阅读: 9
一、前言
威胁是网络安全领域关注的重点,因此针对多样的网络威胁,安全研究人员研究出了多种威胁检测引擎。在业务场景多样化以及海量数据的背景下,各种威胁检测引擎会产生大量的安全告警,例如在物联网威胁狩猎过程中会检测到大量告警而且研究人员是需要人工审核进而从中找到真实有效的威胁,导致这一状况的原因一方面因为威胁检测引擎存在错误告警甚至遗漏告警的可能,因此需要人工进行审核确认,另一方面因为在告警信息中可能存在信息价值低的告警,例如可疑扫描等威胁,因此在人工审核告警的过程中可能会面临大量此种类型告警。因此当安全研究人员面对海量的告警时,如何能够快速的找到有效的安全威胁呢?一种常见的解决办法是对告警的威胁等级进行分级,安全研究人员会优先处理高级别的告警威胁,然后在处理低级别的告警威胁,这样以便在有限的时间内更快的找到有效的安全威胁。虽然这样处理方法在一定程度上能够快速的找到高威胁的告警,但是依然存在一些问题。比如,告警的威胁等级经常是人为定义的,因此会存在一定误差,在某些场景或者情况下是不完备的;此外告警威胁的数量没有发生变化,安全人员依然是面对海量的告警进行处理,因此需要一种更高效更好的方式来解决这个问题。
本文从安全研究人员处理海量告警的角度出发,提出了告警优化的方式,目的是减少告警的数量,并且能够让安全研究人员更快的找到有效的告警,减低人工成本并提升发现高级威胁的能力。
二、告警优化机制
利用传统的告警优化的方式对海量告警进行人工审核其首先将告警按照告警类型进行级别划分,对不同告警进行打分之后得到高级威胁、中级威胁、低级威胁。然后再由安全研究人员依次对高级别的告警威胁进行人工审核,从中发现有效的威胁告警。这个过程如下图所示。

为了更加准确更加高效的对告警进行处理,本文从以下三个方面进行威胁告警优化,分别是告警预处理,告警相似度计算,告警聚类。
面对海量告警,第一步需要针对告警进行预处理,这个过程既需要完成对告警数据的清洗,也包括针对告警数据的去重,甚至需要利用专家知识对告警数据进行筛选,剔除掉一部分告警。通过这一过程只能优化掉少量告警,但是对于后续处理流程提供了比较干净的告警数据内容以及规范的告警数据输入格式,有利于后续处理流程的开展。经过告警预处理之后,告警数据会传递给告警相似度计算模块进行进一步计算。
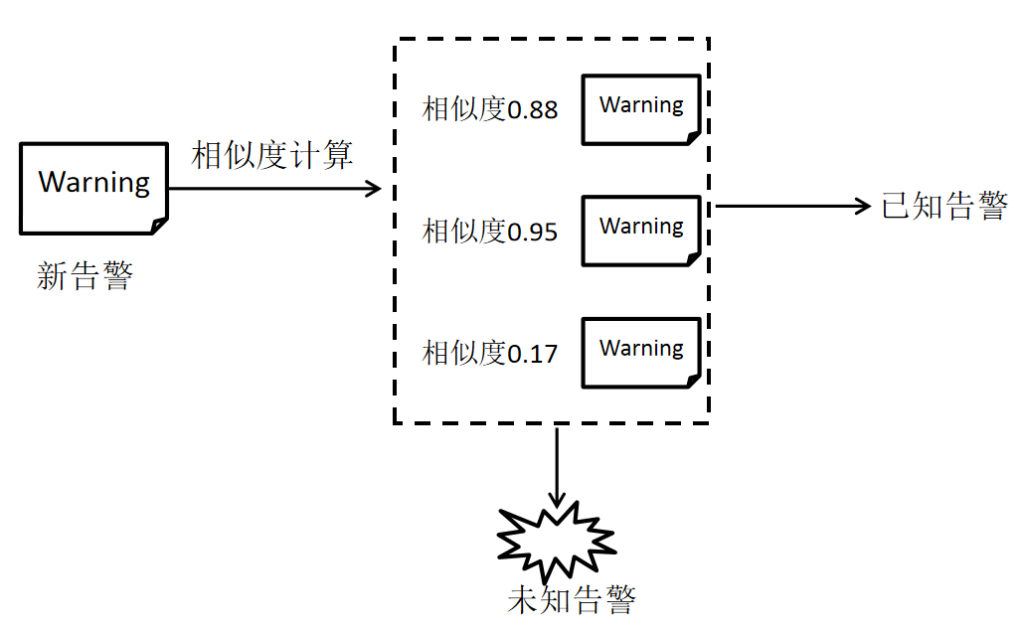
接下来告警优化需要做的是针对告警威胁进行告警相似度计算,这一过程需要利用历史告警和预处理后的告警进行相似度计算,这样能够快速的在历史告警中匹配出高威胁的已知告警,并且能够将较低相似度的其他告警划分到未知告警集合中,未知告警用于后续分析其告警威胁程度,已知告警则在这一过程中被优化掉不需要继续人工分析。经过告警相似度计算之后,安全研究人员能够快速分析相似的已知告警,并且能够排除一些潜在的0day等高威胁攻击,这个过程随着海量历史告警的不断积累会使得告警优化的能力越来越强,在过滤掉大量告警信息的同时能够更好的对已知威胁进行分析,减少了安全研究人员人工审核告警的工作量。

最后告警优化需要对未知告警进行告警聚类,告警聚类可以使用的聚类算法包括KMeans、DBSCAN等,其算法原理以及使用方式在往期文章《物联网资产标记方法研究【二】——基于聚类算法的物联网资产识别算法》中已经详细说明。这一告警聚类过程的目的是将大量冗余复杂的告警以无监督算法的方式进行类别划分,这样能够将大量相似且相关的告警有效的聚集到一起,便于安全研究人员分析的同时,减少了人工重复分析告警的数量。例如通过聚类算法能够快速将wordpress相关的告警聚集到一起,这样安全分析人员能够快速判断该类告警为web相关告警,并且能够通过大量的相似告警内容优化掉整个聚类类别,不需要人工审核这类相似的告警,下图为有关告警URL示例。

此外通过聚类算法还能够将不同类型的告警进行聚集,例如也可以找到DedeCMS织梦的后台代码执行相关漏洞相关的告警,下图为告警示例,后台代码执行相关漏洞作为高威胁告警安全分析人员会优先进行排查和处置,而其他正常业务逻辑例如页面管理等错误告警则可以快速优化掉,避免人工审核的过程。

通过告警聚类也能够将一些告警预处理阶段没有处理好的告警进行二次处理,例如如下告警示例则是SQLite相关的告警,其区别主要在于告警内容中的SQLite版本不同,因此在安全研究人员人工处理告警时,则可以快速优化该聚类结果的告警内容,避免了人工审核本质为同样告警内容的告警信息。

通过以上告警聚类的方式能够实现通过无监督算法对海量告警进行划分,进而对同一聚类类别中的相似告警信息进行优化,降低了告警的数量,而且聚类结果的内容能够帮助安全分析人员快速发现高级威胁的效率。
三、总结与展望
分析告警是安全研究人员日常工作中的一项重要内容,面对海量数据环境下的海量告警,安全研究人员往往无法做到逐条分析,这就面临着会漏掉高威胁告警风险的可能。为了解决传统告警分析过程中遇到的告警数量多、分析威胁慢等问题,本文介绍了通过告警优化机制来降低告警数量并帮助安全分析人员快速审核高威胁告警,通过实践的方式说明了此类告警优化机制的可用性。当然海量告警分析依然存在一些困难也依然存在提升空间,除了利用历史告警数据以及各类算法的助力之外,安全分析人员在未来可以在更多的环节加入自动化处理机制,从而降低人工成本,例如将人工分析审核流程以自动化智能化的方式进行。
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。