一次任意文件读取与分析
本文记录以前的一次偶然测试过程,常见问题在文章底部。地址来源发现第一眼看的时候,整个网站什么都没有,登录后也没有看到什么接口,猜测是个前后端不分离的,通过接口去做什么不太现实,只能想别的方法。看了一下 2022-10-10 23:56:56 Author: 墨雪飘影(查看原文) 阅读量:61 收藏
本文记录以前的一次偶然测试过程,常见问题在文章底部。地址来源发现第一眼看的时候,整个网站什么都没有,登录后也没有看到什么接口,猜测是个前后端不分离的,通过接口去做什么不太现实,只能想别的方法。看了一下 2022-10-10 23:56:56 Author: 墨雪飘影(查看原文) 阅读量:61 收藏
地址来源
唯一一个本地渲染的页面
__dirname
如图,拼接参数存在..会舍弃上一个参数
查阅path.join源码。
参考地址:https://github.com/nodejs/node/blob/v18.0.0/lib/path.js
path.join最后会调用normalize。
参考地址:https://nodejs.org/dist/latest-v16.x/docs/api/path.html#pathnormalizepath
normalize方法会解析”.”与”..”,并对多个”\”或”/”进行处理。这就是这个漏洞产生的原因。
同样的在Python中也有path.join方法,但是没有这个问题。
nodejs与Python中path.join方法对比
因为Python真的是拼接,不会做任何处理。
参考地址:https://docs.python.org/zh-cn/3.7/library/os.path.html#os.path.join
总结
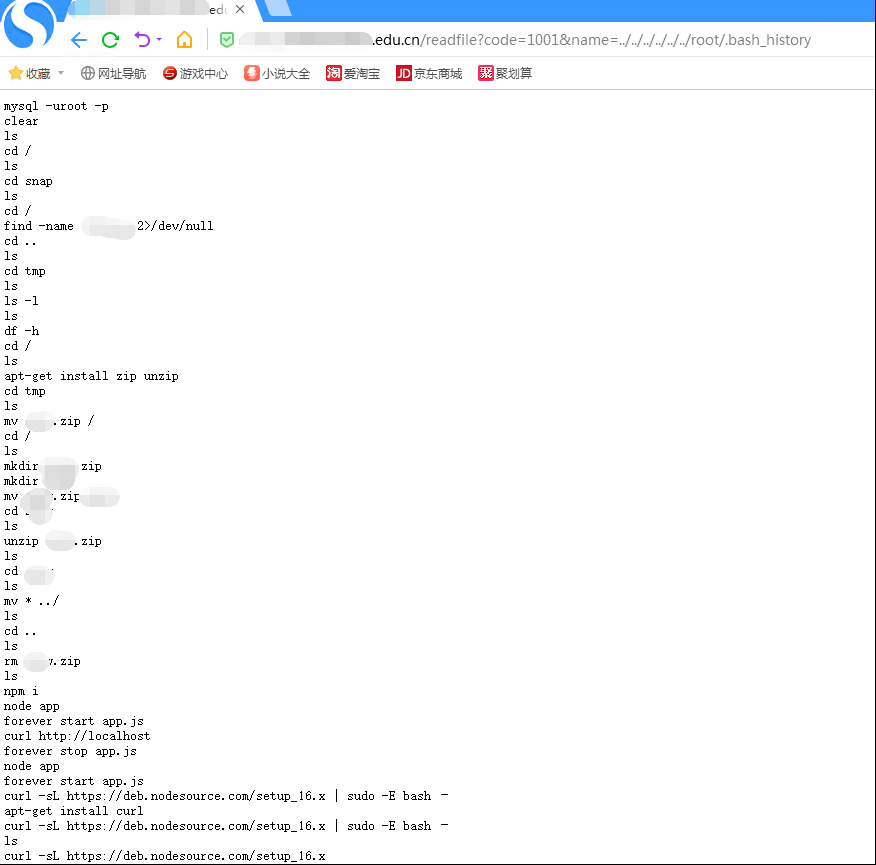
Q:.bash_history文件在哪里?
A:用户家目录下,/home/username/.bash_history
Q:为什么我的root下没有 .bash_history 这个文件?
A:我也发现了这个问题,其原因是没有正常关机内容在内存中,没有存储到硬盘里。
参考地址:https://m.imooc.com/qadetail/158140
大家
文章来源: http://mp.weixin.qq.com/s?__biz=MzI3NzI4OTkyNw==&mid=2247488591&idx=1&sn=923dd434220037359a202d1136ec5ba5&chksm=eb69dae7dc1e53f169b4596d81dd66072f15a43720c4ed0ed72883ac17444347592fb0cf265f#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh