两年前,从兜哥的《Web安全机器学习入门》这本书开始与机器学习结缘,慢慢了解了什么是贝叶斯、HMM、SVM,以及它们应用的场景。关于算法公式,在这里就不班门弄斧了,说实话很多都看不懂,“咱也不敢说,咱也不敢问”。
当前我们对于恶意请求的自动检测主要是基于黑规则的检测,众所周知,这种基于规则库的安全防御被动、滞后,无法检测未知的攻击,造成的影响就是漏报挺多,这也是引入机器学习的重要原因。
本文主要分享一下,在做基于HMM的SQL注入检测时遇到的一些问题及解决方法,至于HMM的原理及概念,有兴趣的同学可以看看《学点算法搞安全之HMM(上篇)》 这篇文章。https://mp.weixin.qq.com/s/Cc15keu4quPBZc1N4bS58g
0×01 建模思路
机器学习建模的整体思路如下:
1. 收集数据集
常见的SQL注入攻击载荷主要集中在请求参数中,解析GET、POST请求的参数值作为样本数据。此次项目收集了大约20万白样本数据。
2. 数据处理与特征提取
数据降噪,如去掉注释、urldecode等;
特征提取:包括分词、泛化、特征向量转化,本文采用自研的分词器,分词、特征转化二合一。
3. 使用HMM训练检测模型
4. 最后模型调优,并使用检测模型检测未知 URL
0×02 特征提取
1. 正则表达式分词与泛化
关于特征提取,刚开始使用的是正则分词+泛化的处理方式。这种方式也是目前使用较多的一种方式,毕竟正则简单易上手。以下列字符串为例:
![]()
使用正则re.split(r’( |,)’, ss)分词,结果为:

观察结果,不符合预期,效果不是很理想。对于sql来说,concat是个函数,属于关键字,需要单独分出来,否则后续不好泛化。在实际场景中,黑客们为了达成目的,一般都不走寻常路,不要奢望他们按常理出牌。也就是说payload会千奇百怪,出现各种变种,分隔符不固定,而为了能尽可能多的覆盖,正则也会变得越来越复杂,相应的执行效率也会直线下降。
对分词后的结果进行泛化,依据:
[a-zA-Z]泛化为A
[0-9]泛化为N
[\-_]泛化为C
其他字符泛化为T,泛化后的结果为:
99999泛化为N
union泛化为AAAAA
正则分词遇到的问题:
1>分词不精准,分隔符不固定,为了能尽可能多的覆盖,需要不断完善正则表达式
2>覆盖范围越广,正则越复杂、效率越低
3>采用单字符的特征提取,弱化了SQL Keyword的影响,字符串长度对预测结果的影响大于SQL关键字
4>没有突出SQL解析的特点
2. 基于SQL解析的词法分词
基于SQL解析的词法分词是一种新的分词方法,也是本次项目中使用的方法, 此方法将正则分词和特征向量提取合二为一,即分词器在返回分词结果的同时,也定义了特征向量值。基于SQL解析的词法分词逻辑很简单,分词器模仿sql解析器进行分词,逐个扫描字符串,遇到符号即返回,遇到字符即继续,以及检测解析出的字符串是否是keyword。
部分代码如下:
1. 定义SQL解析器可以识别的符号、运算符、关键字并预设特征向量值:
2. 字符验证函数定义:

![]() 这个函数是用来判断字符是否可以被SQL标识器识别的。这里当初卡了很久,原因是因为结果不准确。对于ASCII字符集,高位Bit集合的字母都能被SQL标识器识别,对于7-bit的字符,则sqlIsEbcdicIdChar必须为1。后来又分析了SQL99, SQL/MM, and SQLJ: An SQL99, SQL/MM, and SQLJ: An Overview of the SQL Overview of the SQL Standards SQL : 1999, Formerly known as SQL3的语法定义, 其中比较值得注意的是对于char的识别鉴定, 根据分析sql各个标准中char类型的定义,首先进行了ascii码的判断方式,但返回结果并不理想;在查询了相关资料(sql的各种标准)后, 又引入了ebcdic这个字符集,做双重校验,结果终于准确了! 关于ebcdic的定义:http://www.astrodigital.org/digital/ebcdic.html,有兴趣的可以去研究下。
这个函数是用来判断字符是否可以被SQL标识器识别的。这里当初卡了很久,原因是因为结果不准确。对于ASCII字符集,高位Bit集合的字母都能被SQL标识器识别,对于7-bit的字符,则sqlIsEbcdicIdChar必须为1。后来又分析了SQL99, SQL/MM, and SQLJ: An SQL99, SQL/MM, and SQLJ: An Overview of the SQL Overview of the SQL Standards SQL : 1999, Formerly known as SQL3的语法定义, 其中比较值得注意的是对于char的识别鉴定, 根据分析sql各个标准中char类型的定义,首先进行了ascii码的判断方式,但返回结果并不理想;在查询了相关资料(sql的各种标准)后, 又引入了ebcdic这个字符集,做双重校验,结果终于准确了! 关于ebcdic的定义:http://www.astrodigital.org/digital/ebcdic.html,有兴趣的可以去研究下。
3. 字符串扫描:
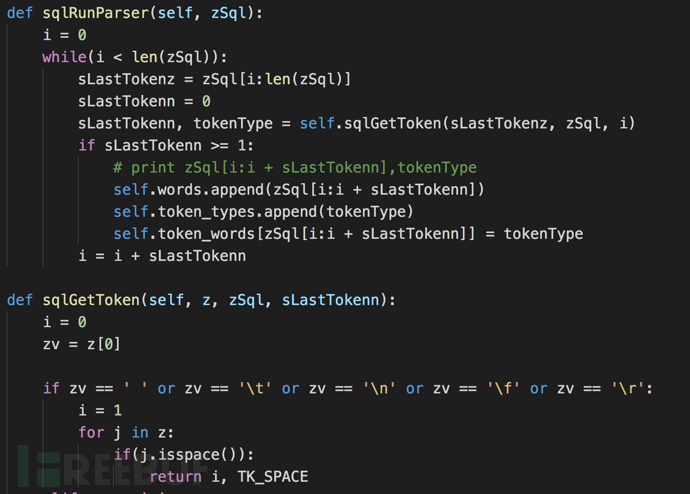 如果字符是合法的SQL运算符则返回对应的状态值,如果字符是字母数字则继续扫描,直到指针越界或者IdChar为False
如果字符是合法的SQL运算符则返回对应的状态值,如果字符是字母数字则继续扫描,直到指针越界或者IdChar为False
5. SQL 关键词识别
SQL标识器可以识别的关键字组成的字符串:
关键字对应的字符串长度:
关键字在zText中的索引位置(offset):
举列说明:
字符串:str = “INDEX”
首字母大写为:I,
长度:5
如果zText[aOffset[1]:aOffset[1]+5] == str.upper() 为True,代表此字符串为Keyword,否则为普通字符串。
zText aOffset aLen这些数组都是提前计算出来,目的是为了提高检索效率。
特殊说明:为了区别关键字和普通字符串,对关键字的特征向量值加了权重50000。
性能对比:

总结:
1>针对简单的字符串性能优势不明显,但是放在复杂的日志环境中优势就能慢慢体现出来了,日志请求越长,效果越明显。
2>比简单正则覆盖范围广,比复杂正则速度快。
3>分词精准度高。
4>具有针对性,sql解析器识别的keyword能重点标记。
0×03 训练HMM检测模型
HMM进行文本异常检测,有两种方式:
以白找黑:相当于找不同
以黑找黑:相当于找相似
以白找黑,是给HMM输入纯白样本,让其记住正常url参数的模型转化概率,然后找不同。本文采用的是以白找黑模型训练,部分代码如下:
预测结果为:
定义T为阈值,概率小于T的参数识别为异常。阈值T过小,误报会少,但是漏报会高;阈值T过大,误报会多,但是漏报会少。本人的观点是接受误报,尽量做到不漏报。误报可以后续进行二次处理,如注入验证或者其他维度检测。
0×04 预测结果二次验证
事实证明,每天都会检测到大量结果为失败或者404的类似告警,导致系统存在大量误报。偶有成功的也会埋没在误报当中,久而久之报警处理人就不想再去查看,或者查看的不够仔细,从而导致被黑。因此就需要对检测结果进行二次验证。
为了完成这个目标,基于sqlmap改了一个简化版,用于验证GET方式的SQL注入是否成功。
第一步:先验证请求参数是否是动态的,如果不是,则忽略;
第二步:如果是动态参数,进行SQL注入检测,检测为True,则进入报警队列。
以dvwa为例:http://localhost/dvwa/vulnerabilities/sqli/?id=1&Submit=Submit#,验证结果如下:
目前此验证脚本为初版,只支持GET方式的部分注入类型验证。
0×05 结束语
我们在进步,黑产也在进步,而且是飞速发展。见识了黑产的群控和各种高级的设备,才知道我们在使用小米步枪和飞机大炮在战斗,这是一项艰巨的任务。技术无分善恶,但落后就要挨打!雄关漫道真如铁,而今迈步从头越!加油吧,少年!。
代码传送门:https://github.com/skskevin/UrlDetect/tree/master/tool/SQLTokenizer
*本文作者:littlegrass,转载庆注明来自FreeBuf.COM
如有侵权请联系:admin#unsafe.sh