作者: Badcode@知道创宇404实验室
日期: 2019/08/29
英文版本: https://paper.seebug.org/1026/
前言
下午 @fnmsd 师傅发了个 Confluence 的预警给我,我看了下补丁,复现了这个漏洞,本篇文章记录下这个漏洞的应急过程。
看下描述,Confluence Server 和 Data Center 在页面导出功能中存在本地文件泄露漏洞:具有“添加页面”空间权限的远程攻击者,能够读取 <install-directory>/confluence/WEB-INF/ 目录下的任意文件。该目录可能包含用于与其他服务集成的配置文件,可能会泄漏认证凭据,例如 LDAP 认证凭据或其他敏感信息。和之前应急过的一个漏洞一样,跳不出WEB目录,因为 confluence 的 web 目录和 data 目录一般是分开的,用户的配置一般保存在 data 目录,所以感觉危害有限。
漏洞影响
- 6.1.0 <= version < 6.6.16
- 6.7.0 <= version < 6.13.7
- 6.14.0 <= version < 6.15.8
补丁对比
看到漏洞描述,触发点是在导出 Word 操作上,先找到页面的这个功能。
接着看下代码层面,补丁是补在什么地方。
6.13.7是6.13.x的最新版,所以我下载了6.13.6和6.13.7来对比。
去除一些版本号变动的干扰,把目光放在confluence-6.13.x.jar上,比对一下
对比两个jar包,看到有个 importexport 目录里面有内容变化了,结合之前的漏洞描述,是由于导出Word触发的漏洞,所以补丁大概率在这里。 importexport 目录下面有个PackageResourceManager 发生了变化,解开来对比一下。
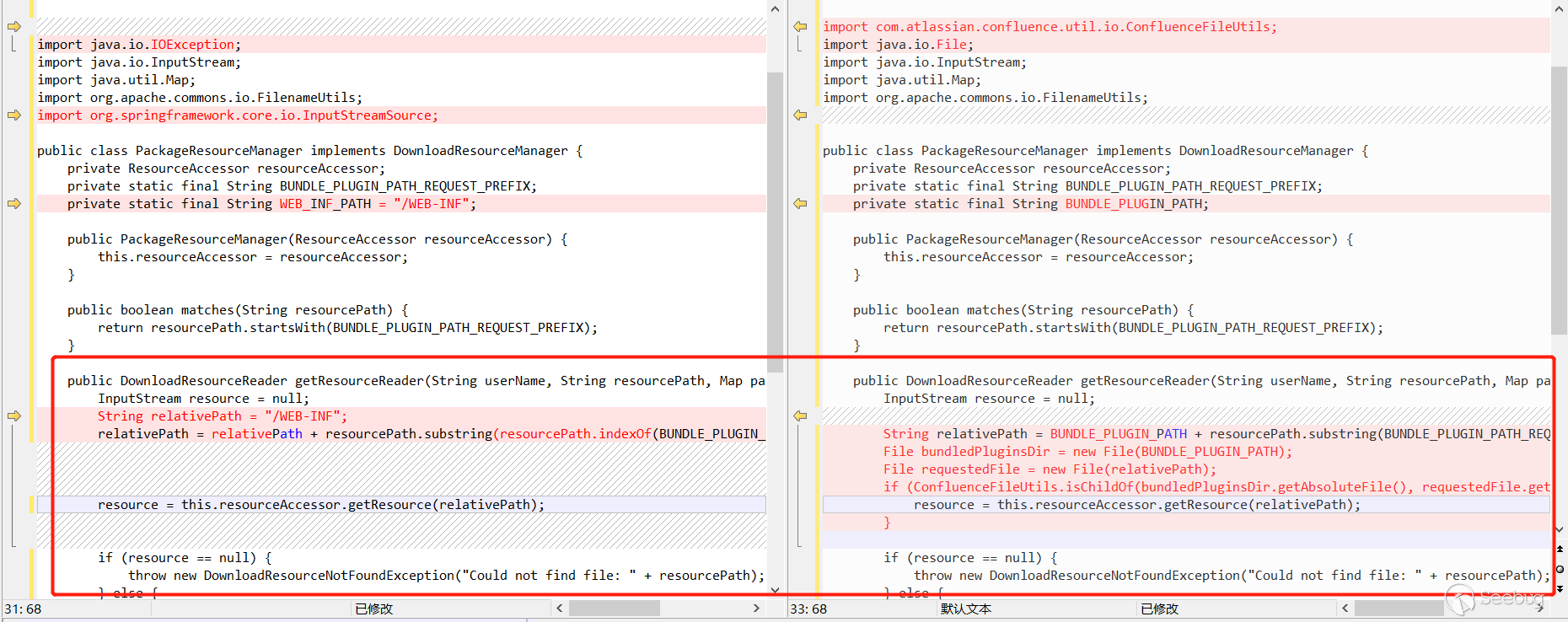
看到关键函数getResourceReader,resource = this.resourceAccessor.getResource(relativePath);,看起来就是获取文件资源的,relativePath的值是/WEB-INF拼接resourcePath.substring(resourcePath.indexOf(BUNDLE_PLUGIN_PATH_REQUEST_PREFIX))而来的,而resourcePath是外部传入的,看到这里,也能大概猜出来了,应该是resourcePath可控,拼接/WEB-INF,然后调用getResource读取文件了。
流程分析
找到了漏洞最终的触发点,接下来就是找到触发点的路径了。之后我试着在页面插入各种东西,然后导出 Word,尝试着跳到这个地方,都失败了。最后我在跟踪插入图片时发现跳到了相近的地方,最后通过构造图片链接成功跳到触发点。
首先看到com.atlassian.confluence.servlet.ExportWordPageServer的service方法。
public void service(SpringManagedServlet springManagedServlet, HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String pageIdParameter = request.getParameter("pageId");
Long pageId = null;
if (pageIdParameter != null) {
try {
pageId = Long.parseLong(pageIdParameter);
} catch (NumberFormatException var7) {
response.sendError(404, "Page not found: " + pageId);
