阅读: 8
一、摘要
当前企业环境面临的攻击越来越趋于隐蔽、长期性,为了更好的针对这些攻击进行有效的检测、溯源和响应,企业通常会部署大量的检测设备。安全运营人员需要根据这些检测设备的日志和告警来对攻击事件进行检测与溯源。然而攻击技术的发展通常领先于检测设备检测能力。当新攻击技术或是新漏洞被发现时,通常是以报告的形式公开,针对这些新攻击的检测能力往往很难快速的部署到检测设备中。
网络威胁情报(CTI),通常是技术报告、白皮书、博客和新闻组中报告,是有关网络攻击的宝贵信息来源。这些报告用自然语言描述了攻击的许多方面,包括行动的顺序、对被攻击系统的影响以及破坏指标(IOC)。威胁情报报告中包含子攻击相关的主要知识,可以帮助安全运营人员了解攻击过程并应用于检测与溯源。已有一些研究工作利用NLP技术从威胁情报报告中提取攻击行为的相关知识。但该工作现在只处理起步阶段,还远没能应用到威胁检测与攻击溯源上。
主要面临如下挑战:
1.在威胁情报报告中,与攻击行为相关的描述可能只占很小一部分。报告中大量的描述信息与攻击行为没有直接关系。
2.威胁情报报告中使用的语句结构与日常生活中使用语言具有较大的差异,其中包含了大量的简写,代指和被动语法等。传统的自然语言处理工具难以对CTI报告进行处理。
3.对威胁情报报告中全局的信息进行提取需要理解攻击行为之间的关系,而理解技术报告中复杂的逻辑是NLP领域公认的难题。
本文以文献[1]为主要参考来介绍如何基于威胁情报报告提取有效的攻击子图。文献[1]提出了一个工具EXTRACTOR,该工具可以精确的自动的从威胁情报报告中抽取攻击行为。EXTRACTOR的主要创新性在于其对文本没有强假设,可以从非结构化文本中提取攻击行为溯源图。提取的这些攻击行为溯源图可以应用威胁狩猎。
二、相关研究内容与技术框架
攻击技术的快速发展为安全防护出了更高的要求,如何快速的针对新攻击技术生成有效的检测与溯源机制是当前面临的主要挑战。从威胁情报中提取可用于检测与溯源的有效信息是一种可能。但其可行性是能够基于报告提取到可用于威胁检查与溯源的信息,这样可以第一时间对新攻击进行检测与溯源。
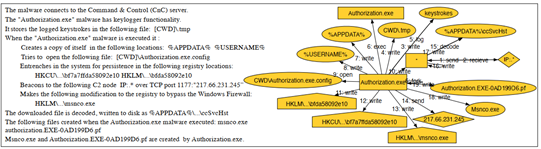
图1是njRAT恶意样本的报告中的一段关于攻击行为的描述。图1右侧表示是根据威胁情报报告构建的溯源图。该溯源图的节点表示与攻击行为相关的实体如进程、注册表等,边表示实体之间的操作行为。njRAT恶意样本的攻击子图可以与终端日志的溯源图相对应,可以根据该子图在终端日志溯源图中进行子图匹配来进行攻击检测。

从威胁情报的报告中抽取精确可用的攻击子图依然存在不少挑战。首先,需要在报告中识别与攻击行为相关的文本,因为威胁情报报告通常很长,其中包含了大量的与攻击过程不相关信息。这需要了解报告中出现的与攻击相关的实体,以及这实体之间的相关攻击行为,据此构建可用于溯源图威胁检测的攻击子图。其次,威胁情报文本的复杂性将影响溯源的图的构建性能,这意味着要解决自然语言写作中存在的不同类型的模糊性和复杂性。
下面以EATRACTOR为例介绍利用NLP技术从威胁情报报告中提取有效的攻击子图的框架。

