作者:时钟@RainSec
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]
Fuzzing input
Fuzzing的一大核心思想其实就是通过大量的Input去触发程序的各个分支逻辑,因此Fuzzing的成功与否和Input的生成关系密切。Input的格式多种多样,可以是文件,代码,json数据等等。但是各种各样的数据都有自己的格式,程序的输入也是如此,那么在生成Input的过程中,格式化非常关键,程序无法接受的输入对于Fuzzing来说是毫无意义的。
为了很好的描述一个程序的输入,一个很有必要的事情是为输入制定一些语法规范。比如编译器的输入:python解释器规定了符合python语法的程序才能得以执行,gcc规定了符合C语言语法的程序才能被完成编译进而生成二进制文件。Fuzzing也是如此,为了很好的达到Fuzzing的效果,为程序定义一种输入的语法规范往往是一种不错的选择。
一般而言,对于Fuzzing简单的程序来说,正则表达式往往是一个不错的选择,它所具备的有限状态机属性使得它易于推理进而获得一个满意的Input。但是如果面临的Fuzzing目标需要非常复杂的输入,那么它就会表现的捉襟见肘。
我曾见过为了更好的实现某些功能而专门设计一些语言,从计算机理论的角度这显然是非常有用的,一些特殊功能在特殊语言的加持之下表现出超高的质量,但是对于Fuzzing而言这确实是成本过高了,Grammars其实就是正则表达式和专业语言之间的一个中间地带。它易于理解,并且能很好的完成Fuzzing对它的期望--生成大量合法输入,因为通过Grammars可以规定Inputs的大量属性,完美的表达一个复杂输入的语法结构。
Grammars初探
Grammar一般由符号和一组表达式组成,例如A = 10 | 9 | 0 |1,符号化使得递归成为可能,假设B = A | AB,这无疑就使得符号所代表的范围倍增。根据这种思想我们可以制作一个算数表达式:
<start> ::= <expr>
<expr> ::= <term> + <expr> | <term> - <expr> | <term>
<term> ::= <term> * <factor> | <term> / <factor> | <factor>
<factor> ::= +<factor> | -<factor> | (<expr>) | <integer> | <integer>.<integer>
<integer> ::= <digit><integer> | <digit>
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9那么通过对<start>的内部的符号进行逐一扩展,并对过程进行随机化处理,最终就可以得到大量的合法算数表达式。和大多数语法一样,Grammar也应该有自己的Type,以便对其合法性进行校验,以Python 为例子可以对上述的Grammar进行定义:
Option = Dict[str, Any]
Expansion = Union[str, Tuple[str, Option]]
Grammar = Dict[str, List[Expansion]]
EXPR_GRAMMAR: Grammar = {
"<start>":
["<expr>"],
"<expr>":
["<term> + <expr>", "<term> - <expr>", "<term>"],
"<term>":
["<factor> * <term>", "<factor> / <term>", "<factor>"],
"<factor>":
["+<factor>",
"-<factor>",
"(<expr>)",
"<integer>.<integer>",
"<integer>"],
"<integer>":
["<digit><integer>", "<digit>"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
}前三行代码定义了一个Grammar应该如何在Python中构成。通过代码中的EXPR_GRAMMAR["<digit>"]可以访问当前Grammar的各个组成部分并对其进行操作。
Sample Grammar Fuzz
那么该如何对Grammar语法进行解析呢?一种最简单的方式就是通过字符串替换,因为在Grammar中:的左右两侧本身就是一种映射关系,因此利用字符串替换不断迭代是一种最为直观的选择。
实例代码:
START_SYMBOL = "<start>"
# 一个简单的gramar fuzzer
def simple_grammar_fuzzer(grammar: Grammar,
start_symbol: str = START_SYMBOL,
max_nonterminals: int = 10,
max_expansion_trials: int = 100,
log: bool = False) -> str:
"""Produce a string from `grammar`.
`start_symbol`: use a start symbol other than `<start>` (default).
`max_nonterminals`: the maximum number of nonterminals
still left for expansion
`max_expansion_trials`: maximum # of attempts to produce a string
`log`: print expansion progress if True"""
term = start_symbol
expansion_trials = 0
while len(nonterminals(term)) > 0: # 判断字符串中是否存在<>,并返回所有被<>包裹的项,注意如果是<dsad<abc>>则返回<abc>
symbol_to_expand = random.choice(nonterminals(term))
expansions = grammar[symbol_to_expand]
expansion = random.choice(expansions)
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
new_term = term.replace(symbol_to_expand, expansion, 1) # 解析下一个符号
if len(nonterminals(new_term)) < max_nonterminals: # 每次的可解析符号,必须少于最大单次解析量
term = new_term
if log:
print("%-40s" % (symbol_to_expand + " -> " + expansion), term)
expansion_trials = 0
else:
expansion_trials += 1
if expansion_trials >= max_expansion_trials: # 总的解析次数也存在限制
raise ExpansionError("Cannot expand " + repr(term))
return term利用上面的表达式Grammar可以制作一个简单的grammar fuzz,Fuzz的编写过程其实面临着很多的取舍,便利和速度或者各种各样的可行性之间的考虑,以上面的Grammar为例子,我们肯定不希望其陷入类似无限递归或者大量符号解析的情况,而是会限制对字段的提取次数和对符号的解析次数。
但是此类Grammar Fuzz都面临几个问题就是大量的字符串搜索和替换操作导致效率低下,而且可以看出存在Input生成失败的情况(ExpansionError),而且这是一个典型的上下文无关的Fuzz。不过,依赖于上述功能,我们只要编写Grammar就可以很好的对一些Inputs进行大量生成。
比如URL生成:
URL_GRAMMAR: Grammar = {
"<start>":
["<url>"],
"<url>":
["<scheme>://<authority><path><query>"],
"<scheme>":
["http", "https", "ftp", "ftps"],
"<authority>":
["<host>", "<host>:<port>", "<userinfo>@<host>", "<userinfo>@<host>:<port>"],
"<host>": # 大部分情况下其实可以指定一个URL
["cispa.saarland", "www.google.com", "fuzzingbook.com"],
"<port>":
["80", "8080", "<nat>"],
"<nat>":
["<digit>", "<digit><digit>"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
"<userinfo>": # Just one
