Cannoli是一款面向qemu用户的高性能跟踪引擎,是一个 Rust 编写的 Python(Python 3.6.5) 编译器,旨在评估对性能有负面影响的 Python 语言特性。它可以记录所执行的 PC 以及内存操作的轨迹。
Cannoli 旨在以最小的 QEMU 执行干扰记录这些信息。这意味着 QEMU 需要产生一个事件流,并将它们移交给另一个进程来处理更复杂的事件分析。在QEMU JIT执行期间进行分析会大大降低执行速度。
Cannoli可以每秒处理数十亿条目标指令,可以处理多线程qemu-user应用程序,并允许多个线程使用来自单个QEMU线程的数据以并行处理跟踪。
性能要求
QEMU中有一个trace模块,可以对于一些函数进行跟踪,例如qemu_malloc, qemu_free等,对于QEMU本身的调试很用帮助。跟踪的一个大问题就是性能。许多简单的解决方案(如使用Unicorn进行模拟)可能导致每秒只能得到100万条左右的模拟指令。这听起来可能很多,但是现代的x86处理器通常每个周期执行2条指令。如果你在4 GHz处理器上运行,运行或启动需要1秒,通常会执行50 -100亿条指令。简而言之,以每秒 1000 万条指令的速度跟踪这样的事情对于任何开发或研究周期来说都是非常缓慢的。
仅仅试图获取 PC 的执行指令地址的完整日志通常就很困难,更不用说记录所有内存访问。
这就不得不用到Cannoli了!
Cannoli 能够执行 QEMU 的完整跟踪,比基本 QEMU 执行速度降低约 20-80%。这意味着每秒可以获得大约 10 亿条目标指令。不过,这会因你的 CPU 时钟频率、系统噪声等而有很大差异。我们稍后会详细介绍性能,因为存在很多细微差别。Cannoli 经过精心设计,可以将超过 20 GiB/s的数据从单个 QEMU 线程流式传输到多线程跟踪分析过程。
QEMU 补丁
作为用户,最好打个补丁,其中包含大约 200 行新添加的内容。这些都是用#ifdef CANNOLI进行控制的,这样,如果CANNOLI没有定义,QEMU构建时就完全等同于没有任何补丁。
这些补丁与用户没有太大的相关性,只是知道它们向QEMU添加了一个-cannoli标志,该标志期望获得到共享库的路径。这个共享库被加载到QEMU中,并在JIT的不同位置调用
要打补丁,运行执行以下命令:
git am qemu_patches.patch
Cannoli服务器
加载到 QEMU 中的共享库称为 Cannoli 服务器。该库在 cannoli_server/src/lib.rs 中公开了两个基本回调函数。

这些挂钩为用户提供了一个机会来决定是否应该挂钩给定的指令或内存访问。返回 true(默认值)会导致检测指令。返回 false 意味着没有向 JIT 添加任何检测,因此QEMU以高速模拟的方式运行。
当QEMU提取目标指令时,将调用此API。在这种情况下,提取是模拟器的核心操作,它在其中反汇编目标指令,并将其转换为 IL 或 JIT 到另一个架构中执行。由于QEMU缓存它已经提取的指令,这些函数被称为"rarely"(与指令本身执行的频率有关),因此这是你应该放入智能逻辑以过滤挂钩内容的位置。
如果挂载少量指令,该工具的性能消耗几乎为零。Cannoli旨在为完全跟踪提供非常低的消耗,但是如果你不需要完全跟踪,你应该在这个阶段进行过滤。这从一开始就防止了JIT被检测到,并为最终用户提供了一种过滤机制。
Cannoli客户端
然后 Cannoli 有一个客户端组件,客户端的目标是处理 QEMU 产生的海量数据流。此外,Cannoli 的 API 在设计时考虑了线程,因此单个线程可以在 qemu-user 中运行,并且可以通过线程化分析来完成对该流的复杂分析,同时在 QEMU 本身中获得最大的单核性能。
Cannoli 公开了一个标准的 Rust 特征样式接口,你可以在你的结构上实现Cannoli。作为这个特征的实现者,你必须实现 init。这是你为单线程可变上下文 Self 以及多线程共享不可变上下文 Self::Context 创建结构的位置。
然后,你可以选择实现以下回调:

这些回调是相对不言自明的,除了线程方面。三个主要的执行回调 exec、read 和 write 可以从多个线程并行调用。因此,这些不是按顺序调用的。这是应该进行无状态处理的地方。它们也只有对 Self::Context 的不可变访问,因为它们是并行运行的。这是进行任何不需要知道指令或内存访问的顺序/顺序的处理的正确位置。例如,应在此处完成从 pc 转换为符号 + 地址的符号应用,以便你可以进行符号化跟踪。
所有主要的回调,exec、read 和 write,都返回一个 Option
然后,该跟踪通过跟踪回调完全按顺序向用户公开。跟踪回调函数是从各种线程调用的,例如,你可能在不同的 TID 中运行,但是,它是否确保始终按顺序和相对于执行的顺序调用。因此,你可以获得对 self 的可变访问,以及对共享 Self::Context 的引用。
我知道这是一个奇怪的API,但它有效地允许并行处理跟踪,直到你绝对需要它是连续的。我希望它不会让最终用户感到困惑,但是处理10亿条指令/秒的数据需要在消费者端进行线程处理,否则QEMU就会成为瓶颈!
注意:除非另有说明,否则此处的性能数据是基于我的 Intel(R) Xeon(R) Silver 4310 CPU @ 2.10GHz。启用超线程,启用 turbo,128 GiB RAM @ 2667 MHz w/ 8内存通道。
在高层次上,整个设计围绕着大量数据的运营程序(在 JIT 中运行的 QEMU 线程)。对于 Cannoli,我们专门针对 QEMU 的 QEMU 单线程吞吐量进行优化,以便我们可以对长时间运行或大型进程(如 Web 浏览器)进行内省。
这与缩放不同,在缩放中你并不真正关心单个线程的性能,而是整个系统。在我们的示例中,我们希望支持每秒从单个 QEMU 线程流式传输数十亿条指令,同时使用线程用户对这些数据进行相对复杂的分析。
基本基准
在examples/benchmark中,你可以找到一个运行小mipsel二进制文件的基准,该二进制文件只是在一个循环中执行一堆 nop。这意味着对PC跟踪的性能进行基准测试。
要使用此基准,请启动基准客户端:
cd examples/benchmark && cargo run --release
然后使用 cannoli'd QEMU 运行基准测试!
/home/pleb/qemu/build/qemu-mipsel -cannoli ~/cannoli/target/release/libcannoli_server.so ./benchmark
在示例中,我得到以下信息(在我的例子中,我使用了benchmark_graph)。