}
} else {
response.sendError(404, "A valid page id was not specified");
}
if (pageId != null) {
AbstractPage page = this.pageManager.getAbstractPage(pageId);
if (this.permissionManager.hasPermission(AuthenticatedUserThreadLocal.get(), Permission.VIEW, page)) {
if (page != null && page.isCurrent()) {
this.outputWordDocument(page, request, response);
} else {
response.sendError(404);
}
......
}在导出 Word 的时候,首先会获取到被导出页面的pageId,之后获取页面的内容,接着判断是否有查看权限,跟进this.outputWordDocument
private void outputWordDocument(AbstractPage page, HttpServletRequest request, HttpServletResponse response) throws IOException {
......
try {
ServletActionContext.setRequest(request);
ServletActionContext.setResponse(response);
String renderedContent = this.viewBodyTypeAwareRenderer.render(page, new DefaultConversionContext(context));
Map<String, DataSource> imagesToDatasourceMap = this.extractImagesFromPage(renderedContent);
renderedContent = this.transformRenderedContent(imagesToDatasourceMap, renderedContent);
Map<String, Object> paramMap = new HashMap();
paramMap.put("bootstrapManager", this.bootstrapManager);
paramMap.put("page", page);
paramMap.put("pixelsPerInch", 72);
paramMap.put("renderedPageContent", new HtmlFragment(renderedContent));
String renderedTemplate = VelocityUtils.getRenderedTemplate("/pages/exportword.vm", paramMap);
MimeMessage mhtmlOutput = this.constructMimeMessage(renderedTemplate, imagesToDatasourceMap.values());
mhtmlOutput.writeTo(response.getOutputStream());
......前面会设置一些 header 之类的,然后将页面的内容渲染,返回renderedContent,之后交给this.extractImagesFromPage处理
private Map<String, DataSource> extractImagesFromPage(String renderedHtml) throws XMLStreamException, XhtmlException {
