作者:时钟@RainSec
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]
go-fuzz
Go-fuzz的原理很多都是基于AFL,这里只分析了一些它独特的地方,收获很多,也希望可以和大家交流,如有分析错误还望交流指正。
go-fuzz是google开源的一款go语言fuzz框架,它和AFL很大的一个不同是在于,AFL通常通过对未修改的文件的输入进行操作,而go-fuzz需要你编写一个Fuzz函数,go-fuzz通过不断的调用该函数来进行fuzz,前者通常会为每一个输入创建一个新的进程,后者则是不断的调用Fuzz函数因此不需要经常启动或者重启进程。
什么是覆盖引导型Fuzz
覆盖引导型Fuzz通过代码覆盖率信息来决定一个突变是否有效,如果代码覆盖率增长就保存该输入并对其进行持续变异,否则就丢弃该变异:



源码解析
go-fuzz-build模块
该模块的主要作用在于将需要测试的包信息和测试用例信息打包方便进行测试。
- 利用PProf进行性能分析
- 加载选中的go语言包和github.com/dvyukov/go-fuzz/go-fuzz-dep这个fuzz材料包
- 遍历加载的go语言包里面所有的函数名查找所有的名为Fuzz的函数,同时进行签名认证,但是Fuzz函数的个数应该大于0同时小于等于255
- 获取环境变量,大多是和go有关的环境变量.
- 加载go语言标准库
- 忽略一些标准库中的包和github.com/dvyukov/go-fuzz/go-fuzz-dep这个包,因为没有理由进行fuzz测试,为了避免陷入循环(具体为啥我也不是很清楚)
- 在/tmp下创建临时文件夹保存需要使用的tools和包
- 接下来就是很高阶的语法树等的建立过程,这个过程中会使用gatherLiterals获取到你提供的初始材料
- 获取到需要fuzz的包的具体信息,进而可以生成go-fuzz的元数据
- 将存储信息的cover.exe和sonar.exe已经metadata打包生成zip文件夹
语法树插桩实现
go语言不同于C语言可以as等汇编工具来较为方便的实现编译时插桩(具体可以参考AFL的插桩方式),为了实现go语言的编译时插桩,我们首先要了解go语言整体的编译流程:
- 词法与语法分析
- 类型检查
- 中间代码生成
- 机器码生成
那么其实大致就可以看出比较理想的地方就是词法与语法分析的时候对抽象语法书进行插桩了,同时go标准库也提供了scanner,ast和token等相关库来帮助很好的扫描,解析和创建相关抽象语法树,在整个插桩的过程中其实是把go的包一个个遍历插桩的,然后因为go-fuzz不允许导入main包,其实是因为它在插桩完成之后会自己加入相关的main函数。
在go-fuzz-build中实现了结构体File和结构体Sonar,这两个结构体都实现了自己的Visit()函数用来遍历相关的语法树:
type File struct {
fset *token.FileSet
pkg string
fullName string
astFile *ast.File
blocks *[]CoverBlock
info *types.Info
}
type Sonar struct {
fset *token.FileSet
fullName string
pkg string
blocks *[]CoverBlock
info *types.Info
}在整个的build的过程中也会生成coverBin和sonarBin两个文件分别对应上述两个结构体的语法树遍历函数执行结果。
File遍历
在生成coverBin的时候使用的是File结构体对应的Visit遍历函数,不过在开始遍历之前会通过自身实现的addImport来实现go-fuzz-dep包相关内容的导入:
file.addImport("go-fuzz-dep", fuzzdepPkg, "CoverTab")
func (f *File) addImport(path, name, anyIdent string) {
newImport := &ast.ImportSpec{
Name: ast.NewIdent(name),
Path: &ast.BasicLit{
Kind: token.STRING,
Value: fmt.Sprintf("%q", path),
},
}
impDecl := &ast.GenDecl{
Lparen: f.astFile.Name.End(),
Tok: token.IMPORT,
Specs: []ast.Spec{
newImport,
},
Rparen: f.astFile.Name.End(),
}
// Make the new import the first Decl in the file.
astFile := f.astFile
astFile.Decls = append(astFile.Decls, nil)
copy(astFile.Decls[1:], astFile.Decls[0:])
astFile.Decls[0] = impDecl
astFile.Imports = append(astFile.Imports, newImport)
// Now refer to the package, just in case it ends up unused.