EXTRACTOR通过对威胁情报报告进行多次转换,将其从复杂的、具有歧义的形式转换成简单的文本。对简化后的文本进行进一步处理,得到一个可以成功用于威胁检测的溯源图。如图2所示,整个过程主要包含四个步骤:1 标准化;2 解析过程;3 文本归纳;4 溯源图生成。标准化是一个初始的数据预处理过程,把报告中的文本内容转换成规范的形式。文本解析过程是对数据进行消歧。文本概要是删除文本中与攻击行为不严格相关的信息。攻击子图构建是挖掘攻击行为的时序与因果关系,并构建可用于威胁检测的攻击子图。这些步骤需要一些包含与威胁情报语言的相关的术语字典来辅助。EXTRACTOR一共使用了两个词典。一是系统调用同义词典,包含了表示系统调用(如写,读fork)的动词以及其同义词。这些同义词表示可能在威胁情报报告中使用的表示系统调用的动词。二是报告中的名词词典,该词典包含了报告中常用的名词词典,以及同一概念的不同文本表示。其中系统调用词典包含了87个动词,名词词典包含了1112个名词短语。
三、技术细节
为了详细说明具体细节,以图1中关于njRAT恶意样本的攻击描述为例来进行说明。njRAT恶意样本Authorization.exe连接C&C服务器,该恶意样本具有键盘记录功能,把相关的键盘记录写到本地[CWD]\.tmp文件中。当恶意样本Authorization.exe执行时,会在本地%APPDATA% %USERNAME%目录下创建一个副本。同时该木马试图打开文件[CWD]\Authorization.exe.config,同时修改下面的注册表信息HKCU\…\bf7a7ffda58092e10 HKLM\…\bfda58092e10以保证该样本的持续运行。同时修改HKLM\…\msnco.exe以绕过防火墙,然后通过端口1177跟c2“217.66.231.245“进行通信下载相关文件并写入磁盘%APPDATA%\…\ccSvcHst,在Authorization.exe运行过程中创建了msnco.exe和authorization.EXE-0AD199D6.pf。
针对该样本的攻击过程分别人标准化、语法与语义解析、文本归纳以及子图构建四部分介绍。
3.1 标准化
为了解决威胁情报的文本复杂性挑战,并最大限度地提高攻击子图构建的准确性,首先必须对报告中的句子进行规范化处理。为此,基于标准化方法对报告中进行规范化,把长的复杂句了转换成简单的短句。直观来说,标准化的目标是把复杂的长句变成多个短句,每一个短句子表示攻击主体对一个攻击客体执行的某个行为。标准化过程也包含了三部分,分别是句子边界切割、同质化和句式转换。这些步骤分别执行了句子边界检测、词的同质化和被动词到主动词的转换。
3.1.1 句子边界切割
当前的分词器(如NLTK[2])主要依据句子的标点符号来识别句子的边界。而在安全领域,包含多个动作信息的长句或是不规范分隔符的情况很多。针对该问题,除了使用典型的句子分隔符之外,还使用新行、点句、枚举数、标题和头信息作为句子分隔符把长句划分为多个短句。通过长句划分得到的多个词语的短序列如果满足下列条件中的一个则认为这个短序列是一个句子。1:该序列是由一个大写的主语开始,包含了构成一个完整句子的所有组成(主语、谓语和宾语),并且该序列之前或是之后的序列也可以构成一个完整的句子;2:该序列以系统调动词典中的动词开始,除了主语之外包含了所有组成,同样该序列的之前或是之后的序列可以构成一个完整的句子。

图3给出该过程处理njRAT报告的示例。第4行到第9行是一个长句子,描述恶意样本Authorization.exe执行时的相关行为。首先需要将其按行切分成多个短序列。然后,每个短序列通过词性标注和依存标注进行打标签,并检测该序列是否满足上面两个条件。可以看到第4行满足条件1,第5行到第9行满足条件2。该过程的结果是一系列短句子,这些短句子更有可能描述一个行为。
3.1.2 同质化
威胁情报报告经常包含可以引入歧义并影响最终结果质量的结构和同义词。例如,图1描述中出现的C2和Command and Control是同一实体的不同表示。同质化是指对同一概念的不同文本表示进行统一。使用两个专门构建的字典对名词短语和动词执行同质化,它们将报告中出现的不同术语和名词和动词的同义词映射到审计日志中可以观察到的实体和动作。例如,C2、C&C和Command and Control需要被映射成“IP:.*”这样的IP地址通配符。以同样的方式,使用系统调用动词在系统调用字典中翻译作为系统调用同义词的动词。同质化可以显著的减少报告文本中的异构性,从报告中提取可行的情报成为可能。
3.1.3 句式转换
威胁情报报告文本标准化的最后一步就是把被动词转换成主动。这种转换可以更方便的发现系统对象与系统目标,同时能更精确的进行因果推理。
为了进行这种转换,首先需要根据词性标注和依存标记来进行被动句检测。这种类型的句子主要是由依存树中特定的已知模式表示。以如下句子为例“This kind of sentence is predominantly represented by specific and known patterns in DP trees”,在依存树中,is表示辅助动词或是被动词,deleted表示动词或是依存树的头,“the downloaded file”被动句的主语,“by malware”是被动句的谓语。然而在一些情况下,一些代词是隐含在被动句中,而没有明显的出现在句子中。例如,图3中第10行,代词malware没出现在句子中,通过上下文可以知道其是指njRAT恶意样本Authorization.exe。通过该模式,可以检测出被动句式,同时能识别句子中显示或是隐式代词。通过该过程可以把报告中的长句转换成短句,每个短句表示一个行为。
3.2 语法与语义解析
在规范后,需要对文本中相关的引用进行解析。尤其是文本中一些暗含的引用必须进行明确的识别。
省略号主语是一种语言结构,也就是指句子中的主语不存在。省略主语会给子图构建带来挑战,从而导致一些攻击的源节点错误。图3中第5-9行描述的所有动作都是省略主体的例子。针对该挑战,EXTRACTOR开发了一个Ellipsis Subject Resolver(ESR)模块。该模块利用词性标注和依存标注以及系统调用的字典。解决这个问题的第一步是检测缺失主语的句子。一旦检测到这种句子,ESR就会在当前句子之前的句子中出现的实体中建立一个候选主体列表。接下来,该模块根据候选者与缺失主语的句子的距离(以句子数计算),从列表中挑选出最可能的候选者。特别是,距离越近的候选人被选中的概率就越高。例如,在图3中,第5-9行的句子中缺少主语。ESR模块检测了前面的句子中的主语和其他对象,它选择了冒号前出现的代词it作为主语。
代词解析是指代词被映射和替换到它们所指的前述实体的过程。在没有PR的情况下处理文档(构建出处图)会导致一个实体出现多个节点(即代词)。为了解决代词问题,EXTRACTOR采用了一个流行的核心词解析模型—NeuralCoref[3]。这个模型在解决威胁情报报告领域的代词方面效果最好。
隐喻是指用一个词或代词来指代句子中以前使用过的另一个词或短语,以避免重复。在解析步骤完成后,文本由具有明确主语、宾语和动词的句子组成。ER模块也在一定程度上减少了文本的数量。然而,主要的文本缩减步骤是在 “解析 “之后执行的,接下来将介绍。
3.3 文本概要
为了减少多余信息,获得可直接用于检测攻击的攻击行为的简明描述,需要删除大量的与攻击行为不相关的描述。针对冗长的报告需要识别哪些句子描述了攻击行为。另外需要简化句子的描述。在每个句子里,通常会出现修饰性词语如副词和形容词,这些词语对构建攻击行为子图的帮助并不大,需要删除。针对该需求EXTRACTOR设计了一个两步法。其流程如图4所示,主要包括一个BERT[4]分类器和一个BiLSTM网络[5]。