Map<String, DataSource> imagesToDatasourceMap = new HashMap();
Iterator var3 = this.excerpter.extractImageSrc(renderedHtml, MAX_EMBEDDED_IMAGES).iterator();
while(var3.hasNext()) {
String imgSrc = (String)var3.next();
try {
if (!imagesToDatasourceMap.containsKey(imgSrc)) {
InputStream inputStream = this.createInputStreamFromRelativeUrl(imgSrc);
if (inputStream != null) {
ByteArrayDataSource datasource = new ByteArrayDataSource(inputStream, this.mimetypesFileTypeMap.getContentType(imgSrc));
datasource.setName(DigestUtils.md5Hex(imgSrc));
imagesToDatasourceMap.put(imgSrc, datasource);
......这个函数的功能是提取页面中的图片,当被导出的页面包含图片时,将图片的链接提取出来,交给this.createInputStreamFromRelativeUrl处理
private InputStream createInputStreamFromRelativeUrl(String uri) {
if (uri.startsWith("file:")) {
return null;
} else {
Matcher matcher = RESOURCE_PATH_PATTERN.matcher(uri);
String relativeUri = matcher.replaceFirst("/");
String decodedUri = relativeUri;
try {
decodedUri = URLDecoder.decode(relativeUri, "UTF8");
} catch (UnsupportedEncodingException var9) {
log.error("Can't decode uri " + uri, var9);
}
if (this.pluginResourceLocator.matches(decodedUri)) {
Map<String, String> queryParams = UrlUtil.getQueryParameters(decodedUri);
decodedUri = this.stripQueryString(decodedUri);
DownloadableResource resource = this.pluginResourceLocator.getDownloadableResource(decodedUri, queryParams);
try {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
resource.streamResource(outputStream);
return new ByteArrayInputStream(outputStream.toByteArray());
} catch (DownloadException var11) {
log.error("Unable to serve plugin resource to word export : uri " + uri, var11);