["user:password"],
"<path>": # Just a few
["", "/", "/<id>"],
"<id>": # Just a few
["abc", "def", "x<digit><digit>"],
"<query>":
["", "?<params>"],
"<params>":
["<param>", "<param>&<params>"],
"<param>": # Just a few
["<id>=<id>", "<id>=<nat>"],
}或者类似HTTP协议的(但是这个不是为上述Fuzz准备的,只是拿来做个参考):
{
"<A>": [["<START_LINE>", "\r\n", "<HEADERS>", "<BODY>", "\r\n\r\n"]],
"<START_LINE>": [["<METHOD>", " ", "<URI>", " ", "<VERSION>"]],
"<METHOD>": [["GET"], ["HEAD"], ["POST"], ["PUT"], ["DELETE"], ["CONNECT"], ["OPTIONS"], ["TRACE"], ["PATCH"], ["ACL"], ["BASELINE-CONTROL"], ["BIND"], ["CHECKIN"], ["CHECKOUT"], ["COPY"], ["LABEL"], ["LINK"], ["LOCK"], ["MERGE"], ["MKACTIVITY"], ["MKCALENDAR"], ["MKCOL"], ["MKREDIRECTREF"], ["MKWORKSPACE"], ["MOVE"], ["ORDERPATCH"], ["PRI"], ["PROPFIND"], ["PROPPATCH"], ["REBIND"], ["REPORT"], ["SEARCH"], ["UNBIND"], ["UNCHECKOUT"], ["UNLINK"], ["UNLOCK"], ["UPDATE"], ["UPDATEREDIRECTREF"], ["VERSION-CONTROL"]],
"<URI>": [["<SCHEME>" , ":", "<HIER>", "<QUERY>", "<FRAGMENT>"]],
"<SCHEME>": [["http"], ["https"], ["shttp"], ["dav"], ["about"], ["attachment"], ["cid"], ["data"], ["file"], ["ftp"], ["ssh"], ["sip"]],
"<HIER>": [["//", "<AUTHORITY>", "<PATH>"]],
"<AUTHORITY>": [["<USERINFO>", "<HOST>"]],
"<PATH>": [["/", "<DIR>"]],
"<DIR>": [[], ["<CHAR>", "/", "<DIR>"]],
"<USERINFO>": [[], ["<CHAR>", ":", "<CHAR>", "@"]],
"<HOST>": [["127.0.0.1:8080"]],
"<QUERY>": [[], ["?", "<CHAR>" , "=", "<CHAR>"]],
"<FRAGMENT>": [[], ["#", "<CHAR>"]],
"<VERSION>": [["HTTP/0.9"], ["HTTP/1.0"], ["HTTP/1.1"], ["HTTP/2.0"], ["HTTP/3.0"]],
"<HEADERS>": [[], ["<HEADER>", "\r\n", "<HEADERS>"]],
"<HEADER>": [["<HEADER_FIELD>", ": ", "<ANY>"]],
"<HEADER_FIELD>": [["A-IM"], ["Accept"], ["Accept-Charset"], ["Accept-Datetime"], ["Accept-Encoding"], ["Accept-Language"], ["Access-Control-Request-Method"], ["Access-Control-Request-Headers"], ["Authorization"], ["Cache-Control"], ["Connection"], ["Content-Encoding"], ["Content-Length"], ["Content-MD5"], ["Content-Type"], ["Cookie"], ["Date"], ["Expect"], ["Forwarded"], ["From"], ["Host"], ["HTTP2-Settings"], ["If-Match"], ["If-Modified-Since"], ["If-None-Match"], ["If-Range"], ["If-Unmodified-Since"], ["Max-Forwards"], ["Origin"], ["Pragma"], ["Proxy-Authorization"], ["Range"], ["Referer"], ["TE"], ["Trailer"], ["Transfer-Encoding"], ["User-Agent"], ["Upgrade"], ["Via"], ["Warning"]],
"<BODY>": [[], ["<CHAR>"]],
"<ANY>": [[], ["<DATE>"], ["<CHAR>"], ["<HOST>"], ["<URI>"]],
"<DATE>": [["Sat, 29 Oct 1994 19:43:31 GMT"]],
"<CHAR>": [["0"], ["1"], ["2"], ["3"], ["4"], ["5"], ["6"], ["7"], ["8"], ["9"], ["a"], ["b"], ["c"], ["d"], ["e"], ["f"], ["g"], ["h"], ["i"], ["j"], ["k"], ["l"], ["m"], ["n"], ["o"], ["p"], ["q"], ["r"], ["s"], ["t"], ["u"], ["v"], ["w"], ["x"], ["y"], ["z"], ["A"], ["B"], ["C"], ["D"], ["E"], ["F"], ["G"], ["H"], ["I"], ["J"], ["K"], ["L"], ["M"], ["N"], ["O"], ["P"], ["Q"], ["R"], ["S"], ["T"], ["U"], ["V"], ["W"], ["X"], ["Y"], ["Z"]]
}到此,我们理解了Grammar对于Fuzzing的重要性,一个杰出的Grammar能够有效的生成大量合法输入,不过这只是从输入组成(句法)来看,这毕竟是一个庞大的范围,虽然有时候满足程序的输入格式,但是未必真的对Fuzzing起作用,这种情况非常常见。再一次以编译器为例子,你的程序在满足语言语法的同时更应该具备正确的语义。但是语义很难再以Grammar的形式表达。以URL生成Grammar为例,简单通过Grammar很难定义端口的范围。面对这样的问题,最简单的解决办法其实就是在Fuzz里面而不是在Grammar里面进行限制。以URL Grammar为例,通过Grammar生成的URL在真正的被作为Input给予目标之前,应该在Fuzz系统里面经过URL“合法性”判断,这里的判断可以由作者根据自己的需求来进行限制。
Grammar Toolbox
在Fuzzing项目中对于Grammar的需求并不是一成不变的,因此Grammar的一大需求就是具备可扩展性。以一个简单的Gramar为例:
simple_nonterminal_grammar: Grammar = {
"<start>": ["<nonterminal>"],
"<nonterminal>": ["<left-angle><identifier><right-angle>"],
"<left-angle>": ["<"],
"<right-angle>": [">"],
"<identifier>": ["id"] # for now
}有时候我们希望拓展其功能,但是不希望原来的Grammar受到影响(类比编程中的继承),就是一个很简单的如下操作。
nonterminal_grammar = copy.deepcopy(simple_nonterminal_grammar)
nonterminal_grammar["<identifier>"] = ["<idchar>", "<identifier><idchar>"]
nonterminal_grammar["<idchar>"] = ['a', 'b', 'c', 'd'] # for now总结为一个函数如下,非常简单就不多解释:
def set_opts(grammar: Grammar, symbol: str, expansion: Expansion,
opts: Option = {}) -> None:
"""Set the options of the given expansion of grammar[symbol] to opts"""
expansions = grammar[symbol]
for i, exp in enumerate(expansions):
if exp_string(exp) != exp_string(expansion):
continue
new_opts = exp_opts(exp)
if opts == {} or new_opts == {}:
new_opts = opts
else:
for key in opts:
new_opts[key] = opts[key]
if new_opts == {}:
grammar[symbol][i] = exp_string(exp)
else:
grammar[symbol][i] = (exp_string(exp), new_opts)
return
raise KeyError(
"no expansion " +
repr(symbol) +
" -> " +
repr(
exp_string(expansion)))同时,在写Fuzz的时候肯定不希望不断地写大量的符号和值的对应,因此我们需要一些语法来帮助,这里提供了ENBF的解析方法:
# 解析 ebnf 语法
def new_symbol(grammar: Grammar, symbol_name: str = "<symbol>") -> str:
"""Return a new symbol for `grammar` based on `symbol_name`"""
if symbol_name not in grammar:
return symbol_name
count = 1
while True:
tentative_symbol_name = symbol_name[:-1] + "-" + repr(count) + ">"
if tentative_symbol_name not in grammar:
return tentative_symbol_name
count += 1
# 提取表达式中符合EBNF语法的部分,? , * , + , ()
def parenthesized_expressions(expansion: Expansion) -> List[str]:
RE_PARENTHESIZED_EXPR = re.compile(r'\([^()]*\)[?+*]')
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
return re.findall(RE_PARENTHESIZED_EXPR, expansion)
# 对Grammar中的EBNF语法括号进行解析
def convert_ebnf_parentheses(ebnf_grammar: Grammar) -> Grammar:
"""Convert a grammar in extended BNF to BNF"""
grammar = extend_grammar(ebnf_grammar)
for nonterminal in ebnf_grammar:
expansions = ebnf_grammar[nonterminal]
for i in range(len(expansions)):
expansion = expansions[i]
if not isinstance(expansion, str):
expansion = expansion[0]
while True:
parenthesized_exprs = parenthesized_expressions(expansion)
if len(parenthesized_exprs) == 0:
break
for expr in parenthesized_exprs:
operator = expr[-1:]
contents = expr[1:-2]
new_sym = new_symbol(grammar)
exp = grammar[nonterminal][i]
opts = None
if isinstance(exp, tuple):
(exp, opts) = exp
assert isinstance(exp, str)
expansion = exp.replace(expr, new_sym + operator, 1)
if opts:
grammar[nonterminal][i] = (expansion, opts)
else:
grammar[nonterminal][i] = expansion
grammar[new_sym] = [contents]
return grammar
# ENBF符号扩展
def extended_nonterminals(expansion: Expansion) -> List[str]:
RE_EXTENDED_NONTERMINAL = re.compile(r'(<[^<> ]*>[?+*])')
# In later chapters, we allow expansions to be tuples,
# with the expansion being the first element
if isinstance(expansion, tuple):
expansion = expansion[0]
return re.findall(RE_EXTENDED_NONTERMINAL, expansion)
# ENBF符号扩展
def convert_ebnf_operators(ebnf_grammar: Grammar) -> Grammar:
"""Convert a grammar in extended BNF to BNF"""
grammar = extend_grammar(ebnf_grammar)
for nonterminal in ebnf_grammar:
expansions = ebnf_grammar[nonterminal]
for i in range(len(expansions)):
expansion = expansions[i]
extended_symbols = extended_nonterminals(expansion)
for extended_symbol in extended_symbols:
operator = extended_symbol[-1:]
original_symbol = extended_symbol[:-1]
assert original_symbol in ebnf_grammar, \
f"{original_symbol} is not defined in grammar"
new_sym = new_symbol(grammar, original_symbol)
exp = grammar[nonterminal][i]
opts = None
if isinstance(exp, tuple):
(exp, opts) = exp
assert isinstance(exp, str)
new_exp = exp.replace(extended_symbol, new_sym, 1)
if opts:
grammar[nonterminal][i] = (new_exp, opts)
else:
grammar[nonterminal][i] = new_exp
if operator == '?':
grammar[new_sym] = ["", original_symbol]
elif operator == '*':
grammar[new_sym] = ["", original_symbol + new_sym]
elif operator == '+':
grammar[new_sym] = [
original_symbol, original_symbol + new_sym]
return grammar
def convert_ebnf_grammar(ebnf_grammar: Grammar) -> Grammar:
return convert_ebnf_operators(convert_ebnf_parentheses(ebnf_grammar))对于Grammar来言,我们必须要确定它的一个合法性,不然在使用中必然会遇到各种错误问题,因此语法检查是很必要的,就如同编译器的语法检查很重要一样:
# 搜索Grammar中的定义的noterminal
def def_used_nonterminals(grammar: Grammar, start_symbol:
str = START_SYMBOL) -> Tuple[Optional[Set[str]],
Optional[Set[str]]]:
"""Return a pair (`defined_nonterminals`, `used_nonterminals`) in `grammar`.
In case of error, return (`None`, `None`)."""
defined_nonterminals = set()
used_nonterminals = {start_symbol}
for defined_nonterminal in grammar:
defined_nonterminals.add(defined_nonterminal)
expansions = grammar[defined_nonterminal]
if not isinstance(expansions, list):
print(repr(defined_nonterminal) + ": expansion is not a list",
file=sys.stderr)
return None, None
if len(expansions) == 0:
print(repr(defined_nonterminal) + ": expansion list empty",
file=sys.stderr)
return None, None
for expansion in expansions:
if isinstance(expansion, tuple):
expansion = expansion[0]
if not isinstance(expansion, str):
print(repr(defined_nonterminal) + ": "
+ repr(expansion) + ": not a string",
file=sys.stderr)
return None, None
for used_nonterminal in nonterminals(expansion):
used_nonterminals.add(used_nonterminal)
return defined_nonterminals, used_nonterminals
def reachable_nonterminals(grammar: Grammar,
start_symbol: str = START_SYMBOL) -> Set[str]:
reachable = set()
def _find_reachable_nonterminals(grammar, symbol):
nonlocal reachable
reachable.add(symbol)
for expansion in grammar.get(symbol, []):
for nonterminal in nonterminals(expansion):
if nonterminal not in reachable:
_find_reachable_nonterminals(grammar, nonterminal)
_find_reachable_nonterminals(grammar, start_symbol)
return reachable
def unreachable_nonterminals(grammar: Grammar,
start_symbol=START_SYMBOL) -> Set[str]:
return grammar.keys() - reachable_nonterminals(grammar, start_symbol)
def opts_used(grammar: Grammar) -> Set[str]:
used_opts = set()
for symbol in grammar:
for expansion in grammar[symbol]:
used_opts |= set(exp_opts(expansion).keys())
return used_opts
# Grammar的合法性判断,类似于编译器里面的语法检查
def is_valid_grammar(grammar: Grammar,
start_symbol: str = START_SYMBOL,
supported_opts: Set[str] = set()) -> bool:
"""Check if the given `grammar` is valid.
`start_symbol`: optional start symbol (default: `<start>`)
`supported_opts`: options supported (default: none)"""
defined_nonterminals, used_nonterminals = \
def_used_nonterminals(grammar, start_symbol)
if defined_nonterminals is None or used_nonterminals is None:
return False
# Do not complain about '<start>' being not used,
# even if start_symbol is different
if START_SYMBOL in grammar:
used_nonterminals.add(START_SYMBOL)
for unused_nonterminal in defined_nonterminals - used_nonterminals:
print(repr(unused_nonterminal) + ": defined, but not used",
file=sys.stderr)
for undefined_nonterminal in used_nonterminals - defined_nonterminals:
print(repr(undefined_nonterminal) + ": used, but not defined",
file=sys.stderr)
# Symbols must be reachable either from <start> or given start symbol
unreachable = unreachable_nonterminals(grammar, start_symbol)
msg_start_symbol = start_symbol
if START_SYMBOL in grammar:
unreachable = unreachable - \
reachable_nonterminals(grammar, START_SYMBOL)
if start_symbol != START_SYMBOL:
msg_start_symbol += " or " + START_SYMBOL
for unreachable_nonterminal in unreachable:
print(repr(unreachable_nonterminal) + ": unreachable from " + msg_start_symbol,
file=sys.stderr)
used_but_not_supported_opts = set()
if len(supported_opts) > 0:
used_but_not_supported_opts = opts_used(
grammar).difference(supported_opts)
for opt in used_but_not_supported_opts:
print(
"warning: option " +
repr(opt) +
" is not supported",
file=sys.stderr)
return used_nonterminals == defined_nonterminals and len(unreachable) == 0以上列举的是常用的Tools,在Fuzz的编写过程中,要根据实际问题针对性的编写各式各样的工具。
高效Grammars Fuzz
前面提供的simple_grammar_fuzzer其实存在大量的问题,比如性能低下,对于符号的解析次数受限,容易引起报错等,因此需要更加高明的算法。这里选择的是派生树,因为树形结构易于追踪而且易于添加和删除其中分支。关于Fuzz的编写其实就是不断的对派生树进行分析和对子节点的不断扩展。
派生树算法
从上述的简单算法可以看出,整个的Grammar Fuzz的核心其实就是通过大量的符号扩展形成对应的数据结构,那么用来存储或者拓展符号的数据结构其实尤为重要。派生树的树状结构其实完美的符合了我们的要求,树形结构自上而下的扩展正好和符号的扩展相对应。而且派生树使得我们可以掌控整个扩展过程的状态,比如那些节点已经被扩展,或者某个节点是否需要扩展等,同时,在扩展过程中增加新节点的速度远超把一个符号替换为一个值的过程,因此使用这种数据结构也带来了一定的性能增益。
让我们以下面的Grammar为例子:
# URL Grammar
URL_GRAMMAR: Grammar = {
"<start>":
["<url>"],
"<url>":
["<scheme>://<authority><path><query>"],
"<scheme>":
["http", "https", "ftp", "ftps"],
"<authority>":
["<host>", "<host>:<port>", "<userinfo>@<host>", "<userinfo>@<host>:<port>"],
"<host>": # 大部分情况下其实可以指定一个URL
["cispa.saarland", "www.google.com", "fuzzingbook.com"],
"<port>":
["80", "8080", "<nat>"],
"<nat>":
["<digit>", "<digit><digit>"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
"<userinfo>": # Just one
["user:password"],
"<path>": # Just a few
["", "/", "/<id>"],
"<id>": # Just a few
["abc", "def", "x<digit><digit>"],
"<query>":
["", "?<params>"],
"<params>":
["<param>", "<param>&<params>"],
"<param>": # Just a few
["<id>=<id>", "<id>=<nat>"],
}以派生树算法来看,首先以<start>为初始节点,然后在Grammar中发现其存在对应的表达,所以就会选择<url>作为它的子节点,循环往复知道一个节点不再出现对应的子节点,然后整个的树形结构完成解析,输出对应的结构化数据。
对应的数据表示如下:
(SYMBOL_NAME, CHILDREN)
DerivationTree = Tuple[str, Optional[List[Any]]]
derivation_tree: DerivationTree = ("<start>",
[("<expr>",
[("<expr>", None),
(" + ", []),
("<term>", None)]
)])SYMBOL_NAME代表的就是符号,CHILDREN代表子节点,表示为具体的数据结构就是:DerivationTree = Tuple[str, Optional[List[Any]]]。其中CHILDREN主要有两种表示:
- None代表当前节点可以继续向下扩展,其含义就是现在节点存在可扩展的符号。
- []代表的就是没有子节点了
整个算法都围绕上面的基本原理展开
def g_rammar_fuzzer():
f = GrammarFuzzer(URL_GRAMMAR)
f.fuzz()ProbabilisticGrammarFuzzer
有时候完全随机的进行表达式展开其实会白白浪费大量的时间和资源,因此可以对表达式附加概率值,这一块涉及到大量的概率学问题,有部分数据来源于世界的统计规律,比如下面给出的leaddigit符号对应的概率,这些就不在深入分析。
PROBABILISTIC_EXPR_GRAMMAR: Grammar = {
"<start>":
["<expr>"],
"<expr>":
[("<term> + <expr>", opts(prob=0.1)),
("<term> - <expr>", opts(prob=0.2)),
"<term>"],
"<term>":
[("<factor> * <term>", opts(prob=0.1)),
("<factor> / <term>", opts(prob=0.1)),
"<factor>"
],
"<factor>":
["+<factor>", "-<factor>", "(<expr>)",
"<leadinteger>", "<leadinteger>.<integer>"],
"<leadinteger>":
["<leaddigit><integer>", "<leaddigit>"],
# Benford's law: frequency distribution of leading digits
"<leaddigit>":
[("1", opts(prob=0.301)),
("2", opts(prob=0.176)),
("3", opts(prob=0.125)),
("4", opts(prob=0.097)),
("5", opts(prob=0.079)),
("6", opts(prob=0.067)),
("7", opts(prob=0.058)),
("8", opts(prob=0.051)),
("9", opts(prob=0.046)),
],
# Remaining digits are equally distributed
"<integer>":
["<digit><integer>", "<digit>"],
"<digit>":
["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
}跟之前的Grammar有很大不同的地方在于,现在的Grammar可以通过增加注释的方式为列表中的值添加随机概率,使得作者可以通过逆向获取其它渠道得到的信息可以在Fuzz中获得利用。那现在问题就显而易见了,如何确定概率?
当Fuzz的作者没办法直接给出一个符号对应的所有项具体的概率的时候,可以遵循的最直接的规则就是下面三个公式:
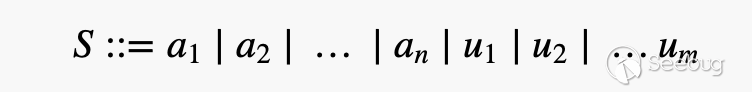
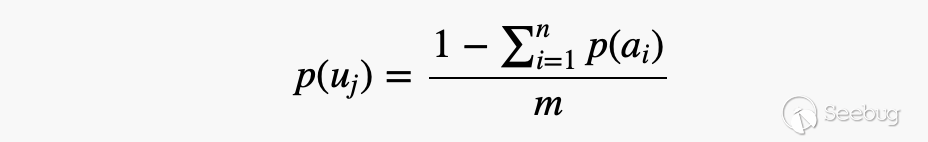
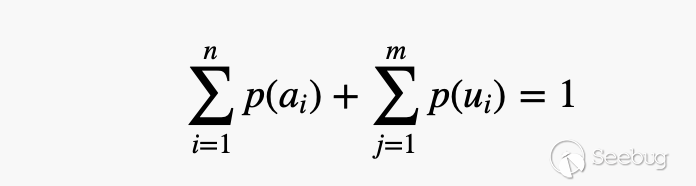
大致含义也很好理解,就是a代表的是已知概率的项,而u代表的未知概率的项目,已知概率自然可以通过opts的方法给对应项附加概率,未知概率的项则按照概率平分的原则来赋予概率。之后自然是要在Fuzz里面引入概率,使得在生成种子的时候可以对符号解析的选择赋予权重,进而提高Fuzz效率。
就Fuzz的具体实现而言,其实相比于上述的Grammar Fuzz只是增加了一个对于opts注释的访问,以便在随机解析的时候可以附加概率值权重。但是这样带来的优势是很明显的,甚至可以通过控制输入Fuzz目标指定的Func等。但是还有一种情况,我第一次解析Grammar symbol的时候希望它的概率为0.3,但是我第二次解析Grammar symbol的时候希望其概率为0.5,为了实现这一点其实可以利用上下文,在不同的上下文中复制希望赋予其不同概率的symbol,以IP Grammar为例子:
IP_ADDRESS_GRAMMAR: Grammar = {
"<start>": ["<address>"],
"<address>": ["<octet>.<octet>.<octet>.<octet>"],
# ["0", "1", "2", ..., "255"]
"<octet>": decrange(0, 256) # 其实代表的就是0-256
}为了使得每次解析<octet>的时候都使用不同的概率,可以对其扩展,形成下面的语法:
IP_ADDRESS_GRAMMAR: Grammar = {
"<start>": ["<address>"],
"<address>": ["<octet-1>.<octet-2>.<octet-3>.<octet-4>"],
# ["0", "1", "2", ..., "255"]
"<octet-1>": decrange(0, 256) # 其实代表的就是0-256
"<octet-2>": decrange(0, 256) # 其实代表的就是0-256
"<octet-3>": decrange(0, 256) # 其实代表的就是0-256
"<octet-4>": decrange(0, 256) # 其实代表的就是0-256
}这样在进行解析的时候就完全可以对每次解析附加不同的概率。下面是帮助实现的函数:
def _duplicate_context(grammar: Grammar,
orig_grammar: Grammar,
symbol: str,
expansion: Optional[Expansion],
depth: Union[float, int],
seen: Dict[str, str]) -> None:
"""Helper function for `duplicate_context()`"""
for i in range(len(grammar[symbol])):
if expansion is None or grammar[symbol][i] == expansion:
new_expansion = ""
for (s, c) in expansion_to_children(grammar[symbol][i]):
if s in seen: # Duplicated already
new_expansion += seen[s]
elif c == [] or depth == 0: # Terminal symbol or end of recursion
new_expansion += s
else: # Nonterminal symbol - duplicate
# Add new symbol with copy of rule
new_s = new_symbol(grammar, s)
grammar[new_s] = copy.deepcopy(orig_grammar[s])
# Duplicate its expansions recursively
# {**seen, **{s: new_s}} is seen + {s: new_s}
_duplicate_context(grammar, orig_grammar, new_s, expansion=None,
depth=depth - 1, seen={**seen, **{s: new_s}})
new_expansion += new_s
grammar[symbol][i] = new_expansion
def duplicate_context(grammar: Grammar,
symbol: str,
expansion: Optional[Expansion] = None,
depth: Union[float, int] = float('inf')):
"""Duplicate an expansion within a grammar.
In the given grammar, take the given expansion of the given `symbol`
(if `expansion` is omitted: all symbols), and replace it with a
new expansion referring to a duplicate of all originally referenced rules.
If `depth` is given, limit duplication to `depth` references
(default: unlimited)
"""
orig_grammar = extend_grammar(grammar)
_duplicate_context(grammar, orig_grammar, symbol,
expansion, depth, seen={})
# After duplication, we may have unreachable rules; delete them
for nonterminal in unreachable_nonterminals(grammar):
del grammar[nonterminal]在完成上下文复制之后就可以通过类似下面的操作得到我们想要的结果:
set_prob(probabilistic_ip_address_grammar, "<octet-1>", "127", 1.0)
set_prob(probabilistic_ip_address_grammar, "<octet-2>", "0", 1.0)不过这就又引入一个问题,概率在赋予给symbol之后一成不变真的合适吗?在真实世界的Fuzz中随着我们对于目标的不断了解,或者一些其它情况比如长时间未出现想要的结果等,及时改变策略也是非常必要的,但是如果Fuzz可以智能的自己调节调整不同symbol的概率值的话,会减轻很多的负担并获得更好的软件测试效果。一个比较好的办法是让Fuzz通过最开始被给予Inputs种子来学习应该赋予某些symbol多大的一个概率值,这种方法在某些场景下非常有用:
- 测试常用功能,因为很多软件测试更希望常用的功能确保安全,但是对于漏洞挖掘研究人员来说可能目标不在于此。
- 测试不常用功能,通过规避Inputs中解析到的symbol,Fuzz就会更偏向于测试一些不常用的功能。
- 专注于指定的Inputs,一些漏洞挖掘可能希望专注于已有的非常有价值的poc inputs,通过专注于这些inputs,Fuzz可以测试软件的一些薄弱环节从而达到很好的效果。
理论已经存在,那么如何实现呢?第一步肯定是需要将已经存在的Inputs种子恢复成为派生树,然后对派生树种每个Symbol对应的值有多少来计算将来的概率值。
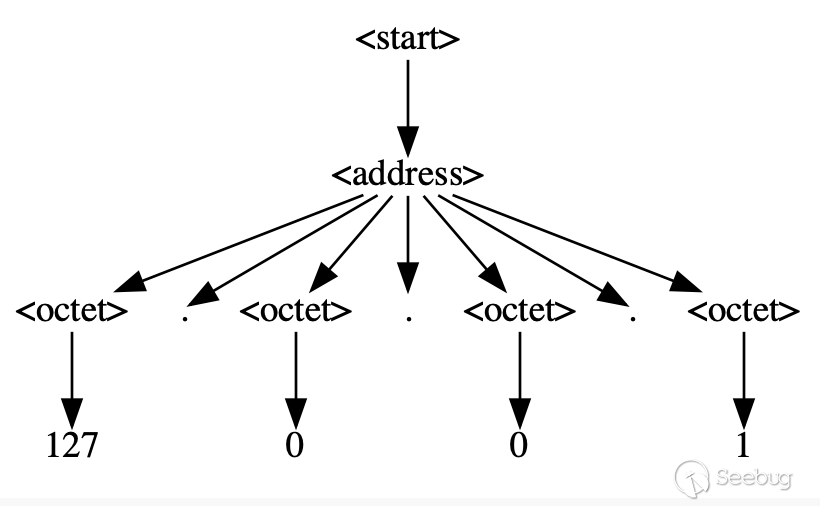
如上图,假设我给与一个127.0.0.1的种子,那么被解析之后,0在<octet>中的概率值就会被限制为50%,127和1分别为25%,那么在Fuzz运行的时候相关的概率值就可以赋予给<octet>。那么如果测试一些不常用功能该怎么办呢?其实就是通过原来测常用功能的Inputs得到相关概率,然后进行概率翻转就行了,比如常用功能的Inputs概率如下:
[('http', {'prob': 0.2222222222222222}),
('https', {'prob': 0.6666666666666666}),
('ftp', {'prob': 0.0}),
('ftps', {'prob': 0.1111111111111111})]那么经过翻转之后就是:
[('http', {'prob': 0.1111111111111111}),
('https', {'prob': 0.0}),
('ftp', {'prob': 0.6666666666666666}),
('ftps', {'prob': 0.2222222222222222})]上述就是之前讲到的专注测试常用功能或者非常用功能的基本思路,从此处引出的另一个比较关键的是通过Inputs帮我们专注于目标的特定功能,它和测试常用功能的区别就是首先要找到一批特殊的Inputs,通过这些Inputs作为seeds就可以对语法解析的过程进行概率分析和限制,使得后续的变异可以一直有较高的目标命中率。
Generator With Pre or Post or order Func
在某些Inputs在生成的时候,Fuzz作者可能希望对他们进行一些限制调整,获取其它的操作,这些都可以通过pre func完成。这类似于hook,那么对于func触发的时机一般就分为两种,在Inputs的生成之前或者是生成之后,在语法里面的表示就是:
CHARGE_GRAMMAR: Grammar = {
"<start>": ["Charge <amount> to my credit card <credit-card-number>"],
"<amount>": ["$<float>"],
"<float>": ["<integer>.<digit><digit>"],
"<integer>": ["<digit>", "<integer><digit>"],
"<digit>": crange('0', '9'),
"<credit-card-number>": ["<digits>"],
"<digits>": ["<digit-block><digit-block><digit-block><digit-block>"],
"<digit-block>": ["<digit><digit><digit><digit>"],
}
CHARGE_GRAMMAR.update({
"<float>": [("<integer>.<digit><digit>", opts(pre=high_charge))], # high_charge是函数名称
})
CHARGE_GRAMMAR.update({
"<float>": [("<integer>.<digit><digit>",
opts(pre=lambda: random.randint(10000000, 90000000) / 100.0))] # 或者选择使用lambda表达式
})另一种就是在Seeds的生成之后了:
CHARGE_GRAMMAR.update({
"<credit-card-number>": [("<digits>", opts(post=lambda digits: fix_credit_card(digits)))]
})比如生成的digits不能满足Fuzz的需求,我们就可以通过这种方式来进行及时的修正,以提高Fuzz的效率。
Greybox Fuzzing with Grammars
除了Fuzzing性能类的问题之外的另一个问题就是变异的导向问题,在Grammars Fuzz生成Input的过程中对于Grammar的内部解析是随机的,但是对于Fuzz目标来说,大量的Input可能会触发相同的分支进而导致代码覆盖率难以达到理想的值。对于AFL类似的覆盖引导型Fuzz来说,因为白盒Fuzz的源代码插桩缘故可以统计代码覆盖率来进行不错的引导,但是还存在很多情况,比如黑盒,甚至是以一种WebServer为目标的Fuzz,统计代码覆盖率并不是一件简单的事情,这时候采取的措施应该是不断的增加Inputs生成的多样性,比如在上述的派生树的子节点的扩展过程进行统计,使其在生成Input语料的时候偏向于还没扩展过的节点。这时候就会面临新的问题,如何快速提升代码覆盖率?
在进行Fuzz的时候,有时候一些输入的部分会被识别为关键字,比如C语言里面的int等,如果告诉Fuzz这些关键字就可以在短时间内极大的提升代码覆盖率,但是就长远来看整体的代码覆盖率还是要差于不使用关键字字典的情况。下面是使用关键字字典的变异Inputs生成器。
class DictMutator(Mutator):
"""Mutate strings using keywords from a dictionary"""
def __init__(self, dictionary: List[str]) -> None:
"""Constructor. `dictionary` is the list of keywords to use."""
super().__init__()
self.dictionary = dictionary
self.mutators.append(self.insert_from_dictionary)
def insert_from_dictionary(self, s: str) -> str:
"""Returns s with a keyword from the dictionary inserted"""
pos = random.randint(0, len(s))
random_keyword = random.choice(self.dictionary)
return s[:pos] + random_keyword + s[pos:]但是问题在于关键字通过字典随机引入的方式很可能破坏了Input本来的正确输入结构进而引发不必要的损耗。解决的方法其实也很简单:Fuzzing with Input Fragments.
- 对原有的Input进行Parse,形成派生树。
- 对派生树进行节点互换或者节点替换等操作。
- 对派生树进行还原,形成新的Input。
以上的所有操作都在派生树上进行。为了更方便的进行编译操作,可以建立一个派生树的碎片池,每个碎片都由子树组成,子树包括符号和对应的Node节点和其子节点。不过对于派生树的parse其实是非常耗时的,因此可以设置一些时间限制来防止速度过低。不过以Fragments为基础的变异虽然可以很好的符合Inputs合法性的要求但是在代码覆盖率提升方面并不亮眼。而且以此为基础的LangFuzz其实在Inputs生成的速度上也远低于平常的结构化黑盒Fuzz。下面是两组对比数据:
LangFuzz
From the 300 generated inputs, 152 (50.67%) can be parsed.In total, 91 statements are covered.
BlackFuzz
From the 300 generated inputs, 36 (12.00%) can be parsed.In total, 161 statements are covered.可以看出以Fragments为基础的变异的优势在于它可以很好的生成符合结构化语法的变异。那么现在的疑问就是如何在保证输入语法正确性的前提下提升代码覆盖率?
一种方法是利用类似AFL的覆盖引导方式,利用代码覆盖率不断作为变异的反馈,以此来不断的增添提高代码覆盖率的种子,同时提供structural mutations和32 byte-level mutations两种变异方式,如下:
class GreyboxGrammarFuzzer(GreyboxFuzzer):
"""Greybox fuzzer using grammars."""
def __init__(self, seeds: List[str],
byte_mutator: Mutator, tree_mutator: FragmentMutator,
schedule: PowerSchedule) -> None:
"""Constructor.
`seeds` - set of inputs to mutate.
`byte_mutator` - a byte-level mutator.
`tree_mutator` = a tree-level mutator.
`schedule` - a power schedule.
"""
super().__init__(seeds, byte_mutator, schedule)
self.tree_mutator = tree_mutator
def create_candidate(self) -> str:
"""Returns an input generated by structural mutation
of a seed in the population"""
seed = cast(SeedWithStructure, self.schedule.choose(self.population))
# Structural mutation
trials = random.randint(0, 4)
for i in range(trials):
seed = self.tree_mutator.mutate(seed)
# Byte-level mutation
candidate = seed.data
if trials == 0 or not seed.has_structure or random.randint(0, 1) == 1:
dumb_trials = min(len(seed.data), 1 << random.randint(1, 5))
for i in range(dumb_trials):
candidate = self.mutator.mutate(candidate)
return candidate想通的种子和变异次数的条件下,测试结果如下:
From the 300 generated inputs, 1 (0.33%) can be parsed.
In total, 180 statements are covered.同时,在Inputs生成的速度方面极大提升,较高的代码覆盖率,但是在Inputs的合法性方面表现是最差的。那这个问题该如何解决呢?答案就是Fuzzing with Input Regions,这种Fuzz的变异方法不再使用派生树节点拆分重组等方式,而是通过将合法种子的不同区域直接进行拆分重组的方式,这里的区域指的是可以和派生树符号对应的连续的字节序列,这样的好处其实在于它操作的对象可能比Fragments更大或者更小,以此种方式进行变异在和上述变异条件相同的情况下测试结构如下:
It took the structural greybox fuzzer with region mutator
11.35 seconds to generate and execute 300 inputs.
From the 300 generated inputs, 4 (1.33%) can be parsed.
In total, 168 statements are covered.
On average, 9.1% of a seed in the population can be successfully parsed.可以看到存在较高的代码覆盖率,在速度方面虽然优于Fragments Fuzz但是还是弱于普通的黑盒Fuzz,在代码覆盖率方面高于Fragments Fuzz并和GreyboxGrammarFuzzer维持在相差无几的水平。不过核心原因还是在于,通过的合法Inputs其实占比很低。那么如何解决这个问题?首先要让Fuzzer可以聚焦合法的Inputs。这一点其实前面已经讨论过了,只需要利用schedule给合法Inputs的相关结构赋予更多的权重。测试结果如下:
It took AFLSmart 20.75 seconds to generate and execute 300 inputs.
From the 300 generated inputs, 46 (15.33%) can be parsed.
In total, 162 statements are covered.
On average, 23.7% of a seed in the population can be successfully parsed.可以看出在代码覆盖率保持较高水平的情况下,Inputs的合法性也得到了大幅度的提升,但是在Inputs的生成速度上来看,还是远弱于普通的GrammarFuzz。
从上面可以看出,在选择Fuzz的时候本身就是一个取舍的问题,通过二次开发或者针对不同场景的选择才能更好的达到我们想要的结果。
Parser input
假设你在做一个模糊测试,无论是Grammar Fuzz 或者其他的Fuzz也好,如果没有合适的种子那么通过不断变异形成合适的Inputs是非常困难的,当然AFL的作者展示了通过简单的输入不断向目标进化的可能性,但是这毕竟十分浪费时间和性能,效果在很多场景下估计也是不尽人意的。
因此在进行模糊测试的时候如果可以获取一些poc,或者其它较好种子,比如在Fuzz js解释器的一个比较经常的做法就是将一些公开的poc,如下:
var haystack = "foo";
var re_text = "^foo";
haystack += "x";
re_text += "(x)";
var re = new RegExp(re_text);
re.test(haystack);
RegExp.input = Number();
print(RegExp.$1);作为seeds进行变异,将生成的Inputs用来Fuzz解释器。表现出来不错的结果。
Tips:如何判断对面的代码覆盖率,一般黑盒情况下可以试时间,如果一个Input在对面耗费了更多的时间来运行,那么可以猜测其走过了更多的代码分支。
总结
在面对Fuzz的目标的时候最重要的是选择合适的变异方式以及较好的初始种子,根据目标和测试目的不断地进行取舍和针对性开发才能得到比较理想的结果。
参考链接
文中数据测试来源大多为Fuzzingbook,因为根据电脑不同,其实具体数值结果会有一定偏差,但是结论都是一样的,因此就展示了书中的测试数据。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1942/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1942/