为了区分实际威胁行为的句子和普通行为的句子,需要超越主题分类,对文本有更深入的理解。因此,为了对这些联系进行分类,模型必须建立一个关于单词上下文的细粒度表示。目前,建立这种细粒度表示法的最佳模型之一是BERT。
文本概要的第二步是从BERT得到的句子中删除修饰性词语。它由两个阶段组成,一个是得出句子成分语义的BiLSTM网络,另一个是去词阶段。
在一个句子被BiLSTM网络处理后,其成分被标记为Agent、Patient和Action,以及其他类型的参数。在下一个阶段,不必要的句子成分被删除。从理论上讲,这只能通过保留句子中的Agent、Action和Patient成分来实现。然而,在某些情况下,这种方法会删除重要的信息。
3.4 攻击子图构建
经过前面的步骤,得到的文本是这样一种形式:系统主语(如进程)、对象(如文件、套接字)和动作(如执行)是明确的、有序的,而且大部分多余的信息均被删除。
这一阶段的目标是根据处理好的文本生成一个有效的攻击子图。该步主要是基于文本识别语义实体与关系。实体的语义识别依据语义角色标签(SRL),关系与信息流方法通过因果关系挖掘方法实现。
SRL是一种发现句子中的语义角色的技术。图5中的两句子是上文中报告的恶意样本的两个攻击行为描述。一个是主动形式的,一个是被动形式的。SRL能够从每个句子中提取两个角色(用Raw SRL表示),并理解哪个名词是目标者(也就是动作落在上面的人,用ARG1表示),哪个是代理人(携带动作的名词,用ARG0表示)。一个SRL角色可以被认为是一个动作。因此,SRL能够正确地将句子中的每个成分与语义标签联系起来。

然后要根据SRL的输出构建攻击子图。首先,将具有相同文本的SRL合并到同一个节点中,并剔除不属于系统实体的词。接下来,使用以下方法构建图。1)源节点-边-目标节点三元组。对于每个句子,如果它至少有三个角色,包括一个动词角色(作为连接器的系统调用表示)和两个实体,据此生成一个三元组。2)边的方向依据系统调用与系统数据流动方向来确定。
四、总结
针对检测设备检测能力的滞后性,如果能够从威胁情报中自动的提取相关攻击子图可以直接应用到终端日志溯源图中,可以大大提高检测的时效性。EXTRACTOR方法提供了一套有效可行的技术框架。但是由于NLP技术的局限,在实际应用过程中依然存在不少的挑战,其次在实验验证过程中该方法针对恶意样本效果较好,针对其他复杂多步攻击的效果依然有待于提高。
参考文献
[1] Satvat K , Gjomemo R , Venkatakrishnan V N . EXTRACTOR: Extracting Attack Behavior from Threat Reports[J]. 2021.
[3] https://github.com/huggingface/neuralcoref.
[4] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
[5] Huang Z , Wei X , Kai Y . Bidirectional LSTM-CRF Models for Sequence Tagging[J]. Computer Science, 2015.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。