渗透测试如何打造社工字典
爬取页面内容利用工具:cewl->(kali)参数详解-h、 --help:显示帮助。-k、 --keep:保留下载的文件。-d<x>,--depth<x>:蜘蛛的深度,默认值为2。-m、 --min 2022-11-9 19:2:24 Author: 猪猪谈安全(查看原文) 阅读量:44 收藏
爬取页面内容利用工具:cewl->(kali)参数详解-h、 --help:显示帮助。-k、 --keep:保留下载的文件。-d<x>,--depth<x>:蜘蛛的深度,默认值为2。-m、 --min 2022-11-9 19:2:24 Author: 猪猪谈安全(查看原文) 阅读量:44 收藏
爬取页面内容
利用工具:cewl->(kali)
参数详解
-h、 --help:显示帮助。-k、 --keep:保留下载的文件。-d<x>,--depth<x>:蜘蛛的深度,默认值为2。-m、 --min_word_length:最小字长,默认值为3。-o、 --offsite:让spider访问其他站点。--exclude:包含要排除的路径列表的文件--allowed:路径必须匹配才能遵循的正则表达式模式-w、 --write:将输出写入文件。-u、 --ua<agent>:要发送的用户代理。-n、 --o-words:不输出单词列表。--lowercase:将所有分析的单词小写--with-numbers:接受带有数字和字母的单词--convert-umlauts:转换通用ISO-8859-1(拉丁语-1)元音(ä-ae,ö-oe,ü-ue,ß-ss)-a、 --meta:包含元数据。--meta_file文件:元数据的输出文件。-e、 --email:包括电子邮件地址。--email_file<file>:电子邮件地址的输出文件。--meta-temp dir<dir>:exiftool在解析文件时使用的临时目录,默认为/tmp。-c、 --count:显示找到的每个单词的计数。-v、 --verbose:详细。--debug:额外的调试信息。身份验证--auth_type:摘要或基本。--auth_user:身份验证用户名。--auth_pass:身份验证密码。代理服务器支持--proxy_host:代理主机。--proxy_port:代理端口,默认为8080。--proxy_username:代理的用户名(如果需要)。--proxy_password:代理的密码(如果需要)。邮件头--header,-H:格式名称:value-可以传递多个。
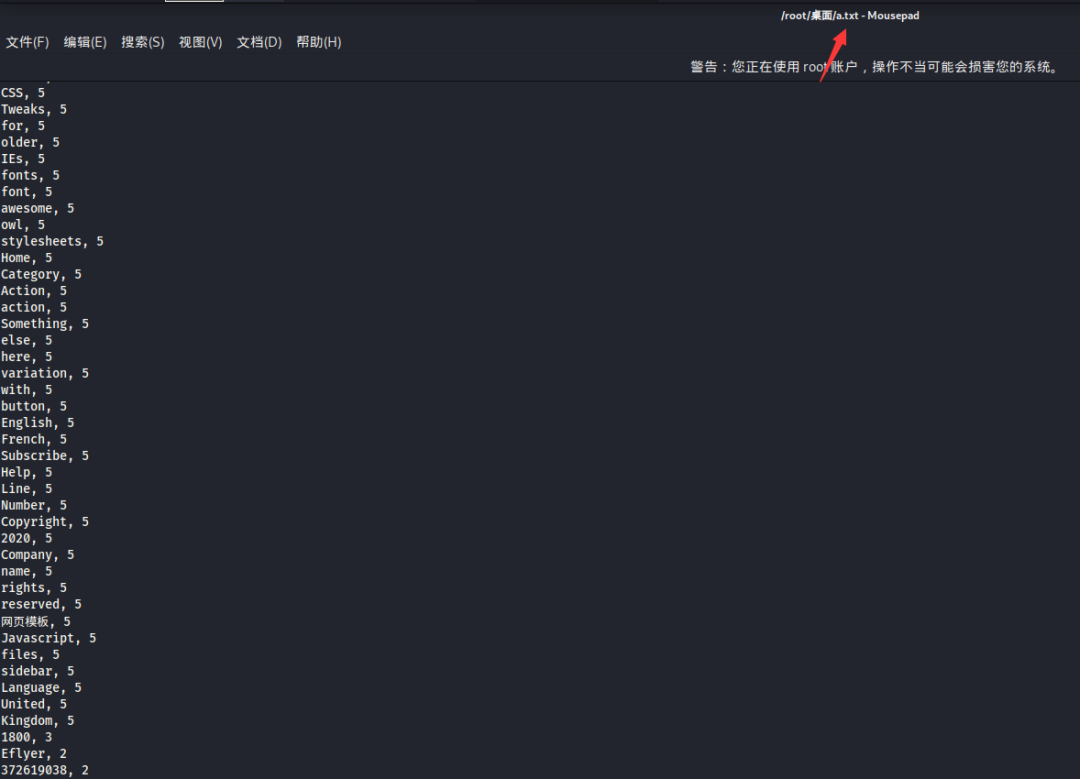
cewl url -m 3 -d 3 -e -c -v -w a.txt --with-numbers可直接使用爬取出的信息做一个爆破,爆破无果可对之前爬取出信息中无用信息做一个简单剔除,然后再结合人工浏览页面筛选出一些带有社工意义的信息,如姓名,电话,联系方法,公司名称等,这些信息的收集我们也可以通过whois反查结合站点的注册人信息,注册人邮箱等。
社工字典生成
利用工具:白鹿社工字典为例。
https://github.com/z3r023/BaiLu-SED-Tool对我们之前通过爬取和一起其他手段搜集过来的信息整理号然后把其放入A项结合一些特有弱口令再次生成社工字典
如果还是无果,我们还可以自己写一个小脚本,去生成用户极有可能设置的社工弱口令然后再与一些常见弱口令进行一个拼接进行爆破。
该处以姓名:张三为例
那我们可以写脚本生成如下社工口令
zhangsan //全拼音zhangs //全姓简名zsan //简姓全名zs //简姓简名张三 //中文名字(还真碰到过用中文作用户名的)//等等,师傅们发散思维
可以把我们脚本生成的的社工口令直接进行一个爆破,无果可以再用白鹿社工字典结合一些常见弱口令再次生成社工字典,再次进行爆破。
点击下方小卡片或扫描下方二维码观看更多技术文章
师傅们点赞、转发、在看就是最大的支持
文章来源: http://mp.weixin.qq.com/s?__biz=MzIyMDAwMjkzNg==&mid=2247506186&idx=1&sn=6f5087ff053a1a347bc7fc2313d78a2c&chksm=97d0361da0a7bf0baf53fc32826edded896abbda486ee28357514987facfdf12da05b6ee64d7#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh