注册回调函数在C++中是十分常见的做法。如: void (*func_ptr)(int, string);vo 2022-11-13 08:51:51 Author: blog.csdn.net(查看原文) 阅读量:27 收藏
注册回调函数在C++中是十分常见的做法。如:
void (*func_ptr)(int, string);
void foo(int x, string s) {
std::cout << __func__ << " " << x << " " << s << endl;
}
int main()
{
func_ptr = foo;
func_ptr(1, "hello");
return 0;
}
但大多时候(像上面这个例子一样)需要显式给出回调函数的声明,因为编译需要这个信息来根据ABI生成函数调用代码。那么问题来了,如果我们想注册不同的任意函数签名的回调函数呢?
先来看下在Python中如何实现:
class Test:
def __init__(self, func):
self.callback = func
def call_func(self, args):
self.callback(*args)
def foo(x, y):
print(f"foo {x} {y}")
test = Test(foo)
test.call_func((1, "hello"))
这里的foo是回调函数,在Test类的构造函数中传入并存于callback变量中。调用时将所有参数以tuple类型传入,然后调用回调函数时用星号进行unpacking。
Python是解释型语言,因此比较容易实现。但如果我们想在C++中实现呢?这就需要用到C++中Variadic Template特性(可参考《The C++ Programing Language》28.6)。它用到元编程(Meta-programming)。我们知道,meta-programming图灵完备,功能强大。这意味着很多事可以通过它放到编译时做,提高运行时效率,但是其缺点除了编译慢、code bloat外,还有就是难读。。。尤其是有些复杂的用法,看得那叫一个醱爽。关于variadic template的用法,最常用的例子可能就是printf了。代码可以参考https://en.cppreference.com/w/cpp/language/parameter_pack,这里就不粘了。基本思想就是利用模板做编译时的递归。
回到主题问题上来,那如何基本它来实现任意函数签名的回调注册呢?在TFRT(TFRT是Google的项目,意在替换TensorFlow中的Runtime)中有这样的用法,下面走读下代码学习一下。先从简单的例子看它的用法。如backends/gpu/lib/ops/test/test_ops.cc中通过下面语句注册回调:
static llvm::Expected<DenseGpuTensor> GpuStreamSynchronize(
GpuDispatchContext* dctx, const DenseGpuTensor& input,
const TensorMetadata& result_md) {
if (auto err = wrapper::StreamSynchronize(dctx->stream())) {
return std::move(err);
}
return input.CopyRef();
}
registry->AddOp("tfrt_test.synchronize", TFRT_GPU_OP(GpuStreamSynchronize));
registry->AddOp("tfrt_test.create_dense_tensor",
TFRT_GPU_OP(CreateDenseTensorOp), {"shape", "values"});
还有test_cuda_kernels.cu.cc中的下面语句:
static Expected<DenseGpuTensor> GpuAddOp(GpuDispatchContext* dctx,
const DenseGpuTensor& tensor_a,
const DenseGpuTensor& tensor_b,
const OpAttrsRef& attrs,
const TensorMetadata& result_md) {
registry->AddOp("tfrt_test.add", TFRT_GPU_OP(GpuAddOp));
它们的作用是将一个回调函数通过AddOp函数注册到注册表Registry中去。但问题是这些回调函数的函数签名是不一样的,这意味着我们没法简单地用一个固定类型的函数指针来存放与使用它们。这时meta-programming的作用就体现出来了,它可以在编译时为每种函数生成相应的glue code。
先来看看注册表类的实现。在文件op_registry_impl.h中定义了模板类OpRegistryImpl:
template <typename OpMetadataFnTy, typename DispatchFnTy, typename OpFlagsTy>
class OpRegistryImpl {
public:
struct OpEntry {
OpMetadataFnTy metadata_fn = nullptr;
DispatchFnTy dispatch_fn = nullptr;
OpFlagsTy flags;
string_view op_name;
...
void AddOp(string_view op_name, DispatchFnTy dispatch_fn, OpFlagsTy flags,
ArrayRef<string_view> attr_names) {
assert(!op_name.empty() && "op names cannot be empty");
auto& entry = op_mappings_[op_name];
entry.dispatch_fn = dispatch_fn;
entry.flags = flags;
entry.attr_names.reserve(attr_names.size());
for (auto name : attr_names) entry.attr_names.emplace_back(name);
entry.op_name = op_mappings_.find(op_name)->first();
}
CPU与GPU平台上对应的实现类CpuOpRegistry::Impl与GpuOpRegistry::Impl分别在文件cpu_op_registry_impl.h与gpu_op_registry_impl.h中:
// This is the pImpl implementation details for CpuOpRegistry.
struct CpuOpRegistry::Impl final
: OpRegistryImpl<OpMetadataFn, CpuDispatchFn, CpuOpFlags> {};
using CpuOpEntry =
OpRegistryImpl<OpMetadataFn, CpuDispatchFn, CpuOpFlags>::OpEntry;
} // namespace tfrt
// This is the pImpl implementation details for GpuOpRegistry.
struct GpuOpRegistry::Impl final
: OpRegistryImpl<OpMetadataFn, GpuDispatchFn, GpuOpFlags> {};
using GpuOpEntry =
OpRegistryImpl<OpMetadataFn, GpuDispatchFn, GpuOpFlags>::OpEntry;
以CPU为例,CpuOpRegistry定义在cpu_op_registry.h中:
// This is the signature implemented by all CPU ops. They take Tensor buffers
// inputs and allocate and return tensors for their results. If the op has a
// metadata function, then the result of the function is passed in as
// result_mds, otherwise it is an empty list.
//
// If the kernel has a runtime failure, the chain should be set to the
// error value, and any invalid results should be set to errors as well.
using CpuDispatchFn = void (*)(const ExecutionContext& exec_ctx,
ArrayRef<AsyncValue*> inputs,
const OpAttrsRef& attrs,
ArrayRef<TensorMetadata> result_mds,
MutableArrayRef<RCReference<AsyncValue>> results,
AsyncValueRef<Chain>* chain);
...
// This represents a mapping from op names to the associated metadata functions
// (optional) and kernel dispatch functions.
class CpuOpRegistry {
// Add an op with the specified dispatch function. This style of dispatch
// function does not require a metadata function.
void AddOp(string_view op_name, CpuDispatchFn dispatch_fn, CpuOpFlags flags);
...
}
上面的CpuDispatchFn 是一个跳板函数,一会儿会提到。CpuOpRegistry::AddOp函数会调用对应实现类中的AddOp函数。对于GPU也是类似的,相关定义在gpu_op_registry.h中。
然后再来看看注册的回调函数。可以看到,这些函数都包了一个宏。以GPU为例,TFRT_GPU_OP定义在gpu_op_utils.h中:
#define TFRT_GPU_OP(...) \
::tfrt::DispatchFnImpl<GpuDispatchContext, decltype(&__VA_ARGS__), \
&__VA_ARGS__>::Invoke
其中的模板类DispatchFnImpl定义在文件include/tfrt/core_runtime/op_utils.h中:
// This class is an implementation detail of TFRT_CPU_OP.
template <typename DeviceContext, typename F, F f>
struct DispatchFnImpl;
template <typename DeviceContext, typename Return, typename... Args,
Return (*impl_fn)(Args...)>
struct DispatchFnImpl<DeviceContext, Return (*)(Args...), impl_fn> {
// Only add DeviceContext* in the dispatch function if DeviceContext is not
// HostContext.
template <typename T = DeviceContext,
std::enable_if_t<!std::is_same<T, HostContext>::value, int> = 0>
static void Invoke(const ExecutionContext& exec_ctx, DeviceContext* ctx,
ArrayRef<AsyncValue*> arguments, const OpAttrsRef& attrs,
ArrayRef<TensorMetadata> result_mds,
MutableArrayRef<RCReference<AsyncValue>> results,
AsyncValueRef<Chain>* chain) {
DispatchFnCallHelper<Args..., void>::template Invoke<0, 0, 0, false, false>(
ctx, arguments, attrs, result_mds, results, chain, exec_ctx);
}
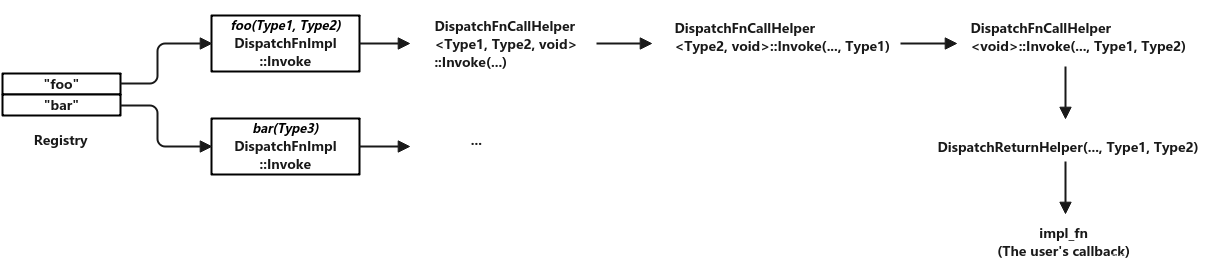
该模板类会根据回调函数的类型进行实例化。其模板参数包含了回调函数的类型和具体的值。其中的成员Invoke函数签名与前面提到的CpuDispatchFn与GpuDisaptchFn是一致的。它的作用就像跳板一样。接下来Invoke中就会试图调用回调函数。但因为这些实际回调函数类型各不相同,因此就需要根据相应的回调函数类型进行构建。在这个过程中,DispatchFnCallHelper类是关键:
// Helper that introspects the DispatchFn's arguments to derive the signature
// and pass arguments, attributes, results, out_chain and location to impl_fn.
// Works by recursively unpacking the DispatchFn's arguments.
template <typename... RemainingArgs>
struct DispatchFnCallHelper;
它的作用是递归解析参数,构建函数调用。该模板类有很多特化,如对于类型为OpAttrsRef的参数:
// Specialization for passing OpAttrsRef.
template <typename... RemainingArgs>
struct DispatchFnCallHelper<const OpAttrsRef&, RemainingArgs...> {
template <int arg_idx, int result_idx, int md_idx, bool has_attrs,
bool has_chain, typename... PreviousArgs>
static void Invoke(DeviceContext* ctx, ArrayRef<AsyncValue*> arguments,
const OpAttrsRef& attrs,
ArrayRef<TensorMetadata> result_mds,
MutableArrayRef<RCReference<AsyncValue>> results,
AsyncValueRef<Chain>* chain,
const ExecutionContext& exec_ctx,
const PreviousArgs&... pargs) {
static_assert(!has_attrs, "Do not place more than one OpAttrsRef");
static_assert(!has_chain, "Do not place argument OpAttrsRef after chain");
static_assert(result_idx == 0,
"Do not place OpAttrsRef after result Tensor");
static_assert(md_idx == 0,
"Do not place OpAttrsRef after result Metadata");
DispatchFnCallHelper<RemainingArgs...>::template Invoke<
arg_idx, result_idx, md_idx, true, has_chain>(
ctx, arguments, attrs, result_mds, results, chain, exec_ctx, pargs...,
attrs);
}
};
对于类型为RCReference<AsyncValue>的参数,相应特化如下:
// Specialization for passing a Tensor result.
template <typename... RemainingArgs>
struct DispatchFnCallHelper<RCReference<AsyncValue>*, RemainingArgs...> {
template <int arg_idx, int result_idx, int md_idx, bool has_attrs,
bool has_chain, typename... PreviousArgs>
static void Invoke(DeviceContext* ctx, ArrayRef<AsyncValue*> arguments,
const OpAttrsRef& attrs,
ArrayRef<TensorMetadata> result_mds,
MutableArrayRef<RCReference<AsyncValue>> results,
AsyncValueRef<Chain>* chain,
const ExecutionContext& exec_ctx,
const PreviousArgs&... pargs) {
static_assert(!has_chain, "Do not place result Tensor after chain");
assert(result_idx < results.size());
RCReference<AsyncValue>* arg = &results[result_idx];
DispatchFnCallHelper<RemainingArgs...>::template Invoke<
arg_idx, result_idx + 1, md_idx, has_attrs, has_chain>(
ctx, arguments, attrs, result_mds, results, chain, exec_ctx, pargs...,
arg);
}
};
还有针对其它类型(如TensorMetadata,ExecutionContext&等)的参数的模型特化。。。就这样,遇到什么类型的参数就会匹配相应的模板特化,直到所有参数匹配完毕。最后会到达递归的最内层:
// Base case: No arguments left.
// The trailing template argument works around around the restriction of GCC
// not being fully C++14 compliant and not allowing fully specialized
// templates in class scope.
template <typename T>
struct DispatchFnCallHelper<T> {
template <int arg_idx, int result_idx, int md_idx, bool has_attrs,
bool has_chain, typename... PreviousArgs>
static void Invoke(DeviceContext* ctx, ArrayRef<AsyncValue*> arguments,
const OpAttrsRef& attrs,
ArrayRef<TensorMetadata> result_mds,
MutableArrayRef<RCReference<AsyncValue>> results,
AsyncValueRef<Chain>* chain,
const ExecutionContext& exec_ctx,
const PreviousArgs&... args) {
// TODO(b/146386166): Emit error instead of assert().
assert((arg_idx == arguments.size() || arg_idx == -1) &&
"Extra arguments passed to dispatch function.");
assert((md_idx == result_mds.size() || md_idx == 0) &&
"Extra result Metadatas passed to dispatch function.");
DispatchReturnHelper<result_idx, has_chain, Return>::Invoke(
results, chain, exec_ctx, args...);
}
};
这里会先检查参数与返回数量是否正确,最后调用DispatchReturnHelper函数。该函数也是个模板函数,会根据相应的返回类型实例化。如对于返回为void的回调,会匹配下面的模板特化:
// The return value is void.
template <int result_idx, bool has_chain>
struct DispatchReturnHelper<result_idx, has_chain, void> {
static void Invoke(MutableArrayRef<RCReference<AsyncValue>> results,
AsyncValueRef<Chain>* chain,
const ExecutionContext& exec_ctx, const Args&... args) {
assert(result_idx == results.size() &&
"Extra results passed to dispatch function.");
impl_fn(args...);
}
};
这里impl_fn就是前面用户实际注册的回调函数了,到这里它的参数已经按要求准备好了。如果返回其它类型,会在模板实例化时匹配到:
// The return value is AsyncValueRef<T>.
template <int result_idx, bool has_chain, typename T>
struct DispatchReturnHelper {
static void Invoke(MutableArrayRef<RCReference<AsyncValue>> results,
AsyncValueRef<Chain>* chain,
const ExecutionContext& exec_ctx, const Args&... args) {
HandleReturn<result_idx, has_chain>(results, chain, exec_ctx,
impl_fn(args...));
}
};
整个过程示意图如下:

如有侵权请联系:admin#unsafe.sh