}
} else if (this.downloadResourceManager.matches(decodedUri)) {
String userName = AuthenticatedUserThreadLocal.getUsername();
String strippedUri = this.stripQueryString(decodedUri);
DownloadResourceReader downloadResourceReader = this.getResourceReader(decodedUri, userName, strippedUri);
if (downloadResourceReader == null) {
strippedUri = this.stripQueryString(relativeUri);
downloadResourceReader = this.getResourceReader(relativeUri, userName, strippedUri);
}
if (downloadResourceReader != null) {
try {
return downloadResourceReader.getStreamForReading();
} catch (Exception var10) {
log.warn("Could not retrieve image resource {} during Confluence word export :{}", decodedUri, var10.getMessage());
if (log.isDebugEnabled()) {
log.warn("Could not retrieve image resource " + decodedUri + " during Confluence word export :" + var10.getMessage(), var10);
}
}
}
} else if (uri.startsWith("data:")) {
return this.streamDataUrl(uri);
}
.....这个函数就是获取图片资源的,会对不同格式的图片链接进行不同的处理,这里重点是this.downloadResourceManager.matches(decodedUri),当跟到这里的时候,此时的this.downloadResourceManager是DelegatorDownloadResourceManager,并且下面有6个downloadResourceManager,其中就有我们想要的PackageResourceManager。
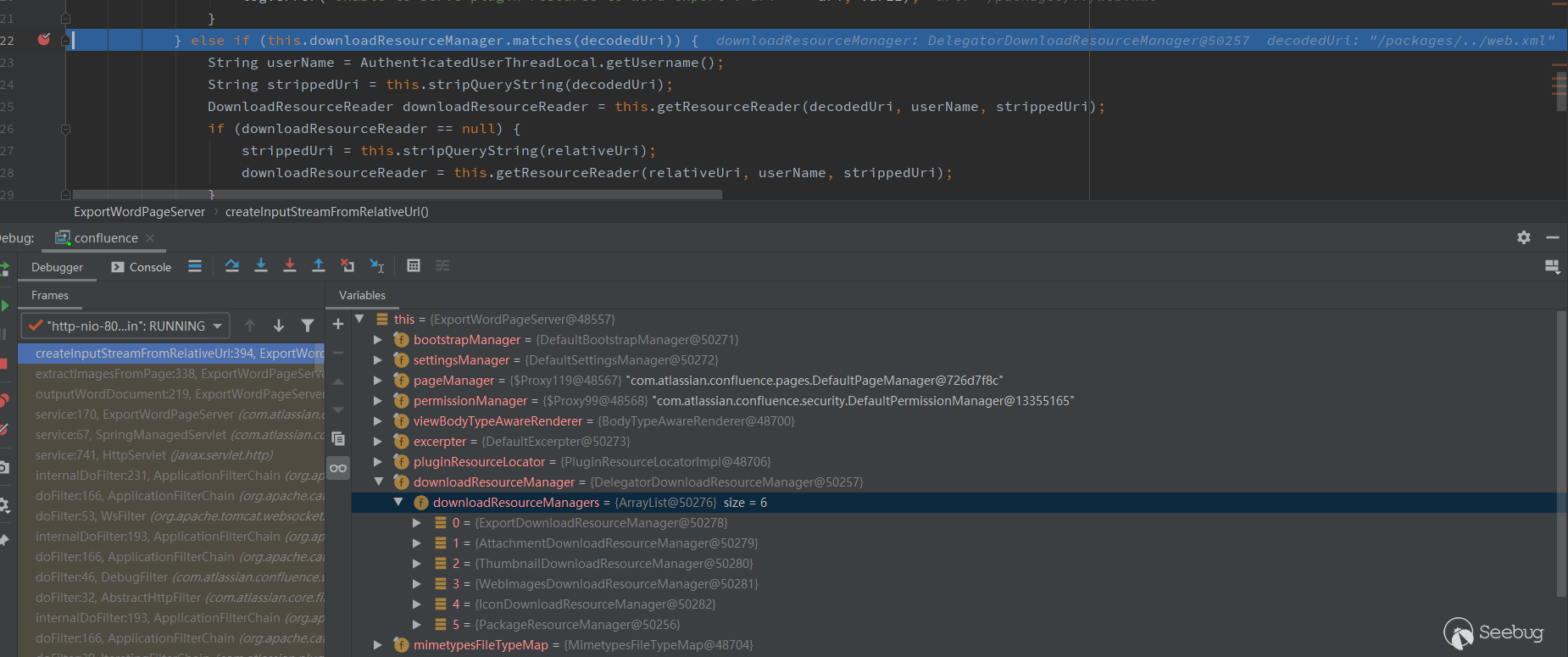
跟到DelegatorDownloadResourceManager的matches方法。
public boolean matches(String resourcePath) {
return !this.managersForResource(resourcePath).isEmpty();
}
......
private List<DownloadResourceManager> managersForResource(String resourcePath) {
return (List)this.downloadResourceManagers.stream().filter((manager) -> {
return manager.matches(resourcePath) || manager.matches(resourcePath.toLowerCase());
