernetes 集群支持 LoadBalancer)。等待虚拟集群创建完成后,vcluster 会自动帮我们切换到虚拟集群的 kubeconfig context 中,此时可以直接通过 kubectl 命令行访问虚拟集群。
vcluster create my-vcluster --expose
你也可以手动创建 Service 来暴露 vcluster,更多方式参见 Exposing vcluster (ingress etc.)[2]。
4 网络 & DNS 解析
每个虚拟集群都有自己独立的 DNS 服务器(CoreDNS),为虚拟集群中的 Service 提供 DNS 解析。vcluster syncer 会确保同步的 Service 在虚拟集群中的名称满足常规 Kubernetes 集群 DNS 名称的直观逻辑,而这些 Service 实际上映射到底层宿主集群中重写的 Service 上。
在虚拟集群中的 Pod 访问本虚拟集群中的 Service 就像在常规 Kubernetes 集群中一样,没有什么差别。但是如果要在虚拟集群和宿主集群之间进行通信,那可能就需要做一些设置。
创建一个虚拟集群用于测试。(在宿主集群 context 中执行)
vcluster create net-vcluster
4.1 虚拟集群和宿主集群之间通过 IP 地址通信
在虚拟集群中创建的 Pod 会被 vcluster syncer 同步到宿主集群中,因此 Pod 实际上运行在底层宿主集群中。这意味着这些 Pod 具有常规的集群内部 IP 地址,并且可以通过 IP 地址相互通信。
在虚拟集群中创建一个 Pod。(在虚拟集群 context 中执行)。切换 context 可以使用 kubectl config use-context <context-name> 命令,context 可以通过 kubectl config get-context 命令获取。
kubectl create deployment nettool-virtual --image=cr7258/nettool:v1
在宿主集群中创建一个 Pod。(在宿主集群 context 中执行)
kubectl create deployment nettool-host --image=cr7258/nettool:v1
查看在虚拟集群和宿主集群中创建的 Pod 的 IP 地址。(在宿主集群 context 中执行)
kubectl get pod -o wide
kubectl get pod -n vcluster-net-vcluster -o wide
两个 Pod 之间互相 Ping 测试,网络之间可以互通。(在宿主集群 context 中执行)
由此可见,虚拟集群和宿主集群之间的 Pod 以及 Service 资源默认情况下都可以直接通过 IP 地址互相访问。
4.2 虚拟集群和宿主集群之间通过域名通信
在虚拟集群的 Pod 无法直接通过 Service 名称访问宿主集群中的 Service,因为在虚拟集群中对宿主集群中的 Service 不可见;同样在宿主集群中的 Pod 也无法通过 Service 名称访问虚拟集群中的 Service(宿主集群中可以看到虚拟集群的 syncer 重写后的 Service)。
vcluster 提供了将 Service 从虚拟集群中映射到宿主集群的功能,反之亦然。
将虚拟集群和宿主集群的 Deployment 分别通过 Service 进行暴露。
# 在宿主集群 context 中执行
kubectl expose deployment nettool-host --port=80 --target-port=80# 在虚拟集群 context 中执行
kubectl expose deployment nettool-virtual --port=80 --target-port=80
4.2.1 将宿主集群 Service 映射到虚拟集群中
创建一个配置文件 host-to-vcluster.yaml,声明将宿主集群 default Namespace 中的 nettool-host Service 映射到虚拟集群的 default Namespace 中的 nettool-host Service。
# host-to-vcluster.yaml
mapServices:
fromHost:
- from: default/nettool-host
to: default/nettool-host
执行以下命令,更新虚拟集群配置。(在宿主集群 context 中执行)
vcluster create net-vcluster --upgrade -f host-to-vcluster.yaml
此时在虚拟集群中就能看到在宿主集群中的 nettool-host Service 了。(在虚拟集群 context 中执行)
使用虚拟集群的 Pod 访问宿主集群的 nettool-host Service。
# 在虚拟集群 context 中执行
> kubectl exec -it deployments/nettool-virtual -- curl nettool-host# 返回结果
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
4.4 将虚拟集群 Service 映射到宿主集群中
创建一个配置文件 vcluster-to-host.yaml,声明将虚拟集群 default Namespace 中的 nettool-virtual Service 映射到宿主集群 vcluster-net-vcluster Namespace(虚拟集群所在的 Namespace) 的 nettool-virtual Service。
# vcluster-to-host.yaml
mapServices:
fromVirtual:
- from: default/nettool-virtual
to: nettool-virtual
执行以下命令,更新虚拟集群配置。(在宿主集群 context 中执行)
vcluster create net-vcluster --upgrade -f vcluster-to-host.yaml