// That is, append to the end of the file the declaration
// var _ = _cover_atomic_.AddUint32
reference := &ast.GenDecl{
Tok: token.VAR,
Specs: []ast.Spec{
&ast.ValueSpec{
Names: []*ast.Ident{
ast.NewIdent("_"),
},
Values: []ast.Expr{
&ast.SelectorExpr{
X: ast.NewIdent(name),
Sel: ast.NewIdent(anyIdent),
},
},
},
},
}
astFile.Decls = append(astFile.Decls, reference)
}观察源码其实逻辑也很简单,首先创建了一个基本声明信息节点来将相关的包导入原本的语法树中,同时为了避免导入包但是未使用,所以导入简单的声明语句。导入完成之后使用ast.Walk()来遍历语法树,该函数会调用File结构体对应的Visit函数。
// 源码太长,只贴部分
func (f *File) Visit(node ast.Node) ast.Visitor {
switch n := node.(type) {
case *ast.FuncDecl:
if n.Name.String() == "init" {
// Don't instrument init functions.
// They run regardless of what we do, so it is just noise.
return nil
}
case *ast.GenDecl:
if n.Tok != token.VAR {
return nil // constants and types are not interesting
}
case *ast.BlockStmt: // {}中间的语句
// If it's a switch or select, the body is a list of case clauses; don't tag the block itself.
if len(n.List) > 0 {
switch n.List[0].(type) {
case *ast.CaseClause: // switch
for _, n := range n.List {
clause := n.(*ast.CaseClause)
clause.Body = f.addCounters(clause.Pos(), clause.End(), clause.Body, false)
}
return f
case *ast.CommClause: // select
for _, n := range n.List {
clause := n.(*ast.CommClause)
clause.Body = f.addCounters(clause.Pos(), clause.End(), clause.Body, false)
}
return f
}
}
n.List = f.addCounters(n.Lbrace, n.Rbrace+1, n.List, true) // +1 to step past closing brace.
......
}可以看出在遍历语法树的过程中对节点的类型进行了判断,然后对{}中间的内容进行一个判断和插桩,具体的插桩函数如下:
func (f *File) addCounters(pos, blockEnd token.Pos, list []ast.Stmt, extendToClosingBrace bool) []ast.Stmt {
// Special case: make sure we add a counter to an empty block. Can't do this below
// or we will add a counter to an empty statement list after, say, a return statement.
if len(list) == 0 {
return []ast.Stmt{f.newCounter(pos, blockEnd, 0)}
}
// We have a block (statement list), but it may have several basic blocks due to the
// appearance of statements that affect the flow of control.
var newList []ast.Stmt
for {
// Find first statement that affects flow of control (break, continue, if, etc.).
// It will be the last statement of this basic block.
var last int
end := blockEnd
for last = 0; last < len(list); last++ {
end = f.statementBoundary(list[last])
if f.endsBasicSourceBlock(list[last]) {
extendToClosingBrace = false // Block is broken up now.
last++
break
}
}
if extendToClosingBrace {
end = blockEnd
}
if pos != end { // Can have no source to cover if e.g. blocks abut.
newList = append(newList, f.newCounter(pos, end, last)) // 在List里面增加counter计数器
}
newList = append(newList, list[0:last]...)