}).collect(Collectors.toList());
}matches方法会调用managersForResource方法,分别调用每个downloadResourceManager的matches方法去匹配resourcePath,只要有一个downloadResourceManager匹配上了,就返回 true。来看下PackageResourceManager的matches方法
public PackageResourceManager(ResourceAccessor resourceAccessor) {
this.resourceAccessor = resourceAccessor;
}
public boolean matches(String resourcePath) {
return resourcePath.startsWith(BUNDLE_PLUGIN_PATH_REQUEST_PREFIX);
}
static {
BUNDLE_PLUGIN_PATH_REQUEST_PREFIX = DownloadResourcePrefixEnum.PACKAGE_DOWNLOAD_RESOURCE_PREFIX.getPrefix();
}resourcePath要以BUNDLE_PLUGIN_PATH_REQUEST_PREFIX开头才返回true,看下BUNDLE_PLUGIN_PATH_REQUEST_PREFIX,是DownloadResourcePrefixEnum中的PACKAGE_DOWNLOAD_RESOURCE_PREFIX,也就是/packages。
public enum DownloadResourcePrefixEnum {
ATTACHMENT_DOWNLOAD_RESOURCE_PREFIX("/download/attachments"),
THUMBNAIL_DOWNLOAD_RESOURCE_PREFIX("/download/thumbnails"),
ICON_DOWNLOAD_RESOURCE_PREFIX("/images/icons"),
PACKAGE_DOWNLOAD_RESOURCE_PREFIX("/packages");所以,resourcePath要以/packages开头才会返回true。
回到createInputStreamFromRelativeUrl方法中,当有downloadResourceManager匹配上了decodedUri,就会进入分支。继续调用DownloadResourceReader downloadResourceReader = this.getResourceReader(decodedUri, userName, strippedUri);
private DownloadResourceReader getResourceReader(String uri, String userName, String strippedUri) {
DownloadResourceReader downloadResourceReader = null;
try {
downloadResourceReader = this.downloadResourceManager.getResourceReader(userName, strippedUri, UrlUtil.getQueryParameters(uri));
} catch (UnauthorizedDownloadResourceException var6) {
log.debug("Not authorized to download resource " + uri, var6);
} catch (DownloadResourceNotFoundException var7) {
