2022-1-13 19:1:0 Author: blog.avast.com(查看原文) 阅读量:16 收藏
This is how Avast collects a stream of potential false detections and swiftly reacts to them
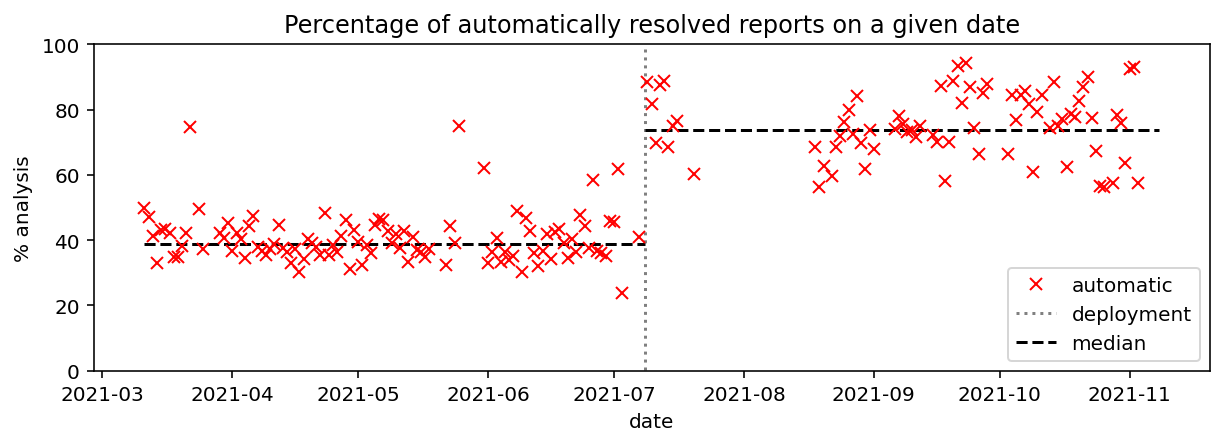
To provide the best possible security, Avast employs a complex ecosystem of detection techniques. Whenever a file enters your computer or gets executed in your computer, a sequence of checks is performed usually in a fraction of a second. The majority of malicious files get discovered using fast detectors running with a small footprint in your computer. Occasionally, however, these detectors can’t reliably assess a file (this can be the case if it is new and unique). In these scenarios, the cloud backend comes to the rescue, since it’s capable of running deep extensive tests that make use of all the knowledge that Avast has. Such extensive tests are done using so much computing power and data that a standalone computer with installed antivirus would not manage to handle it. The interplay of the client-side antivirus engine and its cloud backend ensures that all files get detected with the maximum achievable accuracy. Yet even with the best accuracy, it occasionally happens that we assess a file as malicious and block it, while the user thinks (or knows) otherwise. There is a “gray zone” of files that occasionally can do harmful things without being designed to do so — these are files that use typical malicious techniques for benign purposes, or alternatively, new benign files that just happen to closely resemble known malware. It is of no surprise that a user may occasionally disagree when their antivirus blocks a file and renders their application useless. In these cases (no matter how rare they are), the AV may indeed be wrong, though it’s possible that the mistake may lie on the user’s side. Either way, we provide users with the option to dispute the blocking action that our AV has taken. Users can do this through a dialog illustrated in Figure 1. Figure 1. Based on our file-blocking action, users can send us files for analysis. Reports submitted by users are collected into a queue, and each disputed verdict gets reassessed using a specialized automated analysis pipeline. Such targeted analysis of a file can go deeper than standard automated AV systems can, but such analysis can be slow and can require the intervention of a human analyst. The pipeline itself consists of a large set of expert systems. These include our custom proprietary tools and publicly available platforms, such as the Cuckoo Sandbox, which provides static and dynamic analysis of a given binary. As you can imagine, all these systems output not only a classification of a binary, but also additional structured data. This can include values such as certificate information, file descriptors, or simply decomposition of classification, as shown in Figure 2. Figure 2. An example of a structured output of one of our many systems. Other systems can provide additional information, such as timestamps, certificates, behavioral patterns, etc. The very last step of the pipeline is a complex decision function which aggregates outputs of the individual systems into a final verdict. In some tricky cases, the available information might not be conclusive, and therefore, these binaries can not be resolved automatically. For these cases, there is a manual queue which contains binaries that need to be checked by one of our analysts. Historically, the decision function started as a simple weighted majority vote. Since then, it has been refined to cover more and more nuanced cases, such as specific strains of malware. As it usually happens, the number of systems in the pipeline has increased significantly since its deployment, subsequently increasing the complexity of the final decision function as well. At some point, the manual curation of rules present in the function was no longer efficient. Running in production for significant time already, the pipeline had collected a reasonable amount of historical binaries and verdicts. Thus, we could take the extra step to learn the function from data, which was not previously possible. As shown in a previous blog post, Avast is developing a next-gen machine learning platform designed to automate data processing pipelines. This platform is capable of modeling loosely structured data. More specifically, it can: Traditionally, learning a classifier from deeply nested tree-shaped data, such as the one which we have, requires a lot of manual feature engineering. Moreover, the implementation of feature extractors would have to be maintained over time. Using our machine learning platform greatly simplifies this process by the built-in schema inference, numerization, and implicit feature engineering done while training the neural network. This all makes the platform a great fit for our specific use case of training a meta-classifier on top of a set of rapidly evolving expert systems. The learned decision function has been running in production for some time already. During that time, a major data migration took place. By virtue of the platform backing the function, we can worry a bit less about sudden changes in the structure of the input data. At this point, we can now safely say that deploying the new decision function has significantly improved the overall performance of the pipeline. What we aim for is to confidently resolve as many of the potential false reports as quickly as we can. Figure 3 shows a daily percentage of reports which we could resolve immediately without putting them into the manual queue. Notice the change point in the graph on July 7, 2021. Deploying the decision function has increased the amount of automatically processed reports almost twice, from 38% to 74%. Figure 3. This graph shows how the percentage of automatically resolved analyses of reported binaries evolved in time. Notice the change point on July 7, 2021. It corresponds to the deployment of the automated decisions maker and clearly improves throughput. This throughput gain is due to the machine learning model being able to learn more nuanced patterns from the data compared to what a handcrafted system could achieve. That isn’t all. Using our machine learning platform has additional advantages. As presented in our earlier blog post on explainability in machine learning, we have developed a framework on top of Mill.jl, which helps us to better understand the individual decisions of our models. It does so by estimating an additive importance of individual input features present in our dataset using a game theoretical approach. In a forthcoming post, we will show you how we leverage this framework to improve the UI of a decision support system which provides analysts with outputs from the individual systems mentioned before. To conclude, Avast collects a stream of potential false detections from its customers to which it needs to react swiftly. To do this, we have a dedicated pipeline which processes the individual reported binaries and tries to automatically decide whether or not a reported binary is clean. In some of the cases, analysts need to intervene to give the final verdict. By learning the decision function from the data, we were able to not only reproduce the functionality of the former decision function, but to also capture additional patterns from the data. That manifested in an 1.8x increase of samples, which we’re able to resolve automatically. This, in turn, significantly decreased the average time to reaction because the samples don’t have to wait in a manual queue for an analyst to take action.



如有侵权请联系:admin#unsafe.sh