list = list[last:]
if len(list) == 0 {
break
}
pos = list[0].Pos()
}
return newList
}假设现在有一个switch的demo
func main() {
var n = 1
switch n {
case 0:
fmt.Println("this is 0")
case 1:
fmt.Println("this is 1")
}
}这一步的具体操作就是把每一个case拿出来,然后将case相关的语法树的起始位置和结束位置还有body部分全部传入addCounters,addCounters的逻辑起始也非常简单,如果body为空就直接返回一个Counter的ast.Stmt声明语法树结构,
Counter是作者自定义的一种插桩计数器,这种计数器主要包括两个部分:
- 对于每个包的File的结构体都维护了一个*[]CoverBlock,每次增加Counter都会在这个数组里面增加一个CoverBlock里面记录了插桩语法树的位置以及内部是否还包含多少其他声明。
- 一个是ast.IncDecStmt节点,这个是newCounter()函数的返回值
如果body不为空就找到所有影响控制流的声明,比如if,switch, break ,goto等都会开启或者中断一个新的控制流,找到边界声明之后判断其是否属于刚才的类型:
func (f *File) endsBasicSourceBlock(s ast.Stmt) bool {
switch s := s.(type) {
case *ast.BlockStmt:
// Treat blocks like basic blocks to avoid overlapping counters.
return true
case *ast.BranchStmt:
return true
case *ast.ForStmt:
return true
case *ast.IfStmt:
return true
case *ast.LabeledStmt:
return f.endsBasicSourceBlock(s.Stmt)
case *ast.RangeStmt:
return true
case *ast.SwitchStmt:
return true
case *ast.SelectStmt:
return true
case *ast.TypeSwitchStmt:
return true
case *ast.ExprStmt:
// Calls to panic change the flow.
// We really should verify that "panic" is the predefined function,
// but without type checking we can't and the likelihood of it being
// an actual problem is vanishingly small.
if call, ok := s.X.(*ast.CallExpr); ok {
if ident, ok := call.Fun.(*ast.Ident); ok && ident.Name == "panic" && len(call.Args) == 1 {
return true
}
}
}
found, _ := hasFuncLiteral(s)
return found
}其实就是大量的switch语句,如果是的话,就可以将直接边界作为end进行插桩,这一步的意义其实就是在于把{}里面的body不断的分割成一个个可以影响控制流的小块进行分别插桩。其实到这里我们就可以洞悉go-fuzz整个的插桩思想:在语法分析的时候就通过go-fuzz本身所包含的一个包的内容插桩到各个可以影响控制流的语句块中,那么接下来对应的工作就应该是如何对这些进行插桩语句块进行感知,这其实就是Sonar结构体的作用,这是go-fuzz发明的声呐系统。
Sonar遍历
Sonar结构体同样实现了Visit方法来用于遍历语法树,部分源码如下:
func (s *Sonar) Visit(n ast.Node) ast.Visitor {
switch nn := n.(type) {
case *ast.BinaryExpr:
break
......
case *ast.SwitchStmt:
if nn.Tag == nil || nn.Body == nil {
return s // recurse
}
// Replace:
// switch a := foo(); bar(a) {
// case x: ...
// case y: ...
// }
// with:
// switch {
// default:
// a := foo()
// __tmp := bar(a)
// switch {
// case __tmp == x: ...
// case __tmp == y: ...
// }
// }
// The == comparisons will be instrumented later when we recurse.
sw := new(ast.SwitchStmt)
*sw = *nn
var stmts []ast.Stmt
if sw.Init != nil {
stmts = append(stmts, sw.Init)
sw.Init = nil
}
const tmpvar = "__go_fuzz_tmp"
tmp := ast.NewIdent(tmpvar)
typ := s.info.Types[sw.Tag]
s.info.Types[tmp] = typ
stmts = append(stmts, &ast.AssignStmt{Lhs: []ast.Expr{tmp}, Tok: token.DEFINE, Rhs: []ast.Expr{sw.Tag}})
stmts = append(stmts, &ast.AssignStmt{Lhs: []ast.Expr{ast.NewIdent("_")}, Tok: token.ASSIGN, Rhs: []ast.Expr{tmp}})
sw.Tag = nil
stmts = append(stmts, sw)
for _, cas1 := range sw.Body.List {
cas := cas1.(*ast.CaseClause)
for i, expr := range cas.List {
tmp := &ast.Ident{Name: tmpvar, NamePos: expr.Pos()}
s.info.Types[tmp] = typ
cas.List[i] = &ast.BinaryExpr{X: tmp, Op: token.EQL, Y: expr}
}
}
nn.Tag = nil
nn.Init = nil
nn.Body = &ast.BlockStmt{List: []ast.Stmt{&ast.CaseClause{Body: stmts}}}
return s // recurse
......