log.debug("No resource found for url " + uri, var7);
}
return downloadResourceReader;
}跳到DelegatorDownloadResourceManager中的getResourceReader
public DownloadResourceReader getResourceReader(String userName, String resourcePath, Map parameters) throws DownloadResourceNotFoundException, UnauthorizedDownloadResourceException {
List<DownloadResourceManager> matchedManagers = this.managersForResource(resourcePath);
return matchedManagers.isEmpty() ? null : ((DownloadResourceManager)matchedManagers.get(0)).getResourceReader(userName, resourcePath, parameters);
}这里会继续调用managersForResource去调用每个downloadResourceManager的matches方法去匹配resourcePath,如果匹配上了,就继续调用对应的downloadResourceManager的getResourceReader方法。到了这里,就把之前的都串起来了,如果我们让PackageResourceManager中的matches方法匹配上了resourcePath,那么这里就会继续调用PackageResourceManager中的getResourceReader方法,也就是漏洞的最终触发点。所以要进入到这里,resourcePath必须是以/packages开头。
整个流程图大概如下
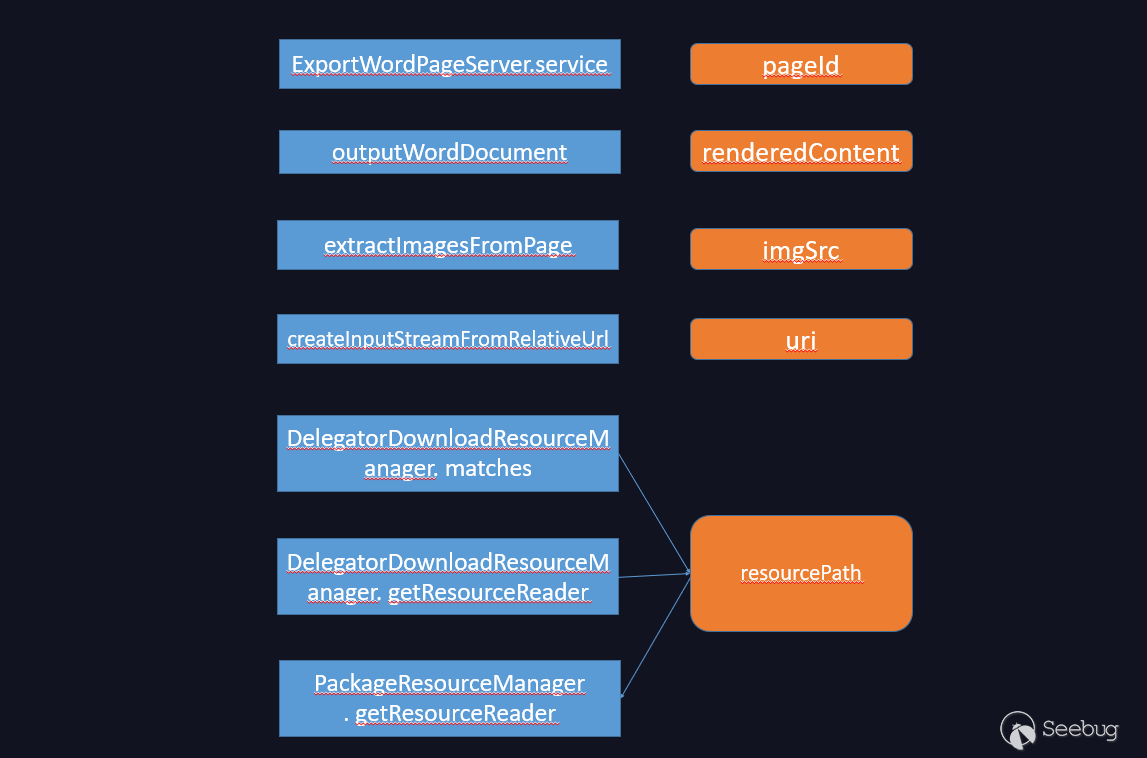
构造
流程分析清楚了,现在就剩下怎么构造了。我们要插入一张链接以/packages开头的图片。
新建一个页面,插入一张网络图片
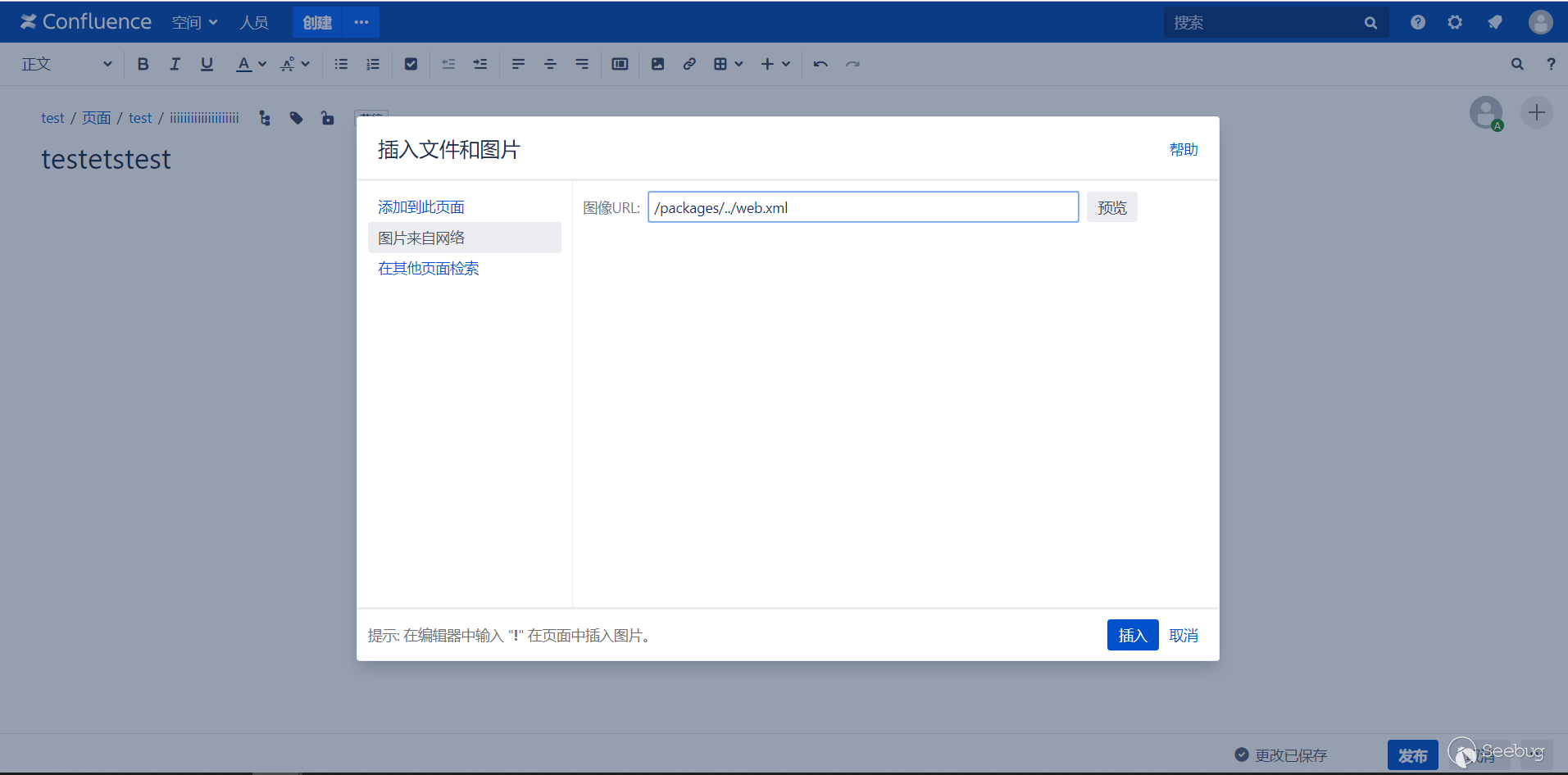
不能直接保存,直接保存的话插入的图像链接会自动拼接上网站地址,所以在保存的时候要使用 burpsuite 把自动拼接的网站地址去掉。
发布时,抓包
去掉网址

发布之后,可以看到,图片链接成功保存下来了
最后点击 导出 Word 触发漏洞即可。成功读取数据后会保存到图片中,然后放到 Word 文档里面,由于无法正常显示,所以使用 burp 来查看返回的数据。
成功读取到了/WEB-INF/web.xml的内容。
其他
这个漏洞是无法跳出web目录去读文件的,getResource最后是会调到org.apache.catalina.webresources.StandardRoot里面的getResource方法,这里面有个validate函数,对路径有限制和过滤,导致无法跳到/WEB-INF/的上一层目录,最多跳到同层目录。有兴趣的可以去跟一下。
利用 Pocsuite3 演示该漏洞:
参考链接
Local File Disclosure via Word Export in Confluence Server - CVE-2019-3394
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1025/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1025/
如有侵权请联系:admin#unsafe.sh