阅读: 28
一、摘要
避免网络空间测绘数据使用中“刻舟求剑”,通过对IP地址对应资产动态变化研究,还原真实网络空间全貌。
测绘最早来源于地理空间地图的绘制,主要研究测定和推算地面几何位置、地球形状及地球重力场,据此测量地球表面自然物体和人工设施的几何分布,编制各种比例尺地图的理论和技术的学科(维基百科)。网络空间测绘和地理信息测绘的技术路线类似,“测”是对网络空间内一切可获得数据的测量机制的建立,偏向于实现扫描和探测的工程问题;“绘”则是根据对网络空间测量数据关联到地理空间绘制成图,更倾向于对数据的分析和研究。这两部分工作重要程度不分伯仲,但目前从行业整体情况来看,更多的是在网络空间扫描,也就是“测”的部分做主要投入,而对扫描测绘数据的分析和研究相对较少。数据放在那就只是数据,只有将生米煮成熟饭,才能发挥其真正的价值。所以我们会持续更新一个研究专题,主要介绍一些在网络空间测绘数据分析方面的研究关注点和方法,旨在还原真实网络空间全貌,绘制出更有效的地图指导作战。接下来将介绍该系列的第一篇文章,网络空间数据绘制专题——资产地址动态变化研究。
二、研究背景
相比于地理信息测绘,网络空间测绘存在一些特殊之处。首先从数据维度来讲,地理空间的测绘数据是三维的(经度、纬度、海拔)且连续,而网络空间中将IP地址转化为长整形后,地址数据是一维的,并且每个点都是独立存在并不连续。此外,二者还有一个最大的不同之处就是变化频率,地理信息测绘数据一般变化较慢,而且因为是连续的,所以变化趋势相对好预测,比如珠穆朗玛峰的每年都会以一定的高度在增长,但正常情况下一般不会突然升高或下降几十米。而网络空间测绘数据则不同,绝大多数的IP地址处于变化是常态。比如存活情况、开放服务、ASN、地理信息、地址所有者等等维度都是处在动态变化中,并且因为网络地址都是离散分布的个体,变化趋势也就更难预测。但想要描绘出网络空间真实面貌,就必须对网络地址的变化情况进行深入研究。
互联网资产发现与识别是资产画像绘制和风险分析的必要前提,面对多变的网络环境,如何进行资产动态追踪是目前亟待解决的问题之一。现有方法在执行互联网资产变化监控时,大多仅基于端口、组件、服务等要素关注资产数量上的统计情况,忽视了对于具体网络地址对应资产的变化标记。为填补上述空白,我们提出了一种用于资产变化识别的新方法,使用该方法,我们可以动态地识别出固定网络地址对应资产是否发生了改变,有助于扫描策略优化、威胁跟踪等多种安全场景。此外,本文还基于对变化资产的监控与分析,提出了一种加速新出现资产指纹标记的策略。
通过对互联网上暴露资产的长期跟踪,我们发现每轮资产扫描得到的网络地址池始终处于动态变化当中,这意味着当新一轮扫描结果到来时,过去的资产标签可能已经失效。在这种情况下,现有暴露的资产数量将不能体现真实的暴露资产规模,而且过时的资产标签会混淆威胁狩猎的溯源。
进一步,正是由于网络资产和地址对应的不确定性,每一轮扫描中可能会存在初次被发现的资产设备类型,如果能及时筛选出这部分资产,就能及时对其进行指纹标记,有助于后续威胁发现与分析工作的展开。
因此,为解决上述问题,我们提出了一种监控网络地址对应资产变化的新方法,该方法能够对网络地址动态变化的资产进行标定,在用户搜索某网络地址信息时,就能告知其在当前时间节点,该网络地址对应资产标签相较过去时间是否已经发生了变化,从而降低试错成本,提高威胁分析的精准度;此外,我们还在每一轮扫描中筛选出全部可能的新出现资产,使用聚类算法将这些资产划分为不同的簇,方便后续利用专家知识从每个类簇中提取资产指纹信息。
三、网络地址对应资产变化识别
综合考虑目前现有的资产识别方法,我们设计出多种监控网络地址对应资产变化情况的方案,这些方案的目的是尽可能可靠的判断出多轮扫描后,相同的网络地址是否还对应同一个资产。本节将对这些方法进行简要说明,并通过实验,对比各方法在不同使用场景下的优劣。
3.1 Banner字符串匹配方法
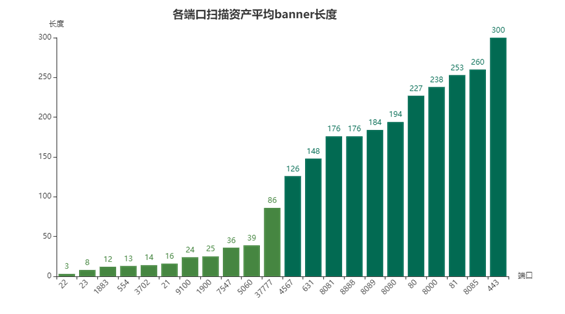
方案一采用资产banner信息进行比对。Banner是目标设备给访问者的响应通告信息,在扫描过程中,与设备建立完整的网络连接后,我们可以获取到目标系统的banner信息,其中可能会包含一些标识身份的敏感内容,包括软件开发商、软件名称、服务类型、版本号等等。因此,我们考虑能否将最新一轮资产的banner信息与之前最近一轮该地址对应资产的banner进行字符串匹配,计算两段banner字符串的编辑距离,进而通过距离大小来判断相似度,一旦两者文本相似性小于阈值,则认为该网络地址对应资产未发生变化。实验发现该方法在banner较长的情况下比较效率低,banner长度的统计结果如图1所示,按空白符分词后,大于100个词的banner主要属于http/https协议。我们发现,以443端口为例,该端口下资产banner长度为均值300时比较耗时约为32s,资产总数约为396万,比较总时间远大于扫描周期(5天),无法做到针对每一轮数据动态更新资产状态。