使用宿主集群的 Pod 访问虚拟集群的 nettool-virtual Service。
# 在宿主集群 context 中执行
> kubectl exec -it deployments/nettool-host -- curl nettool-virtual.vcluster-net-vcluster# 返回结果
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
实验完毕后,执行以下命令清理虚拟集群。(在宿主集群 context 中执行)
vcluster delete net-vcluster
5 暂停 & 恢复虚拟集群
当虚拟集群暂时没有用时,我们可以选择暂停虚拟集群,这会将该虚拟集群控制平面的副本数缩减为 0,并删除该虚拟集群上运行的所有工作负载;当需要用到时,再进行恢复,这对于节省虚拟集群的工作负载使用的计算资源很有用。
创建一个虚拟集群用于测试。(在宿主集群 context 中执行)
vcluster create recover-vcluster
查看当前虚拟集群运行的工作负载:(在宿主集群 context 中执行)
kubectl get all -n vcluster-recover-vcluster
coredns Pod 会通过 syncer 从虚拟集群同步到宿主集群中。 recover-vcluster 以 StatefulSet 的方式部署,用于管理虚拟集群。
5.1 暂停虚拟集群
执行以下命令,暂停虚拟集群。会将 vcluster 的 StatefulSet 的副本数缩减为 0,并删除 vcluster 创建的所有工作负载(本示例中是 coredns Pod)。(在宿主集群 context 中执行)
vcluster pause recover-vcluster
5.2 恢复虚拟集群
执行以下命令,恢复虚拟集群。会将 vcluster 的 StatefulSet 的副本数恢复为原样,并且 vcluster syncer 将重新创建相应的工作负载。(在宿主集群 context 中执行)
vcluster resume recover-vcluster
查看虚拟集群相关的工作负载。(在宿主集群 context 中执行)
kubectl get all -n vcluster-recover-vcluster
实验完毕后,执行以下命令清理虚拟集群。(在宿主集群 context 中执行)
vcluster delete recover-vcluster
6 存储
接下来将介绍在虚拟集群中的 Pod 如何使用 Persistent Volume 来保存持久化数据。
默认情况下 vcluster 不会将 Persistent Volume 和 StorageClasses 同步到宿主集群中,创建配置文件 sync-storage.yaml,声明同步 Persistent Volume 和 StorageClasses 资源。
# sync-storage.yaml
sync:
persistentvolumes:
enabled: true
# If you want to create custom storage classes
# inside the vcluster.
storageclasses:
enabled: true
执行以下命令,根据上述配置文件创建虚拟集群。(在宿主集群 context 中执行)
vcluster create storage-vcluster -f sync-storage.yaml
6.1 创建 StorageClass
在 2.1 小节中我们部署了 OpenEBS 动态供应存储卷,这里我们继续利用 OpenEBS。创建一个 StorageClass,指定 OpenEBS 作为持久卷的 Provisioner,存储路径设置为 /var/my-local-hostpath。
# sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: my-local-hostpath
annotations:
openebs.io/cas-type: local
cas.openebs.io/config: |
- name: StorageType
value: hostpath
- name: BasePath
value: /var/my-local-hostpath # 存储路径
provisioner: openebs.io/local # 指定 OpenEBS 作为持久卷的 Provisioner
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
在虚拟集群中创建 StorageClass。(在虚拟集群 context 中执行)
kubectl apply -f sc.yaml
vcluster 会在宿主集群中创建真正的 StorageClass,会将 my-local-hostpath StorageClass 以某种格式进行重写。(在宿主集群 context 中执行)
kubectl get sc | grep my-local-hostpath
6.2 创建 PersistentVolumeClaim
# pvc-sc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-persistent-volume-claim
spec:
storageClassName: my-local-hostpath # 指定 StorageClass
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
在虚拟集群中创建 PersistentVolumeClaim。(在虚拟集群 context 中执行)
kubectl apply -f pvc-sc.yaml
由于我们创建的 StorageClass 将 volumeBindingMode 参数设置为 WaitForFirstConsumer,表示当 PVC 被 Pod 使用时,才触发 PV 和后端存储的创建,同时实现 PVC/PV 的绑定,由于当前还没有 Pod 使用该 PVC,因此 PVC 当前处于 Pending 状态。如果要让 PVC 立即和 PV 进行绑定,可以在 StorageClass 中将 volumeBindingMode 参数设置为 Immediate。