}第一步先根据节点类型找到Switch和For这种结构进行语法树级别的变化,整体的替换逻辑已经在注释里面体现出来了,其实就是类似把switch的条件都提出来放在body内部,然后再body里面建立一个新的switch结构,主要作用可能就是方便识别和统计,对于ast.BinaryExpr结构则是通过自定义的flag进行标注。
整体来看其实就是对包内代码各种语法树节点进行类型检查和过滤,因为一些代码是肯定顺序执行的,然后再需要的地方都插入一些标志,同时在结构体里面记录标志的总量,方便在fuzz执行的时候确定自己的代码位置从而更方便进行统计,具体的可以细看相关代码。
插桩总结
其实无论是File还是Sonar,个人认为都算是一种插桩,方便对代码覆盖率进行统计,在结束之后都通过createFuzzMain函数进行了封装,这个地方其实也是go-fuzz不支持fuzz的代码包含main函数的具体原因:
func (c *Context) createFuzzMain() string {
mainPkg := filepath.Join(c.fuzzpkg.PkgPath, "go.fuzz.main")
path := filepath.Join(c.workdir, "gopath", "src", mainPkg)
c.mkdirAll(path)
c.writeFile(filepath.Join(path, "main.go"), c.funcMain())
return mainPkg
}其实就是将已经写好的main函数模板写入:
var ainSrc = template.Must(template.New("main").Parse(`
package main
import (
target "{{.Pkg}}"
dep "go-fuzz-dep"
)
func main() {
fns := []func([]byte)int {
{{range .AllFuncs}}
target.{{.}},
{{end}}
}
dep.Main(fns)
}
`))主要作用还是调用包内的Fuzz代码。
go-fuzz
- 首先通过丢弃触发相同代码路径的的样本来最小化语料库。
- 开始改变输入并将数据传递给Fuzz函数,不失败(return 1),然后扩展代码覆盖率的突变会被保留和迭代形成新的样本。
- 当程序出现Crash的时候,会保存报告并重新启动程序。
Fuzz这块的具体原理其实都是参考的AFL,就不多说了,详细也可以参考AFL的Fuzz方式和源码。
测试用例
首先简单介绍一下go的Fuzz函数的基本信息:
func Fuzz(data []byte) int {
}该函数以int作为返回值,因此当其返回值为0的时候说明Fuzz对于数据不敢影响,可能的原因是测试目标发生了无意义的错误,比如输入内容不合法等,返回值为1说明该数据已经被成功解析,简单来说就是Fuzz输入的data被目标所接受。