3.2 基于Simhash的部分banner匹配方法
由方案一,我们进一步改进得到方案二,采用Simhash算法对高维特征向量先进行降维,再比较得到的哈希值的距离。传统hash算法通常可以用于对一段文本生成指纹,但如果输入信息一旦发生轻微的变化,对应的hash值就会有很大的改变。在资产变化识别场景下,相同资产的banner信息在多轮扫描中很有可能局部发生改变,比如其中的时间项、动态序列号等。因此,我们需要hash值的相似程度能直接反映输入内容的相似程度。Simhash是Google提出用于海量网页去重的一种敏感hash算法,该算法将单个文本转换成一个定长的特征字,通过判断两特征字间的距离是不是小于指定阈值从而判断两个文本是否相似。这里,我们将该算法用于判定资产变化情况,能够降低比较的时间复杂度,同样选取300词长度的banner字符串进行比较,计算其simhash后求欧氏距离的时间花费下降为0.0053s。
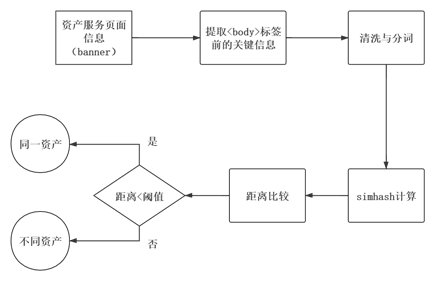
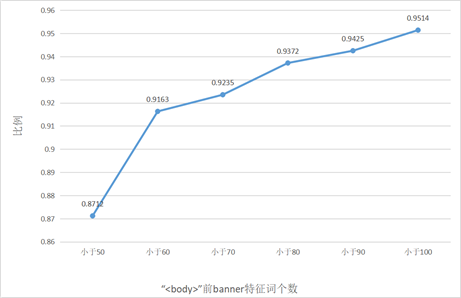
该方案整体流程如图2所示。首先,基于先前对于banner长度的统计,我们可知HTTP/HTTPs协议的banner整体长度过长,影响比对效率。因此,我们根据html语法,仅截取这些协议响应包中的部分信息,经综合考虑,最终选定包中“<body>”前的内容,这部分内容既包含了响应头又留有标题、元数据和url等重要资产信息,能很大程度上区分不同资产;同时该段内容长度适中,如图3所示,约有95%的资产该部分特征词个数小于100,基本能满足系统对于分析效率的要求。
下一步对抽取的banner信息进行缺失值处理和清洗操作,去除banner中所有的html标签和空白字符,同时将所有日期等已知影响判断的文本片段删除。之后,使用Simhash算法将该段banner信息映射为定长的64位二进制编码,采用随机超平面的离散化方法完成了文本的低维度表示;最后,选用了欧式距离用于度量两资产hash码的相似程度,一旦距离小于给定阈值,则认为两轮扫描的网络地址对应资产未发生变化,我们在已有具有相同资产标记的数据集上进行阈值选取。除了用于判断网络地址对应资产变化情况外,计算得到的资产hash码还可用于后续反向追踪资产对应网络地址的变化路径。
四、资产变化标记
本节利用上一节提出的相同资产判别方案,为每一轮扫描得到的暴露资产添加变化情况标记,该标记有利于扫描策略优化、威胁跟踪等多种安全应用。
4.1 标记流程
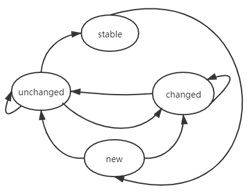
我们将网络地址资产变化情况分为四种,分别为:new、changed、unchanged和stable,每轮扫描中,每个网络地址的资产变化情况都会属于四者之一。
· new:代表该网络地址从未在历史的扫描中出现,暂将其代表的资产视为新增资产。
· changed:代表该网络地址曾在历史的扫描中出现,并且利用上一节中方法判断,其对应的资产和前一次发现时相比发生了变化。
· unchanged:代表该网络地址曾在历史的扫描中出现,并且利用基于Simhash的部分banner匹配方法,能判定其对应的资产和前一次发现时相比未发生改变。
· stable:一旦某个网络地址资产变化标记为changed的次数大于设定的阈值,就将其标记为stable,表示比较长的一段时间内网络地址从未发生过变化的资产。同时对于每种协议,维护一个stable库。各状态间的转换关系如图4所示。
4.2 具体应用
资产变化标记有助于提高威胁溯源准确性,一旦有分析人员溯源追踪到某个网络地址,我们的标记可以帮助其判断该网络地址对应的资产在指定时间区间内是否发生过变化,若发生过变化,我们会提供目标资产网络地址变化的可能集合,帮助分析人员重新溯源目标,提升溯源的效率和准确率。此外,每轮的资产变化统计还可帮助地址扫描策略的优化。某网络地址一旦被标记为stable,那么在之后的多轮(可自定义轮数)中,我们将不对该地址进行扫描,从而节约扫描带宽和扫描节点投入,减少扫描节点被识别为恶意应用的可能,维护一个持续稳定的扫描地址池。
五、新出现资产发现
在收集到的大量的banner响应信息中,我们发现相同设备类别的资产往往在响应报文的结构和内容上具备很高的语义相似性,不同设别类别的资产则差别较大,如图5所示,上方两个被标识为dahua camera的资产banner信息和下方Axis Camera有明显区别。

由上一节的资产变化判定逻辑可知,每轮扫描中变化情况为new和changed的资产很有可能属于之前从未出现过的资产类别,即新增资产。如果能将这些banner信息进行相似整合, 有助于对新出现的资产类型进行标注,从而描绘出网络空间新增资产态势。
根据协议我们将所有待标记的新增资产分为MQTT、UPnP、onvif、Dahua-DVR、FTP、SSH、Telnet、SIP、RTSP、HTTP十类,分别对每种协议的新增资产进行无监督聚类,就能得到协议内部的新增资产分布情况。具体来说,首先提取出新增资产对应的banner后,将其中不包含资产设备信息的条目过滤掉,比如非定制化的普通404、503等错误响应。由于多种资产设备在这些情况下banner响应信息可能相同,这就会影响资产聚类的准确性。下一步需要对过滤后剩余banner信息进行向量化处理,这里采用了目前常用的文本向量化加权技术TF-IDF;最后通过用于数据降维的PCA算法,提取数据的主要特征分量,降维后的向量就用来作为资产聚类的输入。
目前常用的聚类算法包括基于距离的K-Means算法,基于层次划分的Hierarchical算法,基于密度的DBSCAN等多种。由于每种协议都需要进行参数的动态调整,综合考虑新增资产的数量级以及时间开销,我们选用KMeans算法进行资产聚类。
KMeans算法的基本思想是以空间中k个点为中心进行聚类,对最靠近它们的对象归类,通过迭代的方法,逐次更新各聚类中心的值,直至收敛或到达中止条件。
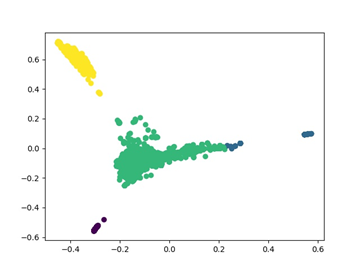
聚类后使用轮廓系数(Silhouette coefficient)对无监督聚类效果进行评价,以针对http协议下8000端口的新增资产聚类结果为例,图6所示是轮廓系数最接近1时(≈0.87)的聚类效果,明显看出,经过聚类之后,我们确实能够得到新增资产中各个可能资产类别的聚类簇,该聚类结果能够用于后续指纹提取以及人工标记,加速了新出现的设备的发现进程。
六、总结
本文基于对暴露资产的网络地址变化的分析,提出了一种基于banner信息比对的资产变化识别方法。使用该方法,我们在搜索引擎中增加了地址对应资产变化情况这一标记维度,能够帮助分析人员提升溯源准确度,同时也能用于优化引擎的地址扫描策略。此外,我们将聚类算法应用于识别每轮扫描中新出现的资产设备,提升后续指纹的提取效率。
参考文献
- 2018物联网安全年报,http://blog.nsfocus.net/wp-content/uploads/2019/03/2018%E7%89%A9%E8%81%94%E7%BD%91%E5%AE%89%E5%85%A8%E5%B9%B4%E6%8A%A5.pdf
2. Manku G S , Jain A , Sarma A D . Detecting Near-Duplicates for Web Crawling[C]// WWW2007;International world wide web conference. Google Inc.;Google Inc.;Stanford University;, 2007.
3. ~J Salton. Introduction to Modern Information Retrieval. 1983.
4. Shlens J . A Tutorial on Principal Component Analysis[J]. International Journal of Remote Sensing, 2014, 51(2).
5. Macqueen J . Some Methods for Classification and Analysis of MultiVariate Observations[C]// Proc of Berkeley Symposium on Mathematical Statistics & Probability. 1965.
6. Dasgupta S , Long P M . Performance guarantees for hierarchical clustering[J]. Journal of Computer and System Sciences, 2005.
7. Ester M , Kriegel H P , Sander J , et al. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. AAAI Press, 1996.
8. Peter R J . Silhouettes: A graphical aid to the interpretation and validation of cluster analysis[J]. Journal of Computational & Applied Mathematics, 1987, 20.
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。