查看宿主集群中真正创建的 PVC。(在宿主集群 context 中执行)
kubectl get pvc -n vcluster-storage-vcluster
6.3 创建 Pod 消费 PersistentVolumeClaim
# pod-sc.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-pod
image: nginx
volumeMounts:
- name: config
mountPath: /usr/share/nginx/html
subPath: html
volumes:
- name: config
persistentVolumeClaim:
claimName: my-persistent-volume-claim # 消费 PVC
在虚拟集群中创建 Pod。(在虚拟集群 context 中执行)
kubectl apply -f pvc-sc.yaml
可以看到当前在虚拟集群中的 Pod 已经成功 Running,并且 PVC 也绑定了 PV。(在虚拟集群 context 中执行)
实验完毕后,执行以下命令清理虚拟集群。(在宿主集群 context 中执行)
vcluster delete storage-vcluster
7 高可用
vcluster 支持通过创建 Vanilla k8s (常规的 Kubernetes 发行版)支持高可用,vcluster 当前不支持单个二进制发行版的高可用(例如 k0s 和 k3s)。
创建配置文件 ha.yaml ,设置相关组件的副本数。由于国内无法直接拉去 gcr 的镜像,这里我提前将相关镜像拉取到我的 Docker Hub 上,大家可以直接使用。
# ha.yaml# Enable HA mode
enableHA: true
# Scale up syncer replicas
syncer:
replicas: 3
# Scale up etcd
etcd:
image: cr7258/k8s.gcr.io.etcd:3.5.4-0
replicas: 3
storage:
# If this is disabled, vcluster will use an emptyDir instead
# of a PersistentVolumeClaim
persistence: false
# Scale up controller manager
controller:
image: cr7258/k8s.gcr.io.kube-controller-manager:v1.25.0
replicas: 3
# Scale up api server
api:
image: cr7258/k8s.gcr.io.kube-apiserver:v1.25.0
replicas: 3
# Scale up DNS server
coredns:
replicas: 3
执行以下命令创建虚拟集群:(在宿主集群 context 中执行)
--connect=false:表示创建完虚拟集群后,不连接到虚拟集群。--distro:参数可以指定创建虚拟集群使用的 Kubernetes 发行版,默认使用 K3S 作为虚拟集群,这里我们指定使用 Vanilla k8s (常规的 Kubernetes 发行版)来部署虚拟集群。
vcluster create ha-vcluster --connect=false --distro k8s -f ha.yaml
查看创建的虚拟集群控制平面 Pod。可以看到虚拟集群控制平面的组件都有 3 个。(在宿主集群 context 中执行)
kubectl get pod -n vcluster-ha-vcluster
实验完毕后,执行以下命令清理虚拟集群。(在宿主集群 context 中执行)
vcluster delete ha-vcluster
8 Pod 调度
默认情况下,vcluster 将复用宿主集群的调度器来调度工作负载。这样可以节省计算资源,但也有一些限制:
1.在虚拟集群内标记节点对调度没有影响。 2.虚拟集群内的排空或污染节点对调度没有影响。 3.不能在 vcluster 中使用自定义调度程序。
某些情况下,你可能希望通过标记虚拟集群内的节点,以通过亲和性或拓扑分布等功能控制工作负载调度。vcluster 支持在虚拟集群内运行单独的调度器,而不是复用宿主集群的调度器。
创建配置文件 schedule.yaml,在虚拟集群中启用调度器,并设置节点同步模式为 Real Nodes All 模式(或者 Real Nodes Label Selector 模式)。vcluster 的节点有以下几种模式:
Fake Nodes(默认):在虚拟集群中创建的节点信息和真实宿主集群是不一致的(假节点),并且如果虚拟集群中没有 Pod 调度到该节点,则会删除该节点。 Real Nodes:在虚拟集群中创建的节点的信息和真实宿主集群是一致的,如果虚拟集群中没有 Pod 调度到该节点,则会删除该节点。此模式需要设置 .sync.nodes.enabled: true。Real Nodes All:在虚拟集群中创建的节点的信息和真实宿主集群是一致的,并始终将宿主集群中的所有节点同步到虚拟集群中,无论虚拟集群中是否有 Pod 调度到该节点。使用此模式需要设置 .sync.nodes.enabled: true和.sync.nodes.syncAllNodes: true。Real Nodes Label Selector:通过标签选择器仅同步指定的节点到虚拟集群中。此模式需要设置 .sync.nodes.enabled: true和.sync.nodes.nodeSelector: "label1=value1"。
# schedule.yaml
sync:
nodes:
enableScheduler: true # 在虚拟集群中启用调度器
# 设置节点同步模式为 Real Nodes All
enabled: true
syncAllNodes: true
执行以下命令创建虚拟集群。(在宿主集群 context 中执行)
