
阅读: 5
一、摘要
机器学习在很多领域展现出其独特的优势,在过去的很多年里,我们关注更多的是封闭环境下的机器学习,即静态地收集数据并训练模型,但是在现实生活中越来越多地遇到开放环境下的任务,比如数据分布、样本类别、样本属性、评价目标等都会发生变化,这就需要模型具有较好的鲁棒性。本文重点关注流式数据中样本属性变化的问题,并给读者分享一种可行的解决方法。
二、前言
在很多实际任务中,数据是随着时间而积累的,所以近几年基于流数据的学习备受关注,通常的一个假设是,数据流具有稳定的特征空间,即数据样本总是用相同的一组特征来描述。但这种假设在很多流任务中并不总是成立,比如随着攻防的升级,攻击者会对之前暴露出来的特征进行隐藏,同时新的特征可能暴露出来,恶意流量的属性空间因此而发生变化。模型需要在不断变化的环境下良好的运行,所以适应环境变化进而处理可演化特征的能力非常必要。
对于特征演化的情形,我们需要解决特征可演化的数据流学习问题,比如一开始对流数据的刻画有n个特征,随着时间的推移,有的特征消失,同时又有新的特征出现,原来的模型是否只做少量的变动就能处理新的特征,更重要的是,新模型是否能有效利用从旧数据中学到的信息。
我们首先思考这个问题是否一定可解。考虑这样一种情况,如图1所示,横坐标表示特征变化,纵坐标表示时间推移,从某一时刻起,T1时间段内旧的特征全部消失,T2时间段内新的特征重新生成,这时模型很难利用旧数据的信息,T1学到的东西可能对T2没有任何帮助,模型只能从头开始学习,此时这个问题是不可解的。

什么情况下此问题可解呢?一般情况下,特征不会以任意的方式改变,很可能会有一些重叠时期,旧特征和新特征同时可用。如图2所示,T2时间段想要利用T1时间段内学到的信息,T1时间段内的特征生存周期较长,有一小段时间内S1和S2同时存在,可以做桥梁,使得在不保存T1数据的情况下,在T2时间段内利用其信息。

一种简单的方法是只依赖新特征学习新模型,但是这样存在弊端,一是新特征刚刚出现时的数据样本很少,可能不足以训练出一个可用的模型,二是用消失特征训练的旧模型被忽略,这是对旧数据的巨大浪费。为了解决这些问题,本文分享一种有效的方法[1],利用重叠时期来挖掘新老特征之间的关系,使得新模型能够充分利用旧数据的信息。
三、算法介绍
特征空间的变化意味着特征集的基础分布和特征数量的变化。如图3所示,第一阶段t=1,…,T1-B,大量的数据流来自旧的特征空间,第二阶段t=T1-B+1,…,T1,在这个重叠期有少量数据来自新旧特征空间的组合,第三阶段t=T1+1,…,T1+T2,假设所有旧特征同时消失,数据流只来自于新的特征空间。这三个阶段我们看做一个循环。
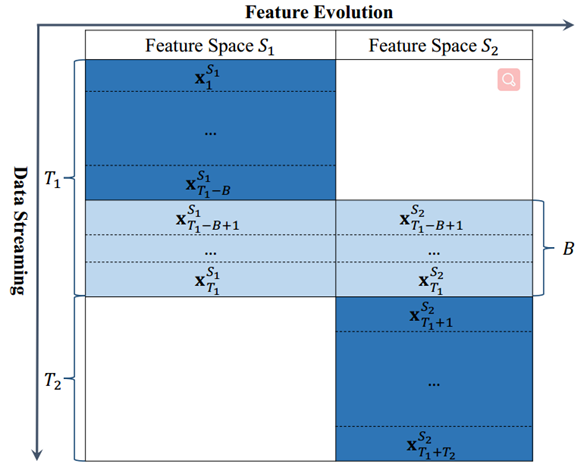
最直接的方法是在第一阶段和第二阶段,在数据流 上利用梯度下降法进行模型训练,然后在第三阶段,在数据流 上再次调用,并使用式(1)更新模型,其中Τt是可变步长。
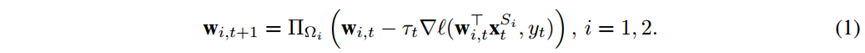
这种方法的局限性在于第三阶段不能从特征空间S1中观测数据,所以第一二阶段训练的模型在第三阶段被忽略了。
为了应对这一挑战,假设在第二阶段的重叠时期可以找到两个特征空间存在的某种映射关系 ,使得我们在第三阶段观察S2的实例时,可以将其映射为S1中的一个实例,所以模型可以计算得到两个分别基于w1,t和w2,,t的预测。利用每一轮的两个基预测,下面介绍两种集成方法。
3.1 加权组合
将预测与基于累计损失指数的权重相结合,如式(2)所示,t时刻的预测为所有基预测的加权平均值,其中αi,t是第i轮基预测的权重。
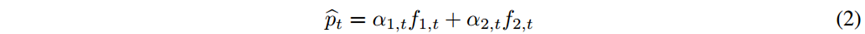
在之前每个基模型损失的基础上,用式(3)更新两个基模型的权重。
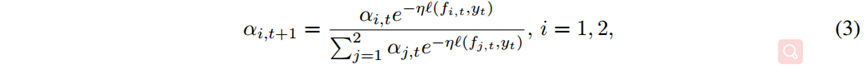
研究人员提出了FESL-c(ombination)算法,如图4所示,首先在t=1,…,T1轮数据上用在线梯度下降法学习模型 ,同时在t= T1-B+1,…,T1轮数据上学习特征之间的关系ψ,当t=T1+1,…,T1+T2时,在每一轮数据上学习模型w2,,t,并采用式(4)恢复数据 来持续更新 ,其中Τt表示可变步长,最后通过式(3)计算的权重将两个模型的预测结果进行集成。
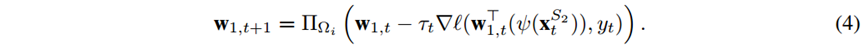