DNS解析器Fuzz
首先第一步是创建初始语料库,其实就是通过拆解pcap数据包来创造数据:
package main
import (
"crypto/rand"
"encoding/hex"
"log"
"os"
"strconv"
"github.com/miekg/pcap"
)
func fatalIfErr(err error) {
if err != nil {
log.Fatal(err)
}
}
func main() {
handle, err := pcap.OpenOffline(os.Args[1])
fatalIfErr(err)
b := make([]byte, 4)
_, err = rand.Read(b)
fatalIfErr(err)
prefix := hex.EncodeToString(b)
i := 0
for pkt := handle.Next(); pkt != nil; pkt = handle.Next() {
pkt.Decode()
f, err := os.Create("p_" + prefix + "_" + strconv.Itoa(i))
fatalIfErr(err)
_, err = f.Write(pkt.Payload)
fatalIfErr(err)
fatalIfErr(f.Close())
i++
}
}编写初步的Fuzz函数:
func Fuzz(rawMsg []byte) int {
msg := &dns.Msg{}
if unpackErr := msg.Unpack(rawMsg); unpackErr != nil {
return 0
}
if _, packErr = msg.Pack(); packErr != nil {
println("failed to pack back a message")
spew.Dump(msg)
panic(packErr)
}
return 1
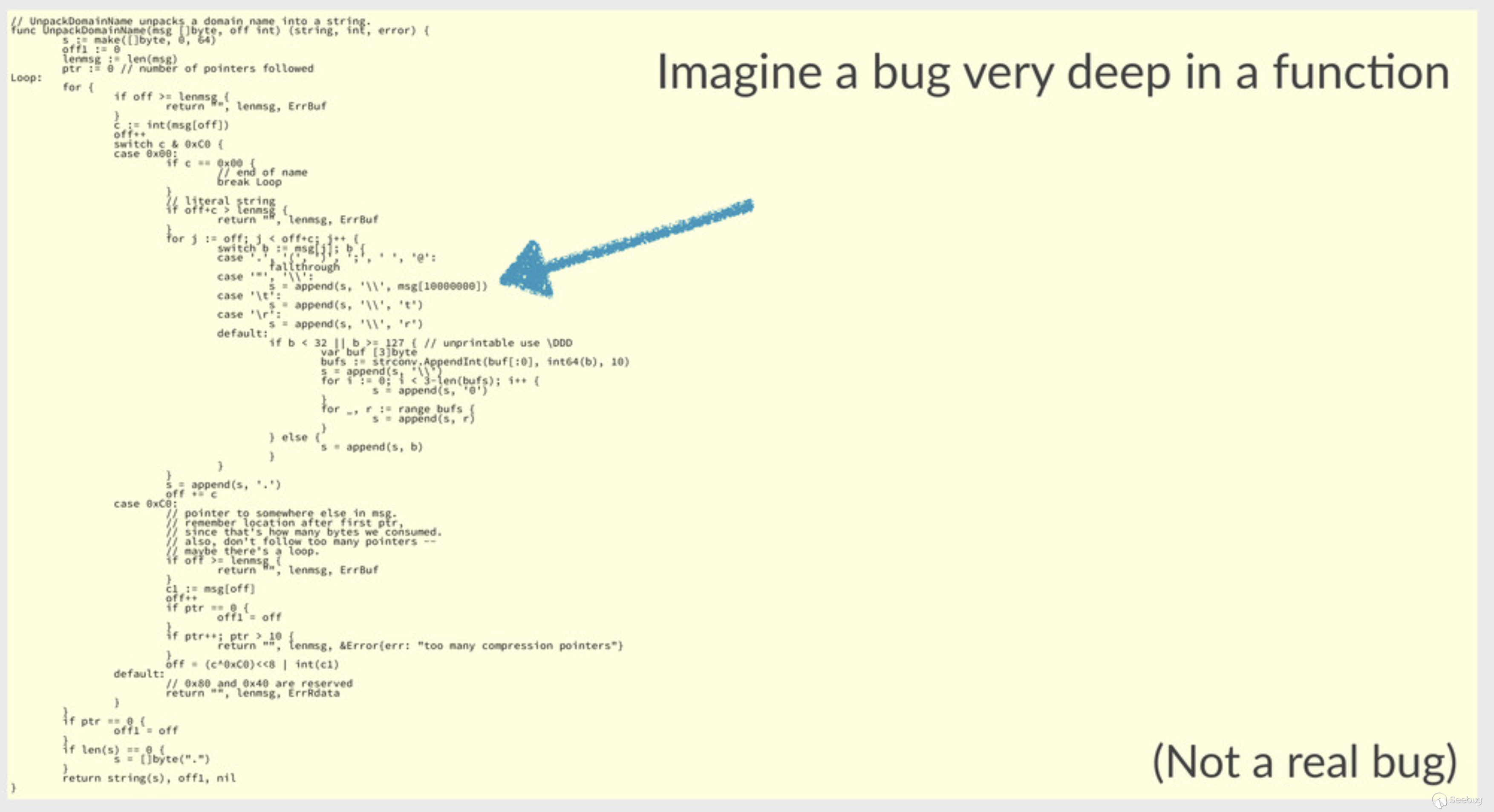
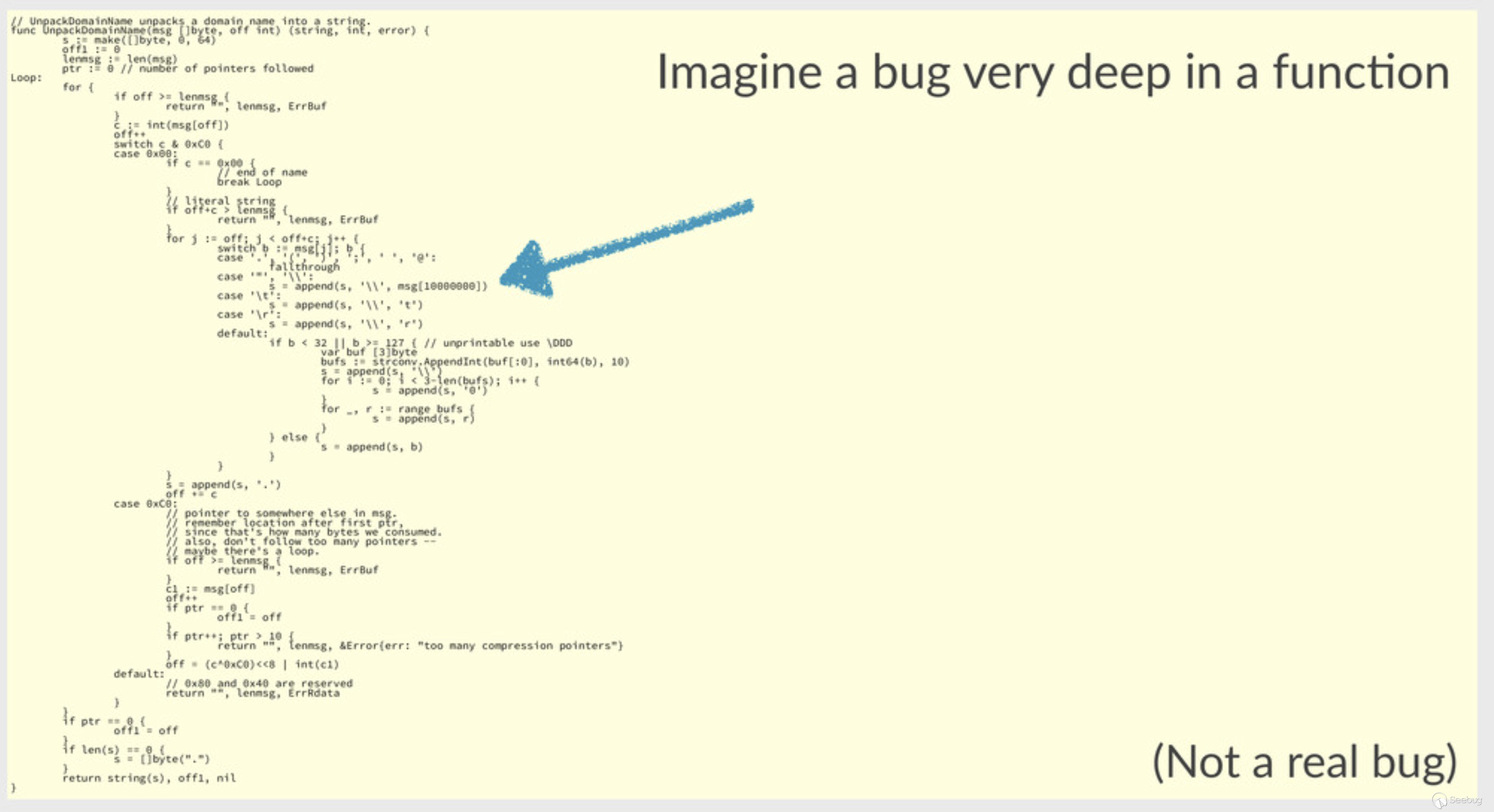
}作者在发现了越界:
func unpackTxt(msg []byte, offset, rdend int) ([]string, int, error) {
var err error
var ss []string
var s string
for offset < rdend && err == nil {
s, offset, err = unpackTxtString(msg, offset)
if err == nil {
ss = append(ss, s)
}
}
return ss, offset, err
}但是因为这些越界使得程序经常崩溃,并且Fuzz变的缓慢,于是作者先进行了阶段性的修复工作,主要修复是使用len(msg)而不是使用保留的偏移量:
func unpackTxt(msg []byte, off0 int) (ss []string, off int, err error) {
off = off0
var s string
for off < len(msg) && err == nil {
s, off, err = unpackTxtString(msg, off)
if err == nil {
ss = append(ss, s)
}
}
return
}之后修改好的Fuzz,主要的修改在于增加了ParseDNSPacketSafely,并抛弃了一些无意义的错误,也可能不断测试,不断排除已知的错误:
func Fuzz(rawMsg []byte) int {
var (
msg, msgOld = &dns.Msg{}, &old.Msg{}
buf, bufOld = make([]byte, 100000), make([]byte, 100000)
res, resOld []byte
unpackErr, unpackErrOld error
packErr, packErrOld error
)
unpackErr = msg.Unpack(rawMsg)
unpackErrOld = ParseDNSPacketSafely(rawMsg, msgOld)
if unpackErr != nil && unpackErrOld != nil {
return 0
}
if unpackErr != nil && unpackErr.Error() == "dns: out of order NSEC block" {
// 97b0a31 - rewrite NSEC bitmap [un]packing to account for out-of-order
return 0
}
if unpackErr != nil && unpackErr.Error() == "dns: bad rdlength" {
// 3157620 - unpackStructValue: drop rdlen, reslice msg instead
return 0
}
if unpackErr != nil && unpackErr.Error() == "dns: bad address family" {
// f37c7ea - Reject a bad EDNS0_SUBNET family on unpack (not only on pack)
return 0
}
if unpackErr != nil && unpackErr.Error() == "dns: bad netmask" {
// 6d5de0a - EDNS0_SUBNET: refactor netmask handling
return 0
}