vcluster create schedule-vcluster -f schedule.yaml
查看虚拟集群的节点,可以看到节点信息和宿主集群一致,当前使用的是 AWS EKS 的节点。(在虚拟集群 context 中执行)
> kubectl get node
NAME STATUS ROLES AGE VERSION
ip-192-168-29-123.ec2.internal Ready <none> 20m v1.23.9-eks-ba74326
ip-192-168-44-166.ec2.internal Ready <none> 20m v1.23.9-eks-ba74326
给节点 ip-192-168-44-166.ec2.internal 打上标签 disktype=ssd。(在虚拟集群 context 中执行)
kubectl label nodes ip-192-168-44-166.ec2.internal disktype=ssd
创建 Deployment,通过 nodeSelector 参数根据标签选择节点,将 6 个 Pod 都分配到节点 ip-192-168-44-166.ec2.internal 上。
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 6
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
nodeSelector:
disktype: ssd
执行以下命令创建 Deployment。(在虚拟集群 context 中执行)
kubectl apply -f deployment.yaml
查看 Pod 的分布情况,可以看到所有的 Pod 都调度到了节点 ip-192-168-44-166.ec2.internal 上了。(在虚拟集群 context 中执行)
kubectl get pod -o wide
实验完毕后,执行以下命令清理虚拟集群。(在宿主集群 context 中执行)
vcluster delete schedule-vcluster
9 隔离模式
默认情况下,vcluster 不会对虚拟集群中的网络和工作负载进行隔离。在虚拟集群中创建的 Pod 虽然无法通过 DNS 名称访问宿主集群,但是仍然可以直接通过 IP 地址来访问宿主集群(参见 4.1 小节);并且在虚拟集群的工作负载并没使用资源的限制。
我们可以在创建虚拟集群时指定 --isolate 参数,以隔离模式创建虚拟集群,该模式会对虚拟集群的网络和工作负载增加一些限制:(在宿主集群 context 中执行)
在 vcluster syncer 强制执行 Pod 安全标准,例如限制创建特权容器或挂载主机路径的 Pod。 为虚拟集群设置 ResourceQuota 和 LimitRange 来限制资源的使用。 为虚拟集群设置 NetworkPolicy 限制虚拟集群中的工作负载对外的访问。
vcluster create isolate-vcluster --isolate
9.1 网络隔离
接下来验证网络的隔离性。在虚拟集群中创建一个 Pod。(在虚拟集群 context 中执行)
kubectl create deployment nettool-virtual --image=cr7258/nettool:v1
在宿主集群中创建一个 Pod。(在宿主集群 context 中执行)
kubectl create deployment nettool-host --image=cr7258/nettool:v1
查看在虚拟集群和宿主集群中创建的 Pod 的 IP 地址。(在宿主集群 context 中执行)
kubectl get pod -o wide
kubectl get pod -n vcluster-isolate-vcluster -o wide
两个 Pod 之间互相 Ping 测试,可以看到虚拟集群无法通过 IP 地址访问宿主集群,但是宿主集群可以访问虚拟集群。(在宿主集群 context 中执行)
让我们看看在宿主集群中创建的 NetworkPolicy(在虚拟集群中是没有 NetworkPolicy 的)。(在宿主集群 context 中执行)
kubectl get networkpolicies -n vcluster-isolate-vcluster
这两条 NetworkPolicy 的 YAML 文件如下所示,可以看到 NetworkPolicy 对虚拟集群的 Egress 方向的流量进行了限制,确保虚拟集群中的工作负载无法主动访问宿主集群或者其他虚拟集群。
# 允许虚拟集群的控制平面访问宿主集群中的 CoreDNS 以及 API Server
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
meta.helm.sh/release-name: isolate-vcluster
meta.helm.sh/release-namespace: vcluster-isolate-vcluster
labels:
app.kubernetes.io/managed-by: Helm
name: isolate-vcluster-control-plane
namespace: vcluster-isolate-vcluster
spec:
egress:
- ports:
- port: 443
protocol: TCP
- port: 8443
protocol: TCP
- port: 6443
protocol: TCP
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
podSelector:
matchLabels:
release: isolate-vcluster
policyTypes:
- Egress# 允许虚拟集群中的工作负载访问虚拟集群的控制平面,以及公网 IP(ipBlock 排除了内网 IP)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
meta.helm.sh/release-name: isolate-vcluster
meta.helm.sh/release-namespace: vcluster-isolate-vcluster
labels:
app.kubernetes.io/managed-by: Helm
name: isolate-vcluster-workloads
namespace: vcluster-isolate-vcluster
spec:
egress:
- ports:
- port: 443
protocol: TCP
- port: 8443
protocol: TCP
to:
- podSelector:
matchLabels:
release: isolate-vcluster
- ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
- to:
- podSelector:
matchLabels:
vcluster.loft.sh/managed-by: isolate-vcluster
- ipBlock:
cidr: 0.0.0.0/0
except:
- 100.64.0.0/10
- 127.0.0.0/8
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
podSelector:
matchLabels:
vcluster.loft.sh/managed-by: isolate-vcluster
policyTypes:
- Egress
为了更直观地查看 Networkpolicy,我们可以借助该网站:https://orca.tufin.io/netpol/ ,黏贴上述两条 Networkpolicy 查看即可。
9.2 资源限制
vcluster 也会在虚拟集群所在的 Namespace 创建 ResourceQuota 和 LimitRange 来限制资源的使用。
其中 ResourceQuota 用于控制整个虚拟集群消耗宿主集群的资源上限。默认创建的 ResourceQuota 如下所示,限制了虚拟集群最多创建 100 个 Configmap,40 个 Endpoints,最多使用 40 Gi 内存,最多使用 10 核 CPU 等等...
apiVersion: v1
kind: ResourceQuota
metadata:
annotations:
meta.helm.sh/release-name: isolate-vcluster
meta.helm.sh/release-namespace: vcluster-isolate-vcluster
labels:
app.kubernetes.io/managed-by: Helm
name: isolate-vcluster-quota
namespace: vcluster-isolate-vcluster
spec:
hard:
count/configmaps: "100"
count/endpoints: "40"
count/persistentvolumeclaims: "20"
count/pods: "20"
count/secrets: "100"
count/services: "20"
limits.cpu: "20"
limits.ephemeral-storage: 160Gi
limits.memory: 40Gi
requests.cpu: "10"
requests.ephemeral-storage: 60Gi
requests.memory: 20Gi
requests.storage: 100Gi
services.loadbalancers: "1"
services.nodeports: "0"
LimitRange 用于控制每个 Pod 申请资源的上限(当创建的 Pod 没有指定 resources.requests和resources.limits参数时会应用 LimitRange 的设置)。默认创建的 LimitRange 如下所示。
apiVersion: v1
kind: LimitRange
metadata:
annotations:
meta.helm.sh/release-name: isolate-vcluster
meta.helm.sh/release-namespace: vcluster-isolate-vcluster
labels:
app.kubernetes.io/managed-by: Helm
name: isolate-vcluster-limit-range
namespace: vcluster-isolate-vcluster
spec:
limits:
- default:
cpu: "1"
ephemeral-storage: 8Gi
memory: 512Mi
defaultRequest:
cpu: 100m
ephemeral-storage: 3Gi
memory: 128Mi
type: Container
实验完毕后,执行以下命令清理虚拟集群。(在宿主集群 context 中执行)
vcluster delete isolate-vcluster
10 参考资料
[1] Install vcluster CLI: https://www.vcluster.com/docs/getting-started/setup [2] Exposing vcluster (ingress etc.): https://www.vcluster.com/docs/operator/external-access [3] vcluster: https://www.vcluster.com [4] 轻量级 Kubernetes 多租户方案的探索与实践: https://juejin.cn/post/7090010143672238094#heading-0 [5] Virtual Cluster 基于集群视图的 K8s 多租户机制: https://www.infoq.cn/article/fsmwwgyknsgwpegjho4g
《Docker中Image、Container与Volume的迁移》
免责声明:本文内容来源于网络,所载内容仅供参考。转载仅为学习和交流之目的,如无意中侵犯您的合法权益,请及时联系Docker中文社区!
如有侵权请联系:admin#unsafe.sh