经过分析,在t=T1+1,…,T1+T2,当w1,t在一定程度上优于w2,,t时,有S1辅助的模型优于无辅助的模型。
3.2 动态选择
前一小节提到的集成方法结合了几个基模型来提高整体性能,因为在通常情况下,多个分类器组合的效果比单个分类器更好,但有一个前提是要求基模型的性能不能太差。在我们的问题中,t=T1+1,…,T1+T2时,w2,,t在开始时由于训练数据不足无法满足要求,当数剧越来越多,由于错误的累积将导致w1,t可能变得越来越差,所以一直将两个模型结合在一起可能不适合,而动态选择最好的一个模型可能是更好的选择。
动态选择方法保留并利用多个模型来更新权重,但预试时只使用最优的单个模型。基本思想是选择权重较大、概率较高的模型,FESL-s(election)算法如图5所示。在t=1,…,T1的步骤与FESL-c算法相同,当t=T1+1,…,T1+T2时,仍然更新每个模型的权重,只是在进行预测时,并不将所有模型结合起来,而是根据式(7)权重的分布,采用最优模型的预测结果。

为了跟踪最佳模型,权重更新方法如式(8)所示。
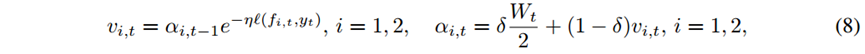

由于w1,t是由旧特征空间中学习到的w1,T1初始化的,而w2,,t是随机初始化的,所以我们有理由相信,从t>T1开始,第一个模型w1,t会因为累积错误而变差,而第二个模型会因为大量数据的到来而变好。
3.3 实验结果
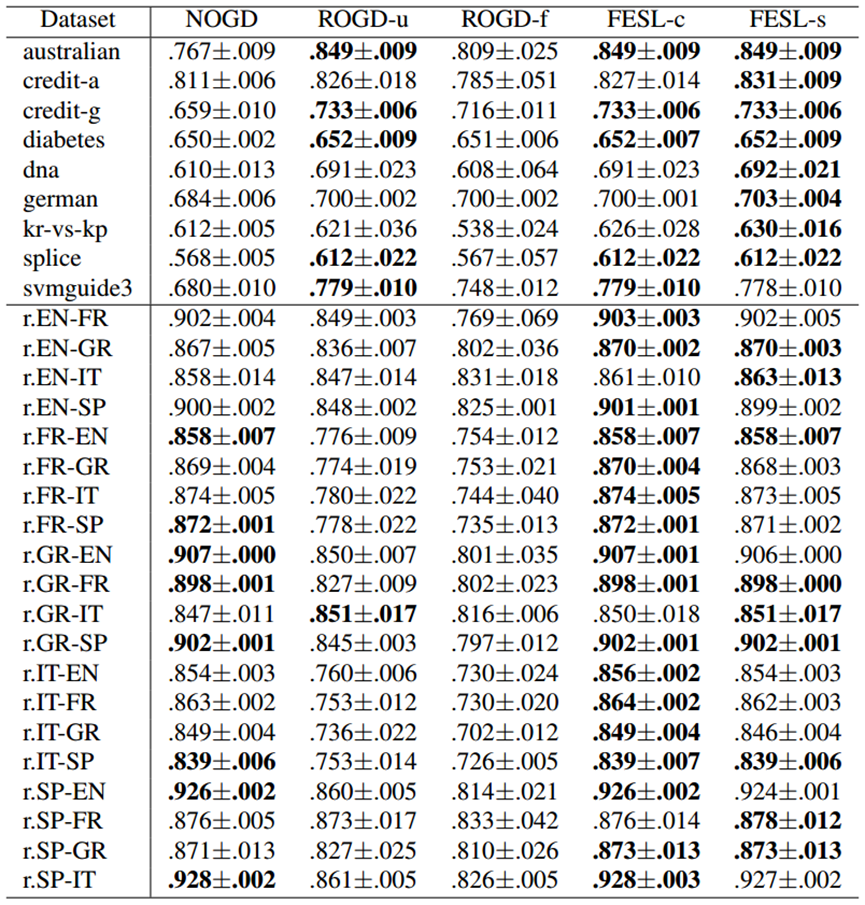
研究人员通过自己收集数据,形成了Reuter数据集和合成数据集,并人为地让它们以流的方式出现。实验效果如图6所示,可以看出,对于表格上半部分的Reuter数据集,FESL-c在17个数据集上优于其他方法,FESL-s在9个数据集上优于其他方法;对于表格下半部分的合成数据集,FESL-s在8个数据集上优于其他方法,FESL-c在5个数据集上优于其他方法。
三、小结
如今我们越来越多地遇到开放环境下的机器学习任务,需要模型具有较好的鲁棒性。本文针对流式数据特征不断演化的情形,介绍了一种在流式数据中解决样本属性变化的方法,假设存在一个包含两个特征空间样本的重叠周期,学习从新特征到旧特征的映射,这样新旧模型都可以用于预测,集成方法有两种,FESL-c算法通过自适应学习权重来集成两个模型,FESL-s算法通过动态选择最佳模型来保证更好的预测性能。
参考文献
[1] Hou B J , Zhang L , Zhou Z H . Learning with Feature Evolvable Streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2017, PP(99).
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。