if unpackErr != nil && unpackErrOld == nil {
println("new code fails to unpack valid packets")
panic(unpackErr)
}
res, packErr = msg.PackBuffer(buf)
if packErr != nil {
println("failed to pack back a message")
spew.Dump(msg)
panic(packErr)
}
if unpackErrOld == nil {
resOld, packErrOld = msgOld.PackBuffer(bufOld)
if packErrOld == nil && !bytes.Equal(res, resOld) {
println("new code changed behavior of valid packets:")
println()
println(hex.Dump(res))
println(hex.Dump(resOld))
os.Exit(1)
}
}
return 1
}Tips:
其实在Fuzz过程中也会遇到一些结构化的问题,毕竟大型项目都会存在大量的复杂结构体难以变异,这时候才为大家提供一个神器go-fuzz-header:
https://adalogics.com/blog/structure-aware-go-fuzzing-complex-types
云原生下的Fuzz思考
云原生的很多新技术其实都是在老技术的交叉上形成的,其实可以类似go项目结构里面的不同的包,对于很多Fuzz目标来言,像以前那样直接从最根本处下手已经不太现实可行,比如容器Fuzz其实很难通过生成大量镜像或者docker client的命令来解决,恰恰相反深入程序内部针对不同函数来编写Fuzz或许更有价值。
但是缺点也很明显,首先必须和代码审计相结合,其次就是由于代码是否用户可达或者crash是否真的引发漏洞效果都有待评估,正如go-fuzz创始人所说:“go-fuzz其实更适合开发者来寻求自己项目中存在的bug”,但是漏洞挖掘技术也是在不断的进步之中,或许可以思考如何把找到的bug发展成漏洞,毕竟对于内存安全的高级语言来说直接谋求可利用漏洞相对困难。
其实在内存漏洞越来越少的现在,这种bug最终演变成漏洞的例子还是有的,就比如linux pkexec提权漏洞,过去几年大家都认为这是一个bug,但是等利用方式被真正发掘,就能变化成为严重的安全问题。
参考资料
https://github.com/dvyukov/go-fuzz
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1864/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1864/
如有侵权请联系:admin#unsafe.sh