在单个QEMU线程上跟踪大约每秒22亿条指令。
Mempipe
在低性能消耗的情况下获得这种级别的跟踪需要一些非常独特的设计。Cannoli的核心是一个名为mempipe的库。在高层次上,这是一种延迟极低的共享内存IPC机制。
最重要的是,JIT 挂钩的设计是尽可能地减少消耗,特别注意分支预测、代码大小(用于减少 icache 污染)等细节,并注意目标架构的位数以减少运行 32 位目标时产生的数据量。
事实上,你会发现几乎所有的 API,除了高级 Cannoli 特征,利用 Rust 宏定义相同代码的两个副本,一个用于 32 位目标,一个用于 64 位目标。这略微增加了代码复杂性,但当我们饱和内存带宽时,我们希望特殊情况下,32位目标产生的有效数据只有1/2小指针大小。
核心 mempipe IPC 机制允许在适合 L1 缓存的进程之间传输缓冲区。由于这些缓冲区非常小,IPC 数据包的频率非常高。这很难实现。我可以对1字节的有效负载每秒进行大约1000万次传输。这有效地饱和了英特尔芯片对缓存一致性通信量所能做的事情。
缓存一致性
如果你不熟悉缓存一致性,那么你的处理器就是这样做的,以确保内存在所有处理器上都是相同的值,即使它存储在多个缓存中。
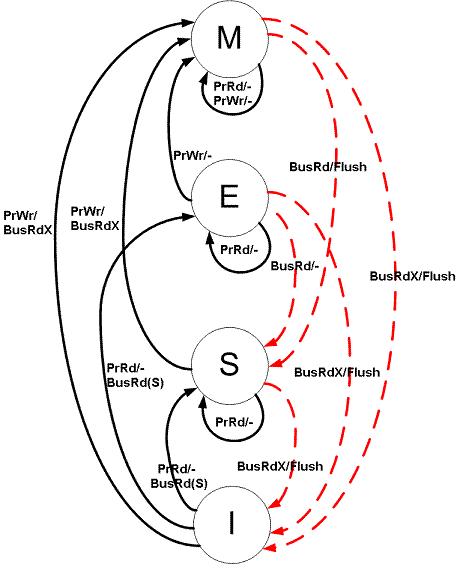
简单的模型是 MESI 模型。这定义了每个缓存行可以处于的状态。
Modified ——存储在高速缓存行中的数据是唯一准确的内存副本;
Exclusive ——存储在缓存行中的数据是干净的(缓存行和内存中的数据相同),这是系统上缓存行中内存的唯一副本;
Shared ——存储在高速缓存行中的数据是干净的,并且系统上有多个不同的高速缓存存储相同的信息;
Invalid ——在软件层面对我们没有任何意义,它只是意味着缓存行未使用;

现在,现代处理器使用稍微复杂一些的缓存一致性模型,但我们在这里不做深入探讨。本质上是一样的。
需要注意的是,任何时候内核需要同步它们的缓存,它们需要访问L2缓存,有时甚至需要访问内存。
进入修改状态需要大量的性能消耗。想想看,为了获得对内存的独占访问,你必须有效地使用锁来获得控制。从硬件的角度来看,你必须告诉其他所有的核心使其对给定行的缓存无效,并且在其他核心这样做之前你不能获得所有权。这实际上类似于执行 Mutex::lock()。
然而,从专用到修改是便宜的。这是专用 MESI 状态的全部意义所在。它允许处理器知道它在转换到修改时不必通知其他内核,因为它已经知道是内存的唯一副本。
之所以谈这个,是因为在进行 IPC 时,缓存一致性很重要。至关重要的是,在我们的热循环中,我们不会导致缓存一致性流量。从更高的层次上来说,这意味着我们需要能够通过只读方式对所有数据结构进行热轮询。这允许多个用户线程轮询邮箱(例如,所有用户都在轮询处于共享状态的缓存行)。当产生一个完整的缓冲区时,才会消耗写入内存的缓存一致性。运营程序刷新缓冲区的行为将导致所有用户核心的缓存失效,并且他们必须在后续访问时通过 L2 获取内存。此获取也必须将运营程序的缓存状态从modified更改为shared。
因此,我们设计了 mempipe 库来轮询一组邮箱,该邮箱保证与正在传输的数据位于不同的缓存行上。如果我们将传输缓冲区与邮箱放在同一缓存行上,那么将会出现严重的缓存不稳。
本文翻译自:https://margin.re/blog/cannoli-the-fast-qemu-tracer.aspx如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh